
机器学习算法信用风险预测模型
2019-04-23 03:39:02
微型电脑应用 2019年2期
(广东电网有限责任公司, 广州 510160)
0 引言
由于近年来国内金融行业的迅猛发展,伴随着我国经济的急速飞腾,银行业务蓬勃发展。信贷业务是银行的主流业务之一,但是如何评价借款人的信用风险已经成为当今互联网金融行业的热门课题之一,日益受到当代人的注意。
银行客户信用风险评估问题其本质为一个分类为题,也就是将现有的银行用户划分为信誉用户与非信誉用户的过程。从其发展历程来看,大致可以分为3个阶段,朴素分析阶段、概率分析阶段、人工智能阶段[1]。朴素分析阶段主要为概率学应用于经济领域之前的所有银行借贷阶段;
概率阶段是指概率学运用到银行金融领域开始直到人工智能在金融领域应用而结束[2],此阶段在我国主要是指上个世纪五十年代本世纪初。
第三阶段也就是现阶段,主要是指人工智能在信用评估中的应用,此阶段从本世纪初开始直到现在[3]。
从国际角度讲,消费者的信用评分美国的理论以及实际最为具有参考价值,其中例如Equifax公司[4],该公司每天可以提供数百万份的消费者信用分析报告。
同时从信贷领域将,美国信贷业务发展较为成熟,以上个世纪七十年代为例,美国信用卡发展达到了极致,甚至有的银行为了抢占市场,直接将信用卡寄到相应的用户家中。
另一方面,从风险控制角度讲,风险控制可以分为主动风险控制以及被动风险控制两种,被动风险控制一般是指,信贷客户违约后进行的催收行为;主动风险控制则是通过事先的机制确立客户是否有偿还能力以及偿还意愿[5]。
在我国,由于征信体系与2013年才开始正式推动以及建立,因此,在此领域属于起步较晚的国家之一,对于现代交易环境而言,信用体系是一种建立在客户稳定偿还能力上的不用立即支付即可享有相应服务的行为。故风险预测是银行发放贷款的重要参考之一[6]。
文献法:本文利用图书馆、网络以及数字图书馆等资源,搜集关于金融以及机器学习的相关资料相关资料,调查机器学习在金融领域应用的的相关理论,为本文写作提供理论基础。
实例分析法:根据模型,对于实际情况进行模拟以及分析,通过对于实际情况的模拟,说明论文的合理性。为该机器学习算法提供现实基础。
论证法:对于本文用到的相关算法以及部分公式给出推到过程,为本文研究提供数据支撑。
1 数据预处理
将判断客户是否有潜在违约风险的数据分为两个类型,一个为静态数据类型,其主要包含用户基本情况以及用户检测量表;另一类为动态数据,其主要包含客户的银行信息记录(如流水信息,基本信用信息),第三方支付记录等。其中动态信息随着客户的时时状态而发生改变,其具体情况如表1所示。

