
基于卷积神经网络图像识别算法的加速实现方法
2019-04-13 06:51秦东辉赵雄波
航天控制 2019年1期
秦东辉 周 辉 赵雄波 柳 柱
1.北京航天自动控制研究所,北京100854 2.宇航智能控制技术国家级重点实验室,北京100854
随着计算机性能的不断提升,以及学术界对机器学习领域研究的逐渐深入,卷积神经网络(convolutional neural network,CNN)成为了近年以来热门的机器学习算法之一,1989年LeCun在论述其网络结构时首次使用了“卷积”一词[1],“卷积神经网络”也因此得名。CNN通过卷积和池化操作自动学习图像在各个层次上的特征,这符合我们理解图像的常识。人在认知图像时是分层抽象的,首先理解的是颜色和亮度,然后是边缘、角点、直线等局部细节特征,接下来是纹理、几何形状等更复杂的信息和结构,最后形成整个物体的概念[2]。CNN在早期被成功应用于手写字符图像识别。2012年更深层次的AlexNet网络[3]取得成功,此后卷积神经网络蓬勃发展,CNN在数字图像处理领域取得了巨大的成功,从而掀起了深度学习在自然语言处理领域(Natural Language Processing, NLP)的狂潮,近年来卷积神经网络,在视频监控,机器视觉,模式识别,图像搜索等领域得到了更为广泛的应用[4-6]。
由于CNN中特定的计算方法,在通用处理器上运算效率较低,很难达到满意的性能。事实上,CNN作为一种前馈网络结构,层与层之间具有高度的独立性:各层网络计算独立,层间无数据反馈。因此,CNN是一种高度并行的网络结构,通用处理器为执行逻辑处理和事务处理而优化的特性并不适合用来挖掘CNN的并行性,基于软件方式的CNN神经网络在实时性和功耗方面都不能满足实际应用中小型化、手持化的需求。当前的卷积神经网络加速器研究主要是基于GPU,但由于GPU本身的高功耗问题,并不适合电池供电的嵌入式环境[7]。