
基于局部化双向LSTM和状态转移约束的养殖水质分类预测
2019-05-15 11:15:50商艳红
渔业现代化 2019年2期
商艳红,张 静
(唐山师范学院,河北 唐山 063000)
随着人工智能和物联网技术的发展,利用物联网设备自动采集养殖环境信息,进而基于先进的机器学习和数据分析技术实现养殖水质情况的自动检测和预测,已成为当前智能化养殖业的研究热点,对提高现代化水产养殖效率具有非常重要的经济价值和现实意义。目前,国内外学者已经做了许多关于水质监控和预测工作的研究。早期的研究工作主要围绕水质的实时监控[1-3],不能对水质状况进行预测。随着机器学习技术的广泛应用,水质预测研究成为该领域的一个研究热点[4-5]。马从国等[6]基于主成分分析技术对养殖水质pH进行预测和报警;胡海涛等[7]提出利用历史时刻的参数值来预测将来时间段的参数值的方法;袁瑜等[8]基于BP神经网络对养殖水质pH进行预测;丁金婷等[9]利用模糊方法和BP神经网络对南美白对虾水质进行预测;商志根等[10]利用多项式核函数和径向基核函数的非负线性组合构造核函数对作物需水量进行预测。这些方法虽然在水质预测方面取得了一定的成果,但是对于水质各个参数之间的局部关系以及不同时间段数据的重要性差异没有得到很好的挖掘利用,因此,其性能受到一定的影响。另一方面,基于深度学习的预测在各行各业都取得了有效的应用[11]。王秀美等[12]将深度置信网络(Deep Belief Nets,DBNs)用于小麦蚜虫的短期预测;姚俊杨等[13]提出了基于深度置信网络的藻类水华预测方法;谭娟等[14]采用深度学习的自编码网络方法进行预测。虽然深度学习模型在许多预测应用中都取得了较好的性能,但是这些深度模型对历史中的所有信息都统一处理,没有考虑不同历史时间的数据对未来趋势预测作用的不同。
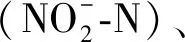
1 基于双向LSTM的局部特征数据挖掘
1.1 双向LSTM
双向LSTM网络模型BiLSTM[15]是在LSTM[16]模型之上发展起来的,LSTM是循环神经网络(Recurrent neural network,简称RNN)[17]的扩展,是一种长短期记忆模型(long short term memory),主要目的是用来处理历史数据中长期依赖缺失的问题,其利用一个单元来存储记忆,每个神经单元(Cell)都有一个状态。LSTM每个神经单元都包含3种门结构:输入门(input gates)、遗忘门(forget gates)、输出门(output gates),通过门的控制,神经单元的状态可以进行更新,LSTM的数据处理和传输过程如以下公式所示[5]:
