
卷积神经网络在车牌识别中的应用研究
2019-04-19 05:18刘华春
计算机技术与发展 2019年4期
刘华春
(成都理工大学 工程技术学院 电子信息与计算机工程系,四川 乐山 614007)
0 引 言
随着中国汽车保有量的持续增加,发展智能交通已经成为一个社会共识,而车牌识别是智能交通的一个重要环节。车牌识别在道路收费管理、超速违规、电子警察、停车场管理、交通数据采集等交通信息控制中发挥着重要的作用。通常的车牌识别系统包括车牌定位模块、车牌校正和预处理模块、字符分割模块、字符识别模块。文中着重研究车牌的字符识别模块部分。
深度学习是一种特定类型的机器学习技术[1],是实现人工智能的一种有效方式,也是一种使计算机系统从经验和数据上得到改进的技术,具有很强的识别能力和灵活性[2]。深度学习可以发现和表征问题的复杂结构特征,因此可以大大提高识别性能,还避免了统计机器学习中关于特征提取的一系列问题[3]。目前有大量的证据表明,在计算机视觉、图像识别领域,深度学习的识别精度高于传统的图像处理和统计机器学习[4]。卷积神经网络(convolutional neural network,CNN)是神经网络(neural network,NN)的发展,是源于人工神经网络的一种深度机器学习方法,近年来在图像识别领域取得了巨大的成功。CNN由于采用局部连接和权值共享,保持了网络的深层结构,同时又大大减少了网络参数,使模型具有良好的泛化能力,又较容易训练,很好地解决了NN中网络训练时的梯度消失(vanishing gradient problem)和梯度爆炸(exploding gradient problem)等问题[5]。目前,卷积神经网络已经成为众多科学领域的研究热点之一。由于卷积网络避免了对图像复杂的特征提取,可以直接输入原始图像,因而得到了更为广泛的应用。卷积神经网络在图像识别领域具有良好的适应性,目前在计算机视觉任务中应用广泛,并在手写数字识别、人脸识别等图像领域的应用中取得了很好的效果[6]。
文中将改进的卷积神经网络LeNet-5引入到车牌字符识别中,以提高传统车牌识别方法的性能。
1 车牌特点和传统的识别算法
1.1 车牌的特点
1.1.1 车牌形状规格
国内车牌种类较多,文中主要研究常用的民用车牌,车牌类型为单排车牌,如图1所示。
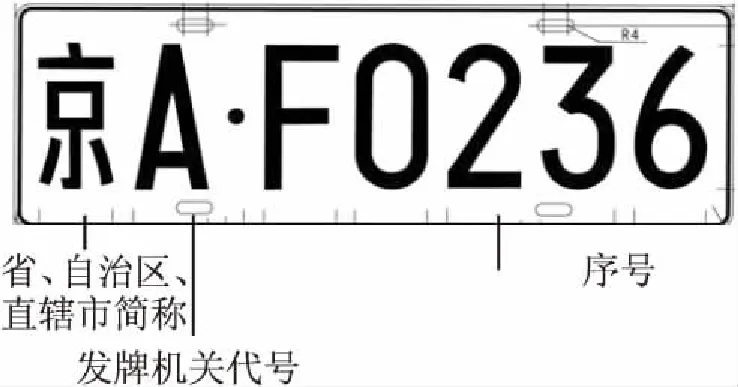
图1 标准车牌规格
车牌尺寸为长440 mm,宽140 mm的矩形,车牌上的字符由1个汉字字符和6个大写英文字母/数字组成。中间一个小圆点分隔符将车牌分成区域和编码两部分,分隔符前面为2个字符,后面为5个字符,小圆点分隔符的直径为10 mm。车牌中的每个字符大小为45 mm×90 mm的矩形区域[7-8]。字符之间有12 mm的标准间隔(小圆点间隔符与前后字符间隔也为12 mm),但实际车牌中,可能存在字符间隔大于12 mm的情况,因为有些字符不能填满整个矩形空间的宽度,例如字符“1”和其他字符。车牌左右边框与第一个字符和最后一个字符距离为15.5 mm,上下边框与字符距离为25 mm。
1.1.2 编号规则
车牌字符是由汉字、英文大写字母和数字组成。编号规则为,第一个字符是中国内地各省、自治区、直辖市的汉字简称,共有31个,第二个字符是发证机构代码字符,使用英文大写字母A-Z,第三到第七位由英文大写字母和数字组成,不包含英文大写字母I和O,因为容易与数字1和0混淆。所以,大写字母为24个,数字为10个,共计65个字符。
1.2 传统的车牌字符识别方法
目前,传统的车牌字符识别方法主要有字符模板匹配法、字符特征统计法和统计机器学习方法等[9-12]。
1.2.1 模板匹配法
