
图像超分辨率卷积神经网络加速算法*
2019-04-26 05:20张晓晖胡清平
国防科技大学学报 2019年2期
刘 超,张晓晖,胡清平
(1. 海军工程大学 兵器工程学院, 湖北 武汉 430033;2. 军事科学院 系统工程研究院, 北京 100044)
单帧图像超分辨率重建旨在从给定的低分辨率图像中重建出高分辨率图像,该技术能够提供视觉效果更好的图像并提供更多的图像信息[1]。最近的超分辨率算法主要是基于深度学习的方法,此类方法利用先验知识学习低分辨率和高分辨率图像之间的映射关系,可以显著增强图像细节。2014年,香港中文大学Dong等成功地将深度学习引入到图像超分辨率重建问题中,提出基于卷积神经网络的图像超分辨率重建算法(Super Resolution Convolution Neural Network, SRCNN)取得了较好的效果[2]。
随后,基于深度学习的方法被大量改进,2016年,Kim等针对SRCNN方法感受野较小的问题,提出使用更多的卷积层来增加网络感受野,同时为了减少网络参数,引入递归神经网络,提出的深度递归卷积网络(Deeply-Recursive Convolutional Network,DRCN)方法得到的效果比SRCNN有了较大提高[3]。在SRCNN和DRCN中,低分辨率图像一般先通过上采样插值扩充到与高分辨率图像同样的大小,再作为网络输入,这就意味着卷积操作是在较高的分辨率上进行,相比于在低分辨率图像上计算,会降低效率,于是SHI等提出了一种在低分辨率图像上直接计算卷积得到高分辨率图像的高效率高效亚像素卷积网络(Efficient Sub-Pixel Convolutional Neural network,ESPCN)方法[4]。上述方法对于大尺度放大因子重建会存在图像模糊问题, Ledig等将生成对抗网络引入超分辨率重建中,提出了一种基于生成对抗网络的超分辨率重建超分辨率重建生成对抗网络(Super-Resolution Generative Adversarial Network,SRGAN)方法,该方法能够提高大尺度放大因子的重建质量[5]。为了提高运行速度,2017年,Dong等通过引入1×1卷积和转置卷积对经典的SRCNN进行了改进,提出了一种快速超分辨率卷积神经网络(Fast Super-Resolution Convolutional Neural Network,FSRCNN)模型,取得了很好的加速和复原效果,但模型参数冗余,难以进行嵌入式部署[6]。2017年,武汉大学肖进胜等通过分析SRCNN卷积核尺寸和数量,提出了一种改进的SRCNN,重建效果得到了一定的提高,但模型参数大量增加[7]。
虽然目前这些模型取得了较好的效果,但由于模型参数冗余,计算量依旧很大,难以实时运行和进行嵌入式部署。
通过深入分析当前超分辨率重建网络结构,发现限制其运行速度主要有以下三个方面:首先,作为预处理步骤,大部分基于深度学习的方法需要使用双线性插值将原始低分辨率图像上采样到期望的大小,以形成输入。因此,模型的计算复杂度随着高分辨率图像(而不是原始低分辨率图像)的空间尺寸二次增长。对于放大因子n,插值的低分辨率图像的卷积计算成本是原始低分辨率图像计算成本的n2倍。如果直接从原始低分辨率图像学习网络,则计算速度快n2倍。其次,目前,模型参数主要来源于卷积操作,标准卷积需要同时进行特征提取和特征融合的工作,从参数利用角度来讲,效率低且效果不佳。相反,2017年,谷歌提出的深度可分离卷积(depthwise separable convolution)把两步分离开来,从深度方向把不同的通道之间相互独立开,先进行特征提取,再进行特征融合,这种方式可以充分利用模型参数进行表示学习,在使用更少参数的情况下取得更好的效果[8]。因此,利用深度可分离卷积替换标准卷积能够降低模型计算量,同时提升模型表达能力。再次,大的卷积核会导致模型参数和计算量的暴增(参数数量随着卷积核尺寸二次增长),但是为了获取更大的感受野,部分模型采用大尺寸卷积核[9]。然而多个3×3卷积核级联也可以获得与对应大尺寸卷积核同样大小的有效感受野,并且包含了更多的非线性,同时减少了网络参数(如,利用2个3×3卷积核的组合比1个5×5卷积核的效果更佳,同时参数量(3×3×2+1<5×5×1+1)被降低)。