表1 相关数据资料表
用户向相关金融机构申请贷款时,需提交自己相关信息,相关平台利用用户提供的信息进行建模。如果相关信息缺失,则通过清洗或者变换的形式将所有信息补充完整。此过程预计占用整个工作流程的80%以上的时间,因为整个数学模型的基础建立在正确的数据处理上,如果相关数据失真,那么整个机器学习进行的最终判定也将会失真。
2 算法比较
1)回归算法
自从高斯提出最小二乘法以来,回归分析的应用也越来越为广泛,在我们日常的生活领域,基本上很难找不用它的领域。自从1969年设立诺贝尔经济学奖以来,大部分的获奖者都是统计学家、数学家或者计量学家,获奖成果也大多与回归分析相关。
从理论角度看,回归分析大致可以分为三个阶段即理论模型构建、数据采集阶段、参数估计与模型校验阶段以及模型应用阶段。
本次研究,根据数据特点,可以选用比较成熟的的回归算法:带虚拟变量的回归模型最为本次模型构建。为式(1)。
Y=α1+α2D2i+α3D3i+…+αnDni+βXi+εi
(1)
其中D为虚拟变量,可以表示性别学历等相关信息,例如D2可以表示性别,当D2=1时,定义为女性;当D2=0时定义为男性。
2)GBDT算法
本次设计采用机器学习算法中比较常见的GBDT算法,其基础原理为迭代法。具体实施为在迭代过程中,通过改变样本的权重,学习多个分类其,并且将其进行线性组合,从而提升算法的准确率。
GBDT算法是集成学习算法Boosting下的一个分支学习算法,与传统学习算法(如Adaboost算法)不同的是,GBDT算法使用向前分布算法,并且使用CATR回归树模型进行相关的学习[7]。
其基础原理为,假设f(x)表示学习器的相关函数,则ft-1(x)表示前一轮得到的强学习器,则损失函数以L(y,ft-1(x))表示,那么最终该算法的目标为,找到弱学习器ht(x)使得损失函数L(y,ft-1(x))=L(y,ft-1(x)+ht(x))最小。
举例来说,假设银行有100个实际违约客户,首先用80个去拟合,发现漏掉20个,这时用12个去拟合剩下的人员,发现还差8个,随后继续用8个拟合,知道差距越来越小,每次拟合过程中,都会逐步逼近真实数据,误差逐渐减小[9]。
3)算法比较
比较带虚拟变量的回归算法与GBDT两种算法,可以看出回归算法的优势在于模型建立简单方便,同时根据银行所搜集到的数据可以更为方便的增加或者减少相关参数(即D值),另一方面,从理论角度讲,只要参数选择合理,数据充足回归算法可以精确的预测出客户的信用等级,对原始数据要求较高。
相比于回归算法,GBDT算法相对复杂,但是对于原始数据的要求较低。在科学研究时,一般能够用简单方法解决问题时,尽量不用复杂方法但是在实际应用中,银行因为现实因素,搜集到的客户信息往往并非十分确切,所以最终根据银行提供的数据情况来看,选择后者GBDT算法建立本次模型。
3 算法实现
本文采用的基本机器学习的具体算法为:设集体样本为最大迭代次数N,损失函数L。最终输出的学习器为,f(x)。
则初始学习器表示为式(2)。
迭代后(N=1,2,3,4,…,N)有:
1)对于样本i=1,2,3,…,m的负梯度计算为式(3)。
(3)
2)利用CART回归树,得到第N颗回归树且对应的子节点区域为,J表示对应回归树的叶子节点个数。
3)对于叶子区域计算最佳拟合值。
4)升级版学习器为式(4)。
(4)
故可以得到最终的学习器f(x)表达式为式(5)。
(5)
4 用户分类以及情景模拟
用户分类,根据客户信息以及相关算法信息,可以将客户划分为4个类别:
1)本身是信誉客户,模型判断也为信誉客户,记作TN
2)本身是信誉客户,模型判断为非信誉客户,记作FP;
3)本文为非信誉客户,但是模型判断为信誉客户记作作FN
4)本身是非信誉客户,模型判断也为非信誉客户记作TP。
其具体划分如下表2所示。

表2 用户类型分类表
故据此可以计算该模型的准确率TPR:
模型错误率FPR:
故现有基本特征如下的银行客户样本:
1)如果用户信用记录有超过60天逾期行为,则记作Y=1;否则记作Y=0;如某银行内有50 000名客户,而逾期的用户为3 000名,且3 000名非信誉用户符合随机分布原则。
2) 用户信息:特征时间主要包含用户所有的动态信息,其中包含前文提及的银行流水记录以及金融信息记录。同时也包含用户检测3个量表的相关结果均已经处理齐全。
方案A,将所有贷款申请用户平均分为10组,每组5 000人,且每组包含300个非信誉客户;
方案B,根据模型可以计算的用户违约概率,将每个用户违约的概率记作P,则根据P值,将客户从大到小顺序,然后分成十个组,每组5 000人。显然十组中,靠后的分组里,信誉用户明显占优更多比例,而非信誉客户则在第一种最多。故此时只要寻找到,P值的分界点,即可确立最终的放款条件。其具体数据如表3所示。
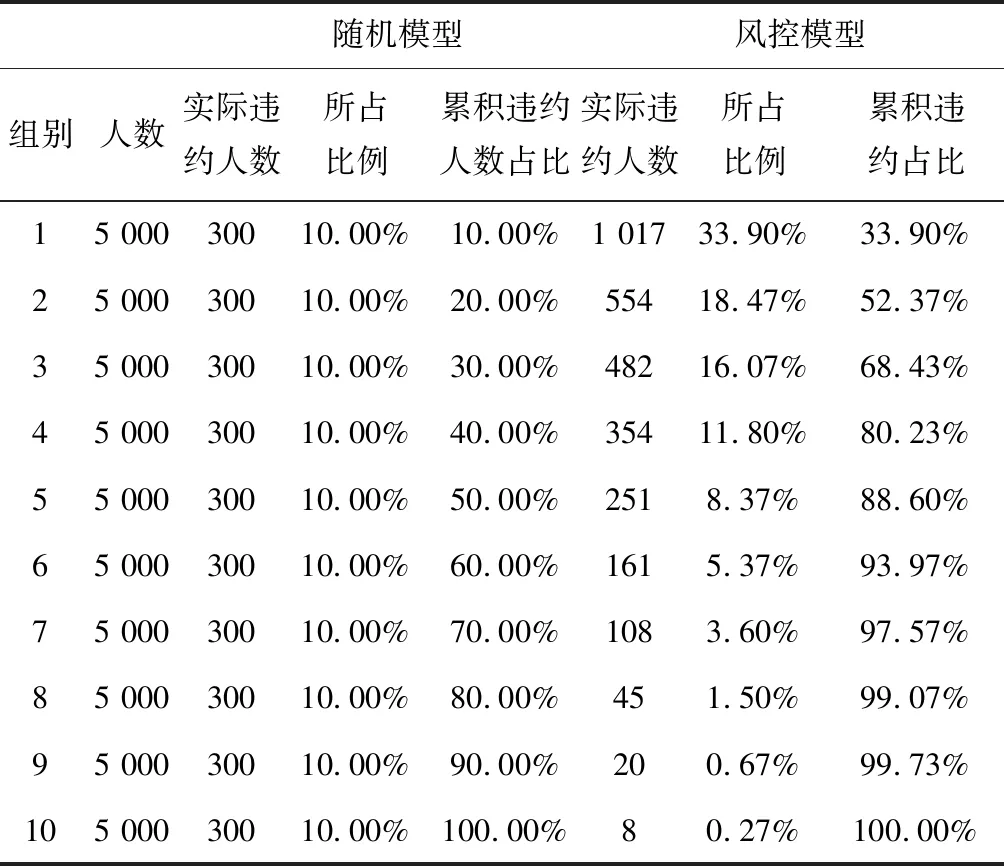
表3 随机风控模型对比表
5 模型评价
将A、B两组每一组的非信誉客户的所占比重绘制成提升图,如图1所示。

