
通过代码模式改进基于IR的需求和代码之间追踪生成方法
2019-05-10 02:00杜天保沈国华黄志球吴德香
小型微型计算机系统 2019年5期
杜天保,沈国华,2,黄志球,2,王 飞,吴德香
1(南京航空航天大学 计算机科学与技术学院,南京 211106)2(软件新技术与产业化协同创新中心,南京 210093)
1 引 言
软件可追踪性(software traceability)是指在软件开发过程中建立和维护软件制品(例如,需求文档,源代码,测试用例等)之间的关联关系,并利用这些关系对软件项目进行一系列分析的能力[1],追踪信息支持变更影响分析、依赖影响分析、系统验证以及安全认证等活动.手动创建和维护制品间的追踪关系存在成本高、耗时长、易出错的问题.因此,如何利用自动化分析来实现软件可追踪性的生成与维护就成了领域内研究的热点与重点.
信息检索(Information Retrieval,IR)已被广泛应用于追踪关系的自动生成,其基本思想是计算制品间(例如需求和代码)的文本相似度,并最终为用户提供一个按照文本相似度从高到低排序的候选追踪链(trace link)列表.典型的IR追踪生成方法包括向量空间模型(VSM)[2],潜在语义索引(LSI)[3]以及概率Jensen和Shannon模型(JS)[4].
然而,需求本身的非结构化和“词汇表失配”问题极大的影响了IR追踪生成方法的准确性[5].为了解决这一问题,研究人员已经在多个不同方面改进了IR追踪生成方法,例如用户的反馈[6],主题模型[7]等.此外,还有一部分工作关注引入代码结构来改进IR追踪生成方法.这种利用源代码的结构信息的改进方法,被证明是非常有用的[6,8-11].
基于这个思路,本文提出IR技术和代码模式相结合的新方法.我们的方法分三步进行:1)利用IR追踪生成方法生成每个需求的候选列表;2)对于每个需求,选择其候选列表中排名靠前的类(本文选择候选列表中前3%的类)加入新候选列表(初始为空),根据已加入新的候选列表中的类以及类之间的依赖关系分析出剩余类(没有加入新候选列表的类)的代码模式,再由代码模式获得剩余类和给定需求之间的预期值;3)通过预期值,对剩余类重排序后加入新候选列表.最终,新候选列表实现对原候选列表的重排序.
2 相关工作
为了应对IR追踪生成方法的准确性低这一问题,当前的主流思想是从文本预处理[12]、IR模型[13]等词法分析的角度出发来优化IR追踪生成方法.但是,这些方法需要丰富的需求描述和完善的代码文档,这在实际项目中是难以获得的[14].为了克服IR追踪生成方法对文本质量的过于依赖,目前有一些工作开始结合代码结构改进IR追踪生成方法.Scanniello等人[15]引入PageRank算法来计算代码中每个函数在代码结构上的关联重要性(relative importance),这个值随后会与函数和给定特征之间的IR相似度相乘,得到的新值作为最终候选列表排序的依据.McMillan等人[16]提出了同时基于代码中调用依赖和数据依赖的自动化分析方法.Panichella等人[6]提出的方法则将用户反馈(user feedback)和代码依赖关系分析同时引入基于IR的需求到代码可追踪性生成.这一方法虽然能够提升精度,但引入了额外的人力投入,降低了工具的自动化程度.针对需求到代码可追踪性的自动化验证,CGhabi和Egyed[17]利用代码元素之间的调用依赖提出了若干代码模式,对于一组满足了某个代码模式的代码元素,它们应该具有类似的追踪链,如果与其在已知的追踪链集合中的追踪链不一致,则认为这条追踪链是有问题的.代码模式在追踪的自动验证领域取得了良好的效果,我们把[18]提出的代码模式的思想应用到追踪的自动生成中,实验表明,引入代码模式的IR追踪生成方法明显优于纯IR追踪生成方法.
3 代码模式和算法
本节主要讨论代码模式的原理、分类以及预期值求解算法.
3.1 类依赖和需求域
正如相关工作中提到的,我们使用代码元素之间的依赖关系来提高追踪关系生成的准确性.我们将软件系统表示为有向图G=(C,E).C表示系统中的类的集合,E表示边的集合(即,C中元素的有序对).每条边(ci,cj)∈E表示两个类ci和cj之间存在依赖关系.软件Understand[注]https://scitools.com/features/可以分析类之间的依赖关系.类与类依赖关系构成类依赖图,图1描绘了eTour[注]http://www.cs.wm.edu/semeru/tefse2011/Challenge.htm.系统(电子导游系统)类依赖图的摘录.类依赖图中节点表示类,边上的指示箭头用于区分依赖者和被依赖者.例如,类GestionePuntiDiRistoroAgenzia对应的节点指向类IGestionePuntiDiRistoroAgenzia对应的节点.则类GestionePuntiDiRistoroAgenzia是类IGestionePuntiDiRistoroAgenzia的依赖者,而类IGestionePuntiDiRistoroAgenzia是类GestionePuntiDiRistoroAgenzia的被依赖者.研究发现给定需求通常在代码的某块联通域内被实现,而不是随机分布在代码各处[18].这种代码联通域称为需求域(requirement region).图1显示了一个需求域(灰色区域)的示例.需求域标识实现eTour系统的需求UC8的所有类(节点).

