
深度学习框架下的移动感知预缓存策略
2019-05-13 02:46陈正勇杨崇旭
小型微型计算机系统 2019年5期
陈正勇,杨崇旭,姚 振,杨 坚
(中国科学技术大学 未来网络实验室, 合肥 230022)
1 引 言
思科预测全球移动数据流量将在2016年和2021年之间增长七倍,并且到2021年每月全球移动数据流量将达到49艾字节[1].为了满足移动无线网络用户不断增长的需求,网络运营商引入了由密集部署的小基站组成的小基站网络[2].在网络中利用好缓存能力一般能够较大地提升网络性能[3,4].因此本文考虑使用具有存储能力的小基站使内容更接近终端用户.与从远程服务器获取内容相比,用户从小基站的本地缓存中获取内容将体验到更低的延迟和更快的下载速度.小基站网络和有线网络之间最重要的区别在于前者的用户是移动的,一个用户在下载一个文件的期间可能会经过多个小基站.为了有效利用小基站的缓存能力,必须考虑到用户的移动性.
考虑到一些流行的内容通常被不同的用户多次请求,许多相关工作以最大化复用缓存的内容为目标来利用基站的存储资源.文献[5]在已知用户对内容的偏好以及移动模式的前提下,提出了一个最大化缓存效用的缓存策略.文献[6]将用户的移动建模为一个马尔科夫链,以尽可能降低宏基站负载为目的提出了针对小基站内容缓存的优化策略.文献[7]在用户逗留时间服从指数分布的假设下,提出了文件在小基站上的分布策略.当小基站中存有部分流行内容时,请求这些文件的用户会获得更高的QoE.但是请求其他文件的用户并不能获得任何QoE上的提高.
为了提高所有用户的QoE,本文考虑在用户从当前基站下载所请求的文件时,在用户接下来有可能接入的基站中预先缓存部分请求文件.所以当用户真的接入到某个预先缓存有部分文件的基站时就能体验到更低的时延以及更快的下载速度.文献[8]首次提出了一个称为数据预取的概念用以将流量从移动网络分流到WiFi热点.文献[9]在假设用户移动信息已知的前提下介绍了一个分布式的主动缓存方案来支持用户的无缝移动.尽管很多相关工作注意到在小基站网络中用户移动模式的重要性,但是它们要么假设用户移动模式已知[5,9],要么用过于简单的模型例如马尔科夫链[6,10]预测用户的移动.然而,在真实的环境中,用户不会提供诸如将在一个基站停留多久以及将会接入哪个基站这样的信息.显然对用户移动预测的准确性会极大地影响到缓存策略的性能.在本文的实验中,马尔科夫链模型只能达到21.4%的准确率.所以选择一个合适的模型从历史轨迹中学习到用户移动模式是至关重要的.
深度学习在图像处理领域取得的巨大成功使其在近些年得到进一步的发展.本文采用变分自动编码器[11]的一个变式来进行轨迹预测.变分自动编码器是一个应用在潜在变量模型上的生成模型,目前已经成为无监督学习复杂分布的最流行的方法之一.用户的移动取决于他的习惯和环境,这些因素是一条轨迹的潜在变量.因此,可以认为用户移动模式是一个潜在变量模型,本文实际上使用条件变分自动编码器[12],基于用户已经过的N1个基站来估计即将到达的下一个基站的概率分布.根据调研,本文是第一个使用生成模型来预测用户轨迹的.在真实的GPS轨迹数据上,本文所提方案的预测准确率能达到79.7%.
本文采用编码缓存来更好地利用缓存资源.Raptor码[13]能够将一个由k个符号组成的文件编码不断产生新的符号,用户只要获得略大于k个新的符号就能够还原出原始文件.使用编码缓存能够保证缓存下来的内容对于用户总是有效的.本文将缓存效用定义为预先缓存内容中被用户消费的部分带来的收益减去预先缓存内容中被浪费的部分带来的惩罚,并设计了一个缓存策略来最大化缓存效用.
2 系统模型及问题定义
本文考虑由密集部署的小基站组成的小基站网络.图1给出了一个网络布局和用户轨迹的例子,每个正六边形表示相应小基站的覆盖范围.本文通过从历史轨迹数据中学习到的用户移动模型,预测用户即将到达的小基站.在用户从当前基站下载文件的同时,预测的小基站缓存部分用户所请求的文件.当用户接入预测到的基站时,能以快得多的速度下载文件,从而提高用户的QoE.当用户从基站的本地存储中下载内容时产生收益,当用户错过了预测到的基站或者基站缓存了过多内容导致用户在逗留期间没有下载完时产生惩罚.在这部分中,本文首先做出一些假设,然后描述系统结构,最后给出问题定义.轨迹预测方法将在下一部分介绍.

