
基于混合像元分解方法的康保县植被覆盖度估测
2019-04-15 03:15:10陈振雄
中南林业调查规划 2019年1期
陈 松,孙 华,陈振雄,吴 童
( 1.中南林业科技大学林业遥感信息工程研究中心,长沙 410004; 2.林业遥感大数据与生态安全湖南省重点实验室,长沙 410004; 3.南方森林资源经营与监测国家林业局重点实验室,长沙410004;4.国家林业与草原局中南调查规划设计院,长沙410014)
植被覆盖度是衡量地表植被状况的重要指标,早期的植被覆盖度调查方法采用传统的地表实测法,分为目测估算法、采样法、仪器法、模型法[1-2]。但是地表实测法的工作量大,耗时耗力,不适于进行大范围的测算。随着遥感技术的不断发展,遥感测量已成为监测植被覆盖的主要途径[3-6],地表实测法则逐步成为了遥感测量的辅助手段,遥感测量植被覆盖度常用的方法有回归模型法、植被指数法和混合像元分解。回归模型法是利用单一波段或者几个波段的遥感数据,计算出植被覆盖指数和植被覆盖度,并通过回归分析得到相应的植被覆盖统计模型,然后根据空间的外延模型进而推求更大范围的植被覆盖度[7-8]。植被指数法是根据植被的光谱特征,选择与植被覆盖度有良好相关性的植被指数,然后通过数据分析,得出植被指数与植被覆盖度之间的关系来估算出植被覆盖度[9-11]。混合像元分解是在某种假定的比例关系下,将图像中的一个实际像元分解成由多个组分构成的遥感数据信息,利用得到的遥感数据信息从而构建像元分解模型从而进行植被覆盖度的估算[12-14]。相比于前两种方法,混合像元分解的优点是其便于大范围的遥感估测且不过多依赖实际数据,可有效减少人力和物力的消耗且易于使用和推广。
1 研究区概况
本文研究区是中国河北省张家口市西北部的康保县, 114°11′—114°56′E, 41°25′—42°08′N。县域东西跨度最大达80 km,南北跨度最大达62 km,总面积3365 km2。地势由东北向西南缓缓倾斜,北部、东部为丘陵区,南部为波状平原区,平均海拔1 450 m。丘陵地区无高山峻岭,山头秃圆,山坡平缓,山间广布谷地、盆地。南部广大地区为波状平原,地形开阔,地势平坦[15-16]。截至2018年,康保县林地面积共126299 hm2,其中乔木林32417 hm2,疏林地218 hm2,灌木林地34975 hm2,未成林地6550 hm2,苗圃地961 hm2,宜林地面积51178 hm2,县森林覆盖率为20.2%。
