
一种融合历史均值与提升树的客流量预测模型
2019-04-19 05:24白智远温从威杨锦浩
计算机技术与发展 2019年4期
白智远,温从威,杨锦浩,陈 智,吕 品
(上海电机学院 电子信息学院,上海 201306)
0 引 言
移动定位服务的发展使得互联网商家“线上线下”的交易数据急剧增长[1-4]。分析这些数据中隐藏的用户交易习惯和倾向性[5-6]对优化商家的运营具有重要作用。近来年,出现了许多关于移动定位服务预测的研究。例如,付全兴等[7]使用逻辑回归和支持向量机,以4个月的电商数据为研究对象,预测用户的购买行为;陈传波等[8]把平滑加权的思想应用于实时模型预测,通过提取包含有趋势的特征来提高预测模型的精确度;张昊等[9]利用XGBoost(extreme gradient boost)算法[10]实现了商品推荐中的用户购买行为预测。他们将决策树[11]、随机森林[12]作为基线对比方法,研究发现变量的重要性对模型的构建有较大影响。
文中借鉴上述研究的思想,提出了历史均值与提升树融合的互联网商家客流量预测模型。该模型的本质是提升树模型与历史均值模型,按照计算公式所求出的权重系数,按照一定比例而融合的加权和,不仅考虑了如何提高模型的预测精度,而且还考虑了客流量的预测与时间的依赖关系。并且对不同模型的预测结果做出了对比分析。最后,将融合了历史均值与提升树的客流量预测模型所得到的结果与传统的零售业结合,粗略进行了分析,对商家今后的运营提出了一些实质性的建议。
1 数据预处理
1.1 数据描述
文中使用的数据来自天池大数据平台,共包含某年7月1日至次年10月31日的商家完整行为数据,分为“商家特征”数据、“用户支付行为”数据和“用户浏览行为”数据。商家特征反映了商家的热度,评分高以及评论好的商家,是提高用户购买力的因素之一,除此之外,门店的等级、菜品的丰富程度也作为商家的考量之一。它的数据共包含7个属性:商家ID、店铺所在地、人均消费、评分、评论数、门店等级以及食品分类名称;用户支付行为特征反映了用户的支付习惯方式,包含3个属性:用户ID、商家ID和用户的支付时间;用户浏览行为则反映了用户的购买习惯,如果用户经常访问同一个商家,结合其他两个特征可以推断出用户所喜爱的商品种类、个人口味等信息,包含3个属性:用户ID、商家ID和用户浏览商家的时间。
1.2 数据预处理方法
由于直接使用原始数据训练模型不仅会产生误差,还会耗费大量的计算资源,因此,对原始数据集进行了预处理,将原始数据中存在的异常值进行剔除、去重、归一化等处理。一方面,由于商家从入驻口碑平台到销售量增加存在一定的启动时间,并且可能出现某段时间销量中断的现象,因此,商家开业前7天的数据以及销量中断前后3天的数据不作为训练数据;另一方面,由于原始数据中存在短时间内单个用户大量购买的情况,为消除这种异常消费对预测的影响,采用了基于规则的方法对原始数据进行归一化;另外,原始数据中还存在一些特殊时间节点和难以预计的大幅波动,如大型节假日(如中秋节、国庆节等)、停业、商家开展促销活动时单个用户大量购买的情况。对于这些基于规则的方法难以处理的异常值,文中采用了模型预训练方法,即采用欠拟合算法对模型预训练,清除原始数据中残差为10%和25%的数据。由于预测目标是商家的日销量,因此预处理后用于训练的数据是按小时统计的商家的总销量。
此外,为提高模型预测的准确性,实验中还采集了全国各省市的天气数据以及节假日天气数据作为原始数据的补充。在额外采集的气温、湿度、气压等数据中,根据经验,将天气状况简单转换为降水指数和天晴指数两个指标。由于人体对于气象参数的感受不成线性关系,故生成人体舒适度指数(comfort index of human body,SSD)作为模型训练的一个重要特征。最终,模型训练与预测使用的特征与标签如表1所示。