根据上述分析,本文设计了一种简洁高效的网络结构。
1 基于卷积神经网络的图像快速超分辨率重建模型
针对当前超分辨率模型参数较多、计算量较大等问题,本文设计了一种轻量级的超分辨率卷积神经网络结构(Light Super-Resolution Convolutional Neural Network, LSRCNN),如图1所示。
整个重建模型主要包含特征提取、非线性映射和重建三层网络单元结构:特征提取网络单元结构紧跟在输入层后面,利用常规卷积提取大量低分辨率特征;非线性映射网络单元结构采用深度可分离卷积进行非线性映射,并引入1×1卷积进行维度压缩和扩展;重建网络单元结构通过子像素卷积层进行上采样操作。为了便于理解,将常规卷积层表示为Conv(fi,ni,ci),深度可分离卷积层表示为SepConv(fi,ni,ci),子像素卷积层表示为SubConv(fi,ni,ci),其中变量fi、ni、ci分别表示卷积核的大小、数量的和输入通道数量(当前层的输入通道数量和上一层的卷积核数量表示同一量,即ci=ni-1,i为层数)。
由于整个网络包含几十个变量,不可能对其进行逐一研究,因此本文提前给不敏感变量分配一个合理的值,并保持敏感变量(当变量的轻微变化可能显著影响性能时,称为变量敏感)未设置。下面将对不同网络单元结构进行详细设计,并确定对应结构的敏感变量和非敏感变量。

图1 基于卷积神经网络的图像快速超分辨率重建模型Fig.1 Image fast super-resolution reconstruction model based on convolution neural network
1.1 特征提取网络单元
大部分基于神经网络的超分辨率模型的特征提取网络单元采用1个或多个卷积核进行低分辨率特征提取。与之相似,本文的特征提取网络单元采用1个常规卷积进行低分辨率特征提取,但在输入图像层面有所不同的是,LSRCNN在不进行插值的情况下对原始低分辨率图像进行特征提取。设低分辨率输入表示为Y,通过与第一组卷积核进行卷积,将每个输入图像块表示为高维特征向量。由前面分析可知,卷积核尺寸的增加会引起参数的二次增长,由于3×3已经能够足够覆盖图像特征, 因此设置f1=3;对于输入通道数量,根据文献[2]的分析,在YCBCR空间中,利用亮度通道进行模型训练能够取得更好的效果,因此设置c1=1;低分辨率图像的特征向量(底层特征)对最终结果很关键,由于卷积核数量n1表示了低分辨率特征通道数量,可将其定义为第一个敏感变量d,因此,第一层可以表示为Conv(3,d,1),图2为特征提取单元输出的低分辨率特征。
1.2 非线性映射网络单元
非线性映射是影响超分辨率重建性能最重要的部分,一般紧跟在特征提取步骤后面,用于将高维低分辨率特征直接映射到高分辨率特征空间。然而,由于低分辨率特征维度d通常非常大,映射步骤的计算复杂度相当高,因此减少非线性映射网络单元模型参数成为压缩超分辨率模型的关键。
谷歌的Inception结构通过应用1×1层来节省计算成本[10],基于同样的考虑,本文在进行特征映射前,通过引入1×1层来减少低分辨率特征维度d。因此设置卷积核大小f2=1,通过采用较少的卷积核数量n2=s≪d使低分辨率特征尺寸从d减小到s。其中,s是确定收缩水平的第二个敏感变量,因此第二层可以表示为Conv(1,s,d)。通过该策略可以大量减少参数数量。
由上述分析可知,相对于常规卷积,深度可分离卷积能够在减少参数的同时,提高映射能力。为了充分利用其优势,本文非线性映射单元除了用于通道压缩和膨胀的1×1卷积,其余均采用深度可分离卷积。通过该策略,可以大大减少参数数量,同时增加网络的非线性能力。作为性能和网络规模之间的折中,本文采用中等滤波器尺寸f3=3,为了保持网络性能不下降,使用多个3×3层来替代单个宽度。因此,映射层数量m是另一个敏感变量,这里所有的映射层采用相同的滤波器数量n3=s。那么非线性映射部分可以表示为m×SepConv(3,s,s)。