it=σ(W(i)xt+U(i)ht-1+b(i))
(1)
ft=σ(W(f)xt+U(f)ht-1+b(f))
(2)
ot=σ(W(o)xt+U(o)ht-1+b(o))
(3)
ut=tanh(W(u)xt+U(u)ht-1+b(u))
(4)
Ct=iteut+fieCt-1
(5)
ht=ottanh(Ct)
(6)
式中:it、ft、ot和Ct表示t时刻对应的三种门结构和神经单元的状态;W∈Rk·|xt|,U∈Rk·k和b∈Rk·1为模型的参数;k为LSTM神经元的个数;i∈Rk·1是输入门;σ为sigmoid函数;e表示两个向量对应位置的元素相乘的操作;u∈Rk·1为上一位置输出的特征表示和当前输入的特征表示组合后形成的新的特征表示;c∈Rk·1为存储数据信息的内部神经单元;ht即为神经单元的状态输出。
LSTM的结构如图1所示,图中的符号表示公式(1)~(6)之间的关系,LSTM神经单元通过门(gate)结构控制信息的输入和输出,门结构被用来让信息选择性地进行传输。
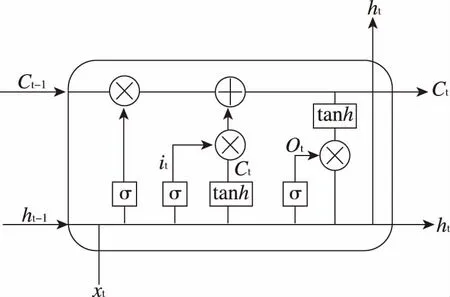
图1 LSTM结构图Fig.1 Architecture of LSTM
双向LSTM(BiLSTM) 的目的是解决单向LSTM无法处理后续信息的问题。单向LSTM只能在一个方向上处理数据,而BiLSTM可以利用历史信息和未来信息来学习当前状态信息,其结构如图2所示。其中自前向后循环神经网络层的更新公式为[7]:
(7)
自后向前循环神经网络层的更新公式为:
(8)
两层循环神经网络层叠加后输入隐藏层:
(9)
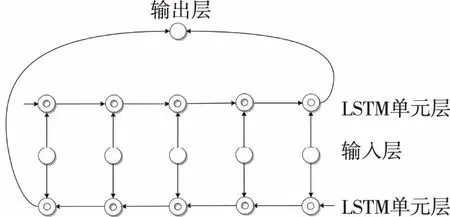
图2 双向LSTM结构Fig.2 Framework of Bi-LSTM
LSTM网络模型在许多应用中都取得了重大成功[21]。主要是因为采用记忆神经单元控制如何丢弃和更新神经单元的信息,能够把序列数据中的远距离依赖信息引入到模型的学习当中。因此,LSTM网络模型可以使用到养殖水质预测问题中,即根据水质的历史数据预测其未来情况。
1.2 局部化双向LSTM