图1 eTour系统的类依赖图摘录(灰色部分是UC8的需求域)Fig.1 Excerpt of class depend graph from the eTour system (UC8 Requirement region highlighted in gray)
3.2 代码模式的基本原理
在类依赖图中,一个类的邻接类(存在直接依赖关系的类)都不追踪到给定需求,表明这个类具有很高的可能性也不追踪到给定需求.例如图1中RicercaStandard远离UC8的需求域,它的邻接类都不追踪到UC8.所以,RicercaStandard具有很高的可能性不追踪到UC8.相反的,如果一个类的邻接类都追踪到给定需求,表明这个类具有很高可能性也追踪到给定需求.在给定的需求下,由类邻接的类可以获得若干代码模式,代码模式可以帮我们确定任意一个类和给定需求间的预期值.预期值有三种:预期追踪到给定需求(trace)、预期不追踪到给定需求(no_trace)或者不能确定(uncertain).
接下来,我们将讨论类的代码模式,为了表示方便,我们用“t”来表示类追踪到给定需求,“n”表示类不追踪到给定需求.
3.3 类的不同的代码模式
1)t→any→t和n→any→n模式
t→any→t模式(如图2上半部分所示)适用于至少有一个依赖者类(any类被依赖者类依赖)和至少一个被依赖者类(any类依赖被依赖者类)的any类,其中依赖者类和被依赖者类都追踪到相同的给定需求.请注意,any类表示任意一个类.模式n→any→n(如图2下半部分所示)它适用于至少有一个依赖者类并且至少有一个被依赖者类都不追踪给定需求的any类.图1中我们可以在需求UC8上识别出类IGestionePuntiDiRistoroAgenzia是t→any→t模式,因为它被GestionePuntiDiRistoroAgenzia依赖并依赖BeanPuntoDiRistoro,而GestionePuntiDiRistoroAgenzia和BeanPuntoDiRistoro都追踪到UC8.类似地,我们可以在需求UC8上识别出类DBPuntoDiRistoro是n→any→n模式,因为它的依赖者类GestionePuntiDiRistoroComune和被依赖者类IDBPuntoDiRistoro都不追踪到UC8.
2)t→t→any,n→n→any,any→t→t和any→n →n模式
t→any→t和n→any→n模式只对既有依赖者又有被依赖者的类有用.但是,有些类不依赖其它的类,在没有被依赖者的情况下,存在两种模式:t→t→any模式(如图3上半部分所示)适用于具有追踪到给定需求的依赖者,并且该依赖者又具有追踪到给定需求的依赖者的any类.n→n→any模式(如图3下半部分所示)适用于具有不追踪到给定需求的依赖者,并且该依赖者又具有不追踪到给定需求的依赖者的any类.还有一些类有被依赖者而没有依赖者,这些类也存在两种模式:any→ t→t和any→n→n.
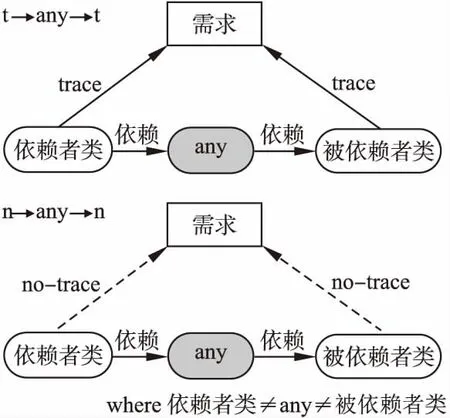
图2 “t→any→t”和“n→any→n”模式Fig.2 “t→any→t” and “n→any→n” patterns

