
基于深度学习模型的我国药品不良反应报告实体关系抽取研究
2019-04-27 01:42葛卫红张海霞
中国药科大学学报 2019年6期
陈 瑶,吴 红,葛卫红,张海霞,廖 俊,3*
(1中国药科大学理学院,南京 211198;2南京大学医学院附属鼓楼医院药学部,南京210008;3药物质量与安全预警教育部重点实验室(中国药科大学),南京 210009)
药品在使用过程中出现的不良反应(adverse drug reaction,ADR)常常会影响药物治疗效果甚至对病人造成生命威胁,对药品不良事件的收集及分析是药物安全监管与评价的重要工作内容[1]。常见的ADR数据来源有ADR报告、电子病历、医学文献、社交媒体等,其中不良反应监测中心所收集的ADR报告是药品上市后安全评价的主要参照之一(图1)。我国的ADR报告由结构化和非结构化两个部分组成[2],其中结构化部分包括病人的基本信息、患病信息、治疗信息、不良反应信息、评价信息等,非结构化部分主要是对药品不良反应发生过程的具体描述,通常包含病人的用药原因、用药信息以及药品不良反应信息等,监管人员通常会以非结构化部分的ADR过程描述为参考对上报的ADR进行评价,涉及大量人工阅读与判断过程,降低评价的效率且伴随一定的误差。
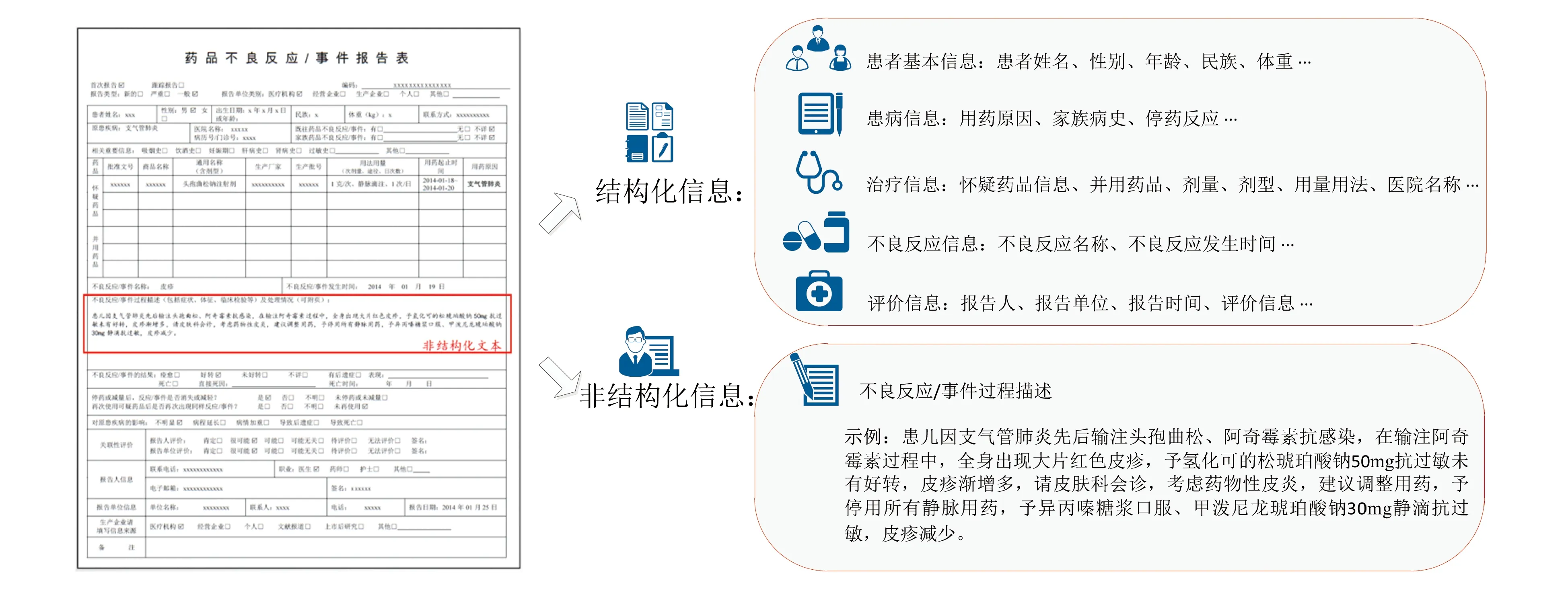
图1 药品不良反应/事件报告表信息分布图
现有针对ADR报告的研究主要集中于对其结构化部分中的药品种类、患者类别、ADR累及系统-器官等进行描述性统计分析,而非结构化文本的结构特征导致很难用统计方法等对其直接进行分析。对于案例中出现的多种药物及多种不良反应情况,结构化部分可能仅包含上报者认为主要相关的“药品-不良反应”对,而完整的信息则可以在非结构化文本中体现。实体关系抽取旨在确定句子中指定两个实体间的语义关系,是信息提取与自然语言处理的重要分支,将其运用于ADR过程描述中可实现“药品-不良反应”关系的确定,从而用于ADR的辅助评价并获得结构化部分所不能体现的多药联用等信息。
深度学习可以从数据样本中自动提取特征,减少人为特征构建的过程且对于大数据集的处理更具优势,近几年在图像分类、语音识别、自然语言处理等领域已经取得了很好的研究成果,常见的有递归神经网络、卷积神经网络、循环神经网络等结构,就其在自然文本等序列问题中的应用而言,循环神经网络结构具备一定的优势[3]。本文以一种名为双向门控循环单元(bidirectional gated recurrent unit,Bi-GRU)的循环神经网络模型为基础,通过添加注意力机制及字向量、分词向量等对模型进行调整,用于对中文ADR报告中ADR过程描述模块中的“药品-不良反应”关系进行自动抽取。所获得的“药品-不良反应”关系可以实现ADR报告的辅助评价,帮助评价人员快速获取报告中所有可能的药物与不良反应的关系,从而实现对结构化部分上报的信息进行综合考量;此外,所提取的信息一方面可用于特定药物与不良反应之间统计学关系的分析研究,另一方面也是ADR知识库构建的重要组成部分。
1 药品不良反应报告研究
1.1 不良反应报告关系提取