由于映射图层的卷积核数量n3=s比较小,如果直接从这些低维特征生成高分辨率图像,则最终的恢复质量将会很差。因此,需要在映射部分之后添加一个扩展层,以扩展高分辨率的特征维度,为了保持与收缩层的一致性,本文还采用1×1卷积,其数量与低分辨率特征提取层的数量相同,则扩展层可表示为Conv(1,d,s)。
1.3 重建网络单元
重建网络单元主要对非线性映射层获取的特征进行上采样和聚合,可采用双三次或双线性插值、上池化+卷积方式和转置卷积等方式。但双三次或双线性插值内核固定,不能够很好地恢复细节,转置卷积虽然可以学习一组输入特征图的上采样内核,但学习过程中需要补零操作,导致图像边缘存在失真。2016年,文献[4]提出了一种全新的上采样方式——子像素卷积层(sub-pixel convolution),该方式能够减弱转置卷积补零操作带来的影响,并减小运算量。因此,本文在网络末端引入子像素卷积层。

图2 特征提取单元的输出特征Fig.2 Output feature of the feature extraction unit
子像素卷积层的实质是,通过在常规卷积层后面添加相位移层改变图像尺寸,在利用其进行上采样的过程中,插值函数被隐含地包含在前面的卷积层中,可以被自动学习。对于放大因子为k=r的网络,子像素卷积层的卷积核数量应该设置为r2,然后将每个像素的r2个通道重新排列成一个r×r区域,对应高分辨率图像中的一个r×r大小的子块,从而大小为r2×H×W的特征图像被重新排列成1×rH×rW大小的高分辨率图像。设放大因子为r,则n5=r2;子像素卷积的卷积部分在低分辨率图像上进行,因此可采用较小尺寸的卷积,这里为了尽量压缩模型参数,设置f5=1,那么子像素卷积层可以表示为SubConv(r2,1,d)。
1.4 网络总体结构和性能分析
将上述三部分连接起来,形成一个完整的LSRCNN网络Conv(3,d,1)-Conv(1,s,d)-m×SepConv(3,s,s)-Conv(1,d,s)-SubConv(r2,1,d),这里每个卷积后面都跟有ReLU激活函数。控制网络参数和速度的三个敏感变量分别为低分辨率特征维度d、非线性映射单元深度可分离卷积数量s以及映射深度m。为简单起见,本文将LSRCNN网络称为LSRCNN(d,s,m)。参数数量(不考虑偏置的情况下)为:18d+2sd+m(9s+s2),设SLR为低分辨率图像大小,则计算复杂度为:
O{[18d+2sd+m(9s+s2)]SLR}
(1)
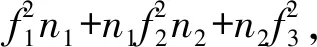
(2)
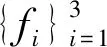
本文对LSRCNN(48,16,1)和SRCNN进行比较,通过上式计算可知,LSRCNN(48,16,1)的参数量为2800,SRCNN参数量为8032,其参数量仅有SRCNN的35%;对于放大因子为3的网络,提高运算速度8032/2800×32=25.8倍。值得注意的是,这种加速并不以降低性能为代价。相反,LSRCNN(48,16,1)性能在Set5数据集上为32.53 dB,优于SRCNN的0.17 dB。
1.5 损失函数
本文采用均方误差(Mean Square Error, MSE)作为损失函数,优化目标表示为:
(3)
其中,Yi和Xi是训练数据中的第i个低分辨率和高分辨率子图像对,F(Yi;θ)是具有参数θ的Yi的网络输出。网络通过最小化估计Y和真实高分辨率图像块G之间的误差找到最优参数θ=[Wj,Bj],对所有参数使用标准反向传播的随机梯度下降进行优化。
2 实验结果与分析
2.1 实验细节
数据集:91数据集具有良好的质量,被广泛用作基于学习的超分辨率重建方法的训练集[11],在实验中本文采用91图像数据集作为训练数据集。为了更好地和其他模型结果进行比较,没有采用数据增强技术。使用Set5[12]和Set14[13]数据集作为测试数据集。