图1 提升图
从图中可以看出,方案B中,每组的非信誉客户人数在逐步递减,则该模型具有一定的现实意义,模型有效。
此时再根据前文提到的模型准确率(FPR)以及模型错误率(TPR)相关概念,由于模型计算结果以及真实结果均为已知,故可以轻松算得FPR,TPR两个参数。故以FPR为横轴,TPR为纵轴绘制ROC曲线。如图2、图3所示。
根据洛伦兹曲线的判定公式,此时选用ROC曲线常用衡量性能指标AUC来表示,AUC曲线通过计算ROC曲线下面积而求得,一般来说,AUC的值在0~1之间,本文中显然方案A的AUC值为,0.5;而方案B的AUC通过计算可以得知,其值为0.74.一般来说,一个模型AUC值要大于0.5才会具有实际效果,AUC值在0.7~0.9之间则被认为是一个优秀模型;AUC高于0.9,则认为该模型有异常变量进入,导致AUC过高。

图2 方案A ROC曲线

图3 方案B ROC曲线
而本次模型的最终AUC值为0.74,故符合相关要求,属于优秀模型范畴。
6 总结
本文针对互联网金融行业的信用风险问题,利用机器学习算法构建了一个信用风险预测模型,该模型的创新点在于首先数据处理方面,除了应用传统的用户基本信息、银行流水记录、金融信息记录外,还引入了用户用户检测量表的相关数据,次量表评定标准以及在模型中所占比重只有系统以及银行系统以及高层管理人员掌握,从一定程度上避免了人为因素对于放款的影响。由于此部分不是本文重点,故不做详细说明。
机器学习方面,本文选用传统的GBDT算法,对于用户的违约概率进行预测,最后通过相关实例进行说明。
但是由于笔者能力有限,文章亦有一定的局限性,例如论文实例部分假设过于理想化,所有数据均已处理完善,但是实际情况可能会出现相应的数据不足,需要进行缺失数据的处理,由于篇幅有限并未给出相关算法。
猜你喜欢
公民与法治(2022年12期)2023-01-07 09:16:26
计算机应用文摘·触控(2022年8期)2022-05-25 13:27:53
华人时刊(2019年13期)2019-11-26 00:54:42
现代营销(创富信息版)(2018年2期)2018-02-10 05:20:50
High Technology Letters(2017年3期)2017-09-25 12:53:30
知识经济·中国直销(2017年7期)2017-07-24 14:12:42
中国老区建设(2016年3期)2017-01-15 13:53:21
创新作文(小学版)(2016年20期)2016-08-22 09:11:22
华人时刊(2016年19期)2016-04-05 07:56:08
山东青年(2016年2期)2016-02-28 14:25:41
