
一种改进的全局注意机制图像描述方法
2019-04-22 08:03:08马书磊张国宾石光明
西安电子科技大学学报 2019年2期
马书磊,张国宾,焦 阳,石光明
(1.西安电子科技大学 人工智能学院,陕西 西安 710071;2.中国电子科技集团公司第二十七研究所,河南 郑州 450047)
图像描述技术是通过计算机视觉及自然语言处理技术让计算机自动描述图像内容。目前图像描述方法一般分为3类:(1)基于检索的方法;(2)基于模板的方法;(3)基于神经网络的方法。其中基于检索和基于模板的方法因其受限于图像的人工特征提取和文本的设计生成规则,往往效果并不理想。而基于神经网络的方法得益于网络强大的图像特征提取能力,在许多计算机视觉应用[1]中都取得了非常好的效果。故文中仅针对基于神经网络的方法进行讨论。
文献[2]早先提出神经图像描述(Neural Image Caption, NIC)模型,该模型由卷积神经网络(Convolutional Neural Network, CNN)和循环神经网络(Recursive Neural Network, RNN)构成。模型利用Google Inception[3]网络作为图像特征提取器,同时利用长短时记忆网络(Long-Short Term Memory, LSTM)作为文本编解码器。视觉注意机制作为一种常用技术,在图像问答[4]、细粒度分类[5]、动作识别[6]以及三位重建[7]等问题中被广泛应用。文献[8]通过引入视觉哨兵机制,提出一种自适应编码器-解码器模型。考虑到视觉注意机制大都基于固定尺寸感受野,文献[9]提出基于自底向上和自顶向下的注意机制的图像描述方法(Bottom-Up and Top-Down, BUTD),使注意机制的感受野尺寸可以随着物体的大小而调整。
现有方法中,虽然视觉注意机制可以很好地模拟人眼对图像局部的理解,但单纯的基于视觉注意机制其实并不完全符合人类感知机制,会造成图像全局信息丢失。因此,笔者提出一种改进的全局注意机制图像描述方法。实验表明,基于全局注意机制的方法能够有效克服全局信息丢失带来的语义失真问题,并在主观及客观性能评价中获得性能提升。
1 动 机
基于注意机制的图像描述方法可以根据上下文针对图像局部内容进行增强或抑制,取得了很好效果。然而,目前基于视觉注意机制的图像描述方法虽然可以有效加强图像各个不同局部特征,但正如下文所述,单纯的视觉注意模型并不完全符合人类感知机制。
人类感知机制的研究[10-11]表示,人们可以通过感知周围整体环境和高效地转移局部注意力来完成对周围场景的深刻理解。目前基于视觉注意机制的方法只模拟了后一点,但缺少对图像场景的整体感知,导致网络生成的文本不能够生动准确地描述图像的场景内容。如图1所示,可以看出,生成的文本虽然可以大致描述图像主体,但错误理解了场景整体内容(如图1(a)中工艺场景,图1(b)中的健身房场景等)。

标签文本:一个穿着白色上衣的男人在房间里制作手工品基于自底向上方法:一个穿着白色上衣的男人在房间里打台球大厅里有三个穿着运动服抬起右臂的人在健身一群穿着运动服的女人在运动场上打排球
图1 全局信息缺失导致网络生成的文本不能准确描述图像场景
因此,所提技术通过模拟人类感知机制全过程,在现有基于视觉注意机制方法的基础上,加入全局先验来指导网络,以生成更加准确、生动的描述文本,并提出改进的全局注意机制中文本描述方法。该方法先通过设计全局网络来提取图像全局特征fg,然后利用fg在长短时记忆网络迭代过程中指导生成局部特征向量fatt,最后通过基于全局特征的fatt和长短时记忆网络隐状态h生成当前文本,并提升生成文本质量。
2 基于全局注意机制的图像描述网络设计
2.1 基于神经网络的图像描述框架
典型的基于视觉注意机制的图像描述网络框架如图2所示。主要包括两个子网络:卷积神经网络和长短时记忆网络。

图2 基于神经网络的图像描述框架
其中,图像I首先经过卷积神经网络进行特征提取,得到图像高级语义特征f。其次图像特征f将会通过注意网络进行编码,得到加权后的图像特征fatt。注意网络以图像特征和当前时刻长短时记忆网络的状态作为输入,通过生成图像特征对应的权值,对图像特征进行加权。不同的权值大小反映了该时刻图像局部特征之间受关注程度的不同。然后,长短时记忆网络将加权后的图像特征fatt、当前时刻隐状态ht和细胞状态ct,以及当前时刻词向量WeΠt作为输入,迭代学习不同时刻词向量之间的关系,并通过归一化指数函数对隐状态ht进行解码,得到当前时刻单词yt。最后,上述步骤在时序上进行循环,直到生成完整文本。需要注意的是,在基于视觉注意机制的图像描述方法中,注意网络虽然增强了图像局部特征,但同时也减弱了图像的全局特征。
2.2 基于全局注意机制的图像描述框架
基于人类感知机制,在传统图像描述网络结构上加入了全局先验通路,提出基于全局先验的图像描述框架结构,如图3所示。