尽管LSTM和BiLSTM比早期的RNN能够更加有效地记忆更长距离的信息,但是在数据的持续处理过程中仍然会造成信息的不断衰减,这使得LSTM不能有效地捕获局部特征对水质的影响,因为不同时间段水质的特点是不一样的,其对水质变化的影响也是不一样的。为了充分利用历史时间段中不同时刻的水质信息来预测未来时刻的水质情况,提出一种局部化的双向LSTM网络模型CovBiLSTM。该模型利用卷积神经网络(CNN)中的卷积和Max pooling方法作用于BiLSTM得到的中间层表达上,进而融合养殖水质序列数据当中的局部特征信息得到更加有效的数据表达,基于此,可更加有效地预测水质情况。
CovBiLSTM的网络结构如图3所示。
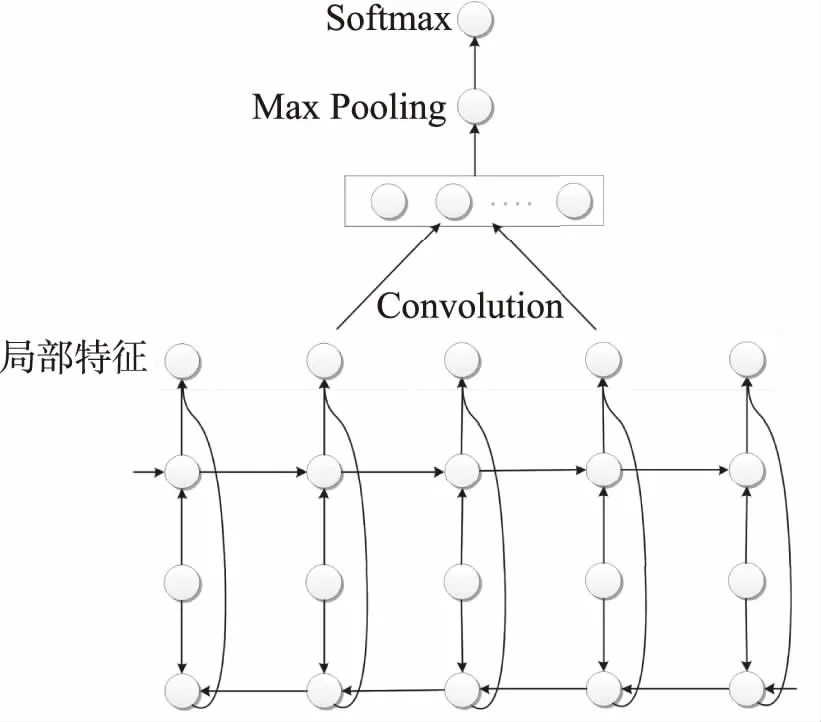
图3 CovBiLSTM结构Fig.3 Framework of CovBiLSTM
首先把BiLSTM网络每个单元的两个方向的输出向量合并成一个向量,然后所有单元的输出就构成了矩阵,在该矩阵上利用卷积函数进行卷积处理,然后利用max pooling处理得到最终向量,最后在该向量上利用Softmax处理得到该输入属于各个类别的值的大小,取值最大的类别作为预测结果。使用窗口大小为k的卷积核进行变换操作,即一次性输入k个向量,输出一个向量,卷积函数如下所示:
dj=hi:i+kWj+bj
(10)
式中:hi:i +k=[hi;hi+1;…;hi+k-1]∈Rd×k;Wj∈Rk×1;dj,bj∈Rd。
然后,对所有的dj进行Max pooling操作得到最终的向量o∈Rd,即对每一维,取所有向量中的最大值,组成最终向量该维所对应的值,最后把向量o输入到Softmax分类器中,对输入的数据进行分类。
2 基于CovBiLSTM和状态转移约束的CovBiLSTMST
(11)
式中:x和x′分别表示变量进行归一化处理前和处理结束后的取值;xmin和xmax分别表示数据集中的最小数值和最大数值。
实际上,当前时间的养殖水质依赖于历史水质情况,所以利用局部化双向LSTM网络建立在历史数据的基础之上来预测下一时刻的水质情况。水质的预警级别为4类,即无警、轻警、中警和重警,分别对应水质正常、水质较差、水质很差和水质极差。因此,水质的预测在本文被当作一个分类问题。在本模型中,使用一个Softmax分类器来预测从双向LSTM网络学习到的数据向量o所属的水质预警类别:
(12)
(13)
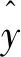
(14)
式中:ci∈Rm是one-hot表示;yi∈Rm表示对于输入数据预测每个类别的概率(m是水质预警预测目标类别个数)。
