
PMS-Sorting: A New Sorting Algorithm Based on Similarity
2019-04-29 03:21:36HongbinWangLiankeZhouGuodongZhaoNianbinWangJianguoSunYueZhengandLeiChen
Computers Materials&Continua 2019年4期
Hongbin Wang, Lianke Zhou, Guodong Zhao , , Nianbin Wang, Jianguo Sun,Yue Zheng and Lei Chen
Abstract: Borda sorting algorithm is a kind of improvement algorithm based on weighted position sorting algorithm, it is mainly suitable for the high duplication of search results, for the independent search results, the effect is not very good and the computing method of relative score in Borda sorting algorithm is according to the rule of the linear regressive, but position relationship cannot fully represent the correlation changes. aimed at this drawback, the new sorting algorithm is proposed in this paper,named PMS-Sorting algorithm, firstly the position score of the returned results is standardized processing, and the similarity retrieval word string with the query results is combined into the algorithm, the similarity calculation method is also improved, through the experiment, the improved algorithm is superior to traditional sorting algorithm.
Keywords: Meta search engine, result sorting, query similarity, Borda sorting algorithm,position relationship.
1 Introduction
Meta search engine [Zhang, Yu, Liao et al. (2004); Smyth and Boydell (2010)] is aimed to increase the precision and recall rate of in-dependent search engine, so there is no need to set data base for search and retrieval mechanism [Yamamoto, Fujii, Toyofuku et al.(2001); Yang (2005); Chen and Xu (2016)]. It achieve its search behavior by integrating a search engine that best meets user needs in accordance with the users’ interest or excellent degree of search engines, and its search interface is the same as the tradition-al search engines. For the search results returned, the Meta search engine will integrate a mechanism in accordance with results to remove-duplicate web pages and complete mix,then sort them according to a certain algorithm, finally return to user a process. Therefore,the ranking of results for the Meta search engine is of vital importance. There are a lot of researches for algorithm of ranking results nowadays. In this paper, the author studies and makes improvement on the classic Borda ranking algorithm. As a traditional ranking algorithm in a weighed way, Borda ranking algorithm is first applied in vote [Yang(2005); Yong and Zulin (2011)], which is a method for voters to choose candidates.Because of its good availability, it has been widely used.
2 Traditional borda sorting algorithm model
The traditional Borda algorithm [Cho, Brand, Bordawekar et al. (2015)] is a kind of improvement based on the weighted sorting algorithm. The algorithm is described as follows:
We define the set of tested search engines in the meta search engine as S={s1,s2,…,sn}.R={r1,r2,...,rm} is the set for all query results to query word q. Each query result rkis composed of four parts: URL, title, abstract, relevance score, which are represented by array assi_Url[k],si_Title[k],si_Abs[k],si_Score[k] on condition of k=1,2,… ,m,i=1,2,…,n.
The Borda sorting algorithm [Katsirelos, Walsh, Davies et al. (2011)] in meta search engine [Lawrence and Giles (1998)] is voted by the results returned by tested search engines. It establishes the preference relationship in position relationship among tested search engines according to the returned results after inputting query word [García-Lapresta and Martínez-Panero (2002)]. If the result is independent, we regard related score in other search engines as zero. Finally we put all the scores of each result to be summed to obtain the final score, and sort it in descending order. The mathematical model for the algorithm is as follows: the number of tested search engine is n, which means S={s1,s2,…,sn}; the set of query results is R={r1,r2,...,rm}. For Sk, we build matrix of preference relationship to Rkas Eq. (1).

when riis ranked before rjby k,=1; otherwise it is 0. The score for ri from Sk is shown in Eq. (2).

so the matrix of all query results from Rk(k=1,2,…,n) is shown in Eq. (3).

the final score is shown in Eq. (4).

sorting Borda(ri) according to relevance score of Borda and return to users.
3 PMS-sorting
The PMS-sorting algorithm based on the query result position, multiplicity and query similarity as is proposed in this paper, not only considers the relevancy and repeated read information of the query result position, but also combines the similarity of the query term and query result, which improves considerably the result of independent searching[Ping (2003)].
Besides, we plan to use global similarity for computing the similarity between query term and query result, because the methods of relevance algorithm of each independent search engine are not public, or are to be compared directly. In addition, on the problem of malpractice of the current global relevance algorithm, the similarity algorithm on the titles and abstracts of the return result would be more effective and accurate.
The research in the paper is about one user’s query string q, the score of the query result can be ultimately represented as a Borda score, and can be sorted and showed to users.We are going to make discussions on the algorithms in the following part.
3.1 The position standardization of the query result in search engine
Result list of independent search engines is sorted according to relevance of search words,therefore, the position of results can reflect its relevance with the query word enormously.Under common cases, the first ones of the results are most relevant to the users, making it very necessary to consider the position information of independent search engine. To make the position score more accurate, we improved the algorithm as follows.
N search engine members S1,S2,…,Snsearch a certain query word q, and m results are returned by search engine Sj, and the relevance of the result rklocated in k and the users query position is represented by pos(q,Sj,rk), which is shown in Eq. (5).