为了充分挖掘卷积神经网络固有的可并行性,越来越多研究人员开始采用FPGA开发基于卷积神经网络的应用,以获得功耗和计算性能的最佳平衡。文献[8-10]通过RTL语言完成了小型CNN网络的硬件加速工作,使用FPGA在50~100Mhz的频率下完成了约十余倍的性能提升,但是设计基于RTL级的FPGA加速器开发周期较长,尤其随着近年来提出的新算法网络逐渐加深,沿用传统RTL语言进行加速的成本成倍增加,而使用高层次综合(HLS)技术可以解决这些问题[11],通过HLS编译器会自动将高级语言(如C / C ++)转换为RTL级代码,可以以较少的时间和成本设计硬件加速器,而由于软硬件工作原理的区别,往往需要对C代码进行一定的重构,例如,在本工程中,由于卷积操作对数据读后写(RAW)的依赖性,直接对算法进行硬件加速无法满足期望的性能。本文采用重构算法循环次序的方案解决了RAW依赖问题,并且设计了内存I/O的优化方法及参数化的并行指令以满足期望的性能。
1 图像识别算法原理
本文使用了Hironsan于2016年提出的SensorNet,该卷积神经网络结构如图1所示,算法网络由3个卷积层(Conv),3个池化层(Pool),1个维度转化层(Flatten)层,1个全连接层(FC)组成,激励层(Activation)均采用Relu函数。图像经缩放处理至64*64*3像素,经该神经网络计算后,输出多个分类数值,通过SoftMax层确定识别概率,分类标签的数量可根据训练集不同进行配置,在本文中分类标签数量为6,各层参数及计算量见表1。
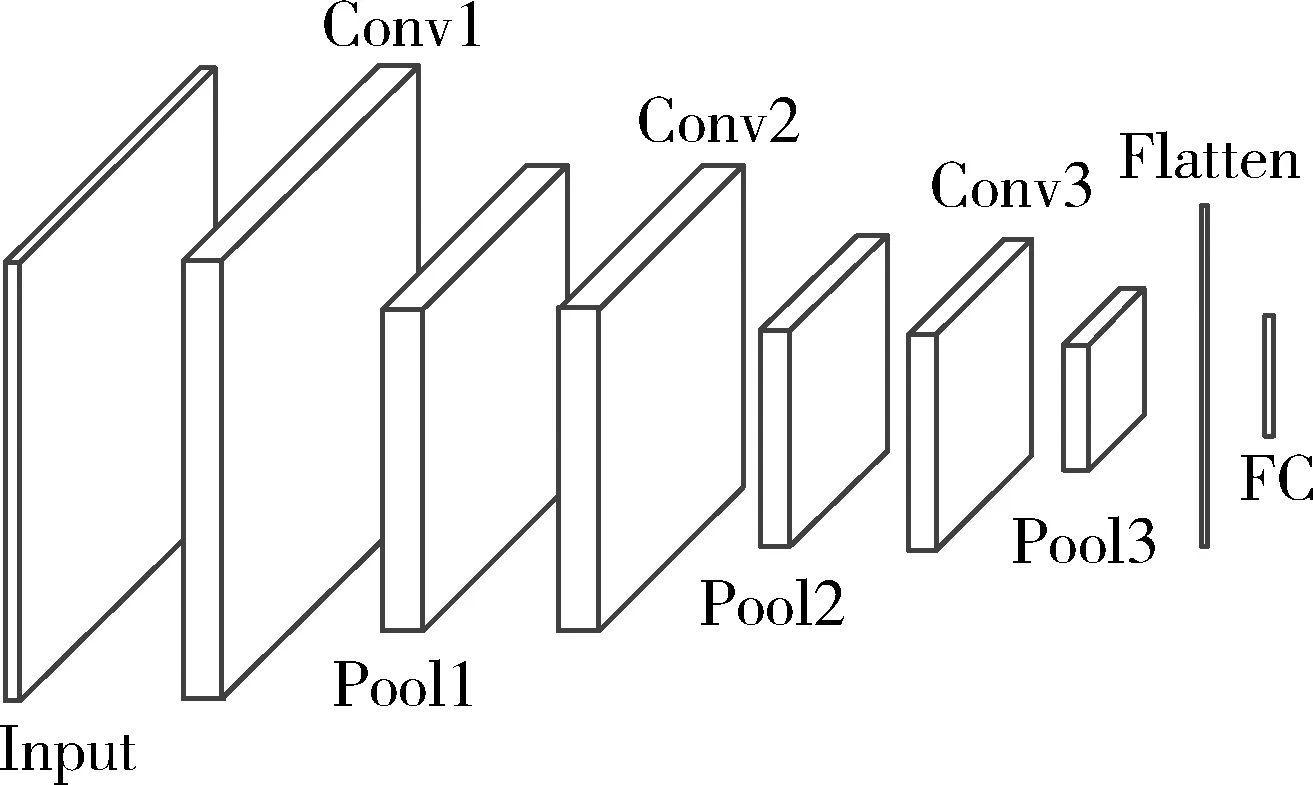
图1 图像识别算法网络结构
2 软硬件协同设计
