
语法分析与纠错相结合的文档结构重构方法
2019-05-16 07:39田英爱
北京信息科技大学学报(自然科学版) 2019年2期
张 真,李 宁,田英爱,耿 思,许 洁
(1.北京信息科技大学 计算机学院,北京 100101;2.中国电子技术标准研究院, 北京 100007)
0 引言
流式文档结构承载着大量宝贵的语义信息[1],对文档理解有着重要作用。例如计算机自动提取文档的大纲时,需要文档结构。文档的逻辑构件表示文档段落的语义信息(例如“摘要”,“一级标题”等),文档逻辑构件之间的关系形成文档结构。由于流式文档排版格式的复杂性,大部分的流式文档都存在一定的错误,如标题式样错误、图表错误等,会导致文档逻辑构件的缺失、冗余、位置错误等。以往不包含容错的文档结构重构算法无法处理上述情况。因此流式文档的结构重构算法中,高效的容错算法至关重要。
1 相关研究
目前,学者们在文档结构重构上进行了一些研究。文献[2]将逻辑构件建立为有向图表示的文档结构,通过有向图的单源最短路径算法过滤多余的有向图,得到文档结构,但是该方法必须确保文档构件识别的准确性;文献[3]构造了一个有限状态自动机,根据状态转移函数控制文档结构识别的顺序,该方法虽然能够对文档进行整体结构识别,但没有考虑构件缺失、多余及顺序颠倒等情况。如前所述,已有的方法虽然能对流式文档的结构进行重构,但前提是文档构件不存在错误。文献[4]提出文档结构识别问题为序列标注问题,使用条件随机场来对文档进行序列标注,具有一定的容错性,但只针对特定类型的文档,灵活性较差;文献[5]定义了一个具有容错能力的文档模型,通过概率松弛的启发式相似度度量方法计算待查文档与文档模型的相似度,并选择最佳优先搜索方法构建文档逻辑结构。在语义标注容错处理研究中,通常使用语义角色标注系统融合来减轻句法分析错误对语义角色标注的影响,文献[6]提出一种最小错误加权的系统融合方法,对每个系统的标注结果给予不同的权值,标注结果越可信其权值越高。在文本自动校对的研究中,文献[7]提出语法分析和词匹配相结合的方法,通过统计与规则相结合,对散串进行语法分析和词匹配,从而发现候选错误字串;文献[8]首先使用精确匹配方法和中文串模糊相似度算法对中文文本进行精确切分和模糊切分,建立词图,然后使用最短路径方法来进行错误的自动发现和自动纠正;文献[9]提出一种基于领域问答系统的错别字自动发现方法,通过多字词和合并串进行相似词串聚类,对相似串的上下文语境进行分析,从而发现错误;文献[10]提出一种基于语义搭配知识库和证据理论的语义错误侦测方法,首先构造语义搭配知识库,然后使用自顶向下的方法发现可能的错误,结合语义搭配以及规则获取词语的语义搭配关联度。上述方法主要针对的是中文文本和语义角色标注中的错误,虽然研究领域不同,但是研究方法上有一定的参考价值。