表1 模型训练与预测使用的特征
2 历史均值与提升树融合的客流量预测
2.1 XGBoost的基本思想
XGBoost是一种极限提升树的机器学习方法,具有良好的扩展性,以及计算速度快、模型表现好等特点。对于数据集D={(xi,yi)},提升树方法的核心是最小化式1所示的正则化目标函数。
(1)

一般,对上述目标函数进行二阶泰勒展开(如式2),然后进行优化。
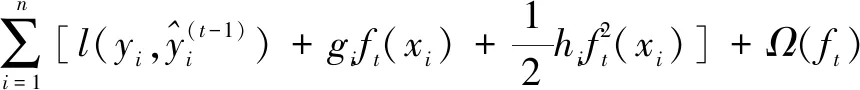
(2)
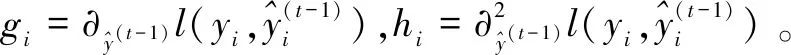
假设树结构q(x)已知,并且Ij={i|q(xi)=j}为叶节点j的样本集合,可得叶节点j的最优权重:
(3)
最后,采用贪心算法,从某一叶子开始,反复向树中添加分支。假设IL和IR是分割后左右节点的实例集合。令I=IL∪IR,则分裂后的损失可由式4计算。
(4)
与传统的GBDT模型对比,XGBoost还支持线性分类器,并且加入正则化因子,用于控制模型的复杂度。正则项里包含了树的叶子节点个数等信息,它降低了模型的方差,使学习出来的模型更加简单,防止过拟合,这也是XGBoost优于传统GBDT的一个特性。
2.2 历史均值模型的基本思想
历史均值模型是以预测日为基准,求出预测日之前到某一天的平均客流量、销量增量等信息,再以权重系数作为融合的比例,预测未来14天的客流量。
2.3 融合方法
为获得精确度高的客流量预测模型,文中采用了二个阶段的训练方法。第一次阶段的训练中,使用了XGBoost与GBDT(gradient boosting decision tree)模型。模型训练的参数如表2和表3所示。每一种模型分别使用了2组参数进行训练,总共获得4个模型。

表2 XGBoost算法的不同参数
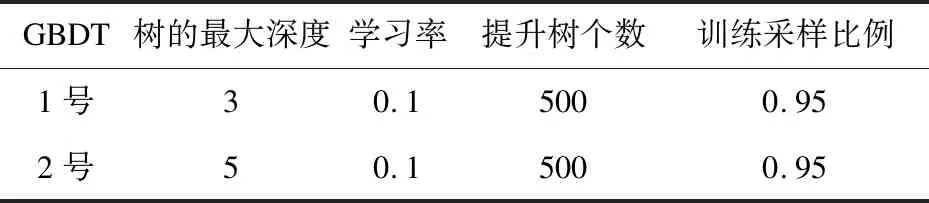
表3 GBDT算法的不同参数
为了减小预测误差,调整XGBoost与GBDT算法中树的深度、学习率以及迭代次数的参数,在XGBoost算法的1号模型中,一般情况下,学习率的值默认为0.1,而树的最大深度默认为3。但是,对于不同的问题,理想的学习率有时会在一些特定的区间范围之间波动。树的深度越大,则对数据的拟合程度越高。因此,文中在确定XGBoost算法的2号模型的学习率以及树的最大深度时,引入XGBoost算法中内置的cv函数,cv函数在每一轮迭代中使用交叉验证,根据算法参数的调整,返回理想的决策树数量。因此,通过cv函数较为精确的计算,将2号模型的学习率调至0.03,树的最大深度为5。
第二阶段的训练使用了历史均值模型。历史均值模型以预测日为基准,首先求出预测日之前的21天的销量平均值,得到每天的平均销量;其次,以周为单位,统计每周的销量的中位数和平均值,通过线性拟合得到每周的销量增量;最后,将每天的均值销量与每周的销量增量叠加,以此预测未来两周的销量。该模型把过去21天的历史销量的相关度矩阵作为输入;将未来两周的销量和历史均值模型与第一阶段的模型融合的权重系数作为输出。均值模型的融合比例最大为0.75。融合的权重系数计算如下:
(5)
由此,将XGBoost、GBDT和历史均值模型得到的过去三周的平均销量和销量值,分别代入式5,可求出相应的权重系数为:0.47,0.34,0.19。最终,将训练得到的2组XGBoost模型和2组GBDT的不同结果分别与历史均值模型按0.47,0.34,0.19的比例融合,得到预测未来14天的客流量。