不同于英文关系抽取,中文关系抽取技术还不够成熟且面临诸多挑战。一方面,中文词与词之间无类似英文中的空格作为明显分割界限,因此中文自然语言处理任务中首先需要解决分词的问题,而特殊领域中的专业词汇、缩写等使得难以完全依靠分词工具实现准确的词切分;另一方面,中文开放性标注语料的缺乏也进一步限制了中文实体关系提取的研究[4]。就中文关系抽取的应用而言,李明耀等[5]使用依存分析从搜狗新闻语料库中提取人名、地名与机构名的关系;Luo等[6]则采用了与本研究类似的基于注意力机制的Bi-GRU模型对中文地质数据进行了关系抽取。医药领域的中文实体关系抽取主要集中于对电子病历中疾病、症状、治疗与检查等之间关系的研究,例如,马敬东等[7]采用自举及依存句法分析对中文电子病历中的“疾病/手术-时间”关系进行抽取;刘凯等[8]则利用半监督和卷积神经网络的方法提取了中文医药领域网站中的症状、检查、治疗等之间的关系。
目前针对药品不良反应关系抽取的研究主要在英文环境中进行,例如,研究人员分别从英文生物医学文献[9]、临床记录[10]、社交媒体[11]中进行了药品不良反应关系提取研究。而无论是中文还是英文的药品不良反应报告,均只集中于对其结构化部分的信息进行统计分析等工作,对于中文ADR报告中ADR过程描述的非结构化文本的研究还缺少标注语料与相关经验借鉴。
1.2 深度学习模型与注意力机制应用于药品不良反应报告分析
循环神经网络除了层与层之间的连接,在隐含层之间的节点之间也设立了连接,从而实现对目标对象之前的信息进行记忆,增强基于时间序列上的变化进行建模的能力[3],这一特点使得其在自然语言处理领域得到了广泛的应用。为解决循环神经网络(recurrent neural network,RNN)在处理大数据集时存在的梯度消失和梯度爆炸问题,长短期记忆模型(long short-term memory,LSTM)被提出[12],通过遗忘门、输入门和输出门这3个门实现对记忆单元中信息的交互,最终解决远距离依赖问题。GRU模型是LSTM模型的一个变体,在保留LSTM遗忘和更新机制的基础上将网络结构进一步简化,提高运算速率的同时减小了梯度弥散的风险[13]。此外,为了提高模型对上下文的学习能力,Graves[12]提出双向RNN的概念,这使得LSTM和GRU模型在机器翻译、语音识别、实体识别及实体关系抽取等序列问题中能够充分学习目标对象的前后信息从而获得较好的表现[14]。在实体关系识别应用中,Huang等[15]和Luo[16]使用LSTM分别从生物医学文献和临床纪录中提取“药物-药物”和“医疗事件-治疗/检查/医学事件”之间的关系;Kim等[17]使用的Bi-GRU模型,在SemEval-2010实体关系识别任务中取得了84.3%的F值。
注意力机制可以理解为从大量信息中选择性筛选出重要信息的过程,该过程通过权重值体现,在神经网络模型中则主要表现为权重向量,通过与字符向量或词向量相乘得到句子级的特征向量。自然语言处理领域中,注意力机制常与深度学习结合应用于机器翻译、文本概述、语音识别等,在关系识别的任务中常用来与RNN结合以提高模型准确率[14,17-18]。
2 基于注意力机制的Bi-GRU模型应用于药品不良反应报告分析
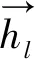
(1)