综上所述,当流式文档中出现逻辑构件的缺失、冗余、位置错误等情况时,将使文档结构重构方法难以处理。本文提出了一种性能更优的算法,使流式文档结构重构在文档逻辑构件存在错误的情况下,仍然能高效地分析出符合预定义排版规则的结构。
2 文档元数据模型的构建
在进行文档结构重构过程中,文档元数据模型需要确定文档中逻辑构件的出现顺序、出现次数以及嵌套结构,最终形成一棵规则语法树,用于分析文档逻辑结构的正确性。文档元数据模型的构建一般有基于模板[11]和基于语法[12]的方法。当使用模板的方法时,一旦编写模板出现错误,则会对文档结构重构产生一定影响;基于语法的方法中,使用XML Schema可定义文档元数据的属性、数据类型、元素及其包含关系,便于解析,所以本文使用XML Schema来构建文档元数据模型。以学位论文为例,逻辑构件集合为{摘要,正文,关键词,一级标题,列表,图,表,图题,表题},则其逻辑构件的排版规则语法树如图1所示。
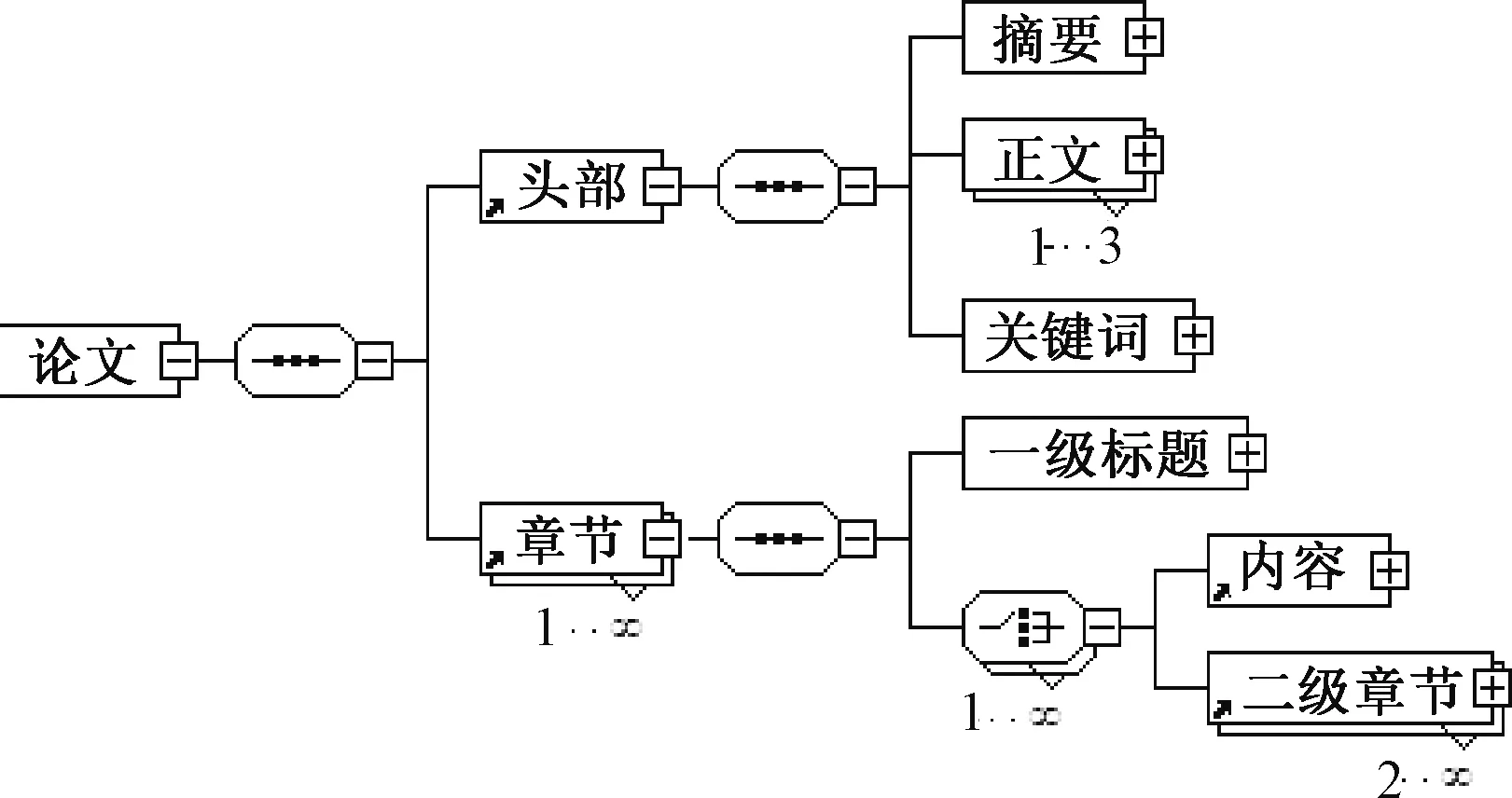
图1 学位论文逻辑构件排版规则语法树图举例
每篇论文包含头部和章节两部分,并且按顺序出现。头部包含摘要、正文和关键词,正文最少出现1次,最多出现3次。章节这部分可重复出现多次,包含一级标题、内容和二级章节,其中内容和二级章节是可选节点。该部分的描述和章节部分的结构是相似的,只是级别不同。
3 基于左角分析法的文档结构重构
在文档逻辑构件重构过程中,需要避免大量的、无谓的节点遍历。在自然语言处理中,结构重构的方法一般有3种,即自顶向下的方法、自底向上的方法以及两者相结合的左角分析法[13-14]。使用左角分析法,既可以避免纯粹的自顶向下分析算法穷尽式扩展非终结符节点,又可以避免自底向上分析中盲目归约当前节点导致父节点找错的问题,可以有效解决文档逻辑构件遍历过程中的问题。本文使用左角分析法进行文档结构重构。
在文档结构重构中,“左角”是指文档结构树中任何子树的左下角符号。例如在图1中,“一级标题”是“章节”的左角。基于左角分析法的重构过程由语法树进行引导,定义所有的非叶子节点为需要判断的状态节点,使用左角分析法来对每个状态节点进行判断,从根节点在语法树中的位置开始,沿着树的左侧边,展开非叶子节点,一直到这棵树最底部最左的非叶子节点。判断当前输入的逻辑标签是否是最底部最左状态节点的左角,如果不是,通过查找该状态节点的兄弟节点,对该兄弟节点进行判断;如果是,则跳入该子结构继续判断识别。当子结构的所有叶节点都判断完以后,该子结构识别结束,使用XML储存识别子结构的结果。算法通过堆栈先进后出的功能来保留状态节点信息。具体描述如下:
算法1基于左角分析法的状态节点结构判断算法
将状态节点state1节点压入栈stack中;
构建以state1为根节点的XML文件state1XML;
if(当前逻辑构件是state1的子孙节点){