图1 网络布局和用户轨迹示例Fig.1 An Example of network layout and user trajectory
2.1 假设
1)为了更好地利用小基站的缓存容量,本文使用raptor码编码被请求的文件.当用户下载的编码数据略大于原文件大小时就能够恢复出原文件.
2)所有被请求的文件大小一样,表示为fMb.用户从基站本地缓存下载速度表示为RMbps,从原服务器下载速度表示为rMbps.因为小基站比原服务器离用户更近,所以有R>r.小基站预缓存文件的速度为rMbps.
3)当用户下载完预缓存的内容或者错过了缓存文件的基站时,这些缓存内容都可以从基站删除.并且每个基站只为相邻基站里的用户缓存一小部分文件.所以本文认为基站的缓存空间足够.
2.2 系统结构
为了使本文的系统正常运行,需要一个控制器来收集用户的轨迹信息和请求信息,同时对预测到的小基站下达预缓存指令.每个用户需要进行注册,并且配有独一无二的UID.系统结构如图2所示.控制器与小基站之间有三种类型的信息交互.

图2 系统结构Fig.2 System architecture
1)轨迹记录:控制器使用哈希表记录系统中所有用户的近期轨迹.当一个用户接入一个新的小基站时,小基站将UID和接入的时间戳发送给控制器.然后控制器将小基站的id和时间戳接入UID所对应的表项,如果表项长度达到设置的阈值,就删除最早的记录.
2)请求处理:当用户需要一个文件时,他向当前接入的小基站发送一个请求,并且在他下载的过程中,每接入一个新的小基站就发送一次请求.当一个小基站接到一个请求时,首先向控制器发送UID和请求的文件名以及时间戳,然后检查本地缓存,看是否为该用户缓存部分内容.如果有,小基站就从本地缓存向用户发送内容,否则经过骨干网从原服务器下载内容.当控制器接收到请求信息时,根据该用户的近期轨迹预测用户可能进入的下一个基站.然后控制器对预测可能性较大的基站下达预缓存指令.
3)预缓存:当一个小基站接收到预缓存指令时,记录相应的UID和文件名,然后从原服务器下载部分内容.
2.3 问题定义

(1)
(2)
(3)
(4)

3 缓存策略

(5)
(6)
(7)
(8)

(9)
公式(9)说明为了最大化E[Ui,s],应该在使其偏导大于0的基站j上缓存内容,即基站j应满足:
(10)
3.1 轨迹预测
本文用l1,l2,…,lN表示一个用户依次经过的N个连续的基站,需要在给定前N-1个基站的条件下预测第N个基站的位置,即估计概率分布P(lN|l1,l2,…,lN-1).数据集中的每一个数据都表示为一个向量:
(11)
这些向量是由用户的习惯和环境所产生的,因此可以将用户习惯和环境看作隐藏变量.将X的前N-1个基站也表示为一个向量:
(12)
本文的目的是估计P(X|Y).使用条件变分自动编码器,能找到一个分布P(X|Y,z;θ)来逼近一个未知分布P(X|Y),其中z通常是从高斯分布采样的隐藏变量,θ是学习到的神经网络的参数.可以将P(X|Y)表示为:

(13)
通过最大化(13)式,在给定Y的情况下神经网络就能输出准确的结果.为了计算(13)式,需要对z进行采样.但是大部分的z值并不能产生有效的X,所以应该寻找z的分布Q(z|X,Y),使服从该分布的z有很大概率会产生相应的X.这里,Q(z|X,Y)是P(z|X,Y)的一个估计,将输入的X编码为隐变量z,即编码器;相应的P(X|Y,z)为译码器.Q(z|X,Y)和P(z|X,Y)的KL散度为:
D[Q(z|X,Y)‖P(z|X,Y)]=Ez~Q(·|X,Y)
[logQ(z|X,Y)-logP(z|X,Y)]
(14)

logP(X|Y)-D[Q(z|X,Y)‖P(z|X,Y)]=Ez~Q(·|X,Y)[logP(X|Y,z)]-D[Q(z|X,Y)‖P(z|Y)]
(15)
如果Q的复杂度足够高,那么(15)式左边第二项会趋近于0.同时假设P(z|Y)为标准正态分布,因为只要给出合适的系数和偏移,可以由标准正态分布得到任何复杂的分布,具体参数由神经网络和相应Y决定.为了最大化P(X|Y),只需要最大化(15)式的右边.通常将Q(z|X,Y)取为:

(16)
并且限制∑为一个对角矩阵,这样就能很容易地计算出(15)式右边第二项.编码器Q(z|X,Y)和译码器P(X|Y,z)都由神经网络表示,可以利用从Q(z|X,Y)采样得到的z估计(15)式右边第一项.为了避免网络中出现采样层以使反向传播算法能够起作用,这里采用了再参数化的技巧采样.即首先采样ε~N(0,I),然后计算:
(17)

图3 CVAE的训练结构(虚线框内为损失函数)Fig.3 Training architecture of CVAE(dotted boxes show loss functions)
图3和图4分别画出条件变分编码器(CVAE)的训练和应用过程.给定Y和从标准正态分布采样的z,本文训练好的译码器能够产生近似于从P(X|Y)采样得到的X.当已知用户当前所在基站和此前经过的(N-2)个基站时,能够通过对z进行足够多的采样然后通过译码器得到用户下一到达基站的概率分布.

图4 训练好的CVAE的应用Fig.4 Application of a trained CVAE
3.2 缓存策略
用户在需要某文件时发出请求,然后每次移动到新的基站时发送一次请求直到下载完成.用户的每次请求都会触发一次预缓存调度.本文算法1描述了对第i个请求的第s次预缓存调度的过程.前4行的信息很容易通过查询控制器记录的信息得到,其中mSojourn是一个数组,mSojourn[k]表示第k个基站地平均逗留时间.第5行得到用户在当前基站的平均逗留时间.第6行通过轨迹预测模型计算出用户下一个连接基站的概率分布,第7到10行根据此概率分布选择进行预缓存的基站.第11到15行估计用户能够在当前基站下载的内容大小.第16到18行计算选中的基站应该缓存多少内容.

