
基于分步遗传算法的压力变送器排产优化
2019-04-15 03:50包伟华
应用技术学报 2019年1期
赵 婧, 包伟华
(1. 上海电力学院, 自动化工程学院, 上海 200090; 2. 上海自动化仪表有限公司, 技术中心, 上海 200072)
车间调度是优化生产的关键,是指在尽可能满足约束条件(如工艺路线、资源情况、交货期)的前提下,通过下达生产指令,安排其组成部分(操作)所使用的资源,加工时间及加工的先后顺序,获得产品制造时间或成本等的最优化。由于仪表类订单主要的特点为批量小,品种多,单台产品生产周期较长,且存在半成品可销售的情况,故采用部分库存准备。这种半成品可销售可库存的车间生产模式,突破了工序唯一性限制,从而使得作业车间调度问题更复杂。
基于瓶颈分析思想构建的启发式算法[1],已经用于许多车间调度问题的求解。在解决生产调度问题和其他复杂的组合优化问题中,元启发式智能算法是很有效的方法,其中包括遗传算法、粒子群优化算法、模拟退火算法等。其中,遗传算法是通过模拟自然界生物遗传过程和选择过程,通过产生编码,初始种群,交叉遗传,变异等适者生存的过程,产生优化解。因其通用性强,计算性能优良,隐含并行性好,全局搜索能力佳等诸多特点,遗传算法广泛应用于车间调度问题的求解。Li等[2]提出针对车间生产的特殊性,通过设计基于动态过程编码的遗传算子,保留最优指标,实现柔性作业的标准遗传算法,满足灵活的工作任务调度要求。赵诗奎等[3]提出了基于工序的染色体编码方式,染色体中的工序位置顺序和实际的调度工序实际加工顺序一致,从而能够体现每台机器上的工序实际加工顺序。田旻等[4]提出采用分层混合遗传算法,在初始化种群时根据目标函数分为不同质的2层,即精英层和普通层,针对2层采用不同的灾变和邻域搜索求解,提高了遗传算法局部领域搜索能力和增强种群的多样性。
在实际生产中在订单生产周期长、批量小的情况下,如果不考虑订单组合生产的情况,就有可能会丢失一部分可行解。并且在压力变送实际生产过程中,存在多种量程器件,某个工序阶段不使用同种设备,需要在初始化阶段进行处理。在实际生产过程中,一旦分配好了工序,就将该车间调度问题转化为传统车贷的调度问题,从而降低了算法的复杂度。
本文在研究分析某厂压力变送器生产过程及对工序瓶颈分析的基础上,提出基于传感器部件的量程分类件进行哈希除去余数法插入种群初始化,并基于工序和数量进行编码的分层分步遗传算法,降低此车间调度问题的复杂度,将其转换为类似流水车间调度问题。与原工厂排产策略相比,减少了订单最小完成时间,提高了生产效率。
1 生产过程瓶颈分析及其模型建立
在生产过程的基础上,针对生产过程分析瓶颈工序和建模是排产优化的重要组成部分。