where pos(q,Sj,rk)∈[0,1], if the query result rk is the first result in the result collection of some search engine, then the score of pos(q,Sj,rk) is 1, which means that the first result of all member search engines are equally important. But if the numbers of results list documents that returned are different, the smaller is the number, the higher is the score. It means that having a good position in a list that has more results is more valuable than in a list that has fewer results. Thus the relationship between query results and query words is unified, i.e., the latter the position is, the smaller pos(q,Sj,rk) is, the fewer its relationship with the query word is, and the less the influence on the sorting.
3.2 The global similarity between query results and user query
Suppose query string q has n feature items t1,t2,…,tnand two documents d1,d2, if a certain feature occurred n times in d1while other feature items haven’t occurred, but in d2, n feature items have occurred once, in this case, although the word frequency is the same in the two documents, d2is obviously more relevant and has the most comprehensive covered features. For example, the query string “central People’s Government” divides q into three feature items, t1= “Central”,t2= “People’s”,t3=“Government” , if feature item t1= “Central” occurred many times in document one with other features not occurring, while all the three features occurred once in document two, apparently document two is more relevant to query string q. Under such cases,higher weight should be put when the query string matches the query word more comprehensively.
The matching degree between query string q and the rkabstract. If the feature term matches the abstract rather comprehensively, it should have higher weight. The matching level of feature item ti and abstract is represented by pg(ti,Sj,rk· abs), and the computing method is shown in Eq. (6).

in the above method, w(ti) represent the weight of each feature item given by query string.
The matching level of query string q and abstract can be represented as pg(ti,Sj,rk· abs),and the computing formula is shown in Eq. (7).

3.1.1 The computing of the similarity of feature item tiand rkabstract
Now let’s compute the similarity between every feature item of the query string and the result rk, then the similarity between each feature item tiand rk abstract can be represented by sim ti,Sj,rk,· abs , which is shown in Eq. (8).

in the above method, N(ti,abs) represents the times that feature item tiof the query string occurred in the query result rk, and length(abs) represents the length of query result rkabstract, position(ti,k) represents the k times that feature item tioccurred in the abstract. Then the computing method of the similarity between query string q and abstract is shown in Eq. (9).

3.1.2 Computing of the similarity of query string q and rk
If the similarity of query string q and abstract is represented as corr(q,Sj,rk.abs), the computing method is shown in Eq. (10).

and the query result rkcan be represented as Eq. (11).

the computing of the similarity of query string q and rkquery result. The computing can be more scientific by making weighted summation of the similarity of query string q and title rkand abstract. The two weights are represented as α and β, and the ultimate similarity as corr(q,Sj,rk), the formula is as Eq. (12).
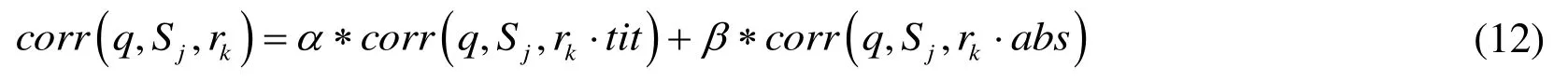
where α +β =1.
3.2 Computing of relevant score of the query result
The Borda sorting idea is the accumulated ultimate score of every result, whose query result is voted by search engine, and the score has considered the position of query result.In this paper, the ultimate relevant score of query result rk is represented as the above weighted summation of position relevance pos(q,Sj,rk) and the similarity corr(q,Sj,rk)between query word string and query result rk. The computing method is as Eq. (13).

where ω and θ are weight factors, and ω + θ =1.
3.3 Score computing of the ultimate borda of the query result
Through the above steps we have computed the relevant score of the query result rk, the score of the results searched by many member search engines is the sum of each one of them. Hence, for n member search engines, the Borda score of the query result rkis represented by Borda(q,Sj,rk) as Eq. (14).

in the end, descending the query result according to the score of Borda(q,Sj,rk), and display it to users.
4 Experiment results and analysis
Authors should discuss the results and how they can be interpreted in perspective of previous studies and of the working hypotheses. The findings and their implications should be discussed in the broadest context possible. Future research directions may also be highlighted.
4.1 Selection of dataset
To analyze and exam the algorithm with experiment, we build a prototype system of search engine, whose member search engines are Baidu, Yahoo, Bing and Sogou. We do experiments on representative retrieval topics, and each time of the search concludes the first 30 results of their member queries.
The query dataset uses the top 100 query words on the search ranking list of search engines in 2004. In this experiment, we use query words of different topics. In the end,we compare them concerning effect of algorithm.
4.2 Evaluation method
Common evaluation methods in search engine domain are recall, precision, system response time, etc. Because of the principle of element search engine, normally they all can get pretty high recall ratio, and the formula we use in this paper to evaluate the efficiency of algorithm by precision is demonstrated in Eq. (15).