使用的片上系统(SoC)平台包括Block RAM(BRAM),查找表(LUT),触发器(FF)和数字信号处理器,称为可编程逻辑(PL)以及基于四核ARM处理器的处理系统(PS),软硬件功能划分见图2,网络的卷积层、池化层、全连接层均使用SDSoC添加至FPGA中进行加速,ARM处理器包含预处理模块和数据整理模块,前者负责从SD卡读取图像、标签、权重等数据,对数据进行预处理,并完成数据对PL端的写入工作,后者整理PL端各层硬件计算时间,接收分类结果、计算标签匹配数量,并将数据整合为报告写入SD卡,实现了通过PS端对PL端的控制。
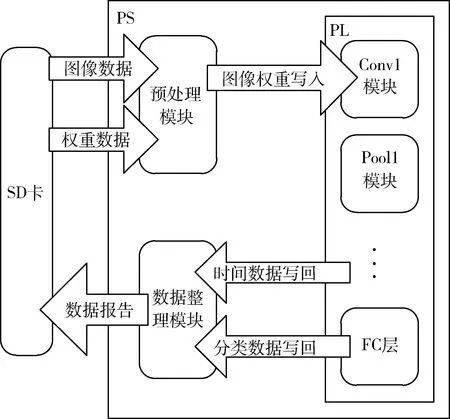
图2 软硬件结构划分
2.1 数据加载优化
FPGA在访问外部存储器时会有较大的延时,使用不合理的数据传输方法会对算法的性能造成较大影响。以卷积层为例,本文在PS 端和PL端使用流数据传输来减少延时。数据加载部分的相关编译指令如下:

#pragma SDS data mem_attribute(input_feature:PHYSICAL_CONTIGUOU)#pragma SDS data access_pattern(input_feature:SEQUENTIAL)#pragma SDS data zero_copy(input_feature)
SDS Data mem_attribute指令用于规定SDSoC编译器在内存块里为数组分配的存储空间是物理上连续的。那么,SDSoC编译器会在综合中选择AXI_DMA_Simple而不是AXI_DMA_SG,因为前者在传输物理上连续的内存时更小更快。
SDS data access_pattern用于规定数据访问模式,因为卷积输入中所有元素为流式访问,而不是随机访问,如果访问模式设置为SEQUENTIAL,则将生成流接口(例如ap_fifo)。否则,使用RANDOM访问模式,将会生成一个RAM接口。
SDS data ZERO_COPY编译指示意味着硬件通过AXI主总线接口直接从共享存储器访问数据。