该方法是在车牌识别前,预先获取各种车牌的标准字符模板,构建一个库。然后将待识别的车牌字符逐一与标准字符模板库比较,计算待识别字符与每个字符模板的匹配程度,匹配度计算采用字符图像对应的像素进行逻辑运行,匹配度最高的模板即为该字符的类别。由于该方法采用像素逻辑运算进行相似度的匹配,对于相似度较小的字符,如Q与0,8与B不能很好地分别。另外,在光照条件不好,较为模糊或磨损、断裂等情况下,识别率变低,所以,鲁棒性低。
1.2.2 特征统计法
字符特征统计方法比模板匹配方法检查更多的特征,该方法是提取车牌字符的一系列统计特征作为识别字符的判别特征,然后设计某种判别规则和决策函数,对待识别的字符进行分类。该方法的缺点与模板匹配法的缺点相似,即抗干扰能力低,性能不稳定。
1.2.3 机器学习方法
机器学习方法是将大量的车牌字符训练学习模型,学习输入输出映射模型,让分类器进行有监督学习。机器学习算法有SVM、贝叶斯、决策树等。模型训练完成后,将待识别的字符输入模型,输出字符所属的类别。其缺点是这类机器学习方法通常需要进行大量车牌特征的抽取,抽取的特征不同,选用的分类器算法不同,往往结果也不完全相同。
综上,由于这些方法都各有其自身的不足,有的鲁棒性不强,有的需要抽取复杂的车牌特征,对经验依赖性高。为了改善这些问题,进一步提高识别准确率,文中将深度学习中的LeNet-5卷积神经网络模型进行改进后应用于车牌字符识别。
2 卷积神经网络
卷积神经网络是采用卷积运算进行特征提取的一类深度神经网络,其结构通常由卷积层和子采样层交替组成前端,后端输出采用全连接层结构。
2.1 卷积层
卷积层的主要任务是进行特征提取,运算方式是卷积运算,连接方法是局部连接。卷积层通常由多个特征平面组成,共同完成前一层的特征提取,每个特征平面内神经元的连接权值相同(权值共享)[13]。在特征平面中,每个神经元连接到前一个特征平面的特定区域中的神经元(局部感受野)。卷积计算过程是首先对输入的特征平面像素进行边界填充,以保证卷积核与输入像素尺寸匹配,然后将卷积核在整个特征平面上滑动一个固定的步长,从而构建新的特征平面[14]。卷积层的连接关系表示为:
(1)

卷积运算完成后,通常采用sigmoid或tanh激活函数对结果进行变换。
2.2 子采样层
子采样层也称为池化层(pooling layer)或下采样层(subsampling)。该层的作用是降维,即降低输入图像的灵敏度。由于输入数据经过卷积层的卷积运算后,根据卷积核形成多个特征平面,是一个升维过程,需要随后进行适度的降维处理,否则,可能造成“维数灾”。因此,子采样层的功能是适当地对卷积层的输出进行降维处理[15]。子采样层的每个特征平面上的神经元连接到卷积层的共享值区域,特征平面的数量是不变的,通过子采样层的映射缩小比例,子采样过程可以由式2表示。采用子采样层处理,使得网络降低了图像位移翻转的灵敏度。
(2)
2.3 全连接层
卷积神经网络的前端是由若干卷积层和子采样层构成,后端输出部分由全连接层组成。全连接层完整地连接当前层和前一层的所有特征平面神经元[16]。由于卷积层和下采样层是二维特征平面,而全连通层输出是一维类别向量,所以网络中首个全连接层需要将二维特征平面转换为一维向量形式。全连接层通常采用多层感知器网络来实现,最后输出识别类别。
3 LeNet-5网络和改进
3.1 LeNet-5网络结构
LeNet-5网络最早是由YannLeCun于1998年提出的一个卷积神经网络模型,主要用于手写数字识别,具有卷积神经网络的典型结构,是深度神经网络中最有代表性的实验系统之一,曾广泛用于美国银行手写数字的识别。网络结构由7层组成,每层包含训练参数,LeNet-5中主要有卷积层、下抽样层、全连接层3种连接方式。如图2所示,其中Cx层代表卷积网络,Sx层代表子采样层网络,Fx层代表全连接层网络。

图2 LeNet-5卷积神经网络结构