2 材料与方法
2.1 影像数据的获取与处理
研究使用的遥感数据为Langdsat8 OLI,接收时间为2014-08-01。数据共有11个波段,本次研究仅用到前7个波段,分辨率均为30 m×30 m。
2.2 样地的调查
研究区内共布设样地134个(图1),抽样间隔为5 km×5 km,样地大小为30 m×30 m,在样地中心及对角线位置选出5个1 m×1 m的小样方进行调查。在小样方内,用皮尺分别在东西和南北方向上测量,以10 cm为间隔观察是否有植被覆盖。以两次测量的均值为植被覆盖度,同时记录植被的高度。
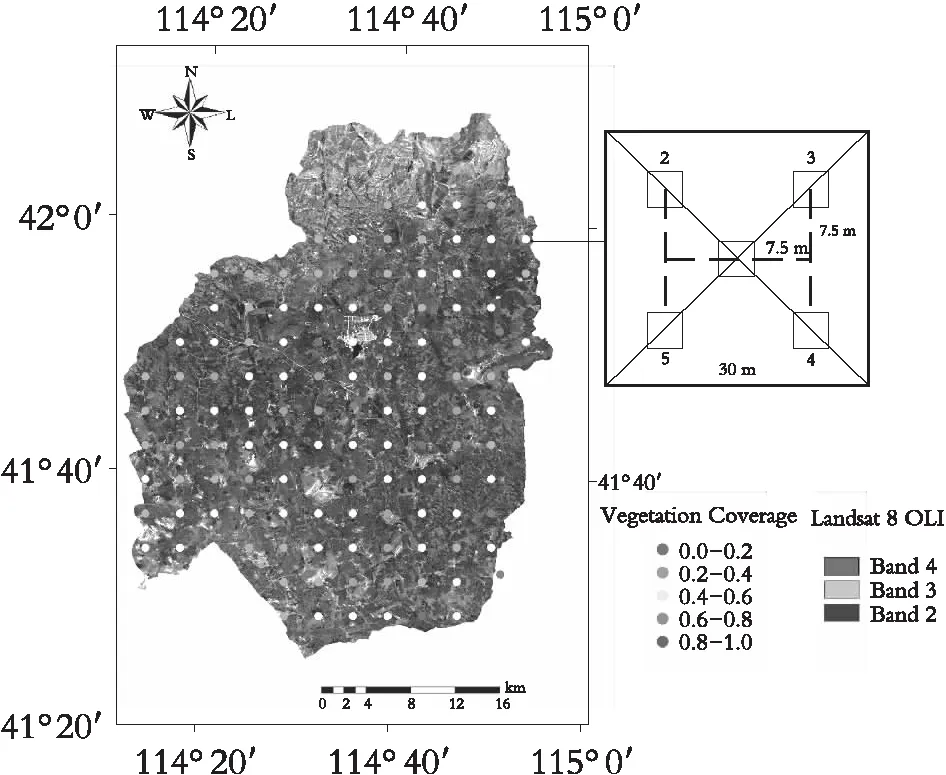
图1 样地布设图
2.3 植被覆盖度的反演方法
2.3.1 像元二分法
通过Compute Statistics对归一化差值植被指数(Normalized Difference Vegetation Index,NDVI)影像进行统计,以NDVI为5%和90%的累计率作为NDVImin和NDVImax,用以替代NDVIsoil和NDVIveg。将整个研究区分为三个部分:当NDVI小于0.047 848时,VFC取值为0;当NDVI大于1.742240时,VFC取值为1;当NDVI在两者之间,使用公式

2.3.2 完全约束最小二乘法
在混合像元分解中,基于线性的混合像元分解是认为在遥感影像中各个像元反射率的值是像元内的每个地物反射率按照线性关系组合而成的。因此线性方程的权重可认为是纯净端元的面积与该像元的总面积的比值。
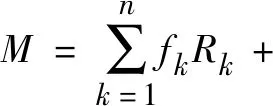
式中,n为混合像元内端元的总数;ε为残差项[26-31]。
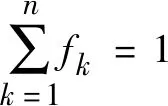
2.3.3 随机森林
随机森林是多个决策树组合而成的模型。决策树是一种树形结构,在进行分类时,每次分类判定就像树的分枝节点一样把后续树枝分开,而后的每一个分枝就代表了一个分类结果。随机森林在分类中返回得票数最多的分类选项,在回归中返回所有决策树输出的平均值。随机森林模型分类效果优于多元线性回归,并且不需要预先给定模型的形式假定[33-35]。