1.1 压力变送器生产过程描述
压力变送器的生产存在订单批量小,规格品种多,单台生产时间周期长的特点,并且在半杯体生产过程中,半杯体的量程存在不确定性的问题。压力变送器具体生产过程如图1所示。
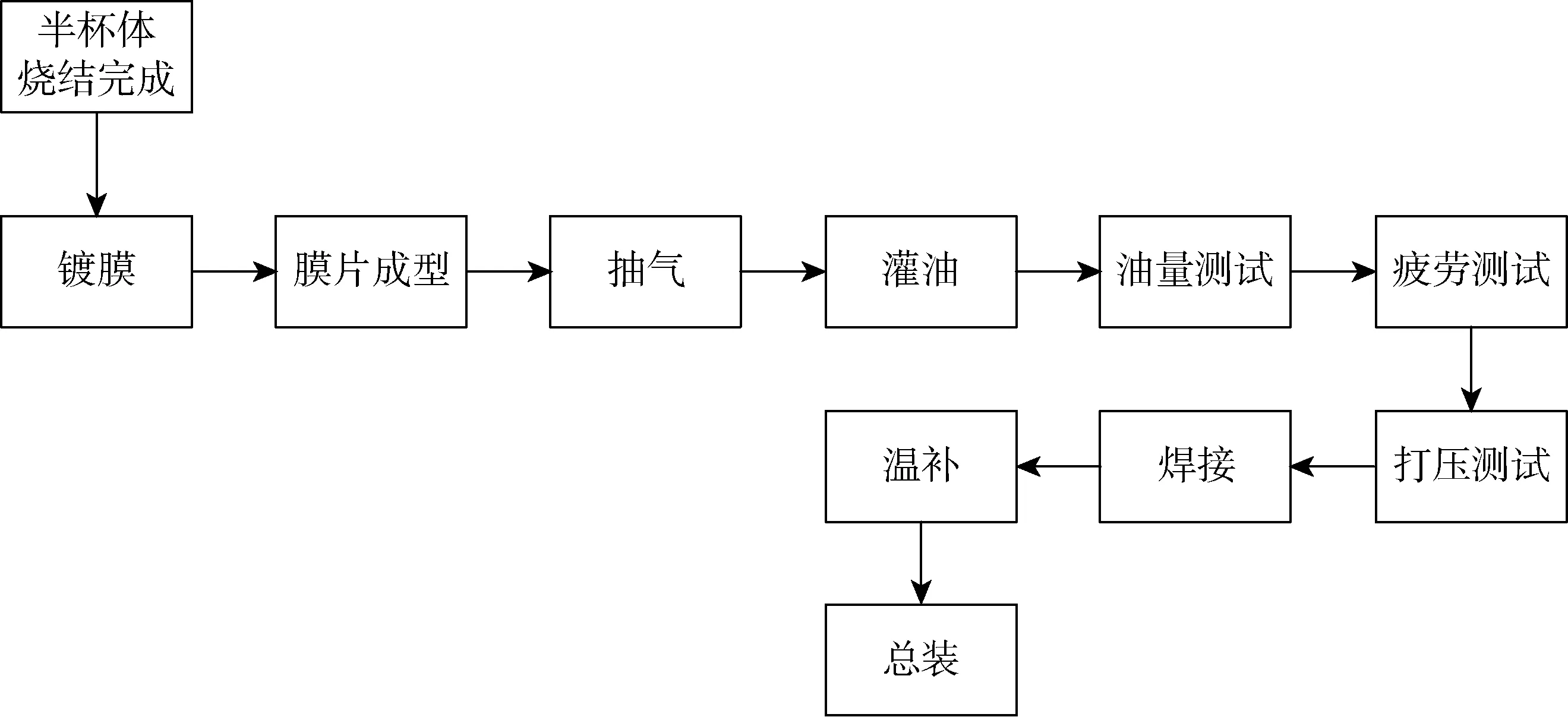
图1 压力变送器生产流程图Fig.1 Production flow chart of pressure transmitters
1.1.1 半杯体的制作
半杯体制作可以分为烧制、检验分类、精加工3个阶段。烧制一般为批量生产,1批生产 4 500 个,烧制后根据人工检验将量程粗分为3个等级,普通量程4的数量较多,特殊量程3和5的数量较少。经过精加工以后,普通量程4的半杯体可覆盖6种规格传感器,特殊量程3的半杯体可覆盖2种规格传感器,而特殊量程5仅可覆盖1种规格传感器。
每个半杯体的人工检验分类,平均花费约5 min,且不存在机器损坏情况。
1.1.2 膜盒的制作
2个相同量程等级的半杯体为膜盒的原料,膜盒制作分为镀膜、膜片成型、抽气、灌油、油量测试、疲劳测试等工序。每个工序至少有2台机器同时工作,但必须严格按照工序加工,镀膜工序需要 5 min;膜片成型工序需要10 min;抽气工序需要 3 h,但无需考虑数量限制;灌油工序1次最多45个,每次需要6 h;油量测试工序需要5 min;疲劳测试工序需要5 min。膜片成型工序存在 1.5% 的报废率,灌油工序存在4%的报废率。膜盒可以作为产品进行单独销售。
1.1.3 传感头装配
传感头装配包括打压测试和焊接等工序,每个工序有2台机器同时工作,每件传感头在打压测试和焊接工序各需要花费约10 min。
1.1.4 温度补偿
传感头的温度补偿工艺,要求在3个温度点(20 ℃,-20 ℃,70 ℃)进行全量程范围压力(包括:0%,25%,50%,75%,100%)的检测及标定。从一个到另一温度点的稳定时间约为2 h,每个温度点的压力检测时间约为10 min,因此每个传感头的温度补偿过程一般需要5~6 h。
1.1.5 总装
每台压力变送器的总装及检验需要15 min,由1人完成,不存在机器损坏情况。
在所有机器运行正常的情况下,其中排产模型还需要遵循以下约束条件和前提[5]:
(1) 每个工件都必须在原料准备好的情况下才能加工;
(2) 每个量程等级的每个工序结束后,成品或半成品都服从离散正态分布;
(3) 本道工序必须在前一道工序有足够的成品或半成品,或前一道工序完成后才能进行;
(4) 同一时刻同一机器只能加工1个工件;
(5) 将半杯体检验分类以后的半成品视为原材料;