图3 “t→t→any”和“n→n→any”模式Fig.3 “t→t→any” and “n→n→any” patterns
3)边界模式
1)2)中提到的模式不适用于全部的类.例如,图1中类IDBPuntoDiRistoro依赖实现了需求UC8的类BeanPuntoDiRistoro,并被没有实现UC8的GestionePuntiDiRistoroComune依赖.因此,IDBPuntoDiRistoro的模式是n→any→t,n→any→t不属于1)2)中提到的模式.我们可以看出IDBPuntoDiRistoro正好处于需求域的边界上,处于需求域边界上的类的模式是边界模式.总共有六种边界模式:
·有一个依赖者类追踪到给定需求,而没有被依赖者类追踪到给定需求(t→any→n).
·有一个被依赖者类追踪给定需求,而没有依赖者类追踪到给定需求(n→any→t).
·没有依赖者类追踪到给定需求,而至少有一个依赖的依赖者类追踪到给定需求(t→n→any).
·有一个依赖者类追踪到给定需求,而没有依赖者的依赖者类追踪到给定的需求(n→t→any).
·有一个被依赖者类追踪到给定需求,而没有被依赖者的被依赖者类追踪到给定需求(any→t→n).
·没有被依赖者类追踪到给定需求,而至少有一个被依赖者的被依赖者类追踪到给定需求(any→n→t).
3.4 代码模式分类
我们通过实验对类在不同的代码模式下追踪到给定需求的可能性进行了比较.根据可能性大小,我们将代码模式分成了三类:TT模式、NN模式、边界模式.其中,t→any→t,t→t→any,any→t→t属于TT模式,n→any→n,n→n→any,any→n→n属于NN模式,边界模式已经在3.3节做了介绍.实验表明,类在TT模式(t→any→t,t→t→any,any→t→t)下追踪到给定需求的可能性明显高于在边界模式(t→any→n,n→any→t,t→n→any,n→t→any,any→t→n,any→n→n)下追踪的可能性.而在NN(n→any→n,n→n→any,any→n→n)模式下追踪的可能性远远小于在TT模式和边界模式下追踪的可能性.
3.5 模式组合:纯模式和混合模式
到目前为止,我们已经讨论了单一的模式.但是在实际中,这些模式经常发生在一起.图1可以发现多个模式的发生在一起的情况.在需求UC8的情况下,由DBPuntoDiRistoro、IDBPuntoDiRistoro(any)和BeanPuntoDiRistoro可知IDBPuntoDiRistoro的模式是t→any→t,由GestionePuntiDiRistoroComune、IDBPuntoDiRistoro(any)和BeanPuntoDiRistoro可知IDBPuntoDiRistoro的模式是n→any→t.IDBPuntoDiRistoro具有两个不同的模式.如果给定的类(any)匹配多个模式,则适用以下两种情况之一:
1)纯模式(pure patterns):所有模式都是同一种.
2)混合模式(mixed patterns):模式有不同的种类.
对于纯模式,我们很容易确定给定类的模式,因为所有的模式都是同一种.但是,对于混合模式我们需要在不同的模式中选一个作为给定类的模式.对于混合模式有如下定义:
·TT模式、边界模式、NN模式同时出现的时候,TT模式占主导地位,我们忽略边界模式和NN模式的存在,选择TT模式作为给定类的模式.
·边界模式和NN模式同时出现的时候,边界模式占主导定位,我们忽略NN模式的存在.选择边界模式作为给定类的模式.
3.6 内部类,叶子类和根类
在类依赖图中既有入度又有出度的类称为内部类t→any→t,n→any→n,t→any→n,n→any→t中的any类都是内部类,只有入度而没有出度的类称为叶子类,t→t→any,n→n→any,t→n→any,n→t→any中的any类都是叶子类.只有出度而没有入度的类称为根类,any→t→t,any→n→n,any→t→n,any→n→t中的any类都是根类.
3.7 计算预期值
any类在不同种类的代码模式下具有不同预期值:TT模式的any类的预期值是追踪到给定需求(trace),NN模式的any类的预期值是不追踪到给定需求(no_trace),而边界模式的any类预期值不确定(uncertain).算法1描述了计算内部类预期值的算法:该算法使用四个变量:dependerT表示追踪给定需求R的依赖者数量;dependerN表示不追踪到R的依赖者的数量;dependeeT表示追踪到R的被依赖者的数量;dependeeN表示不追踪到R的被依赖者的数量.此算法仅针对内部类,因为既需要依赖者又需要被依赖者.如果至少有一个依赖者类追踪到给定需求(dependerT> 0)并且至少有一个被依赖类追踪到给定需求(dependeeT>0),则给定类的模式是t→any→t∈TT,预期值是追踪到给定需求(trace).TT模式和其他模式混合的时候,TT模式占主导地位.TT的主导地位是按照if的顺序隐含的(TT模式在其他模式之前检测).如果至少有一个依赖者类不追踪到给定需求(dependerN>0)并且至少有一个被依赖类不追踪到给定需求(dependeeN>0),而且没有依赖者类和被依赖者类追踪到给定需求(dependerT+dependeeT=0),则给定类代码模式是n→any→n∈NN,预期值是不追踪到给定需求(no_trace).如果存在依赖者类或者被依赖者类追踪到给定需求(dependerT+dependeeT≠0),则给定类的代码模式是边界模式(边界模式和NN模式混合,边界模式占主导地位).剩余的情况是纯的边界模式.边界模式的预期值不能确定(uncertain).我们不再介绍计算叶子类和根类代码模式的算法,因为如果假设变量dependeeT代表追踪到给定需求的依赖者的依赖者类的数量,并且dependeeN代表不追踪给定需求依赖者的依赖者类的数量.算法1就变成了计算叶子类代码模式的算法.同理,算法1也可以变成根类的预期值求解算法.

