
基于自适应遗传算法和BP神经网络的云服务器请求量预测模型*
2019-04-30 01:47:46胡晔明
通信技术 2019年4期
胡晔明,李 强
(杭州电子科技大学 计算机学院,浙江 杭州 310018)
0 引 言
大规模云服务平台将数据中心的资源以弹性云服务器的形式为租户提供云计算服务[1-2]。对于云服务器供应商而言,如何在需求不确定的情况下进行预测未来云服务器的负载情况,将是有效地配置服务器资源以提供高质量服务的关键所在[3]。云服务器上虚拟机请求量预测问题本质上是非线性时间序列拟合问题。一些传统的统计模型如自回归模型(Auto Regressive,AR)、移动平均模型(Moving Average,MA)、自回归移动平均(Auto Regressive and Moving Average,ARMA)目前已广泛应用于该问题中[4-5],而这些模型无法很好的捕捉预测问题中的非线性关系。王天泽[6]提出一种灰色预测模型动态预测云服务器负载,但该模型在波动性较大的情况下精准度欠佳。Dang Tran[7]提出了基于最小权重的指数平滑预测法(Exponential Smoothing Forecast-Based Weighted Least-Connection,ESBWLC),而这种方法预测精度较差。
本文提出了一种结合自适应遗传算法和BP(Back Propagation)神经网络的预测模型,该模型建立三层BP神经网络对未来请求量预测。为了避免BP神经网络陷入局部极小值,采用自适应遗传算法对神经网络的初始阈值和权值优化。在自适应遗传算法初期引入多子代交叉方法加快遗传算法的收敛速度。最后,进行了对比实验证明了算法应用在云服务器上虚拟机请求量预测问题的有效性。
1 问题定义
1.1 问题描述
服务商的云数据中心通常由大规模的物理服务器集群所组成,每台物理服务器上可以同时容纳多个可以共享该物理服务器上所有资源的虚拟机。租户在云平台虚拟机进行请求后都将在后台的数据库产生一条记录。获取云平台在过去一段时间内所有虚拟机请求记录,并构造数据特征训练预测模型,利用模型与历史记录预测下一个时间段可能到来的虚拟机请求分布。