提取出NDVI、增强植被指数(Enhanced Vegetation Index,EVI)、差值植被指数(Difference Vegetation Index,DVI)、比值植被指数(Simple Ratio Index,SR)等15个植被指数,再分别与实测数据通过回归分析做相关性分析,同时对它们进行自相关分析。选出自相关性较小且与实测数据相关性较大的4个植被指数:SR13,RGVI,DVI31和DVI21;再用这4个植被指数建立随机森林模型。
3 结果与分析
3.1 像元二分法
将研究区分为NDVI
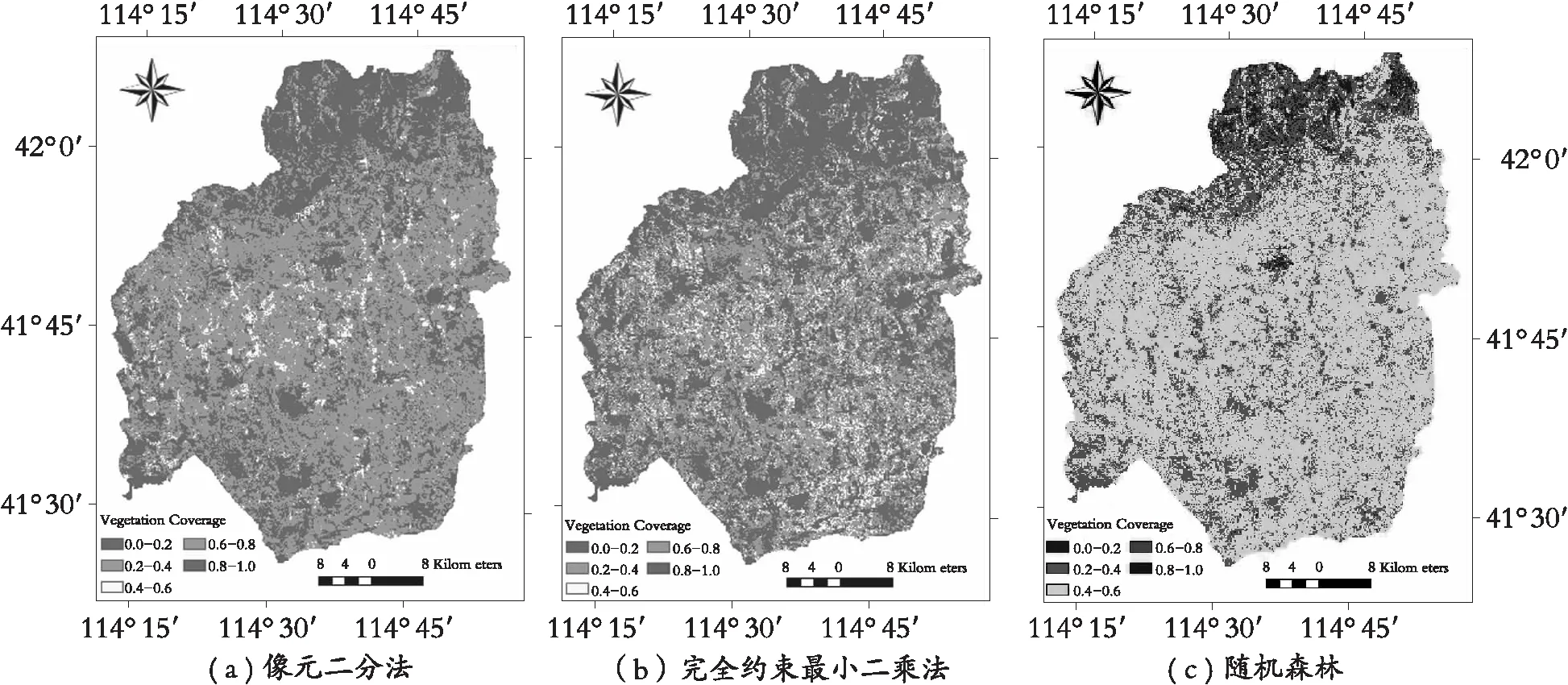
图2 植被覆盖度反演图
3.2 完全约束最小二乘法
通过对原线性光谱模型添加两个限制条件,导出植被覆盖丰度fk,得到研究区植被覆盖的混合像元分解图(图2(b)),获得研究区植被覆盖度预测结果。由图2(b)可知,研究区的植被多分布在研究区中部地区,另外在研究区的边界附近也有部分的植

表1 三种估测方法的精度比较估算方法R2RMSEI/%像元二分法0.6840.2435.27完全约束最小二乘法0.6840.2189.43随机森林0.6640.1276.25
被密集区,与图1进行比较发现其县域中部地区的植被覆盖度较高,通过计算RMSE为0.218(表1),表明混合光谱分解后像元中各地物丰度值和原始图像相同像元中各地物的丰度之间存在较大的误差。
3.3 随机森林
通过随机森林模型得到研究区植被覆盖的混合像元分解图(图2(c)),获得研究区植被覆盖度预测值,通过对图2(c)与图1的比较,发现两幅图像的植被覆盖丰度大致相同,通过计算得出此模型的RMSE为0.127(表1),表明混合光谱分解后像元中各地物丰度值和原始图像相同像元中各地物的丰度之间误差较小,估算结果较为精准。
3.4 模型精度评价
模型的精度主要从两个方面进行检验,一是预测数值与实测数值的拟合度R2(图3);二是对三种模型的预测结果进行残差分析(图4),用均方根误差RMSE作为检验标准,结果显示混合光谱的效果随着RMSE的减小而精度越来越高(表1)。
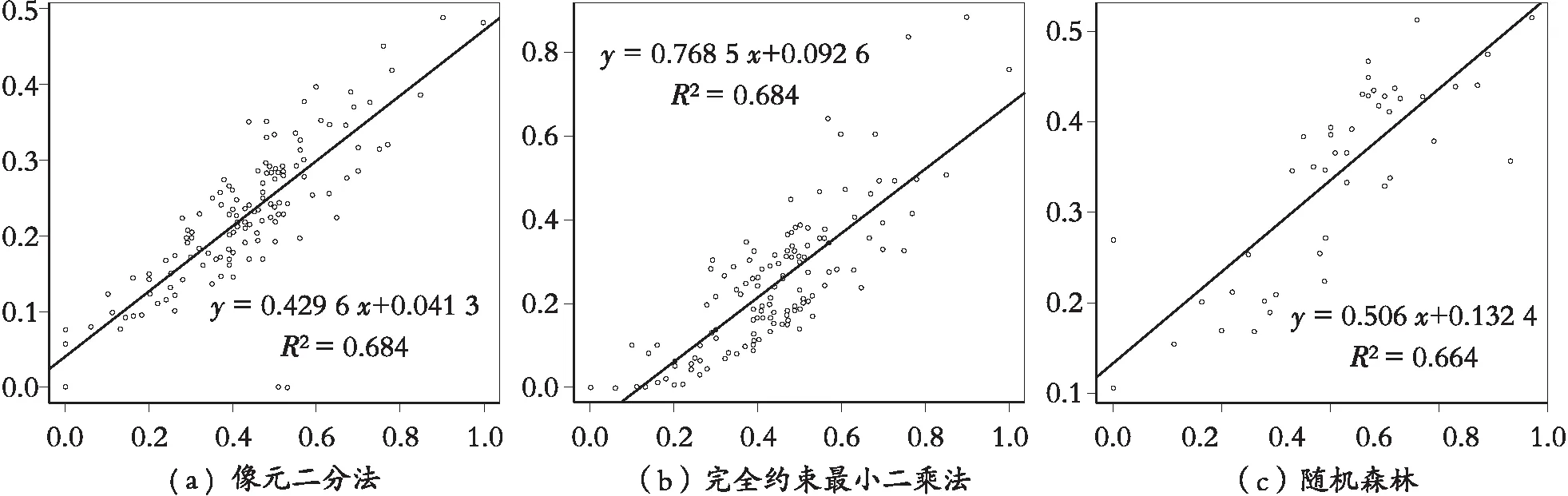
图3 线性拟合图
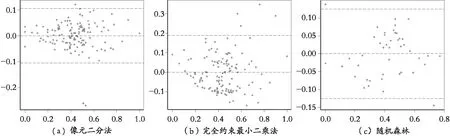
图4 残差分布图

4 结论与讨论
4.1 结论