4 候选列表的生成和重排序
候选列表生成和重排序主要由三部分组成.第一,利用IR追踪生成方法在需求和类之间生成候选列表.第二,初始化给定需求的需求域,通过域内类(初始需求域内的类)和类依赖图获取域外类(初始需求域外的类)的代码模式,再由代码模式获取域外类的预期值.第三,域内类直接加入新候选列表,域外类重排序后加入新候选列表.新候选列表是对原候选列表的重排序.整个过程如图4所示.
4.1 通过IR追踪生成方法在需求和类之间生成候选列表
我们利用IR追踪生成方法在需求和类之间生成候选列表,总共包含四个步骤:
·创建文档库:对于代码中的每个类,我们抽取一个包含类名、函数名、注释的文档.对于每条需求,我们抽取一个包含题目和内容的文档(对于有结构的需求用例我们抽取其前置条件、主要流程、以及分支流程,对于无结构的需求我们直接引入所有文本信息)

图4 候选列表生成和重排序流程Fig.4 Candidate list generation and reordering process
·标准化文档库:所有类和需求的文档都使用IR领域内通用的手段进行预处理,包括标识符拆分、特殊字段与停用词消除以及词性还原和词根获取.
·通过IR计算文档的相似度:本文使用了两种不同类型的方法计算相似度,一种是基于向量空间的隐式语义索引(LSI)算法,另一种是基于词汇重叠的二次分配问题(QAP)算法[19].
·生成候选列表:在生成的候选追踪链列表中,我们按照每条追踪链的需求和类之间的相似度值对该列表进行降序排列.
4.2 获取初始需求域外类的预期值
4.2.1 初始化需求域
对于每个给定的需求,我们通过IR追踪生成方法生成了该给定需求的候选列表,候选列表中类按照相似度值从高到低排序的.我们选择候选类表中前3%的类构成初始的需求域.
4.2.2 获取类依赖图
Understand是进行静态代码分析的集成开发环境(IDE),它可以分析项目中类的依赖关系.我们根据类的依赖关系获取类依赖图.
4.2.3 域外类的预期值的求解算法
我们已经在第三节讨论了类的预期值的求解算法,首先,由初始需求域内的类和类依赖获得域外类的代码模式,再由代码模式获得域外类的预期值.算法2调用3.7节提到的预期值求解算法获得域外类的预期值.该算法区分内部类,叶子类和根类.需要注意的是,如果一个类既没有依赖者也没有被依赖者,我们无法分析其预期值,直接返回fail.