(6) 同一道工序,不同机器的生产时间一致;
(7) 在加工过程中,机器正常运行(不会存在故障情况);
(8) 排产前已知半成品和每个量程等级的半杯体的数量。
本文还将考虑,在已知某1个或几个机器坏的情况下,排产模型需要遵循以下假设:
(1) 不会出现同一工序所有机器都损坏的情况;
(2) 机器故障是排产前已知的;
(3) 加工中不存在机器损坏的情况。
1.2 瓶颈分析及模型建立
根据上述生产过程分析,本模型将压力变送器整机和半成品可卖期间分为普通量程和特殊量程,由于抽气和灌油单次不能多于45个,且45个一起完成,其他工艺可单个生产,且用时较短,因此认定抽气和灌油工序,在此生产过程为制约生产的瓶颈工艺,在考虑报废率的基础上,以42个实际完成工件为1组进行生产,并且根据半成品是否可卖,加工时间,将工序简化。以普通量程4的压力变送器为例,简化后每道工序及其所需的时间如表1所示。
表1普通量程生产过程及时间

Tab.1 The process and time of general range productionh
特殊量程3和5的压力变送器,由于需求少(假设每个订单不会超过45个),抽气和灌油则1个订单为准,加工时间相对较长,则按订单进行生产,特殊量程简化后生产工序时间如表2所示。
表2特殊量程生产过程及时间
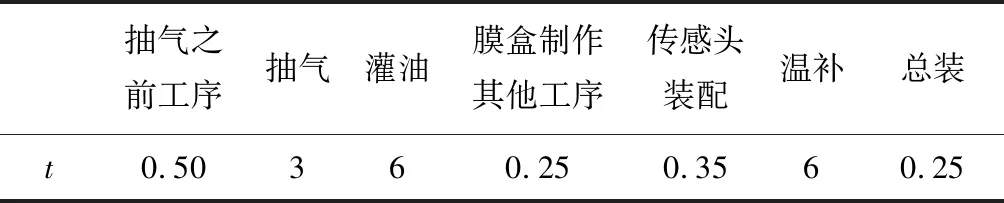
Tab.2 The process and time of special range productionh
根据订单情况,将成品和半成品分为6类:普通量程膜盒,特殊量程膜盒,普通量程传感头,特殊量程传感头,普通量程压力变送器,特殊量程压力变送器,分别用W1~W6表示。
表3每个成品和半成品的生产过程及时间
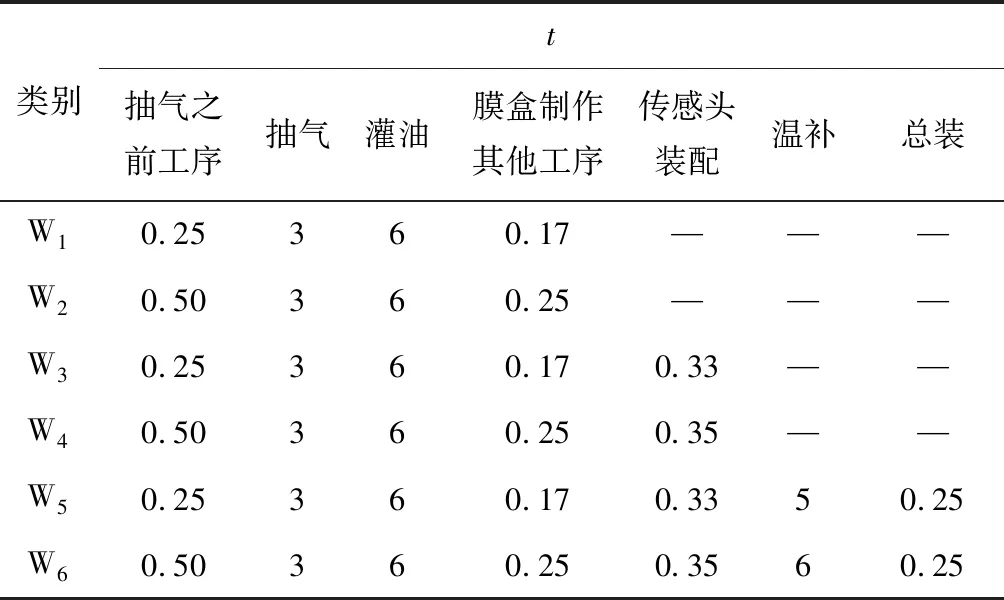
Tab.3 The process and time of products and semi-finished productsh
2 遗传算法设计
遗传算法采用染色体上的基因寻找好的染色体来求解问题,具有隐含并行性和全局解空间搜索的特点,在生产调度中得到广泛的应用。遗传算法包括5个关键要素:编码和解码、适应度函数、初始化种群、遗传操作(交叉和变异)和参数设置。
经典的遗传算法应用于调度问题,步骤如下:首先基于工序进行编码[6],其次随机产生N个可行解,N种群规模,然后计算个体的适应度,评价个体的使用度,判断是否达到终止条件,若满足,则输出搜索解,否则按选择策略选择下一代种群规模N,按交叉概率PC执行交叉操作,按变异概率PM执行变异操作,产生新的种群。返回到计算个体的使用度步骤循环直到得到满足适应度的优质解[7]。