if(currentLabel的父节点是state1){
将currentLabel加入到state1XML;
While(栈不为空){
将下一个构件输入到stack中;
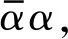
else if(栈顶为α,B→αγ):

}
if(state1有兄弟节点)
递归调用算法1对兄弟节点进行判断;
else
返回state1的XML结构;
}
例如逻辑标签集合{摘要,正文,关键词},状态节点集合为{论文,头部,一级章节,二级章节,三级标题},首先对根节点‘论文’进行判断,沿着最左侧展开为头部,通过判断当前输入的逻辑标签摘要是头部的左角,对头部状态节点进行判断,具体分析过程如表1所示。
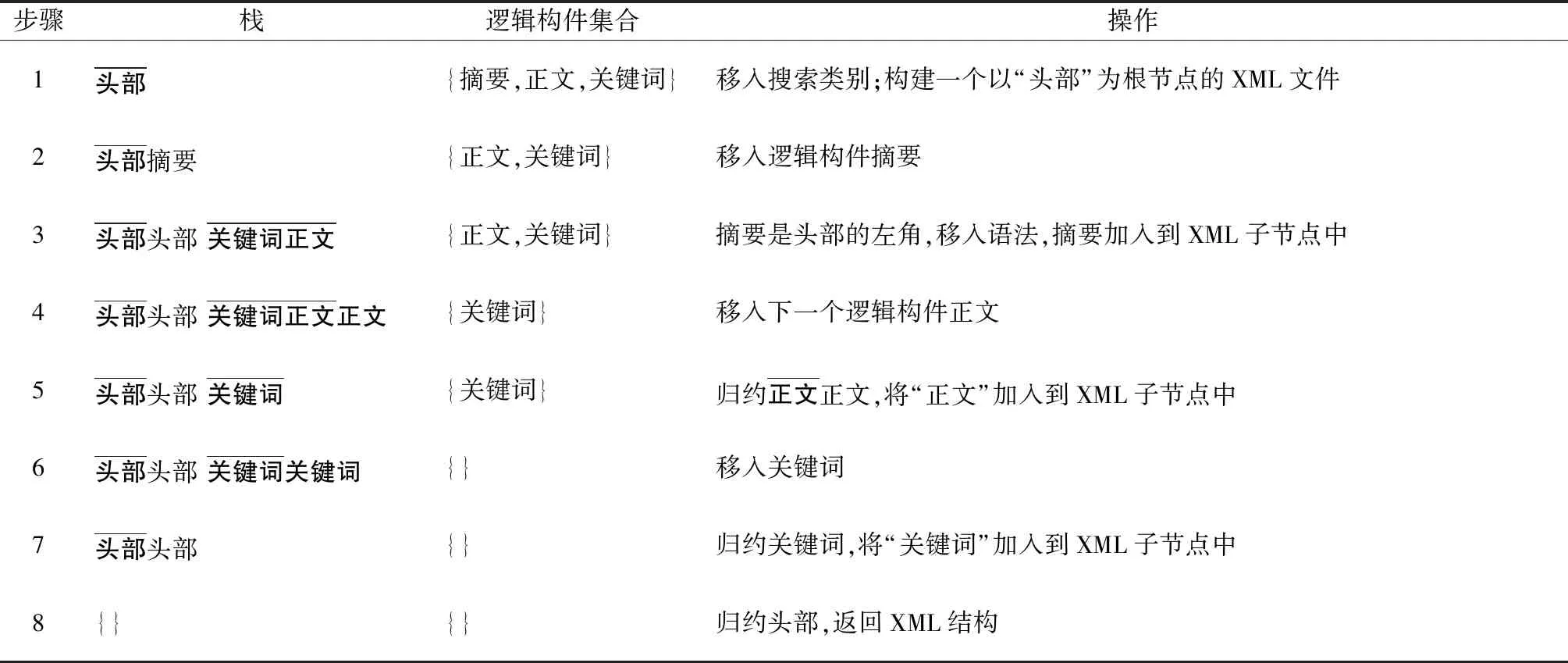
表1 左角分析法分析过程举例
4 基于纠错规则的容错处理
由于用户在写作过程中一般会出现一些错误;另外,机器对构件的识别结果也可能不准确,容易造成第3节中文档结构分析过程无法进行或分析结果不准确。所以在使用左角分析法分析文档结构的过程中,需要考虑错误处理,从而生成尽可能符合用户写作意图的结构。为解决以往结构重构方法在遇到错误时无法进行重构的问题,本文将加入纠错规则,使得文档分析在逻辑构件出错的情况下能继续做出正确判断,生成尽可能符合作者意图的结构。
4.1 错误分析
结构分析中的错误主要有两类:一类是作者写作时产生的错误;一类是机器识别构件时产生的错误。本文参照北京信息科技大学的学位论文规范对300篇北京信息科技大学的学位论文中的错误进行统计。经过人工统计,发现内容缺失类错误包括标题、摘要、参考文献等关键字的丢失;标题顺序类错误包括各级标题的顺序不连续;表题、图题类错误包括表题、图题不规范;大纲级别类错误包括标题大纲级别与其所属的级别不符。我们对每一篇文档进行人工判断,统计上述错误数量,发现标题错误和图表错误是文档结构重构常见的错误。其中标题错误、题注的缺失、图表与相应题注的位置颠倒在所有错误中占比分别为42%、33%、18%,因此本文针对上述3种错误制定纠错规则。
4.2 纠错规则的构建
文档结构分析过程中,由于含有错误的构件集合无法满足排版规则,将造成左角分析法无法进行或分析结果不准确。本文从左角分析法的文档结构重构分析过程中来发现这些错误,并且进行相对应的处理,制定了以下规则来判断分析。
[规则1]重构分析过程中,如果发现当前判断状态节点和待查构件是祖父关系时,利用以下算法进行处理。
算法2状态节点与待查构件是祖父关系错误处理算法
if(当前逻辑构件currentLabel是下一个逻辑构件nextLabel的父节点)
将currentLabel,nextLabel位置互换;
else{
统计下文中与当前逻辑构件级别相同的个数count,直到出现不同级别的逻辑构件为止;