4.3 重排生成新的候选列表
算法3对每个给定需求的候选列表重排序.首先,初始化一个空的新候选列表,把初始需求域中的类直接加入新候选列表.然后,通过算法2计算域外类的预期值,如果给定类预期值是trace,直接将其加入新候选列表.如果给定类预期值是no_trace,则不加入.如果是unceratin,则将给定类加入不确定列表.最后,不确定列表中的类根据按照相似度从高到低依次加入新候选列表.而剩余的没有加入新候选列表的类也按照相似度值从高到低依次加入新候选列表.新候选列表实现对原来的候选列表的重排序.

5 实 验
在本节中,我们通过实验验证了本文提出的方法的有效性.5.1节介绍了数据集和实验使用的IR追踪生成方法.5.2节定义了实验度量指标.5.3节实验与结果分析.
5.1 数据集和实验使用的IR技术
我们选择两个中等规模的软件系统:eTour(电子导游系统)、iTrust3(在线医疗系统)来验证我们的方法.表1列举了这两个系统的基本信息.我们选择这两个系统的重要原因在于它们有可用的、高质量的需求追踪矩阵(RTM).每个需求追踪矩阵(RTM)包含m x n个单元,其中m表示需求的数量,n表示代码元素(本案例中是类)的数量.表2描述了etour系统的需求追踪矩阵(RTM)的摘录.单元格里的“X”表示需求和代码元素之间存在一条追踪链(trace link),单元格空白表示需求和代码元素之间不存在追踪链(trace link).实验使用两种不同类型的IR追踪生成方法:基于向量空间的LSI和基于词汇重叠的QAP.
表1 系统信息
Table 1 System information

eTouriTrustLanguagejavajavaKLOC2624#Executed class116226#Requirements58131Trace links in RTM308286
表2 eTour系统的RTM的摘录
Table 2 Excerpt of RTM from eTour system

ClassRequirementR1:UC6R2:UC8GestionePuntiDiRistoroAgenziaXXGestionePuntiDiRistoroComuneIGestionePuntiDiRistoroAgenziaXXDBPuntoDiRistoroXXIGestionePuntiDiRistoroComuneIDBPuntoDiRistoroControlloDatiXBeanPuntoDiRistoroX
5.2 实验度量指标
检索工作中最常用的度量指标是查全率(recall)和查准率(precision)[20].本文的查全率(recall)是检索到的正确追踪链与RTM中所有追踪链的比值,查准率是检索到的正确追踪链与所有检索到的追踪链的比值:
(1)
(2)
比较IR追踪生成方法的一种常用的方式是在相同的查全率水平上比较不同IR追踪生成方法的查准率,通常使用precision-recall曲线进行比较.为了进一步衡量实验结果的整体质量,我们选用了另外两个常用的实验度量指标:AP(average precision)与MAP(Mean Average Precision)[21],其中,AP用于度量每次查询检索到的相关文档(类)的排序质量.AP计算方法如下:
(3)
其中,r表示被查询对象(类)在候选列表中的排序,precision(r)表示前r个类的准确率.isRelevant()是一个二值函数,如果文档相关,则返回1,若无关,则返回0.MAP是所有AP的平均值:
(4)
其中q是单次查询,Q是查询的总数,MAP值越大,检索到的相关文档排序质量越好.
5.3 实验与结果分析
首先,我们对类在不同的代码模式下追踪到给定需求的可能性进行了比较.其次,为了验证代码模式的引入可以提高IR追踪生成方法的准确性,实验2使用改进前后的两个原型工具分别对eTour和iTrust数据集进行分析并比较实验结果,该实验采用LSI作为向量相似度计算模型.最后,为了验证不同类型的IR技术对实验结果的影响,我们分别使用LSI和QAP对eTour数据集进行分析.
5.3.1 实验1
本实验对eTour和iTrust数据集中的内部类和叶子类在不同的代码模式下追踪到给定需求的可能性进行了比较.根类和叶子类的实验结果类似,因此根类不再赘述.
对于给定的需求,我们通过需求追踪矩阵(RTM)和类依赖关系获得每个类的代码模式.已知每个类的代码模式,可以进一步分析出每种代码模式包含哪些类,以及这些类中追踪到给定需求的类占的比例(由RTM可知类是否追踪到给定需求).一种代码模式在给定需求下求得的比例值越高,any类在该模式下追踪给定需求的可能性越大.我们把每种代码模式在数据集中每个需求下求得比例值取平均,来比较any类在不同模式下追踪到给定需求的可能性.实验结果如表3所示,表中的N/A表示代码模式不存在,pure和mixed用于区分纯模式和混合模式.从实验结果可以看出,对于内部类,TT模式比例值的平均值是60%~65%,边界模式是5%~39%,NN模式0.5%~0.7%.iTrust数据集中没有一个叶子类追踪到需求.因此,我们不对iTrust数据集中的叶子类进行分析比较.对于叶子类,TT模式比例值的平均值是36%~83%,边界模式是10%~34%.NN模式是0.9%.对于内部类和叶子类,TT模式比例值的最低平均值比边界模式比例值的最高平均值分别高21%和2%,NN模式比例值的平均值远远小于TT模式和边界模式的比例值的平均值.因此,无论是内部类还是叶子类(或者根类),在TT模式下追踪的可能性都是最高的,其次是边界模式,而在NN模式下追踪的可能性远远小于在TT模式和边界模式的追踪的可能性.
表3 类在不同的模式下追踪到给定需求的可能性
Table 3 Possibility of classes tracing a given requirement in different code patterns