另一方面,养殖水质是逐步变化的,相邻时间段水质的类别分布不是相互独立的,即相邻时间段的水质状态一般不会相差太大。例如,如果当前的水质为正常状态,下一个时间段的水质为重警的概率就很小。利用转移概率来建模连续时间段水质状态的依赖关系,因此提出基于CovBiLSTM和状态转移约束的水质预测算法CovBiLSTMST,模型的目标函数需要在CovBiLSTM目标函数基础之上再增加一个转移代价函数:
(15)
式中:a(tt-1,yt)表示从t-1时刻的类别标签yt-1转移到t时刻的类别标签yt的代价权重值,该权重值可以基于训练数据中类别标签转换的概率值来计算,概率值越大转移代价权重值越小,试验中用指数函数e-p(yt-1,yt)来计算,p(yt-1,yt)表示从类别标签yt-1转移到类别标签yt的概率值。最终,模型的损失函数表示如下:
L(θ)=J(θ)+γT(θ)
(16)
为了训练局部化双向LSTM,最直接的方法是以历史中连续相等间隔采样n单元的水质特征数值作为模型输入,模型的输出与第n+1单元的数据进行比较。另外,还尝试利用非等间隔采样的方法来训练模型,例如,利用序列(Dn,Dn-1,Dn-3,Dn-7,Dn-13,Dn-18,…)来预测第n+1单元水质情况。这种方法采样的数据历史更长,而且考虑了不同时间间隔的数据对未来水质的不同影响。
3 试验
3.1 数据集与评价标准
提取唐山某养殖基地2017年9月1日—9月30日30 d的水质数据。根据实际经验,采样间隔设为2 min,选取1 700组数据作为试验数据,每组数据都包含连续时间段的100个样本水质信息,有900组数据包含水质报警的数据。随机选取1 000组数据作为训练数据对局部化双向LSTM模型进行训练,利用200组数据作为测试数据进行模型性能的测试。n的取值为20,即利用过去的20个时间单元的数据预测未来的水质情况。针对每个时间单元提取的水质信息,利用人工标注水质状态,包括无警、轻警、中警、重警。表1给出了水质4种状态所对应的参数取值的标准。试验结果的评价采用分类算法的评价指标,即准确率(P)、召回率(R)和Macro(F1)。
(17)
(18)
(19)
式中:m表示分类的总数,本文中水质分为4个类;ti表示被算法正确分到第i个类中的样本个数;fi表示不属于第i类而被算法分到第i类的中的样本个数;ni表示属于第i类而被算法分到其他类的样本个数。
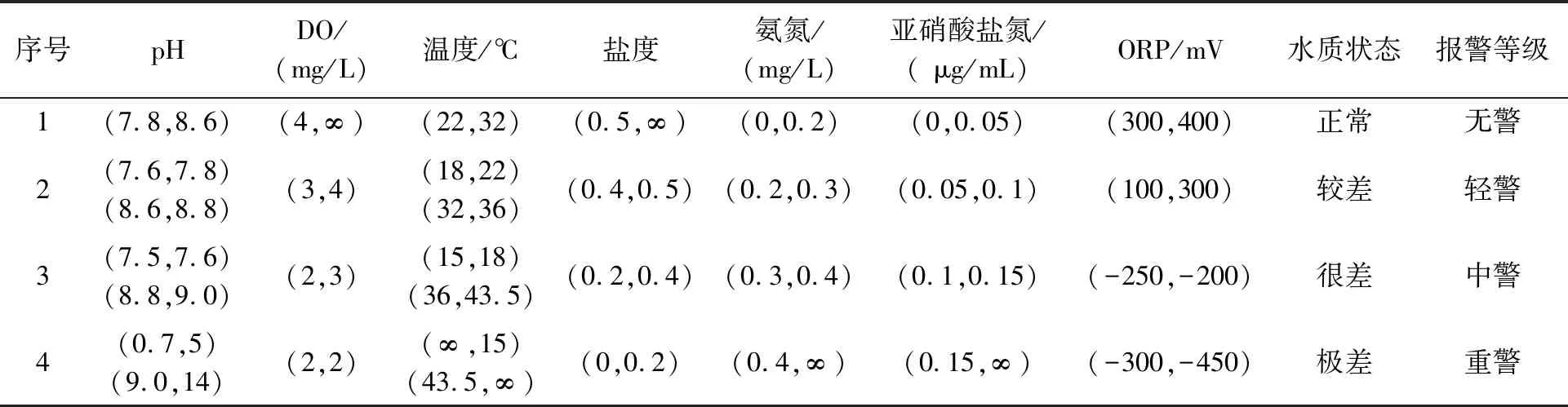
表1 水质状况分类标准Tab.1 Water quality classification standard
3.2 模型设置