本文以订单为基础,以最小完成时间为目标函数。订单集合为O:{O1,O2,…},其中每个订单信息,包括2个元素:On{产品类型wi,生产时间Ti},每个订单可含多个产品类型。本文以完成订单为目标,可建立以下目标函数:
(1)
根据工序的特点,且半加工产品可卖,将采用分步遗传算法。即将订单为普通量程的整机和特殊量程的整机作为第1环节,利用遗传算法进行调度生产,其次订单为普通量程的传感头和特殊量程的传感头作为第2环节进行调度生产,最后订单为普通量程膜盒和特殊量程膜盒作为第3环节进行工序安排。
2.1 编码与解码
基于订单数量和种类标识对每个订单进行分组编码,基于瓶颈工艺中灌油最多为45个,考虑到不良率为4%~6%,将相同的产品订单以42个为单位分组,如果42个产品都来自同一订单,则采用2位数编码,例如11、12、21等,十位数表示来自第几个订单(先将订单按交货时间,进行排序)。个位数1、2、3、4、5、6分别表示普通量程膜盒、特殊量程膜盒、普通量程传感头、特殊量程传感头、普通量程压力变送器,特殊量程压力变送器。若42个产品来自于2个订单,则采用5位数编码机制,例如 12281,万位数和百位数表示来自第几个订单,千位数和十位数表示2种产品分别占总的比例,个位代表产品类型。12281 表示这个组产品中第1个订单的数量为42的20%、第2个的订单数量为42的80%,只保留1位小数。染色体采用单链编码的方式(11,12,13,21,22,23,11,22,12281),11出现2次说明1号订单需要84个膜盒,分为2组进行处理调度排产。
2.2 初始化种群
(1) 基于温度补偿环节,特殊量程的器件和普通量程的器件可以分别在 1151 温度补偿装置和 3151 温度补偿装置上同时进行补偿,因此尽可能使得特殊量程和普通量程交替生产,基于订单将需要温补的特殊量程和普通量程分别进行,随机产生50个序列:
(a1,a2,…,aj,…),(b1,b2,…,bj,…)
其中:aj表示第j个普通量程的器件,bj表示第j个特殊量程的器件。
(2) 采用哈希算法中除去余数法:
h(k)=k%p
(2)
根据式(2)将序列(b1,b2,…,bj,…)插入到序列(a1,a2,…,aj,…)中,得到整体初始化序列{ij}:
(i1,i2,…,ij,…)
并计算每个订单所需时间:
(3)
式中:TOj表示第j个订单O所需要的时间。然后计算这批订单总的时间,选择出总时间最小的序列:
(…,im,…)
im代表1个订单编码,在式(3)的基础上计算每组序列时间总和
Tk=∑TOj
(4)
迭代50次,得到序列矩阵{im},序列对应的时间矩阵{TOm}和总时间矩阵{Tk}:
(5)
式中:im代表1个订单编码;TOm表示第m个订单O所需要的时间;T1表示第1组序列对应的时间总和。
2.3 分层交叉选择
2.3.1 分层交叉
根据总时间将矩阵分为精英层和待改善层[8],如果采用双亲染色体交换,则会产生出现工件工序重复或缺失情况[9]。因此,采用单亲交叉的方式,将待改善层对应序列进行单亲交叉,即随机交换2个订单序列的位置,如下式所示:
(i1,i2,…,im,…,in,…)→(i1,i2,…,in,…,im,…)
(6)
将第m个订单序列和第n个订单序列进行交换,其中im表示某个订单的编码。
2.3.2 选择
针对待改善层的选择采用锦标赛的方式进行基因的选择随机产生1个[0, 1]的数,如果>0.5,则胜者留下来,如果<0.5,则败者留下来[10]。
最终得到新的排产序列矩阵{im}及与之对对应的时间矩阵{TOm},和最小总时间矩阵{Tk}:
(7)
式中:im代表1个订单编码;TOm表示第m个订单O所需要的时间;T1表示第1组序列对应的时间总和。
2.4 分步遗传算法
采用分步遗传,每一环节的初始化是基于前一环节的算法结果。基于上述遗传算法流程和压力变送器生产流程及产品出售情况,将整个调度排产进行分步遗传计算,首先利用上述遗传算法,将整机生产订单进行排序及时间计算,即将编码以5、6结尾的2位数和编码以5、6开头的5位数的订单序列,进行排序及时间计算。在计算结果的基础上,加入编码以3、4结尾的2位数和编码以3、4开头的订单序列,进行排序及时间的计算,在此基础上,再加入编码以1、2结尾的2位数和编码以1、2开头的5位数的订单序列,进行排序及时间计算。最终将50组计算结果分为精英层和待改善层,针对待改善层,进行选择交叉。最终得到整批订单的生产序列矩阵{im},序列对应的时间矩阵{TOm}和总时间矩阵{Tk}:
(8)
将得到的整个时间序列进行排序,即获得整体生产时间最小的生产时间
(9)
式中,T1表示第1组序列对应的时间总和。
进而得到对应最小生产时间Tmin的时间订单生产序列{im}和时间序列{TOm}:
(i1,i2,…,im,…)(TO1,TO2,…,TOm,…)
(10)
式中:im代表1个订单编码,TOm表示第m个订单O所需要的时间。
综上所述,分步分层遗传算法步骤如下:
(1) 基于订单数量和种类标识将同种类型订单以45个为1组进行分组编码。
(2) 将特殊的器件和普通量程的器件进行分别初始化,随机产生50组订单生产序列{ai},{bi},再采用哈希算法中除去余数法,将{bi}插入到{ai},得到最终的初始化订单生产序列{ij}。