模式分类模式不同代码模式的比例值的平均值(eTour)不同代码模式的比例值的平均值(iTrust)TT模式 t→any→t(pure)65%N/A t→any→t(mixed)61%60% t→t→any(pure)83%0% t→t→any(mixed)36%0%边界模式 t→any→n(pure)36%38% t→any→n(mixed)16%33% n→any→t(pure)39%N/A n→any→t(mixed)21%5% t→n→any(pure)34%0% t→n→any(mixed)21%0% n→t→any(pure)10%0% n→t→any(mixed)12%0%NN模式 n→any→n0.5%0.7% n→n→any0.9%0%
5.3.2 实验2
本实验的主要目的验证我们的方法是否优于基线方法,我们选取仅使用LSI模型的方法(简称为LSI-ONLY)作为基线方法.而我们的方法是在LSI模型基础上引入了代码模式(简称为LSI-CP).对于相同的数据集,我们比较LSI-ONLY和LSI-CP的实验结果.图5是LSI-ONLY和LSI-CP的MAP值的比较.图6是LSI-ONLY和LSI-CP的precision-recall曲线的比较.表4、表5显示了相同的查全率点上LSI-CP相对于LSI-ONLY查准率的提高以及false positives(错误创建的追踪链)的减少.从实验结果可以得出以下结论:

图5 LSI-ONLY和LSI-CP的MAP值比较Fig.5 MAP comparison between LSI-ONLY and LSI-CP
1)从图5的MAP值来看,通过LSI-CP方法得到的类排序质量要优于LSI-ONLY.对eTour数据集使用LSI-CP比使用LSI-ONLY的MAP值提高了2.8%,对iTrust数据集使用LSI-CP比使用LSI-ONLY的MAP值提高了5%.
2)从图6和表4、表5可以看出LSI-CP在查准率上的提升最高达到了9.74%(在iTrust数据集70%查全率处).也就是说,如果LSI-LONY想要在iTrust数据集上达到70%的查全率,需要否决掉1671条false positive来获得200条正确的追踪链.而LSI-CP只需要否决掉779条false positive来获得200条正确的追踪链.这种优化在40%到80%的查全率区间上最明显(eTour数据集查准率平均提升4.26%,iTrust数据集查准率平均提升6.16%).
3)从图6和表4、表5还可以看出LSI-CP在查全率0%-40%的区间上几乎没有优化.这是因为我们选择候选列表的前3%类构成初始需求域,初始需求域中的类不进行重排序直接加新候选列表.初始需求域可以根据不同的项目设置不同的大小,寻找最优的初始需求域大小还需要进一步的研究.其次,LSI-CP在80%~100%区间上优化效果较弱,这表明排名靠后的类与初始需求域内的类存在较少的依赖关系, 代码模式不能有效的提高排名靠后的正确的追踪链中类的排名.目前,提升所有查全率区间上的查准率是业界公认的研究的难点[6,22],需要进一步的探索.