训练样本:为了生成训练数据,本文首先用所需的放大因子k对原始训练图像进行采样,以形成低分辨率图像(由于不同语言的Resize函数内部实现机制有所差异,为了和其他模型比较,这里的采样操作采用MATLAB中的Resize函数)。然后将低分辨率训练图像裁剪成具有步幅l的一组尺寸为fsub×fsub的子图像。相应的高分辨率子图像(尺寸为kfsub×kfsub)也从高分辨率图像中裁剪出来。这些低分辨率/高分辨率(Low Resolution/High Resolution, LR / HR)子图像对是基本训练数据。
对于填充问题,为了确保提取的低分辨率特征轮廓清晰,对特征提取层不进行填充。实验中发现非线性映射层是否填充对结果影响不大,这里为了保证映射层输入输出尺寸相同,采用零填充,由于卷积核尺寸均为3,填充尺寸设置为P=1,最终网络输出尺寸为k(fsub-2)×k(fsub-2),而不是kfsub×kfsub。因此,需要在高分辨率图像上裁剪2k边界像素。最后,对于典型的放大因子3,本文将LR / HR子图像的大小设置为18×18/48×48。
训练参数:优化算法采用学习率可以自适应优化的Adam算法[14],初始学习率lr=0.001;权重初始化采用xavier初始化方法[15];Batchsize设置为32;周期数设置为80。
训练环境:训练过程均采用Keras库实现[16],训练平台采用CPU为 intel i7 4710MQ,GPU为NVIDIA GTX 860,内存为16 G的笔记本电脑。
2.2 不同敏感参数研究
为了测试LSRCNN结构的属性,本文设计了一组包含三个敏感变量的控制实验(即低分辨率特征维度d、非线性映射单元深度可分离卷积数量s以及映射深度m)。这里分别设置d=48, 64;s=16, 24和m=1, 2,因此总共进行了不同组合的12次实验。
这些实验在Set5数据集上的平均PSNR值如表1所示。本文分别在水平和垂直方向上分析实验结果,首先固定d和m,分析s对模型性能的影响,可以看到,随着s尺寸的增大,网络具有更好的性能。这种趋势也可以从图3(a)所示的收敛曲线观察到。但是当网络参数冗余,s的增加并不能提高性能,甚至会引发过拟合(见表1中第四行s的变化规律)。其次固定s,并检查d和m的影响,通常更好的结果需要更多的参数,但是更多的参数可能引起网络过拟合,并不能保证更好的结果(见表1中第2列的变化规律)。这种趋势也反映在图3(b)中,可以看到网络最后几乎汇聚到一起。从所有的结果中,能够找到性能和参数之间的最佳平衡LSRCNN(48,24,2),在适度参数情况下,获得了最好的效果。由于选择的batchsize比较小,因此收敛曲线会存在比较明显的跳跃。

表1 不同敏感参数在Set5测试集上的PSNR比较Tab.1 Comparison of PSNR for different sensitive parameters in Set5 test set

(a) 固定d=48,m=1,改变s (a) Fixed d=48, m=1, change s
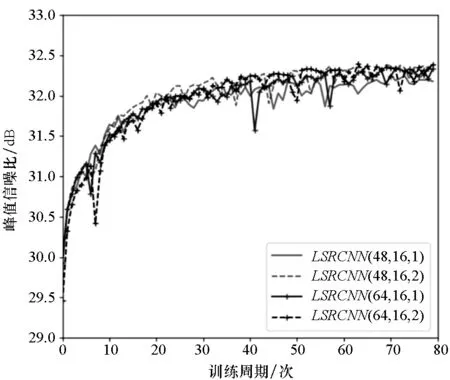
(b) 固定s=24,改变d和m (b) Fixed s=24, change d and m图3 不同敏感参数的PSNR收敛曲线Fig.3 PSNR convergence curve of different sensitive parameters
2.3 与其他方法比较