(3) 根据目标函数计算每组序列的生产总的时间Tk=∑TOj,根据总的生产时间将订单生产序列分为精英组和待改善组。
(4) 针对待改善层随机交换2个序列的顺序,产生新的订单生产序列,再采用锦标赛的方式进行基因选择随机产生1个[0, 1]的数,如果>0.5,则胜者留下来,如果<0.5,则败者留下来。
(5) 经过选择后,产生新的50组生产序列,在此基础上,增添前1道工序,重复步骤(2)。
(6) 当所有工序都添加完成,并经过上述算法,最终得到整体的订单生产工序{im}和对应的生产时间{Tk},将生产时间进行排序得到最小的生产时间Tmin。
分步遗传算法流程图如图2所示。

图2 分步分层遗传算法流程图Fig.2 Flow chart of step-by-step hierarchical genetic algorithm
3 仿真算例
以某天实际获得的订单为例,采用上述算法,对订单进行排序与时间计算,分别求得这批订单的总体所需要花费的时间,验证算法的可行性。
订单详情如表4所示。
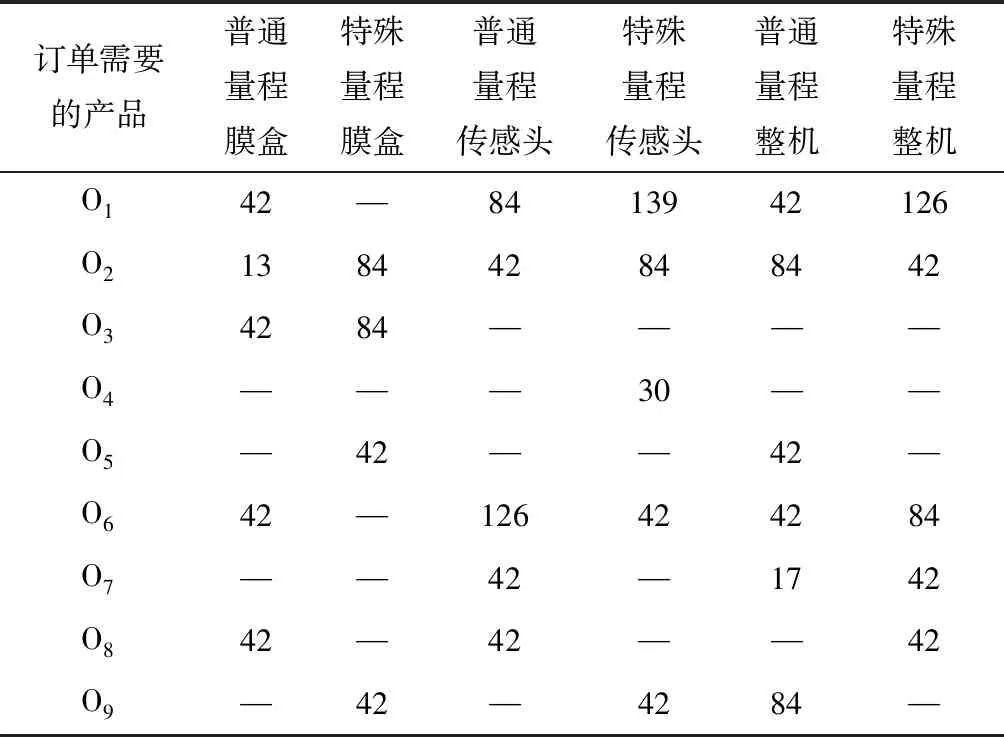
表4 仿真模拟订单详情Tab.4 Simulated order details 个
在Matlab2013的平台上,对上述遗传算法进行仿真,并且为了方便测试,直接将这批订单利用基于遗传标识订单数量和种类编码方式拆分好的订单序列,再基于分步规则,将订单序列分为如下情况:
生产普通量程的整机和特殊量程的整机序列为
(15,25,25,55,65,95,95,51 374,16,16,16,26,66,66,76,86,86,86)
生产普通量程的传感头和特殊量程的传感头序列为
(13,13,23,63,63,63,63,73,83,14,14,24,24,64,94,41 347)
生产普通量程的膜盒和特殊量程的膜盒序列为
(11,31,61,81,13 723,22,22,32,32,52,92)
将这些序列作为分步遗传算法的输入,这里将基于分步遗传算法得到50组订单序列矩阵和时间序列矩阵,获得整体生产时间最小的生产时间:
(11)
所对应的订单序列如下:
生产普通量程的整机和特殊量程的整机序列为
(26,55, 66,25,16,25,66,15,76,15,86,95,16,
95,66,65,66,51 374,86,65,16,55)
生产普通量程的传感头和特殊量程的传感头序列为
(24,83,24,13,14,13,64,23,14,73,94,63,41 347,63,63)
生产普通量程的膜盒和特殊量程的膜盒序列为
(52,61,31,22,13 723,32,22,11,92,81,32)