算法1.对第i个请求的第s次预缓存调度1:计算还需要下载的文件大小fleft2:当前基站缓存内容大小为cachedSize3:用户轨迹Y=[l1l2…lN-1]4:在每个基站统计的平均逗留时间mSojourn5:Ti,scur←mSojourn[lN-1]6:Psi←cvaeTrajectoryPrediction(Y)7:Sf←ø8:for allj such that psi,j>βα+βdo9: Sf←Sf∪{j}10:end for11:if cachedSize>R·Ti,scurthen12: f si←R·Ti,scur13:else14: fsi←cachedSize+(Ti,scur-cachedSizeR)·r15:end if 16:for all j such that j∈sfdo17: csi,j←min {fleft-fsi,mSojourn[j]·R}18:end for
4 性能评估
4.1 用户移动模型
本文使用Geolife[14]项目从182位用户收集的总共17621条轨迹的GPS轨迹数据集.这些轨迹大部分是在中国北京产生的,本文选取其中轨迹最密集的区域为研究区域,即经度116.3到116.35和纬度39.97到40.02.研究区域如图1分为85个正六边形,每个正六边形表示一个基站的覆盖范围.移除几乎没有用户经过的范围后,得到77个有效基站.一方面,用户可能到达家里或工作地点,所以有些轨迹中包含逗留时间相当长的点;另一方面,用户可能在相邻基站的边界徘徊,造成轨迹中出现抖动现象.这两种异常点会对实验造成影响,所以在这些点处将原轨迹一分为二.得到的数据就可以做模型训练了.
在进行轨迹预测时,本文将N设置为5,即在已知轨迹中前4个点的条件下预测第5个点.每个基站位置表示为一个独热向量.隐藏变量z的维度设置为60.训练集和测试集分别有15634和3181条长度为5的GPS轨迹.对于测试期间的每个Y(即已知的用户经过的前四个基站位置),本文将z从正态分布中采样200次以获得下一基站的概率分布.
表1是本文所用轨迹预测模型的准确率.第一列表示概率范围,第二列表示预测出的最大概率落于相应范围的预测数,第三列表示最大概率落在相应范围的预测的准确率.总体预测准确率为79.7%,有58%的预测其最大概率在0.98到1.0之间,这部分的预测准确率可以达到91.3%.
4.2 实验
本文缓存策略的核心部分是轨迹预测模型.很多相关工作使用马尔可夫链[10]或随机运动模型[15]建模用户移动模型.因此本文对比以下三种策略的性能:
表1 CVAE的轨迹预测准确率
Table 1 Trace prediction accuracy of CVAE

概率范围次数准确率0.98~1.0183491.3%0.96~0.9827983.9%0.94~0.9622180.1%0.92~0.949269.6%0.0~1.0318179.7%
1)基于条件变分编码器的缓存策略(CBS):如算法1所示.
2)基于马尔可夫链的缓存策略(MBS):整体缓存策略如算法1所示,差别是先用训练集算出概率转移矩阵,然后用该矩阵估计用户下一接入基站的概率分布,从而部署预缓存.
3)基于随机运动模型的缓存策略(RBS):整体缓存策略如算法1所示.这种模型假设用户是自由随机地移动的,所以每次随机选择与用户当前所在基站相邻的基站进行预缓存.
本文假设在所考虑时间段内,系统一共服务了300条请求(K=300),每一条请求对应于测试集里一条完整轨迹.用户从基站缓存中下载速度为2MB/s,即R=2MB/s;用户从原服务器下载速度为1MB/s,即r=1MB/s.在接下来的实验中,本文将被用户消费的单位预缓存内容的效用设置为1,即令α=1.
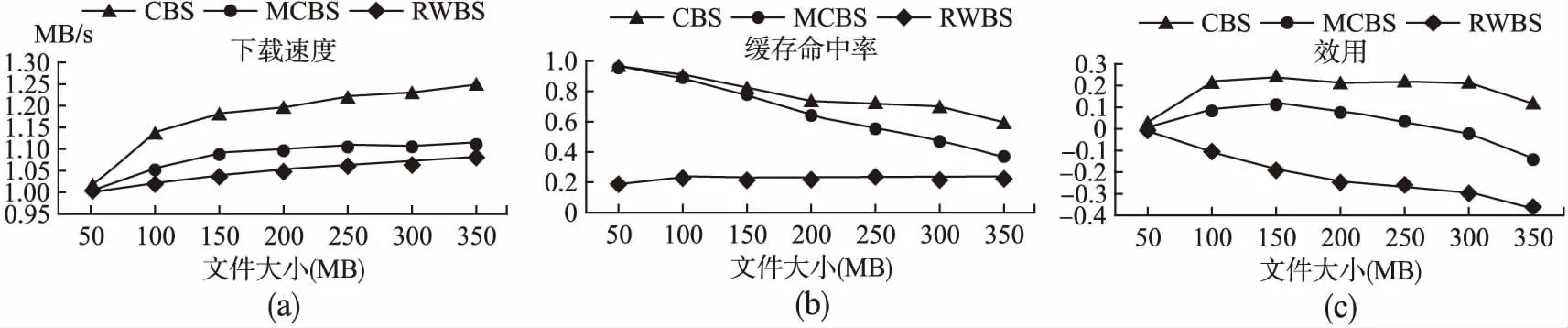
图5 文件大小的影响Fig.5 Influence of file size
在第一组实验中,本文将浪费的单位预缓存内容的惩罚设置为1,即令β=1,然后将所请求文件大小由50MB变化到350MB.图5(a)是三种策略的平均下载速度.当文件较小时,用户很可能在一个基站就能完成下载,因此预缓存不能带来明显的提升.三种策略的平均下载速度都随着文件大小增大而提升,这是因为用户在下载过程中经过更多基站,从而获得更多的预缓存内容,并且本文提出的策略总是具有最高的平均下载速度.本文将缓存命中率定义为被用户消费的预缓存内容占总的预缓存内容的比值.图5(b)是三种策略的缓存命中率.RBS的缓存命中率一直比较低,因为不能准确预测用户轨迹.CBS和MBS的缓存命中率随着文件增大而降低,因为随着用户经历更多基站,浪费的预缓存内容也一直在累加.本文用call表示所有的缓存内容,用cused表示所有被用户消费的缓存内容,那么效用可表示为[α·cused-β·(call-cused)]/(K·f).图5(c)是三种策略的缓存效用.CBS由于可以准确预测用户轨迹,因此比RBS和MBS有高得多的效用.