C1层是卷积层,包含6个特征平面,每个特征平面由一个卷积核映射而形成。每个特征平面中的单元连接到输入层中的一个5×5的区域,即卷积的输入区域大小是5×5。该层的卷积运算使用6个5×5的卷积核与输入区域进行卷积运行。每个特征图平面内只使用一个共同卷积核,即共享权值。
S2层是下采样层,采用的是2×2的输入域,C1层的6个特征平面分别以2×2的区域进行采样,得到6个14×14的下采样平面。C1层的4个单元作连接到S2层的1个单元,作为S2层的输入,输入区域滑动运行,每次滑动2个像素。在这里,使用最大池化(maximum pool),大小为2×2的采样核。
C3层是一个由16个10×10大小的特征平面组成的卷积层。卷积运算与C1层相同,不同之处在于,C3层的每个神经元与S2层中的多个特征平面相连,即该层的每个神经元连接到S2层多个特征平面的5×5大小的输入区域。C3层输出是16个10×10的特征平面。
S4层是下采用层,采样核大小为2×2。C3层的16个10×10的特征平面分别作为输入,以采样核为2×2的下抽样,仍然使用最大池化,S4层得到16个5×5的特征平面。
C5层是由120个卷积结果构成的卷积层。由于S4层的特征平面大小为5×5,与本层的卷积核大小相同,这样经过卷积后,形成特征平面的大小为1×1,所以就形成一维的卷积结果。这里采用120个神经元,每个神经元都连接到S4层的16个特征平面,这样就得到120个卷积结果。
F6层是由84个神经元组成的全连接层,它与C5层的120个神经单元完全连接。
输出层OUTPUT是由10个神经元组成的全连接层,与F6层完全连接。每个神经元代表输出的一个类别,在这里分别代表数字0到9。采用径向基RBF分类器连接F6层,RBF的映射关系如式3所示。
(3)
其中,xj为F6层上的第j个神经元;yi为输出层的第i个神经元的输出值;wij为神经元i到神经元j之间的偏置。输出层的每个节点yi表示一个数字类别的置信度。
3.2 LeNet-5模型的改进
在车牌识别中,由于车牌分割的输出由汉字和6位数字/字母组成,而传统LeNet-5网络主要用于数字0-9的手写数字识别。这明显是不同的,所以LeNet-5模型不能直接应用,需要根据中国车牌中字符类别等特点进行改进。
3.2.1 输出层的改进
由于在传统的LeNet-5模型中输出的数字只有10个,而车牌对象共有65个类别(31+24+10=65),考虑到车牌中的字母/数字与中文字体相差很大,所以设计两个分类器,一个用于汉字分类,一个用于字母数字的分类。这样,模型输出层的单元个数分别设计为31个和34个。
3.2.2 调整特征平面数
由于模型的识别数量修改为31和34,比原来模型的输出类别大,而且有较为复杂的汉字识别,为了更全面地提取图像特征,需要调整一些层的特征平面的数量。因此,将C1层和S2层的特征平面数量由6个增加到24个,将C3和S4层的特征平面数量由16个增加到52个,将C5层的特征平面数量由120个增加到480个。调整各层参数,将对输出的结果产生影响。
3.2.3 改进模型输入大小
由于传统模型中为32×32的输入,当某些汉字图像被压缩时,可能会造成某些复杂的汉字信息丢失,如“藏”、“赣”、“鄂”等。因此,模型输入修改为64×64大小,从而相应地调整每个层的特征平面神经元数量。
3.3 网络实现和训练
采用Tensorflow框架用于实现改进后的LeNet-5网络模型。将车牌字符分割后,得到的汉字和数字/字符图像作为训练数据。部分训练样本如图3所示。

图3 部分训练数据样本
为了增加数据量,部分车牌数据通过图像处理变形获得。共获得汉字图像35 460个,类别31个,平均每个类别1 143个;数字/字符图像32 100个,类别34个,平均每个类别944个。随机抽取80%的数据作为训练样本,其余20%作为测试样本。所有数据标准化为64×64的二值图像。分别为每个分类字符设置标签,汉字31个标签,从0到30,数字/字符34个标签,从0到33。在CPU为i5-5200U上训练模型,进行有监督学习。在训练中设置不同的迭代次数,在2 000~10 000之间训练模型,直到收敛为止。