使用landsat8 OLI数据,采用像元二分法、完全约束最小二乘法混合像元分解和基于随机森林模型的混合像元分解对康保县植被覆盖度进行估测,结合地面调查结果,利用预测值与实测值的回归分析和均方根误差对三种估测方法进行拟合分析与精度验证,得出以下结论:
1)采用基于混合像元分解的方法进行植被覆盖度的估测能够较为便捷和精准地对植被覆盖度进行估测,这将是以后大尺度监测地表植被覆盖的有效迅捷手段。
2) 基于随机森林的混合像元分解模型的精度高于像元二分法与完全约束的最小二乘法混合像元分解模型,表明基于非线性的模型能够更加精准地对地表植被覆盖进行监测,因为其限制条件更加严格,需要结合部分地面实测数据来进行随机森林模型的构建。
4.2 讨论
像元二分法和完全约束最小二乘法混合像元分解的R2均较高,但是它们的RMSE都较大,精度偏低,分析原因可能是:
1)由于研究区为荒漠化地区,在进行像元二分法时,NDVImin过小,NDVImin和NDVImax差值过大,近似为1.7,因而在使用公式VFC=(NDVI-NDVImin)/(NDVImax-NDVImin)计算植被覆盖图时将NDVI累计率在5%~90%之间的值近似地除以了1.7,导致原本植被丰度高的区域在预测图像中的植被丰度较低,集中在了0.4~0.6,因此与实测数据产生了偏差。
2)在进行完全约束最小二乘法混合像元分解时,忽略了植被与地面间的二次反射,因此在混合像元分解时将一些原本的其他地物归到了植被范畴,导致其中部区域的植被覆盖密度相对较大,与实测数据产生了偏差。
猜你喜欢
科学技术创新(2022年30期)2022-10-21 14:01:24
农业与技术(2021年23期)2021-12-14 09:03:32
中国交通信息化(2021年1期)2021-06-11 01:23:44
中学生数理化·自主招生(2021年3期)2021-05-30 10:48:04
中学生数理化(高中版.高考理化)(2021年3期)2021-05-21 02:10:20
原子与分子物理学报(2020年5期)2020-03-17 06:59:18
水土保持研究(2018年5期)2018-10-12 05:29:52
中国农业信息(2018年2期)2018-07-28 08:02:10
中学生数理化·七年级数学人教版(2018年3期)2018-05-30 06:58:16
西藏科技(2015年1期)2015-09-26 12:09:29