同时使用上述3条编译指示,可令编译器使用在内存中连续分配存储空间,并为参数合成AXI Master接口,减少数据传输延迟,提高处理性能,在本文中,输入输出图像及权重偏置信息均通过此方式加载。
2.2 卷积操作优化
通过创建多组硬件逻辑的方式对算法中的循环进行展开。在本文中,改善卷积层的性能使用下述代码的结构。将Input channel循环(第10行)完全展开,并行计算所有输入层的权重乘积,作为一个独立的处理单元(PE),将output channel(第7行)展开作为PE的并行数量,用来一次获得多个输出层的部分和,并且使用input channel作为最内层循环来简化卷积层的硬件结构,以最小化单个PE核。
通过使用#pragma pipelining向硬件逻辑添加流水线功能以增加硬件吞吐量。某些循环叠放顺序将会使多个操作同时尝试访问和更新同一个变量,从而产生RAW依赖关系,例如将kernel row或kernel col循环(第3,4行)位于output channel的正上方,则会对循环累加结果产生RAW依赖,使流水线启动间隔(initiation interval)偏高,影响综合性能。故如代码段所示使用output col(第6行)作为output channel(第7行)正上方的循环,以消除输出缓冲区的RAW依赖性。
2.3 卷积层内存I/O优化
将kernel row与kernel col作为外层循环,在卷积神经网络的每个卷积层计算中不反复更新权重和偏置数据。在本文中,通过一次性将权重和偏置传输到片上缓冲区,用减少外部存储器和PL之间的数据传输开销来提高性能。

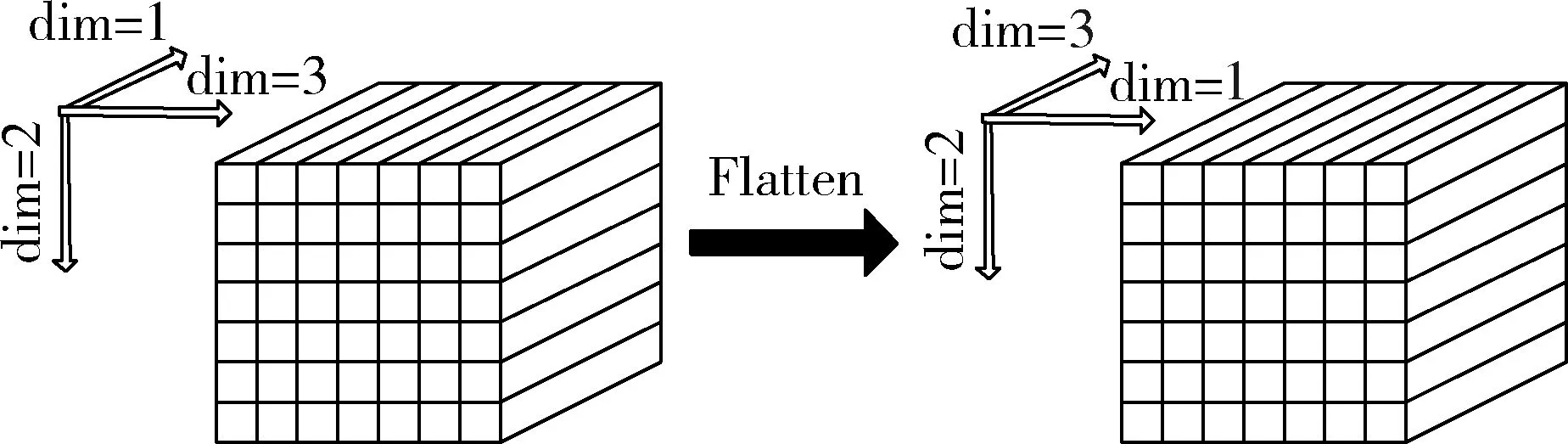
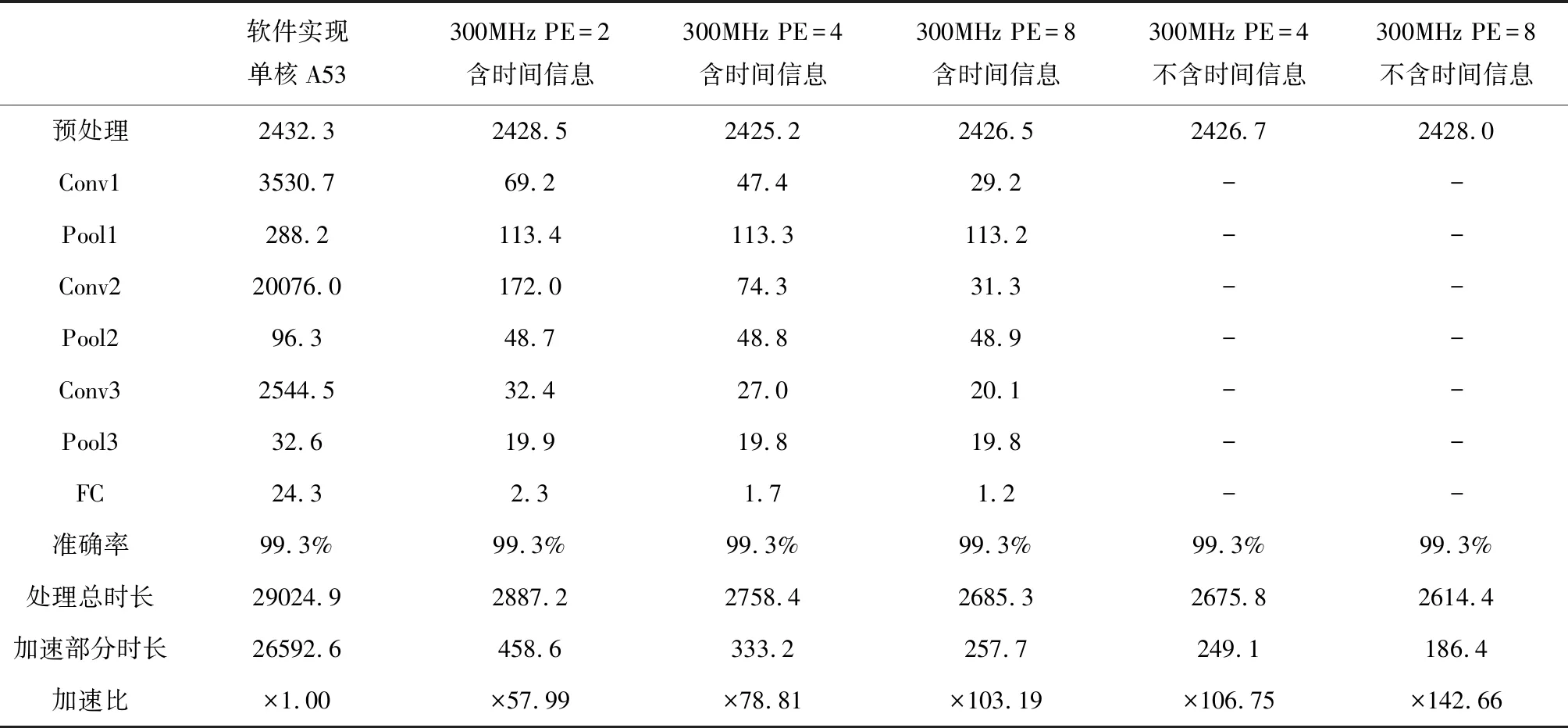
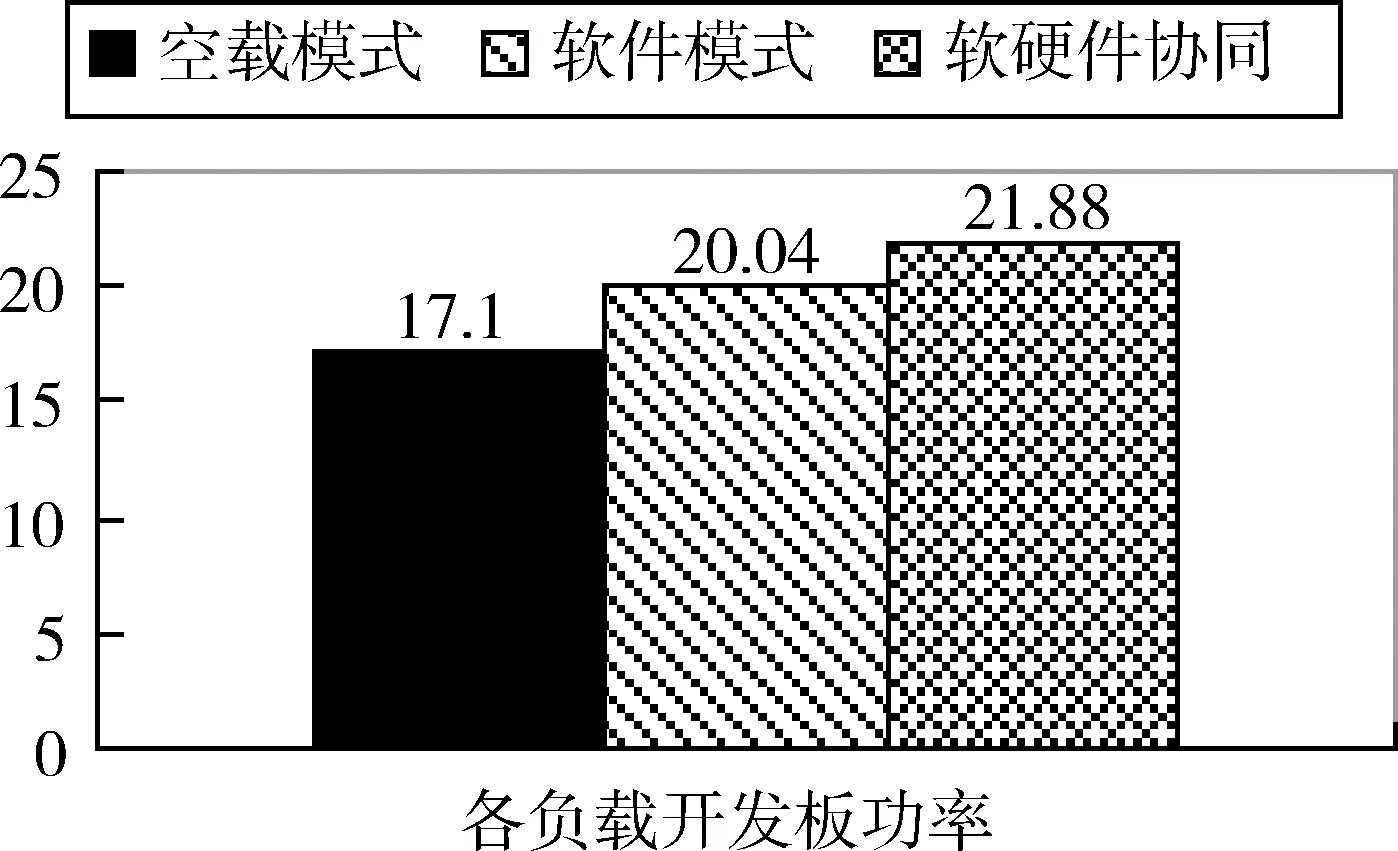