图3 基于全局注意机制的图像描述框架
如图3中虚线所示,图像I首先经过全局网络进行特征提取,得到全局特征向量fglb。全局网络的设计可以采用经典的深度神经网络。然后,fglb、fatt和当前词向量WeΠt将一同作为输入传给长短时记忆网络。在长短时记忆网络的设计中,全局特征向量fglb将会和局部特征向量fatt进行融合,以保证网络在学习全局信息的基础上学习图像局部特征。
2.3 基于全局注意机制的图像描述网络模型
在图像描述任务中,目前表现最好的神经网络是基于自底向上和自顶向下的注意机制的图像描述方法(BUTD),下文简称为基于自底向上的方法。该算法以提出的网络框架为基础,对自底向上的方法网络结构进行优化改进,提出基于全局注意机制的图像描述方法。网络核心部分如图4所示。

图4 基于全局注意机制的图像描述网络模型
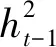
(1)
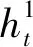
3 实验及分析
3.1 数据集
为了验证模型的有效性,选取具有挑战性的 “AI Challenger全球AI挑战赛” 中文数据集进行对比实验。在该数据集中,每一张图片均有5句中文描述作为标签。数据集总共包含30万张图片,对应150万句中文描述。其中包括训练集210 000张,验证集30 000张,测试集60 000张。
3.2 实现细节
实验采用VGG-16网络结构卷积部分作为全局网络进行图像全局特征提取,并将所有输入图像I均缩放为448×448像素大小。因此conv53输出特征图大小为[512,28,28],经过全局平均池化后,全局特征向量f53大小为[512,1,1]。APN网络中Faster R-CNN产生512个候选特征区域,即K=512。生成的特征向量fatt大小为[512,1,1]。长短时记忆网络中层数为2,隐状态h和细胞状态c的长度均被设置为512,循环次数由生成文本的结尾标识符动态确定。对于中文文本描述来说,采用Jieba分词对文本进行切割,然后利用Word2Vec方法进行编码,得到We。
网络训练过程中批大小设置为20,学习率为5×10-4,最大迭代周期为15。网络训练采用Adam优化算法,其中动量设置为[0.9,0.999],权值衰减为0.001。
3.3 结果对比
将当前图像描述任务中最优网络BUTD作为基准,和提出的方法在中文数据集上进行深入对比。在客观对比方面,采用BLEU[12]、METEOR[13]、ROUGEL和CIDEr[14]等图像描述评价标准,如表1所示。

表1 客观评价指标对比
如上表所示,所提方法在相同的训练条件下,各项客观评价指标均优于基于自底向上的方法。其中在BLEU评价指标上平均比基于自底向上的方法高出0.003,在METEOR、ROUGEL和CIDEr指标上分别高出0.02、0.001和0.24。除了客观评价指标,还进行大量主观对比实验,如图5所示。

基于自底向上方法: 全局注意机制方法: 一个穿着白色上衣的男人在房间里打台球 一个穿着白色上衣的男人在房间里制作工艺品 一群穿着运动服的女人在运动场上打排球 三个穿着短袖的人在健身房锻炼身体 两个戴着帽子的男人站在道路的机器旁 两个戴着帽子的男人在室外的道路上交谈 基于自底向上方法: 全局注意机制方法: 大棚里有一个穿着深色裤子的男孩在摘草莓 大棚里有两个穿着各异的人在摘草莓 一个左手拿着球杆的女人蹲在高尔夫球场上 一个左手拿着高尔夫球杆的女人蹲在绿茵茵的球场上 一个右手拿着话筒的男人坐在广告牌前说话 一个右手拿着话筒的男人坐在广告牌前的沙发上讲话
图5 模型生成文本对比
在以上对比实验中可以看到,在样例(a)、(b)、(c)中,基于自底向上的方法生成的文本甚至错误的描述了图像内容,而基于全局注意机制的方法由于加入了全局先验信息,可以准确的表述图像内容。除此之外,基于全局注意机制的方法在描述上更倾向加入修饰性的形容词,如“红毯上”“绿茵茵”“汽车旁”等,使生成的文本更自然、生动,描述了更加丰富的图像细节。
4 结束语
算法基于人类感知机制,在视觉注意模型的基础上加入图像全局信息,提出一种改进的全局先验图像描述方法。该方法通过融合图像全局特征和区域局部特征,解决基于视觉注意机制方法中的全局信息丢失的问题。实验证明,基于全局注意机制的方法在客观评价标准上优于目前最好算法;在客观评价中,该方法可以更准确地描述图像的整体内容,并生成更加细致、生动、形象的自然语言文本。
猜你喜欢
大电机技术(2022年4期)2022-08-30 01:39:24
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
电子制作(2019年19期)2019-11-23 08:42:00
金桥(2018年4期)2018-09-26 02:24:54
疯狂英语(双语世界)(2017年4期)2017-04-28 09:10:06
唐山文学(2016年11期)2016-03-20 15:25:57
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