if(count>1)
在currentLabel之前添加currentLabel的上一级构件;
else
将currentLabel的级别设为上一级;
}
该规则多应用于标题的缺失、冗余、位置错乱处理中,例如构件集合{一级标题,三级标题,正文},可以使用以上规则发现二级标题的缺失并纠正。
[规则2]重构分析过程中,如果发现当前待查逻辑构件是当前判断状态非第一个孩子的子节点时,使用以下算法进行处理,伪代码如下:
算法3构件是状态节点的子节点且非第一个孩子节点的处理算法
if(下一个逻辑构件nextLabel是当前状态state的第一个子节点)
将nextLabel和当前逻辑构件currentLabel互换;
else
添加与state第一个子节点相匹配的逻辑构件;
[规则3]重构生成后的文件保存为XML文件,但是该XML文件使用Schema校验时出现校验失败时,使用以下方法处理。
由于在Schema中限制了章节可出现的次数,当XML校验失败则说明该XML文档结构不完整,返回缺少章节的名称。读取XML中该章节的标题T,查找其上级逻辑构件S,通过比较上下两级标题的相似度来判断来进行纠正分析。其定义如下:
(1)
(2)
式中:S和T的长度分别为m、n;矩阵Dij为长度为i的逻辑构件S转变为长度为j的逻辑构件T所需要的编辑距离。
最终,字符串S和T的编辑距离D(S,T)即为矩阵中右下角Dmn的值。其相似度定义为
(3)
式中:sim(S,T)为S、T的相似度;|S|为S的字符串长度;|T|为T的字符串长度。如果Sim(S,T)的相似度为1,说明2个逻辑构件名称完全相同,则认为T多余;否则,比较T与nextLabel的相似度,如果Sim(T,nextLabel)大于等于0.5,则认为nextLabel存在级别错误,应与T级别相同;否则,认为T为多余逻辑构件。
4.3 容错处理
具有容错能力的文档结构重构算法将容错规则和第3节的方法结合起来.在使用左角分析法过程中,通过对状态节点与当前输入构件的关系进行分析,判断该构件是否有错,如果发现当前输入构件是状态节点的左角,则使用第3节的方法继续分析文档结构;否则判定为构件错误,调用相应的规则进行处理。算法描述如下。
算法4添加纠错规则的结构重构算法
if (当前输入逻辑构件currentLabel是当前判断状态state的子孙节点){
if(state是currentLabel父节点){
if(currentlabel是state的第一个孩子节点){
算法1分析文档结构;
else
按规则2处理;
}
else
按规则1处理;
}
算法4中,使用规则1和规则2对常见错误进行具体分析和纠错,纠错以后继续使用左角分析法识别文档结构,直到分析出状态节点的子结构;同时为了能够确保每个状态节点子结构识别的准确性,将每个状态节点的子结构识别结果分别以XML形式存储,并调用预先设定的Schema进行验证,如果校验失败按照规则3对其进行改正。