本试验与目前主要的预测方法进行比较,包括:基于SVM分类器的方法[18-19]、基于循环神经网络RNN的方法[20]、基于单层LSTM网络的预测方法[21]和基于线性拟合方法Linear Regression[22](表2)。为了测试采样方法和状态转移约束对于水质预测效果的影响,试验中测试了本文提出的模型的4种具体实现:CovBiLSTMSTequa表示采用局部双向LSTM和状态转移约束进行预测,并利用等间距采样的历史数据来训练模型;CovBiLSTMSTne表示采用局部双向LSTM和状态转移约束进行预测,但利用非等间距采样的历史数据来训练模型;CovBiLSTMequa表示仅采用CovBiLSTM基于等间距历史数据的预测;CovBiLSTMne表示仅采用CovBiLSTM基于非等间距历史数据的预测。
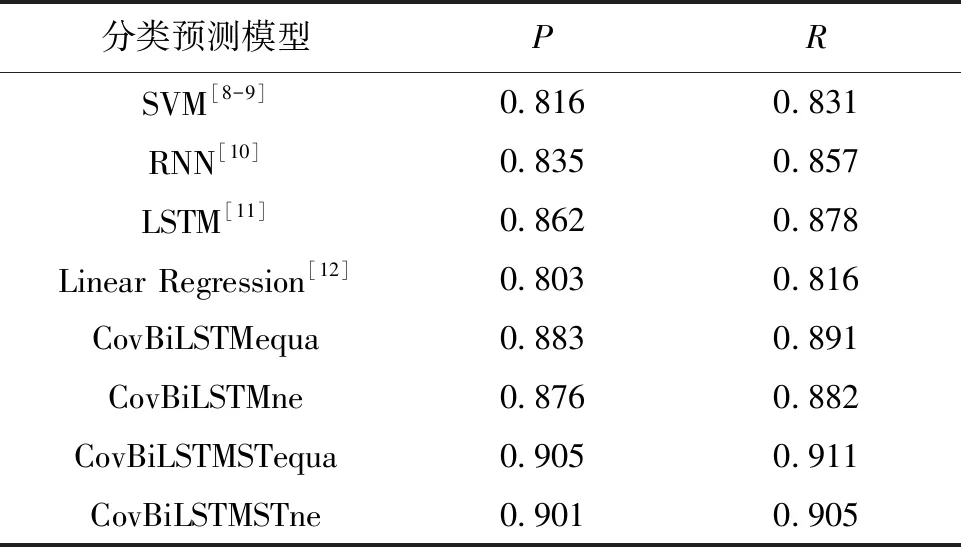
表2 不同算法水质预测试验结果Tab.2 Water quality prediction result of different approaches
4 结果与分析
由表2可知,基于局部化双向LSTM和状态转移约束的养殖水质预测方法(CovBiLSTMSTequa)比基于SVM、RNN、LSTM和Linear regression的养殖水质预测方法具有更好的性能,比现有最好的基于LSTM的预测方法CovBiLSTMSTequa的分类准确率(P)和召回率(R)分别提高5%和4%。性能提高的主要原因:首先,基于SVM的方法不区分各个时间单元对未来水质的不同影响,该方法不适合于时间序列预测;其次,基于RNN和LSTM的方法虽然能考虑历史数据的依赖信息,但是这些方法只考虑前向信息的影响,没有考虑未来信息对当前数据的影响,此外,这些方法没有考虑不同单元数据之间的交叉影响以及相互之间的关系,因此,其性能受到影响;最后,基于Linear Regression的方法很难有效拟合序列数据的非线性关系,因此,对于养殖水质这种复杂的变化情况很难进行有效预测。
针对CovBiLSTMST,表2的数据显示,加入水质状态转移约束条件有利于提高水质预测结果的准确性。这是因为这种约束信息可以减少局部噪音数据抖动对水质预测结果的干扰;基于等间隔序列数据的预测CovBiLSTMSTequa比基于不同间隔序列数据的预测CovBiLSTMSTne具有更好的性能,这是因为当前的水质状态受历史数据的影响更少,不同间隔数据序列不能有效反应数据的变化趋势。因此,双向局部化LSTM模型和状态转移约束对南美白对虾养殖水质的预测具有较好的性能,在实际应用中利用等间隔的序列数据来进行模型训练,可以得到更好的性能。