1: //load input feature map to on-chip buffer2://load weight & bias to on-chip buffer at 1st iteration3:for(i=0;i 采用设置中间变量的方式防止流水线出现RAW依赖(第7~10行),拆解语句使2*2最大池化块通过3次二值比较的方式并行执行的方式(第11~13行),并在内层循环加入#pragma pipeline指令,使循环流水线展开,未添加流水线及添加流水线但启动间隔不同的时序如图3所示: 图3 流水线指令展开 1://load conv_output data to on-chip buffer2:for(int ci=0;ci 在硬件实现中通过改变Input数组维度直接完成Flatten层的排列,其余部分优化方式与卷积层相似,在此不再赘述。 图4 Flatten数组维度变化 我们使用Xilinx ZCU102嵌入式开发平台以人脸识别为例进行实验,ZCU102 PL端搭载了Zynq Ultra Scale XCZU9EG-2FFVB1156FPGA芯片,PS端为四核 ARM? Cortex-A53,数据为单精度浮点。ARM Cortex-A53的工作频率为1200MHz,PL端的工作频率为300MHz。使用视频摄像头采集到有标签的5个人物各1000张照片、未添加标签的其他人物1000张,共6000张照片,经过OpenCV截取人脸部分并缩放为64*64*3像素送至网络进行训练。另外,使用10组带有标签的照片,每组100张,共1000张测试该网络的性能及准确率。 性能测试时,进行了6组实验:使用单核ARM Cortex-A53处理方案;PL端频率为300MHz,并行计算单元数量PE=2/4/8三组带有时间信息返回的软硬件协同方案;以及300MHz下PE=4/8,硬件加速单元整合为单一函数,且不带有时间返回的2组软硬件协同方案进行加速比较。从PL端逐层返回计算中间结果和时间信息会对各层性能产生一定影响。