3 实验分析
3.1 实验设置
该实验采用的硬件为Inter(R) Core(TM) i5-5200U CPU @ 2.20 GHz。软件环境中操作系统为Windows 7,开发环境为Python3.6。原始数据为2.13 GB,预处理后的数据为220 MB。为判断XGBoost方法预测的有效性,实验中引入了时间序列加权回归的算法作为基线对比方法[8]。
3.2 预测结果对比分析
由于时间序列反映了实体属性在时间顺序上的特征[13],因此,实现了时间序列加权回归算法,分析2种算法的预测结果后,得到的前500位互联网商家在未来14天的客流量发展趋势,如图1和图2所示。
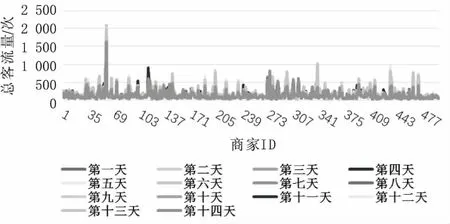
图1 历史均值与提升树融合模型预测
分析客流量发展趋势可知:
(1)与浏览动作相关的变量对模型的贡献程度最大,这是因为浏览是用户交互的最主要方式,其信息丰富程度远高于其他特征;
(2)部分商家可能所经营的商品评价较高,顾客的返回率使得部分商家的客流量稳步上升;
(3)大部分的商家十四天总客流量已经突破了5 000,少量甚至达到了约25 000的级别。这极有可能是商家近期的某种促销活动所导致的。比如通过平台派发不同程度的优惠券、现金红包、买满一定金额优惠等活动。但如何调整自己的运营策略,吸引到更多的客流量显得至关重要。

图2 时间序列加权回归模型预测
3.3 性能分析
通过优化算法参数,采用测试集样本对建模结果进行评测[14],算法运行结果和精度测试如表4所示。
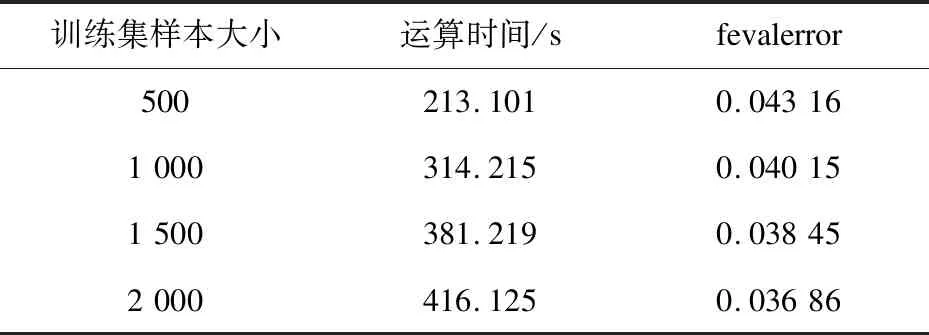
表4 历史均值与提升树融合模型精度测试
实验中利用XGBoost自定义的评价函数对提出的模型进行了性能评估。调用评价函数时,传入验证集和验证集上的预测值作为函数参数,返回一个浮点类型的评估值fevalerror。fevalerror的值越大,模型预测精度越低。反之,fevalerror的值越小,模型预测精度越高。结果表明,随着训练集样本大小的增加,运算时间增加,fevalerror值逐渐减小,精度上却逐渐增加。由此,历史均值与提升树的融合模型具有预测精度较高、运算速度较快的优势。
4 结束语
将历史均值模型与提升树方法进行了融合,对互联网商家的线上线下的真实用户数据进行了特征提取和建模预测。并将提出的模型与时间序列加权回归进行了预测结果与性能比较。实验结果表明,融合历史均值模型与提升树模型的方法能有效实现互联网商家客流量的预测。在互联网高速发展的今天,对比传统的零售行业,互联网商家的营销对用户消费给予了更多的关注,在产品详情页的介绍、客服服务、便捷的移动支付等方面都致力于为用户带来更好的消费体验。通过这次客流量预测模型的构建和对用户数据进行的挖掘,商家利用互联网这一渠道,能够更好地与用户及时沟通,了解用户感受,使互联网商家与用户建立了信任关系,吸引到更多忠实的用户。这对互联网商家的运营决策、降低成本、改善用户体验有着重要的现实意义。
猜你喜欢
文萃报·周五版(2022年17期)2022-05-05
现代电子技术(2021年15期)2021-08-06
销售与市场(营销版)(2020年3期)2020-03-24
数学大王·中高年级(2019年5期)2019-06-09
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
智富时代(2018年7期)2018-09-03
智富时代(2018年7期)2018-09-03
数学大世界(2018年35期)2018-02-22
发明与创新·中学生(2017年5期)2017-05-12