为了进一步测试CovBiLSTMST算法在训练数据集大小上的性能,利用不同比例的训练数据来训练各个模型,然后比较各个模型的测试结果。图4给出了用于模型训练的数据集占原有训练集比例从20%到100%的情况下不同模型的预测结果。在试验中,所有模型都利用等间隔的序列数据来训练模型。根据图中结果可以得出:相比其他方法,CovBiLSTMST受到训练数据集大小的影响最小;Linear Regression受到训练数据集大小的影响最严重,其预测能力相对于其他方法更弱。而基于深度学习模型RNN和LSTM的方法能够取得比浅层模型更好的效果,其受到训练数据的影响相对较小。研究表明,深度学习模型在预测南美白对虾养殖水质方面比传统模型具有更好的性能,而考虑局部特征之间的关系和状态转移约束的模型,CovBiLSTMST能在训练数据有限的情况下进一步提升南美白对虾水质预测的性能。
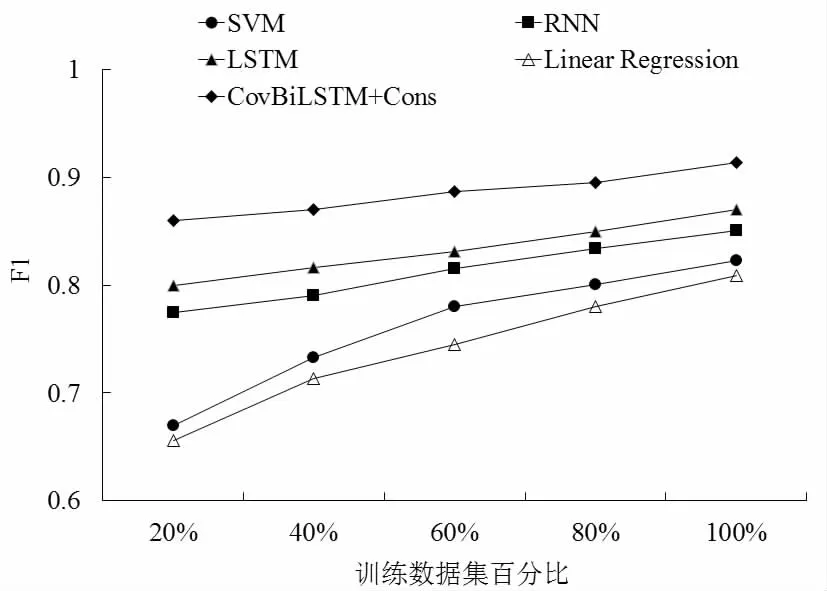
图4 基于不同训练集大小的预测性能Fig.4 Prediction performance of different percentages of training dataset
5 结论
针对当前养殖水质监控与预测方法存在的问题,提出一种基于局部化双向LSTM网络和水质状态转移约束模型的南美白对虾养殖水质预测算法,利用双向LSTM来建模养殖水质历史特征信息,通过卷积和max pooling等处理来预测水质状况。该算法可充分利用历史不同时段的水质特征信息,以及水质特征之间的相互关系信息,并利用水质相邻状态之间的依赖关系来进一步提高水质预测的效果。与现有方法相比,该预测模型在分类准确率和召回率方面可分别提高5%和4%。该算法能够更加有效地预测南美白对虾水质状况,也可以用于其他类型养殖水质状况的预测。
□
猜你喜欢
环境(2023年5期)2023-06-30 01:20:01
出版人(2022年11期)2022-11-15 04:30:18
小学生作文(低年级适用)(2019年5期)2019-07-26 00:45:10
当代水产(2019年1期)2019-05-16 02:42:04
读友·少年文学(清雅版)(2018年12期)2018-04-04 05:16:40
通信电源技术(2016年5期)2016-03-22 01:09:37
家庭百事通(2016年3期)2016-03-14 08:07:17
山东青年(2016年3期)2016-02-28 14:25:52
电源技术(2015年9期)2015-06-05 09:36:07
河南科技(2014年23期)2014-02-27 14:19:07