本文将提出的方法与传统的锚定邻域回归方法A+[17]以及三种基于外部数据库学习的超分辨率重建算法进行比较,即SRCNN[2]、改进的SRCNN[7]、FSRCNN-s[6]方法。A+方法的实现基于它们发布的源代码,其余三种基于深度学习的方法根据文献内容在Keras框架上进行了编写,为了对恢复质量进行比较,所有模型都对没有增强的91数据集图像进行了训练,因此结果可能与对照论文略有不同。本文选择了两个代表性的LSRCNN模型LSRCNN(48,16,1)(简写为LSRCNN-s)和LSRCNN(48,24,2)(简写为LSRCNN)。所有模型的运行时间通过NIVIDIA GTX 860 GPU上的Python进行测试。表2列出了放大因子为3的定量结果(PSNR、模型参数和测试时间)。首先,分析测试时间,可以看到,提出的LSRCNN是最快的方法,比改进的SRCNN至少快15倍(在GPU上测试时间),LSRCNN-s最快可以达到50帧/s的处理速度。其次,LSRCNN也具有更少的参数,相比于动辄具有几万甚至几十万参数的模型,LSRCNN-s仅有2800个参数,按照32 bit的精度进行存储,只需要10 KB空间,便可以满足嵌入式部署。最后,LSRCNN在具有更少参数的情况下,PSNR依旧优于A+、SRCNN、改进的SRCNN以及FSRCNN等算法。
图4和图5分别为Set5数据集和Set14数据集中典型图像在放大因子为3条件下不同模型的测试效果,可以看到本文算法相比其他算法在边缘和对比度保持方面效果更好,与原图效果最接近,且取得了最好的PSNR。
3 结论
本文针对当前基于深度学习超分辨率模型存在参数量大、运行速度慢等问题,通过深入分析影响当前网络模型参数数量和运算性能的因素,结合深度模型压缩技术取得的最新成果,提出了一种更为高效的网络结构,通过减少卷积核尺寸、将子像素卷积层放置在网络末端进行上采样、引入1×1卷积进行维度压缩以及采用最新的深度可分离卷积,可以大幅度降低网络参数,提高模型非线性表达能力,从而实现高速运行而不损失重建分离卷积,可以大幅度降低网络参数,提高模型非线性表达能力,能够实现高速运行,而不损失重建质量。实验结果表明,本文提出的方法在参数更少、运算速度更快的情况下,取得了更优的超分辨率效果。模型大小仅有10 KB,可以达到50帧/s的处理速度,能够部署到FPGA等嵌入式设备并实时运行。
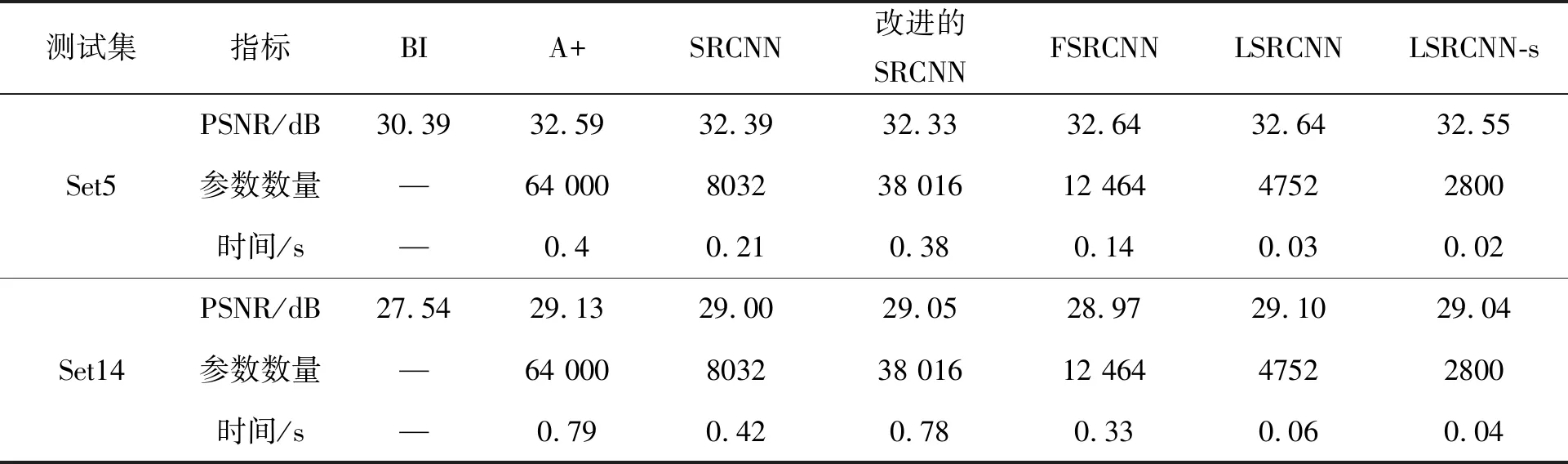
表2 不同模型在测试集上的PSNR、参数数量和测试时间

(a) Original/PSNR (b) Bicubic/24.04 dB (c) A+/27.02 dB (d) SRCNN/27.51 dB

(e) Improved SRCNN/27.71 dB (f) FSRCNN/27.92 dB (g) LSRCNN-s/28.16 dB (h) LSRCNN/28.29 dB图4 测试集Set5中的蝴蝶图像在放大因子为3条件下重建效果Fig.4 Reconstruction effect of butterfly image from the Set5 dataset with an upscaling factor 3

(a) Original/PSNR (b) Bicubic/31.68 dB (c) A+/33.20 dB (d) SRCNN/33.27 dB

(e)Improved SRCNN/33.18 dB (f) FSRCNN/33.30 dB (g) LSRCNN-s/33.28 dB (h) LSRCNN/33.38 dB图5 测试集Set14的lena图像的在放大因子为3条件下的重建效果Fig.5 Reconstruction effect of lena image from the Set14 dataset with an upscaling factor 3
猜你喜欢
红外技术(2022年11期)2022-11-25
计算机应用(2020年7期)2020-08-06
雷达学报(2020年3期)2020-07-13
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
艺术科技(2018年2期)2018-07-23
自动化学报(2017年11期)2017-04-04
太空探索(2015年8期)2015-07-18
浙江大学学报(工学版)(2015年1期)2015-03-01
噪声与振动控制(2015年4期)2015-01-01