4 算法测试和性能分析
4.1 性能测试实验
为了测试改进后的LeNet-5网络的性能,通过实验进行测试。将数据集的80%作为训练模型数据,20%作为测试数据。测试样本数据由6 420个数字/字母图像和7 092个汉字图像组成。分别与支持向量机(SVM)和BP神经网络进行了对比实验。
支持向量机也分别设计2个分类器进行训练,一个用于汉字分类,一个用于数字/字母分类。支持向量机使用的特征包括笔画、密度和网格特征,在相同的实验环境下进行实验,结果如表1所示。
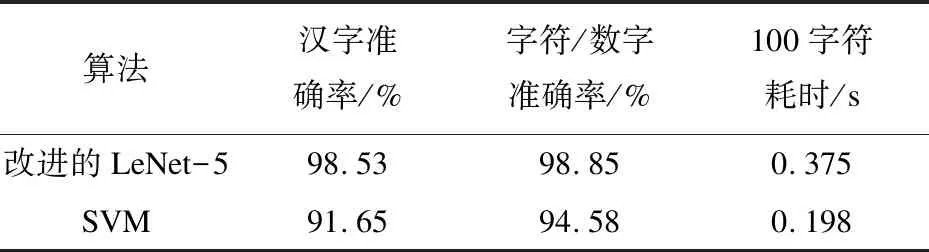
表1 改进的LeNet-5与SVM实验结果
从表1可以看出,采用卷积神经网络可以显著地提高车牌中的字符识别准确率,汉字分类准确率可以提高约7%,字符/数字准确率可以提高约4%。使用支持向量机方法,平均识别100个字符的时间为0.198 s,卷积神经网络的耗时为0.375 s,由于卷积网络需要对车牌字符图像进行卷积运算,故耗时较多。
在相同的实验环境下,改进的LeNet-5网络和BP神经网络分别进行对比实验测试,结果如表2所示。
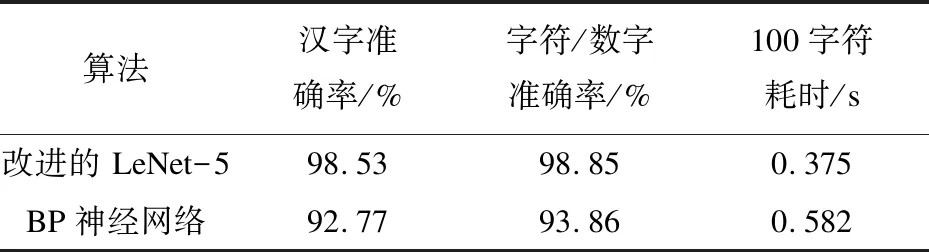
表2 改进的LeNet-5和BP网络实验结果
为了测试改进的LeNet-5性能,将常用的BP神经网络进行对比实验。BP网络设计为三层结构,隐含层为450个节点,学习率设为0.01。从表2可以看出,改进的LeNet-5网络识别准确率比BP网络高出约6%。时间性能方面,在相同实验环境配置条件下,改进的LeNet-5识别100个字符为0.375 s,BP神经网络需要0.582 s,改进的LeNet-5网络所需时间也少于BP网络。
4.2 识别错误样本分析
在车牌字符识别测试中,出现一些识别错误的情况。分析这些错误识别的字符原因,有如下特点:(1)车牌中某些字符本身就比较模糊,因为光照、倾斜、变形、粘连、分裂等原因所致;(2)车牌分割时,由于噪音或其他原因的干扰引起的字符分割错误,如“京”与“琼”,“1”与“T”等,“0”与“Q”等。对于这些识别错误,部分可以通过加大训练样本来加以改善,部分可以通过提高字符分割正确率等预处理方法来加以改善。
5 结束语
为了改善传统车牌识别方法中过分依赖车牌特征和鲁棒性不强等问题,对卷积神经网络LeNet-5的结构进行了改进,并进行了性能测试实验,与三层BP神经网络和SVM进行了对比。结果表明,改进的LeNet-5在车牌字符识别中有良好的识别性能,与三层BP神经网络相比,改进的LeNet-5在准确率和识别速度方面都优于BP神经网络;与SVM相比,识别准确率高于SVM,识别速度慢于SVM。由于实验中没有采用GPU,若在实际应用部署时使用GPU加速,运行速度会有很大程度的改善。改进的LeNet-5卷积神经网络具有优异的鲁棒性、准确性和较好的实时性。下一步将进一步完善数据预处理及车牌字符分割算法,构建性能优良的车牌识别系统。
猜你喜欢
动漫界·幼教365(中班)(2021年4期)2021-05-23
电子产品世界(2021年8期)2021-01-16
电脑知识与技术(2019年29期)2019-12-16
小学生学习指导(低年级)(2019年12期)2019-12-04
电脑爱好者(2019年8期)2019-10-30
中国计算机报(2019年49期)2019-02-07
中国新闻周刊(2017年36期)2017-10-21
小猕猴智力画刊(2017年5期)2017-05-25
科技创新导报(2016年32期)2017-04-22
创新时代(2016年8期)2016-10-21