1.2 数学定义
服务商提供的服务器有多种规格,任一规格服务器的历史请求数据可以表示为一组非负序列。假设自变量X表示某一规格服务器的历史请求数据,是由n个非负整数组成的序列。目标变量yn+1表示n+1期的预测值,通过目标函数f()可以得到X到yn+1的映射。
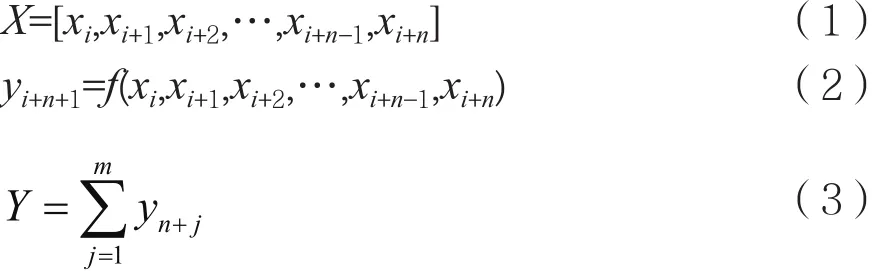
其中,xi表示第i期的云服务器请求数,n代表历史请求数据的总期数。Y表示未来m期的服务器数量总和。f()为目标函数,对于服务器请求数预测问题,目标函数即为预测模型。
2 预测模型设计
2.1 模型总体设计
如图1所示,将服务器请求日志记录划分为历史数据和预测数据,对于历史数据采用滑动窗口法[8]进行预处理组成训练数据集。根据Kolmogorov定理,已经证明三层BP神经网络可以任意精度逼近任何有理函数。因此方法使用三层BP神经网络来捕获未来数据与历史数据之间的潜在关系。本文使用自适应遗传算法初始化神经网络的权值和阈值。在自适应遗传算法初期引入多子代交叉方法加快遗传算法的收敛速度。
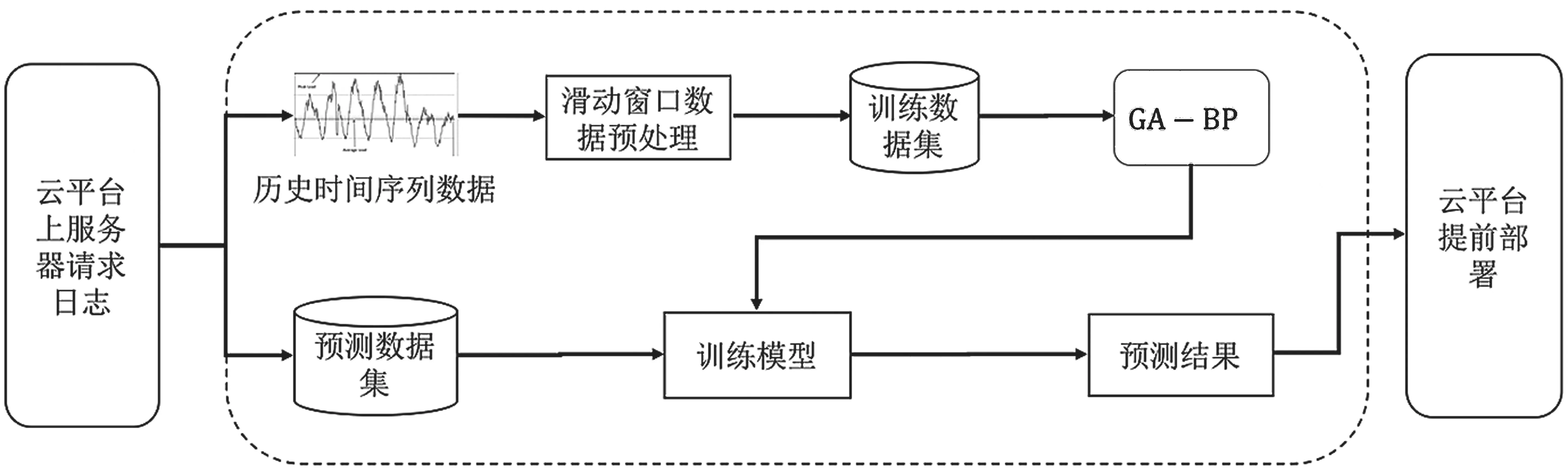
图1 预测模型总体设计图
2.2 训练样本预处理方法
如图2所示,滑动窗口法选择前几期的服务器数量作为输入来预测后一期的服务器数量。假设选择前o期的服务器数量去预测第o+1期的服务器数量,选择第2期至第o+1期的虚拟机数量去预测o+2期的虚拟机数量,以此类推组成训练数据集。
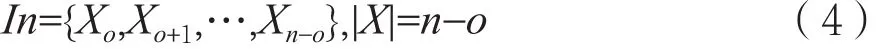
其中,每一项为为一个训练样本Xn-o={xn-o,xn-o+1,…,xn-1}训练样本的数量为n-o个。xn-o为第n-o时间段服务器的数量。目标数据集为Out={xo+1,xo+2,…,xn-1,xn}每一项与训练数据集对应。

图2 训练样本划分
2.3 神经网络训练基本思想