图6 β的影响Fig.6 Influence of β
在第二组实验中,本文将文件大小f设置为250MB,将β从0.4变化到1.4.根据算法1,是否在一个基站进行预缓存取决于用户接入该基站的概率是否大于p=β/(α+β).该阈值随β增大而上升.图6(a)、(b)和(c)分别表示三种缓存策略的平均下载速度、缓存命中率和缓存效用.如表1所示,在大部分情况下CBS预测的结果中只有一个基站具有很大的接入概率.所以改变β的值几乎不影响CBS的平均下载速度和缓存命中率.MBS的平均下载速度随β增大而减小,这是因为随着阈值升高,MBS满足预缓存要求的基站越少,从而用户从缓存中获取的内容越少.对于RBS,平均下载速度和缓存命中率都很低,这是因为其预测准确率过低.因为β增大意味着对于浪费了的缓存内容的惩罚加大,所以所有策略的缓存效用都随着β增大而减小,但是CBS一直具有最高的缓存效用.
5 结 论
本文提出了一个基于深度学习的具有移动感知能力的预缓存策略,通过在预测出的小基站上预缓存用户请求的部分文件来提高用户体验.首先根据用户消费缓存内容所产生的收益及浪费掉的缓存内容所产生的惩罚,给出了缓存效用的概念.然后本文将所考虑的问题公式化为一个最大化缓存效用的最优化问题.接下来本文第一个提出了使用条件变分自动编码器进行轨迹预测,并给出了具体缓存策略.本文使用了真实的GPS轨迹数据评估所提出的缓存策略的性能,结果显示所提出的缓存策略比其他基于现有移动模型预测轨迹的缓存策略具有更高的平均下载速度和缓存效用.
猜你喜欢
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
中国新通信(2022年4期)2022-04-23
建材发展导向(2021年7期)2021-07-16
中国药学药品知识仓库(2021年18期)2021-02-28
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
恋爱婚姻家庭·青春(2019年9期)2019-12-10
恋爱婚姻家庭(2019年26期)2019-09-14
冰雪运动(2018年3期)2018-12-29
探索科学(2017年4期)2017-05-04