网络各层运算速度统计及加速比见表2。 Zynq Ultra Scale XCZU9EG计算资源丰富,包 括:18K大小的Block RAM 1824个,查找表(LUT)274080个,触发器(FF)548160个和数字信号处理器2520个。5组进行硬件加速的实验资源使用情况如表3所示: 表3 不同参数配置下硬件资源使用情况 表2 不同参数配置下的网络性能(单位:ms/百张) 实验结果表明,各组软硬件协同设计方案(2~6组)功率相似,故仅对第1组Cortex-A53软件实现方案与第6组协同设计方案进行功率与功耗性能分析。 图4 各负载下开发板平均功率(单位:W) 图5 每百张图片开发板功耗(单位:J) 使用SDSoC对一种基于卷积神经网络的人脸识别算法的所有网络层进行了硬件加速设计,通过对PE单元并行化设计和存储器的I/O优化,提高了计算性能减小了外部存储器的访问。实验结果表明,提出的软硬件协同设计方案的性能远高于单独使用ARM Cortex-A53软件设计方案,在精度一致的情况下,加速比可达143,节约了88倍功耗。2.4 池化层优化


2.5 全连接层优化
3 实验结果分析
3.1 网络加速性能比较
3.2 硬件资源使用情况

3.3 功耗性能比较

4 结论
猜你喜欢
汉语世界(The World of Chinese)(2023年2期)2023-06-22
北京航空航天大学学报(2021年9期)2021-11-02
小学科学(学生版)(2020年2期)2020-03-03
电子制作(2019年11期)2019-07-04
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
公民与法治(2016年10期)2016-05-17
中国资源综合利用(2016年9期)2016-01-22
计算机工程(2015年8期)2015-07-03
