
基于深度强化学习的无人驾驶智能决策控制研究
2019-04-17 09:00朱武哲
赢未来 2019年11期
朱武哲

摘 要:随着人工智能技术的发展,越来越多的智能应用正在潜移默化地改变我们的生活。普及无人驾驶车辆是未来交通的发展方向,决策控制问题则是无人驾驶技术发展需要面对的重要问题。本文针对无人驾驶决策控制问题,提出将示教学习与强化学习相结合的解决方案,尝试吸取示教学习算法的优点,对强化学习算法训练效果进行提升。基于深度确定性策略梯度算法(Deep Deterministic Policy Gradient, DDPG),本文提出了融合示教的 DDPG 算法(DDPG with Demonstration, DDPGwD),并使用了开源微软仿真环境对算法进行了仿真验证,证明了上述算法在自动驾驶决策控制中的有效性。
关键词:无人驾驶智能决策;深度确定性策略梯度算法;示教学习;强化学习
一 引言
随着自动驾驶技术的不断突破,无人驾驶车辆的生产已经向实用化迈进,在未来数年内将对提高道路安全、促进交通管理和改善城市环保等产生颠覆性影响。据统计,在所有车辆肇事情况中,九成以上的车祸是由驾驶员的失误造成的。因此,无人驾驶功能的出现,有可能大幅降低交通肇事案件的数量。我国对于无人驾驶的研究起步较早,但是随着对自动驾驶应变能力要求的不断提高,新一代的无人驾驶车辆既需要对复杂的道路场景进行识别与分析,又需要克服不同环境下的传感器噪声等问题,同时还需要实时应对各种突发状况,这对自动驾驶人工智能的快速学习能力、泛化能力提出了更高的要求,成为急需攻克的难点问题。当前,制约无人驾驶技术应用的一个关键问题是如何保证车辆在不可控复杂环境中长时间安全自主行驶。在不可控复杂交通环境中,道路情况复杂(包括道路标志缺失、被遮挡、表面破损,行人及车辆共存等),道路周围环境多变(包括天气、光照和气候多变,城市部分片区改造或重新规划等)。在不可控环境中要求无人驾驶车辆具有更加智能的决策控制能力,能够综合利用感知信息,在紧急突发情况下做出安全合理的决策控制。以示教学习(Imitation Learning)为代表的一系列通过人类示教来引导机器进行学习的智能方法,已經在机器人与智能控制领域取得了很大的成就。但是,如何将人类的经验用于汽车自动驾驶人工智能的训练,尤其是在示教样本较少的情况下,如何应付不可控复杂交通场景、如何提高泛化能力,都是无人驾驶研究的难点。无人驾驶的决策与控制模块是决定无人驾驶汽车安全性、稳定性的关键。图1展示了谷歌无人车和特斯拉自动驾驶模式下发生的事故。会发生这些事故,主要原因是面对不可控的突发交通状况时,无人车无法做出最佳的实时决策与控制。因此,不可控复杂环境中的无人驾驶的决策和控制,逐渐成为制约无人驾驶技术发展的关键问题。
二 国内外研究现状