江露琪[9]等人实现了BP神经网络的网络流量预测模型。本文实现的一个3层BP网络结构如图3所示,以上一小节滑动窗口法处理好的训练数据集作为输入,目标数据集作为输出训练神经网络。训练过程由两部分组成:正向传播和反向传播。正向传播将输入样本在神经网络的权值、阀值以及激活函数的作用下传递到输出层。反向传播根据输出层的结果与目标值的误差对各层上的权值、阀值进行修正。以此反复迭代,直到输出层的结果与目标值的误差满足训练精度。
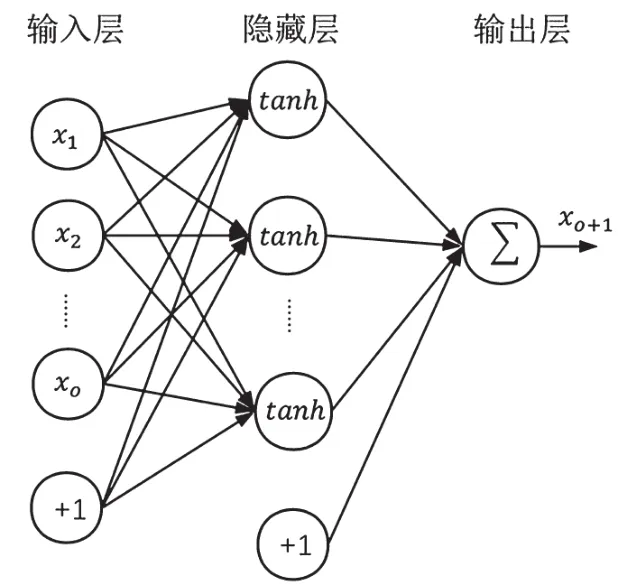
图3 三层BP神经网络
2.4 自适应遗传算法
采用自适应遗传算法初始化神经网络分为三个过程:(1)以神经网络权值、阈值进行编码,随机构造一组基因链;(2)确定适应度函数,计算组内每个基因链适应度;(3)对组内基因链进行选择,交叉和变异操作。
2.4.1 编码及适应度函数
编码方式采用实数编码,将网络的所有权值和阈值作为一个基因链。在遗传算法中以适应度函数来确定对基因链的评价。神经网络前向传播后的输出值与目标值的差值越小,此基因链中的神经网络权值与阀值越优。适应度函数采用目标值和输出值误差平方和的倒数:
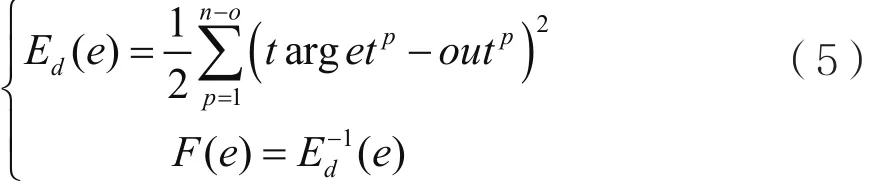
其中,n-o代表训练样本的个数,targetp代表第p个样本的目标值,outp表示第p个样本的输出值。F(e)表示基因链e的适应度函数,当误差Ed(e)越小,适应度函数越大。
2.4.2 进化操作
基因链的选择根据轮盘赌选择法,这是一种按概率选择的方法,适应度函数值越大的个体被选中的几率越高。
传统的遗传算法应用中,交叉概率Pc和变异概率Pm为常数值,选取过小,进化收敛速度慢;选取过大又会使算法过于随机。因此Srinivas[10]等人提出了自适应遗传算法(Adaptive Genetic Algorithm,AGA),根据适应度自适应地改变交叉、变异概率,使算法收敛速度提升,全局搜索能力增强。计算式子如下:
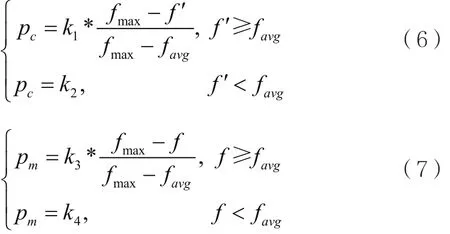