4.3 Result and analyze
4.3.1 The influence on the algorithm by weight factors ω and θ
In the algorithm in the paper, the weight factors ω and θ influence the weight of position and similarity factors, hence their dereferencing have great influence on the algorithm. In the experiment, the dereferencing of ω vary from 0.1 to 0.9, and the variety of the average precision on different dereferencing is demonstrated in Fig. 1.

Figure 1: The relationship between the dereferencing (ω) and the average precision
As we can see from Fig. 1, when ω<0.4, the variety remains barely changed, but when the dereferencing is around 0.6, the precision reaches its highest point, and then in the downward trend. Hence, in the following experiment, the dereferencing of weight factor is ω=0.6, which means the great value of the result permutation position in the return results collection of its search engine.
4.3.2 Comparison between the algorithm in the paper and independent search engine
To verify the effectiveness of the algorithm in the paper, we will compare the element search engine NMSE of the algorithm with the average precision rate and recall rate of its element search engine. Different search engine will have different effect in accordance with different query subject, for example, among the search engines, the precision rate of searching “Ebola virus” of Baidu is 0.75, of Yahoo is 0.68, of Bing is 0.59, and of Sogou is 0.67. And when searching other words, we receive different results. In the following section, we will search with every independent search engine and the element search engine using the algorithm in the paper, and the effect of average value comparison is demonstrated in Fig. 2.

Figure 2: Average precision comparison
As we can see from Fig. 2, Baidu remains the leading role in Chinese searching, while the element search engine used the algorithm in the paper has higher average precision rate than Baidu when searching different subjects.
4.3.3 Comparison between the improved algorithm in the paper and classic element search engine sorting algorithm
The algorithm in the paper is improved based on the Borda sorting algorithm in element search engine. To verify the efficiency of the algorithm, we now choose several classic sorting algorithms as comparison object, which are Borda sorting algorithm, Round-Robin algorithm and Comb SUM algorithm.
The Round-Robin algorithm adopts the idea of polling, and its algorithm method is to first arrange the member search engines in a certain order, and when the search engine does results merging, get the first result of its member search engine, then the second, and so on. Comb SUM algorithm is a relevance score method, because local similarity of different search engines cannot be compared but to composed directly, we can get normalized relevance score by mapping the position of search result to [0,1]. Com SUM algorithm is to add all the relevance scores that occur in different search engines as the ultimate relevance score, and sorting in this order.
We now select query key words of different subjects from the dataset, and do search experiment for ten consecutive years under the Web environment, in the end, we extract the average value. The comparison effect of the four algorithms is demonstrated in Fig. 3.

Figure 3: Precision comparison diagrams between our algorithm and traditional algorithm
As we can see fromFig. 3, along with the increase of results, the precision is declining.The algorithm in the paper has better precision than traditional Borda sorting algorithm,and also higher than the other two traditional sorting algorithm, which means that the improved algorithm is very effective.
5 Conclusions
The improved algorithm has made the following improvements on the basis of traditional Borda sorting algorithm. (1) Normalize the sorting position of the query results, and replace the position score with position relevance. We cannot directly compare the query result position in the search engine, because the results returned from each search engine are few yet different, which is why it is not accurate to represent the position score by the quantity, whereas position relevance can better represent the relevance between position and query word. (2) Considering the current relevance algorithm is to first download the original document, then compute in unification the global similarity, which waste a lot of time and network resource thus cannot be accepted by users. According to research, the title and abstract of search results centralized the main information of the websites, so in the paper, we compute global relevance with information extracted from titles and abstracts returned by websites. (3) When computing the similarity with titles and abstracts, we combined the matching weight of query words and results, which makes the computing more accurate. However, there exist some shortcomings in time efficiency.Besides, it does not take individualized needs of different users into consideration.Element search engine will be more personalize, professionalize, and intellectualize,which is also a hotspot for future element search engine research.
Acknowledgement:This work was funded by the National Natural Science Foundation of China under Grant (No. 61772152 and No. 61502037), the Basic Research Project(Nos. JCKY2016206B001, JCKY2014206C002 and JCKY2017604C010), and the Technical Foundation Project (No. JSQB2017206C002).
 Computers Materials&Continua2019年4期
Computers Materials&Continua2019年4期
- Computers Materials&Continua的其它文章
- A Credit-Based Approach for Overcoming Free-Riding Behaviour in Peer-to-Peer Networks
- Image Augmentation-Based Food Recognition with Convolutional Neural Networks
- Artificial Neural Network Methods for the Solution of Second Order Boundary Value Problems
- DPIF: A Framework for Distinguishing Unintentional Quality Problems From Potential Shilling Attacks
- Color Image Steganalysis Based on Residuals of Channel Differences
- Mechanical Response and Energy Dissipation Analysis of Heat-Treated Granite Under Repeated Impact Loading