总体耗时为765 h,将最小生产时间对应的订单序列和时间序列,在Teambition中转化为甘特图如图3~5所示。

图3 生产普通整机和特殊整机的甘特图Fig.3 Gantt chart for general products and special products
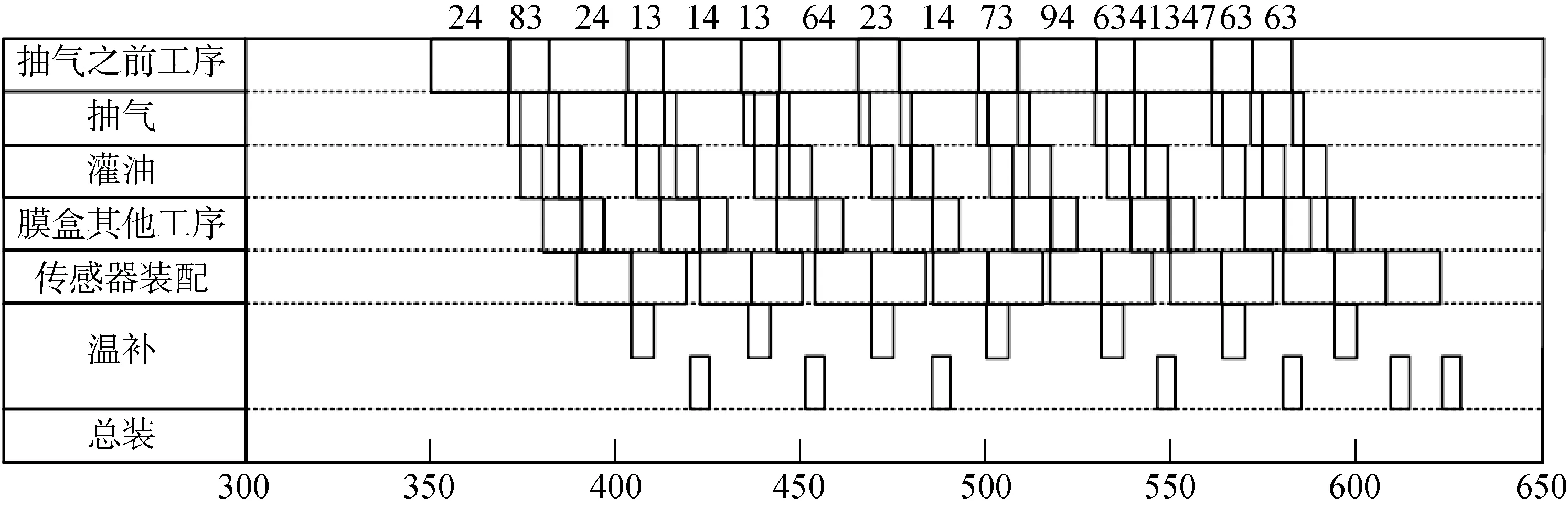
图4 生产普通传感头和特殊传感头的甘特图Fig.4 Gantt chart for general sensing head and special sensing head

图5 生产普通膜盒和特殊膜盒的甘特图Fig.5 Gantt chart for general capsule and special capsule
车间原先采用排产的规则为先到的订单先生产,即先生产订单1,再生产订单2,依次类推。如相同订单,遵循原先排产策略,则每个订单时间花费如表5所示。
表5根据工厂原先生产调度规则每个订单所需时间

Tab.5 The time required for each order according to the factory's original production scheduling rulesh
同一批订单,若按工厂原先生产调度原则,所需要的时间为 1 049.5 h,基于本文提出的分步遗传算法进行调度,所需时间为765 h,生产效率提高了 27.10%。仿真验证结果表明,此算法可以提高生产效率,优化车间生产调度。
4 结 语
本文针对开放式生产过程的压力变送器生产流程,在分析瓶颈工艺的基础上,采用分步分层遗传算法,将原来复杂的开放式生产过程转化为流式生产过程,使得排产过程变得相对简便,另外Matlab仿真验证结果表明,与原来根据订单顺序决定生产顺序的生产调度策略相比,本文提出的基于分布分层遗传算法的生产调度策略,提高了车间生产效率,有利于进一步提高准时交货率,提高产品的竞争力。
猜你喜欢
军民两用技术与产品(2021年7期)2021-10-13
煤气与热力(2021年4期)2021-06-09
河北农机(2020年10期)2020-01-08
电子制作(2018年12期)2018-08-01
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
通信电源技术(2016年1期)2016-04-16
现代计算机(2016年34期)2016-02-28
智能系统学报(2015年4期)2015-12-27
汽车科技(2015年1期)2015-02-28
自动化博览(2014年12期)2014-02-28