强化学习是一种再激励学习算法,和上述的监督学习方法不同,它通过和环境交互试错进行在线的学习,获取反馈,从而优化策略,不依赖环境模型和先验知识。近年来很多学者将强化学习用于无人车路径规划上面。Liwei Huang等在动态环境下基于强化学习进行车辆的路径规划和避障,将状态空间分为八个角度区间,动作域分为三向前、左转和右转三个动作,并加入ε-贪婪策略改进了奖励函数,实现了无人小车导航,但是该方法未考虑后退动作,难以解决若前方堵死时车辆如何选择动作的问题,还有避让的路线是折线,并不是光滑的,与现实车辆行驶路线不符;董培方等加入初始引力势场和陷阱搜索的改进Q-learning算法,在其基础上对环境进行陷阱区域逐层搜索,剔除凹形陷阱区域Q值迭代,加快了路径规划的收敛速度,搜索到较好的路径,但是其收敛速度还有待提高,规划的路径也可能不是最优的;张明雨利用代价地图的cost信息来构建状态空间,动作空间,奖赏函数和值函数,然后对移动机器人进行训练,获得Q值表,然后在后面的导航过程中遇到障碍物时,用学习到的策略选择动作,避过障碍物,使用代价地图结合Q-learning算法来修改全局路径实现机器人的动态导航;张汕播等针对未知环境,利用情感学习机制辅助强化学习系统,给出算法在当时环境下的决策空间,实现agent的实时决策,最后将强化学习模型和A*算法结合构建路径规划系统。
现在大部分的无人驾驶车辆都是在无人区域或者简单的道路环境下行驶的,但是现实的路况都是实时变化的,障碍物分布随机且多,我们希望在复杂动态环境下无人车辆能自主搜索出合适的路径并自主避让障碍物。
三 DDPGwD 算法框架
本文采用组合运动规划方法进行无人车的行为规划。运动规划的组合方法通过连续的配置空间找到路径,而无需借助近似值。组合方法通过对规划问题建立离散表示来找到完整的解,首先使用路径规划器生成备选的路径和目标点(这些路径和目标点是融合动力学可达的),然后通过优化算法选择最优的路径。
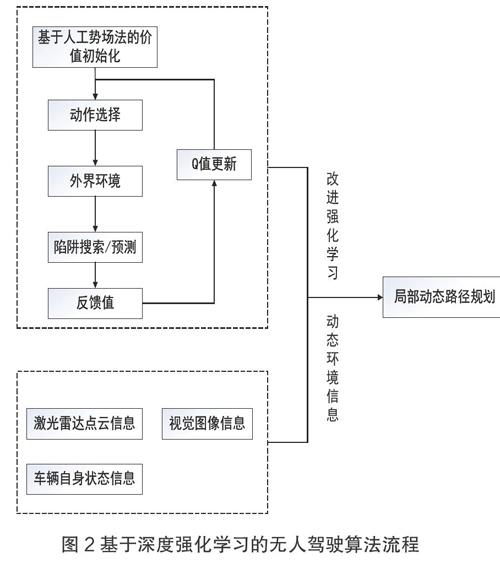
在大规模学习时强化学习普遍有收敛速度慢、规划效率低的缺点,对于无人车辆来说,其“试错”机制可能会使车辆撞击到障碍物,不能直接应用于真实环境中。针对上述问题,拟加入人工势场法对环境的势能进行赋值作为搜索启发信息对Q值进行初始化,从而在学习初期便能引导移动机器人快速收敛,提高规划效率,使用摄像机、激光雷达等识别周围环境,结合强化学习进行动态的路径规划,流程图如下:
利用强化学习解决机器人路径规划问题时,机器人会在相应的环境中“试错”学习,在执行动作的同时会得到相应的奖励,考虑动作选择和回报的马尔科夫过程称为马尔科夫决策过程。强化学习的各种方法都是以马尔科夫决策过程(MDP)为基础的。
S:表示系统环境状态的集合;
A:表示Agent可采取的动作集合;
P(s|s,a)描述在当前状态s∈S下,Agent采取动作a∈A,转移到s∈S的概率;
R(s,a)表示在状态s下Agent执行动作a后获得的奖赏值;
目标就是求出累计奖励最大的策略的期望。
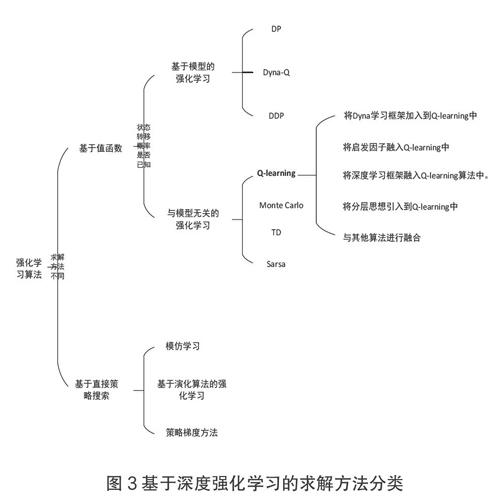
根据求解方法不同,强化学习的算法主要分为两大类:基于值的算法(Value-Based)和基于策略的算法(Policy-Based)。
四 试验验证
(一)环境因素分析