5 实验
本实验采用北京信息科技大学的学位论文来验证容错处理能力方面的识别效果。我们选择了50篇共含有108个错误测试点的文本结构样例。由于文档的保密要求,本文选择了在github上公布的68篇数据(https://github.com/COSLab)。每篇样例都含有一个或多个错误。我们利用左角分析法和纠错规则相结合的算法进行纠错,共纠正错误96个,其中真正的错误89个,准确率为92.71%,召回率为82.41%。对于常见的错误处理情况如表2所示。
本文方法在处理文档中的常见错误时,一旦发现错误,对错误的识别准确率较高。对于标题缺失和表题位置颠倒的错误,这些逻辑构件的缺失或顺序错乱,使用以往的流式文档重构方法如有限状态机和有向图的方法,因为无法找到与文档排版相匹配的规则都会造成重构失败;而对于标题冗余的错误会造成重构结果不符合写作意图;但是本文方法通过容错规则都能准确识别。
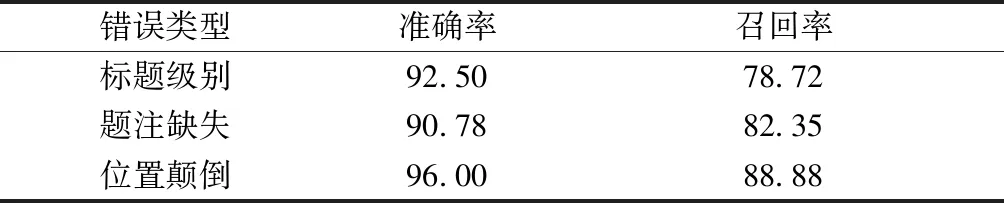
表2 常见错误的识别效果 %
对于文档结构识别结果,本文方法与基于有限状态自动机的方法[3]和基于有向图[2]的方法进行比较。采用上述相同的语料集合,评价指标选用正确率来评价文档结构识别的效果。最后发现,基于有限状态自动机的方法准确率为94.22%,基于有向图的方法为97.38%,本文方法的正确率为98.86%。本文方法相比于基于有限状态机的方法和基于有向图的方法识别结果都要好。究其原因,是因为本文方法通过排版规则可以对文档结构进行全面的分析,充分考虑每一种逻辑构件转移的可能性,增强了文档结构理解的容错性,提高了文档结构理解的正确性。
6 结束语
本文针对目前流式文档结构重构方法容错能力不足的问题,提出一种语法分析与纠错规则结合的流式文档结构重构方法。实验表明,本文方法能处理常见错误,一定程度上解决了以往方法遇到错误无法处理或者识别错误的问题,提高了结构重构的容错能力。但是本文方法中也存在一些问题,将来可以考虑增加对文本内容的语义分析从而将不常见的错误加入进来,因此加入语义信息来分析文档结构错误是未来研究的重点。
猜你喜欢
建材发展导向(2022年12期)2022-08-19
客联(2022年3期)2022-05-31
当代陕西(2022年4期)2022-04-19
摄影世界(2022年1期)2022-01-21
北京航空航天大学学报(2021年9期)2021-11-02
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
天津诗人(2017年2期)2017-11-29
电脑爱好者(2017年7期)2017-05-06
中国新通信(2016年17期)2016-11-17