本研究在Bi-GRU结构的基础上引入注意力机制(attention),注意力机制通过计算注意力概率分布产生词或句子的权重向量,并通过此权重向量将GRU模型的每一个时间节点连接起来,从而加深输入层对输出层的影响,所获得的句子级特征向量最终用于关系分类。此外,为了充分利用中文语料中的字符特征及词特征[19],本研究使用Word2Vec[20]工具对数据进行字向量(character embedding)的预训练,同时利用分词工具jieba(https://github.com/fxsjy/jieba)对文本作分词处理,生成的分词特征向量联合预训练的字向量共同组成嵌入层(embedding layer)加入到网络模型中。模型框架结构见图2。

图2 基于注意力机制的Bi-GRU的不良反应描述关系提取模型框架图
3 基于“药品-不良反应”的关系提取模型的实验过程与结果分析
3.1 基于“药品-不良反应”的关系提取模型的语料介绍
ADR报告作为ADR研究最主要的来源之一,可以分为结构化和非结构化两个部分[2]。其中结构化部分可直接用于统计分析或信号挖掘等,但该部分数据通常以药物为单位进行记录,当同一案例中出现多药合用的情况时,一般仅上报其中认为主要相关的一条或多条分开上报,很难直接从这些独立报告之间发现多种药物与多种不良反应之间的关系情况。而非结构化部分的“ADR过程描述”模块则包含了ADR具体信息,例如病人的用药原因、使用药物名称、用药产生的ADR以及ADR的结果与处理情况,对于该模块的挖掘利用,能够在一定程度上弥补结构化数据中的信息缺失及信息孤立。例如,在案例“患儿因上呼吸道感染在我院静脉滴注5%葡萄糖注射液100 mL+头孢唑肟1.25 g,续滴5%葡萄糖注射液100 mL+喜炎平2 mL约5分钟后,患儿头部手部出现皮疹,立即通知医生,遵医嘱更换生理盐水100 mL续滴,输液结束后皮疹消退,自述无其他不适。”中,所对应的结构化数据只包含了其中“喜炎平-皮疹”的药物不良反应对,直接对这部分数据的分析将忽略“头孢唑肟”与“皮疹”之间的关系。
本文研究数据来自江苏省药品不良反应监测中心2010- 2016年不良反应报告中关于不良反应过程描述部分的自由文本,在总数约60万的数据中随机抽取其中的3万条进行人工标注。标注工作分为实体标注和实体关系标注两部分。
3.1.1 药品不良反应描述中的实体的标注 本文旨在研究药品不良反应报告中“药品-不良反应”关系对,因此仅对自由文本中的“药品”和“不良反应”进行标注,其中“药品”标注过程中将剂型与药品名称作为整体,“不良反应”的标注过程则主要参考国际医学字典MedDRA中关于不良事件的定义与分类,药品不良反应描述中的实体的标注规则及实例如表1。
3.1.2 药品不良反应描述中的实体关系的标注 在本文所使用的研究数据中,“药品-不良反应”之间的关系可归纳为“直接”“可能”“否认”和“后处理”4类,具体药品不良反应描述中的实体关系的标注规则如表2所示。
为提高标注效率,我们开发了实体及实体关系的标注工具(https://github.com/cpuchenyao/NER_RE_Annotation),实现案例的自动读取以及相应格式的标注结果输出。实体采用‘BIO’格式界定实体位置,其中‘B’表示实体开端字符,‘I’表示实体非开端位置字符,‘O’表示非实体字符,具体案例见表3。在不良反应监管人员指导下,10名药学专业背景的学生经过培训,共花费一个月的时间完成了数据的四轮标注工作,包括一轮预标注、两轮正式标注以及一轮标注修正,在除去无效数据(未提及具体药品名称或不良反应名称的案例)后得到24 137条有效不良反应过程描述案例,总共包含116 321例“药品-不良反应”关系(同一案例中可能同时包含多组“药品-不良反应”关系)。