外界环境因素作为无人驾驶车辆的主要信息输入,对无人驾驶过程中的环境感知、系统决策,路径规划和系统控制都有十分重要的影响。外界环境因素本身也是一个庞大而且复杂的系统,从广义上讲,外界环境因素主要包括静态环境因素和动态环境因素。其中静态的环境因素有不同类型的道路和交通标志、道路上和两边的场景以及静态障碍物等;动态的环境因素有车辆、行人、交通信号灯以及动态障碍物等。
1.结构化道路
影响无人驾驶车辆的主要静态环境因素是道路和静态障碍物,道路两旁的建筑和场景对于车辆路径规划的影响较小,故本文不做讨论。其中道路又分为结构化道路和非结构化道路两种,在结构化道路中又有直道、弯道、十字路口、Y型路口、环岛、主干道的出口和入口以及这些要素的组合道路等,对于非结构化道路本文不做讨论。
①直道,作为结构化道路中最简单的组成元素,是结构化道路主要的存在形式,大多数的道路都是以尽量直道的原则建造。直道又分为单车道和多车道,直道的边界都是直线,主要的参数是道路的长度、宽度和边界位置等信息。车辆在直道上行驶的方式较为固定,一般是直行、换道行驶,同时采取一些避障行为。
②弯道,通常作为道路的连接,弯道也是典型路况中的典型组成元素。由于其特殊性,弯道是交通事故的多发地。所以在做无人驾驶车辆的局部路径规划时,要着重考虑车辆在弯道的曲率值下的行驶能力。车辆在弯道上行驶的类型一般是沿着弯道作转向行驶。
③汇入和汇出道路,两条或者多条道路的合并形成汇入道路。单条道路分成多条道路形成汇出道路。车辆在汇入汇出道路上,一般会进行变道和避障行驶。
④十字路口,两条或者多条道路相会产生十字路口,无人驾驶车辆的路径规划主要考虑来往车辆和行人。车辆在十字路口上,一般有转向、调头和直行等行驶方式。
⑤U型路,U型路通常是曲率比较大的弯道,有可能出现在双向直道上需要调头的位置。和弯道相类似,车辆在U型路上,一般是沿着U型路作调头行驶,和彎道不同时是,转向角度更大,目标点一般在身后。
2.行人
行人在道路上行走一般具有很大的随意性,是道路交通上的不确定因素,同时由于行人缺少相应保护,往往在发生交通事故时会受到较大的伤害。行人在道路上行走一般可以分为两类,一类是沿着道路行走,另一类是横穿道路行走。由于行人具有随意性,无人驾驶车辆如何检测和避让行人是研究的重点和难点之一。
为了验证DDPGwD最终训练得到的模型泛化性,我们在微软开源仿真平台测试轨道中进行了测试,轨道形状及场景如下图所示,无人车能够顺利地完成整圈的驾驶。
综合上述仿真实验,我们提出的DDPGwD算法能够合理地解决无人驾驶的决策控制问题,并且通过引入示教监督数据,能够在相同的奖励值函数下、在一定量的训练回合中获得比原始DDPG算法更多的训练步数,可以更快地学到一个相对合理的策略。在弱化奖励值函数后,我们提出的算法效果虽有所下降,但相较于DDPG算法仍然能够维持在一个较高的训练水平。
五 结语
本文介绍了基本深度强化算法原理,分析了DDPGwD算法作为无人驾驶车辆局部路径规划与决策算法的优缺点。针对无人驾驶车辆使用DDPG算法进行局部路径规划的缺点,提出了基于场景约束的DDPGwD规划方法,在此基础上设计了基于示教学习与深度强化学习融合的路径节点修剪与优化方法,最后结合整车转向控制模型对路径进行了进一步的优化。