式中,Pc为交叉概率,f´为交叉操作的两个基因链中适应度较大的基因链的适应度。Pm为变异概率,f为参与变异的个体适应度,fmax为当前种群中最大的适应度,favg为当前种群的平均适应度,k1-k4均为[0,1]的常数。这种方法使个体适应度低于平均适应度时有恒定的交叉、变异概率;当f接近于总群中最大适应度时,交叉和变异的概率比较低。该方法在算法迭代后期确实可以保存优良个体,但是在算法迭代初期会导致适应度高的个体参与交叉、变异概率较低。
本文对算法迭代初期适应度较高的个体采用多子代交叉的方法。假设有两个基因链如图4所示,随机选择两个交叉点n1和n2,将基因链分为四段。按照单点交叉的方式的方式产生多子代:交换a1和a2产生子代 f1和 f2,f1=a1b2,f2=a2b1。同理交换 d1和d2产生子代f3和f4, f3=c1d2,f4=c2d1,这种方法使适应度较高的个体子代数量增加一倍。
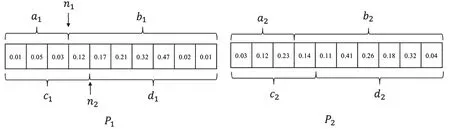
图4 多子代交叉操作
该方法在算法迭代初期可以加快收敛速度。从遗传学角度看,优秀的个体子代越多,越有利于放大优秀个体的可能。
基因变异为了使个体逼近最优解。本方法的基因链是实数编码,因此采用某一范围的随机数来替换原有的基因。首先随机地从[1,n-1]的空隙位置当中选取一整数位置k,将此位置变异为:

其中,emin和emax是基因链中基因的最小值和最大值。β为[0,1]内均匀分布的随机数。
2.5 AGA-BP算法流程
AGA-BP神经网络算法的操作步骤描述如下:
步骤1:确定以下参数:BP神经网络层数和每层的神经元数、种群规模、遗传算法的基因链编码方式、适应度计算方法。随机产生一组基因链进行遗传算法迭代。
步骤2:当迭代适应度函数值大于精度时,则将最优适应度的基因链解码后作为BP神经网络的初始权值和阈值。
步骤3:根据输入层和输出层神经元节点数确定BP神经网络隐含层节点数,假设训练样本为S(n-o)*o矩阵,目标为Go*1向量,因此BP神经网络的输入层节点个数为o,输出层节点个数为1,隐含层节点个数由经验公式确定,其中α为[1,10]之间的常数。
步骤4:对BP神经网络进行前向传播、反向传播直到拟合。
3 验证以及结果分析
3.1 实验数据以及评价指标