表1 药品不良反应描述中的实体的标注规则及实例
表2 药品不良反应描述中的实体关系的标注规则及实例关系类别

定 义实 例标注结果直接明确表述两者之间的直接相关性患者输液头孢曲松后出现全身皮疹,停药后皮疹消失头孢曲松--皮疹→直接可能联合用药时,无法确定必然关系给予患者奥美拉唑、克拉霉素同服,用药后出现恶心症状奥美拉唑--恶心→可能;克拉霉素--恶心→可能否认明确表述两者之间无直接相关性患者予参麦注射液5 min后出现寒战,无发热参麦注射液--寒战→直接;参麦注射液--发热→否认后处理针对不良反应采取的用药措施患者输液后出现皮疹,停药后予非拉更肌注,皮疹消失非拉更--皮疹→后处理
表3 ‘BIO’格式的药品不良反应报告中药品不良反应描述的实体标注案例

案 例BIO 标注患者因咳嗽、咳痰来医院诊治,给予阿奇霉素静滴,在静滴过程中患者出现寒颤患(O)者(O)因(O)咳(O)嗽(O)来(O)医(O)院(O)诊(O)治(O),(O)给(O)予(O)阿(B-Drug)奇(I-Drug)霉(I-Drug)素(I-Drug)静(O)滴(O),(O)在(O)静(O)滴(O)过(O)程(O)中(O)患(O)者(O)出(O)现(O)寒(B-ADR)颤(I-ADR)
在表3的案例中,被标记的“药品-不良反应”实体有“阿奇霉素”和“寒颤”,标记的“药品-不良反应”关系组有“阿奇霉素-寒颤:可能”。
3.2 基于“药品-不良反应”的关系提取模型的超参数设置
本研究参考基于文献[14,21]改进的中文关系识别开源代码(https://github.com/crownpku/Information-Extraction-Chinese/tree/master/RE_BGRU_2ATT),采用TensorFlow框架构建基于注意力机制的Bi-GRU网络,其中20维分词特征向量和100维的预训练字向量共同构成120维的嵌入层,初始学习率为0.002,在Bi-GRU隐藏层中的单元数为230,为了防止Bi-GRU模型训练过程中出现过拟合,在网络中设置了dropout为0.5。模型训练了13个epoch后,药品不良反应报告中不良反应过程描述的关系识别效果最佳。实验采用Python编程,运行服务器配置为Intel Xeon Gold 6136 CPU、NVIDIA Tesla V100 GPU及768 GB内存,软件使用Linux操作系统。
3.3 实验结果及分析
实体关系提取任务中常采用的模型评价指标有准确率(Precision,P)和召回率(Recall,R),本研究选取综合考虑准确率和召回率的F值作为模型评价指标,其计算如公式(2)~(4)所示,其中TP表示将正例样本预测为正例的样本数量,FP表示将负例样本预测为正例的样本数量,FN表示将负例样本预测为负例的样本数量。
(2)
(3)
(4)