图6 LSI-ONLY和LSI-CP的precision-recall曲线比较Fig.6 Comparison of precision-recall curves between LSI-ONLY and LSI-CP
表4 eTour数据集在相同的查全率点提升的查准率与减少的false positives(对比LSI-CP和LSI-ONLY)
Table 4 eTour dataset Improved precision and reduced false positives at the same recall point(Comparative LSI-CP and LSI-ONLY)

eTourPrecisionFPRecall(10%)+0%-0Recall(30%)+0%-0Recall(50%)+4.95%-42Recall(70%)+6.68%-203Recall(90%)+0.94%-240
表5 iTrust数据集在相同的查全率点提升的查准率与减少的false positives(对比LSI-CP和LSI-ONLY)
Table 5 iTrust dataset Improved precision and reduced false positives at the same recall point(Comparative LSI-CP and LSI-ONLY)

iTrustPrecisionFPRecall(10%)+0%-0Recall(30%)+0%-0Recall(50%)+5.01%-103Recall(70%)+9.74%-892Recall(90%)+2.17%-2018
5.3.3 实验3
实验2已经证明在LSI模型基础上引入代码模式可以提高追踪生成的准确度,那么使用不同的IR技术会对实验结果造成什么影响?本实验目的有两个:第一,分析哪一种IR技术生成的追踪准确度更高.第二,探索我们的方法是否适用于不同的IR技术.我们使用LSI和QAP分别对数据集eTour进行分析,并比较试验结果.图7是QAP-ONLY(仅使用QAP)、QAP-CP(QAP引入代码模式)、LSI-ONLY、LSI-CP的MAP值的比较.图8是四种方法的precision-recall曲线的比较.从图可以看出:
1)LSI-ONLY比QAP-ONLY的MAP值高20.7%,LSI-CP比QAP-CP的MAP值高19%.在整个查全率区间上LSI-ONLY比QAP-ONLY的查准率平均高10.6%,LSI-CP比QAP-CP的查准率平均高9.68%.在本实验中,LSI的类的排序质量以及查准率远远高于QAP.这也说明了为什么现在主流工作都选择使用基于向量空间的模型进行追踪的自动生成.

图7 QAP-ONLY、QAP-CP、LSI-ONLY、LSI-CP的MAP值比较Fig.7 MAP Comparison of QAP-ONLY,QAP-CP,LSI-ONLY and LSI-CP

图8 QAP-ONLY、QAP-CP、LSI-ONLY、LSI-CP的precision-recall曲线的比较Fig.8 Comparison of the precision-recall curves of QAP-ONLY,QAP-CP,LSI-ONLY and LSI-CP
2)从图7和图8可以看出QAP-CP的MAP的值和查准率都要高于QAP-ONLY,这说明我们的方法也适用于QAP.我们可以推测我们的方法是不受IR技术类型限制的,具有良好的适用性.
6 总结和展望
本文提出将代码模式运用到追踪自动生成的研究中.在选定给定需求初始需求域的情况下,代码模式可以帮我们确定域外类与给定需求间的预期值,通过预期值对域外类进行重新排序.域内类和重排后的域外类构成新的候选列表并取代原来的候选列表.我们实现了一个原型工具进行验证,实验结果表明引入代码模式的IR追踪生成方法明显优于纯IR追踪生成方法,并且这种优化不受IR技术类型的影响.
在未来的工作中,我们希望可以找到最优的初始需求域大小.同时,我们也希望我们的方法和其它优化策略结合(如用户反馈),进一步提高IR追踪生成方法的准确性.
猜你喜欢
名家名作(2021年4期)2021-05-12
小学生学习指导(中年级)(2021年4期)2021-04-27
课堂内外(初中版)(2020年5期)2020-06-19
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
新高考·高二数学(2016年7期)2017-01-23
股市动态分析(2016年17期)2016-10-20
太空探索(2016年6期)2016-07-10
股市动态分析(2015年16期)2015-09-10
中学生数理化·中考版(2015年10期)2015-09-10