本文实验数据来自“2018年华为精英挑战赛”赛题中的样例数据。算法需要从输入数据提取服务器信息,包括服务器ID,服务器所属类别,以及对应服务器请求时间等。实验数据部分例子如表1所示。四种不同规格的服务器历史100天每天的访问量如图5所示,访问量序列呈非线性,其中flavor6、flavor5访问量波动性较大,flavor1、flavor3访问较为集中平缓。本文采用均方误差作为模型预测准确率的评价指标,其中公式为:
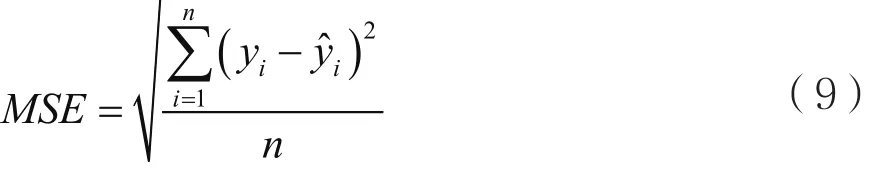
其中,yi为样本真实值,y^i为样本预测值,n为样本总数。本文采用灰色预测模型、BP、AGA-BP模型进行对比实验。
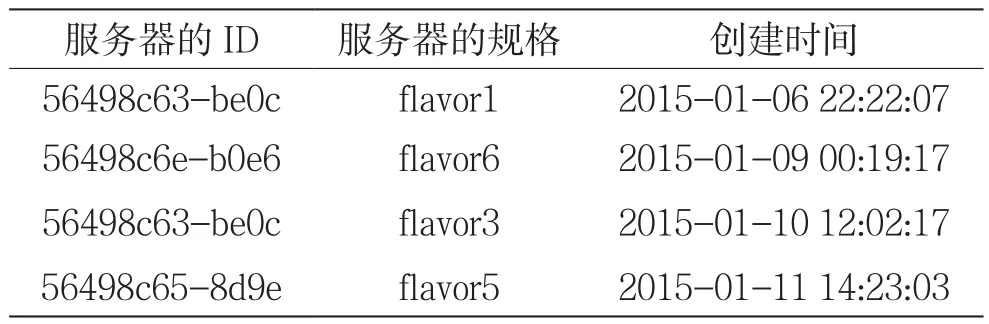
表1 用户请求虚拟机的历史数据举例
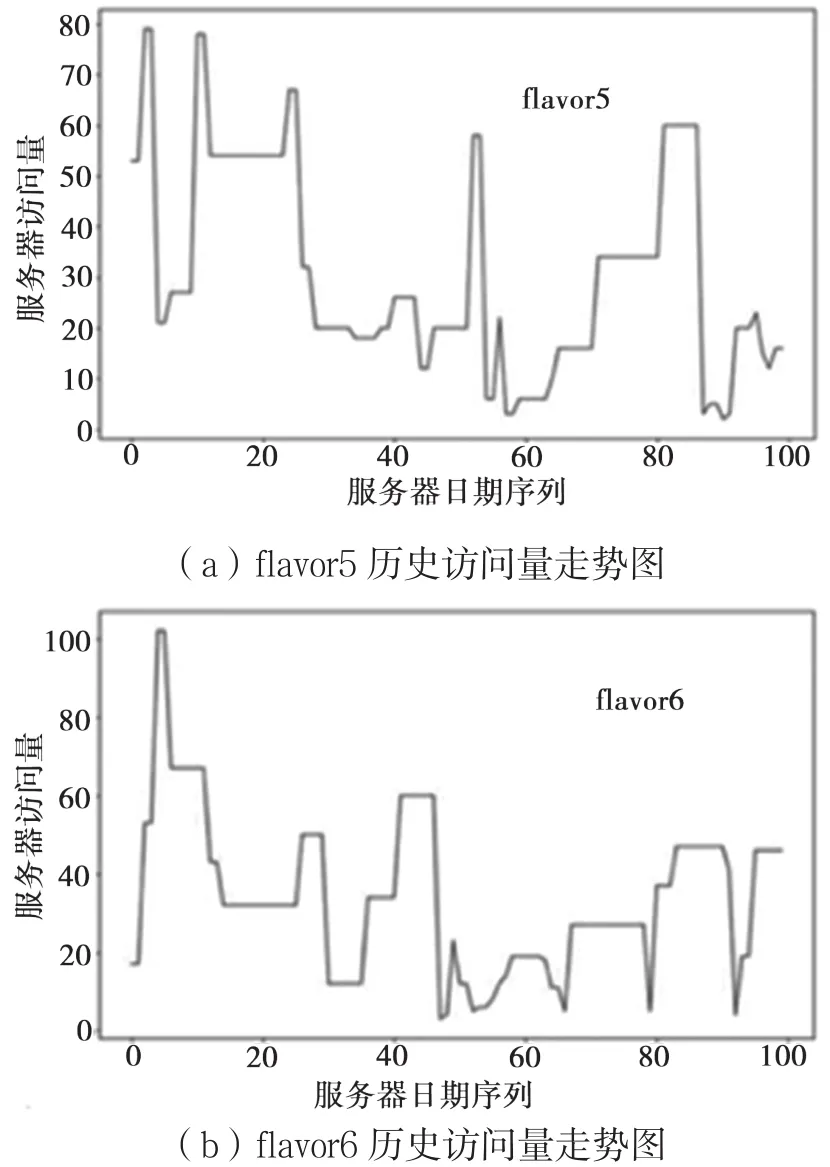
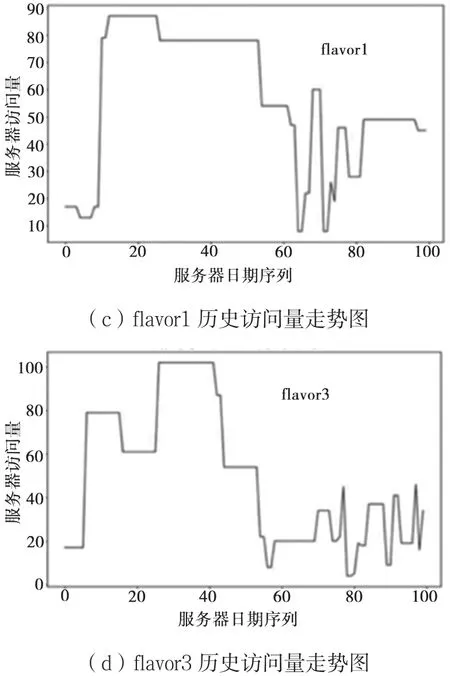
图5 各服务器访问量走势图
3.2 分析
四种服务器在灰色预测模型、BP、AGA-BP下的均方误差如图6所示。由于flavor6和flavor5访问量波动性较大,所有模型对于这一类服务器的预测误差比波动性小的服务器flavor1和flavor3要大。其中灰色预测模型效果尤为不好,该模型在波动性较大的情况下精度欠佳。AGA-BP比灰色预测模型、BP预测误差要更小,相比较灰色模型,AGA-BP更适用于波动性较大的情况;相比较BP而言,AGABP具有更好的全局搜索能力表2中可见4种服务器在灰色预测模型、BP、AGA-BP三种模型下的量化误差,其中AGA-BP模型相较于灰色预测模型至少有50%的误差提升,相较于BP模型4%~13%的提升。实验结果显示出AGA-BP神经网络在预测精度和应对波动性较大的情况有较强的优势。

表2 各服务器误差
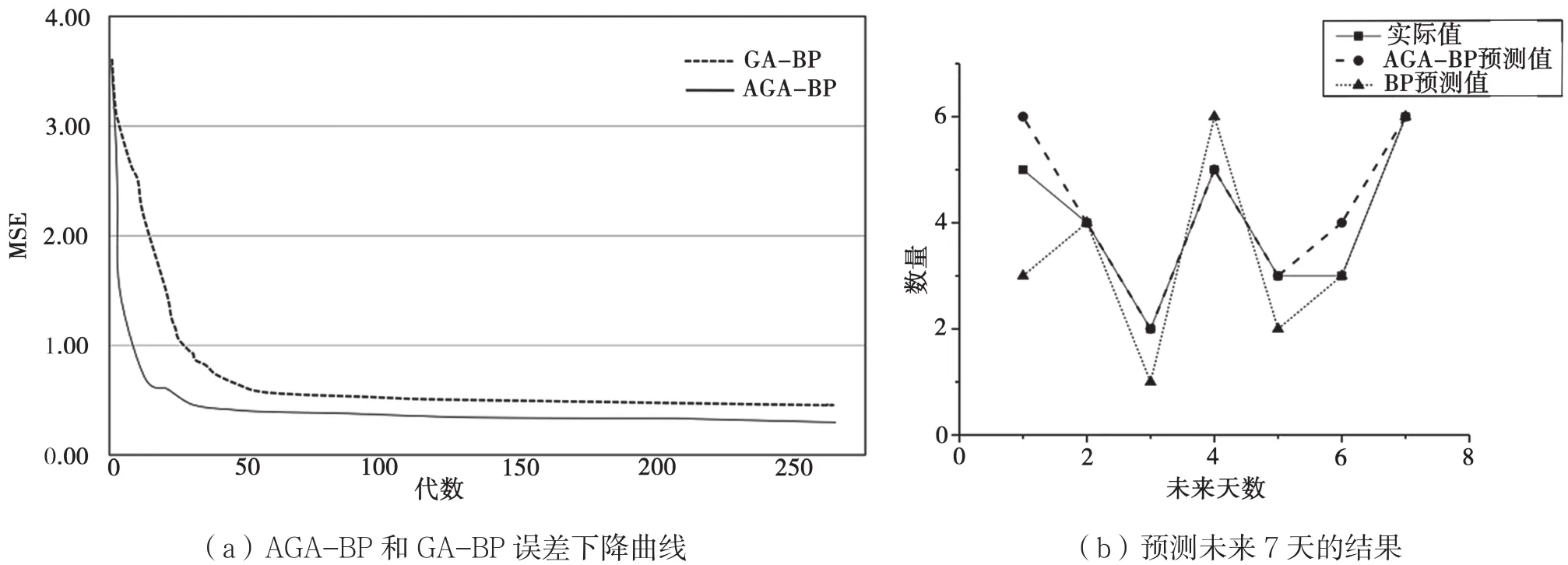
图7 算法误差下降曲线和预测结果