在“3.2”所示的参数设置下,将标注语料按8∶2的比例随机划分为训练集与测试集,最终取得四种类型关系以及总体的提取结果如表4所示。模型取得了87.52%的整体F值,但是可以发现各类型关系之间的抽取效果存在较大差异,“直接”和“后处理”两类关系的抽取效果要明显好于另外两类关系,这可能与样本中关系种类分布的不均匀有关。在所有116 321条标注样本中,各类型关系样本所占比例为:直接(55.9%)、可能(2.9%)、否认(3.5%)、后处理(37.7%),其中“可能”与“否认”关系所占比例较低。本研究建立在案例文本语义的基础上,即在案例中不良反应出现在某药物使用之后,只要未明确表示两者之间是可能相关或不相关,则均认为其关系为“直接”,未加入医学知识或人为经验进行判断。“可能”与“否认”两类关系主要出现在多药联用的案例中,而就上报的药品不良事件而言,大多数在不良反应过程描述中未进行排除分析,这就导致即使是在多药联用的案例中,“可能”和“否认”两类关系总共也仅占了不足15%,“直接”和“后处理”两类关系在样本量上的优势也促使了其在抽取效果上表现更优。
表4 药品不良反应报告中药品与不良反应间各类关系提取的准确率、召回率及F值
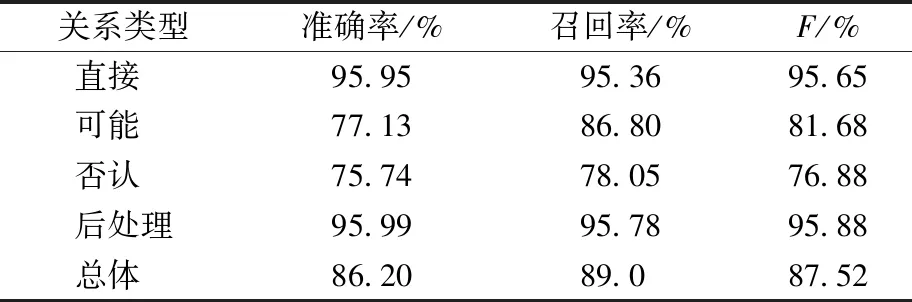
关系类型准确率/%召回率/%F/%直接 95.9595.3695.65可能 77.1386.8081.68否认 75.7478.0576.88后处理95.9995.7895.88总体 86.2089.087.52
4 小 结
本研究对中文ADR报告中的关于ADR过程描述的自由文本部分进行标注并制定相应的标注规则与标注工具,通过引入注意力机制及字向量与分词向量的Bi-GRU模型对标注好的数据进行学习,智能分类不良反应描述中所出现的“药品”实体及“不良反应”实体之间的关系,实现对句子中包含的“药品-不良反应”实体关系自动抽取并取得了整体较好的抽取效果。从生物医学领域的科研文章、医疗记录等文本中提取生物医学实体及其之间的关系,已经成为当前生物医药领域的研究热点,对生物医学研究具有重要应用价值。基于深度学习的药品不良反应报告实体关系抽取模型具有普适性,同样适用于生物医学中药品实体与疾病间关系抽取、对临床文本等碎片化的内容进行关系抽取以及抽取生物医学文献中化学品蛋白质之间的关系,将大大减轻使用传统方法所需时间且获得更好的关系抽取效果。针对样本分布不均导致的误差,除了采取人工标注的方法,还可以在已有标注数据集的基础上,通过半监督学习等方法自动获取标签,从而实现对训练集的进一步扩充,改善因样本量不足导致的“可能”和“否认”两类关系抽取效果较差的情况。对于ADR报告中“药品-不良反应”关系的自动抽取,可用于辅助监管人员对ADR的评价工作,同时能够挖掘出结构化数据中所忽略的信息,发现更多潜在的不良反应信息。将模型运用于电子病历或其他相关文本中自动提取ADR相关信息从而对ADR报告所包含的信息作进一步补充有待进一步的研究。
猜你喜欢
中国合理用药探索(2022年1期)2022-11-26
军民两用技术与产品(2021年2期)2021-04-13
云南教育·小学教师(2021年12期)2021-03-23
父母必读(2021年3期)2021-02-04
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
小学生优秀作文(低年级)(2018年6期)2018-05-19
消费导刊(2017年20期)2018-01-03