如图7(a)所示,比较AGA-BP与GA-BP在训练flavor5时的误差下降曲线,其中GA-BP中取交叉概率0.5,变异概率0.01。在训练初期迭代曲线几乎是重合的,GA-BP在之后的训练过程中误差平稳得下降,在迭代次数100次之后收敛。AGA-BP在训练初期误差下降速度比GA-BP快,因为在初期采用了多子代交叉方法,使适应度高的个体子代越多,加快了算法收敛速度。AGA-BP训练到接近GA-BP收敛误差时有一个明显的抖动,这是因为AGA-BP跳出局部极小值能力比较好,AGA-BP在50代时收敛,实验证明AGA-BP收敛速度更快,全局搜索能力更强。如图7(b)所示,用训练好的AGA-BP神经网络预测flavor5未来7天的访问数量,实际值总数为28,GA-BP预测值总数为30,预测精度约为92.8%,BP预测总数为23,预测精度为82.1%。
4 结 语
弹性云服务器的请求数据具有复杂的规律性,本文提出的AGA-BP神经网络在预测此类问题上具有一定的效果。在预测过程中,采用滑动窗口法对数据进行预处理,为了避免陷入局部最优解,采用遗传算法对BP神经网络进行优化。实验对灰色预测模型、BP神经网络AGA-BP神经网络均方误差以及GA-BP和AGA-BP的收敛进行对比。结果表明,AGA-BP网络在弹性云服务器请求量预测问题上比较有优势。
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02
初中生世界·八年级(2019年6期)2019-08-13 18:41:18
小学生导刊(低年级)(2016年6期)2016-07-02 22:17:33
中国塑料(2016年11期)2016-04-16 05:26:02
广西林业科学(2016年2期)2016-03-20 05:53:21
广西林业科学(2016年1期)2016-03-20 05:32:58
广西林业科学(2016年4期)2016-03-16 05:44:47
广西林业科学(2016年3期)2016-03-16 05:43:34
计算机工程(2015年8期)2015-07-03 12:19:54
振动、测试与诊断(2014年6期)2014-03-01 01:14:47
