
基于数据挖掘技术的档案馆信息快速分析算法研究
2019-04-13 03:03甘璐
现代电子技术 2019年7期
甘 璐
(中国科学院合肥物质科学研究院,安徽合肥 230031)
0 引 言
档案是指人们在各项社会活动中直接形成的各种形式的具有保存价值的原始记录。档案继承了文件原始记录性,所以档案具有历史再现性、知识性、信息性、政治性、文化性、社会性、教育性、价值性等特点,其中历史再现性为其本质属性,其他特点为一般属性[1]。随着档案事业的发展和档案信息化进程的加快,我国档案信息管理工作也日益成熟起来[2]。但是,随着数字化档案馆建设的不断推进,档案信息的存储容量迅速增加,目前的档案管理系统仅仅停留在简单的检索和统计阶段,根本无法有效满足人们的需求。档案信息的分析工作仍旧需要耗费大量的人工和时间成本[3]。数据挖掘是20 世纪90年代出现的一门交叉学科,涉及来自数据库技术、知识工程、概率与统计、模式识别、神经元网络、可视化技术等各领域的研究成果[4]。数据挖掘的本质目标是从大量、有噪声、不完全、模糊、随机的数据中抽取出隐藏的并具一定可利用价值的信息和关系。数据挖掘的功能和不同模式类型包括[5]:关联分析、分类和预测、聚类分析和孤立点分析。数据挖掘不仅可以对现有信息实现查询和遍历,并且可以发现现有信息之间的隐含关系,从而为决策提供必要的科学技术支持。
本文提出一种基于数据挖掘技术的档案馆信息快速分析算法。该算法采用熵加权对典型数据挖掘K-means聚类算法进行改进,以便有效解决数据集合维度和相似数据冗余的问题。实验结果表明,相比原始的K-means聚类算法,提出算法的聚类精度及运行效率较高。
1 问题表述
数据挖掘技术已经经历了十几年的发展,国内外不少研究人员已经将其运用于各种数字档案信息管理工作中。文献[5]对档案数据挖掘中数据采集与准备问题进行系统分析。在给出执行具体挖掘操作前的数据采集和数据预处理各个环节概念描述的基础上,探讨各个环节的注意事项及具体实现方法。文献[6]从日志文件到评估指标等多个方面,对使用数据挖掘学生档案信息进行了系统研究。通过现有研究结果可以看出,数据挖掘技术在档案信息管理系统中具有重要的应用价值,例如,发掘用户对哪些方面的档案更感兴趣(见图1);档案的分类等。
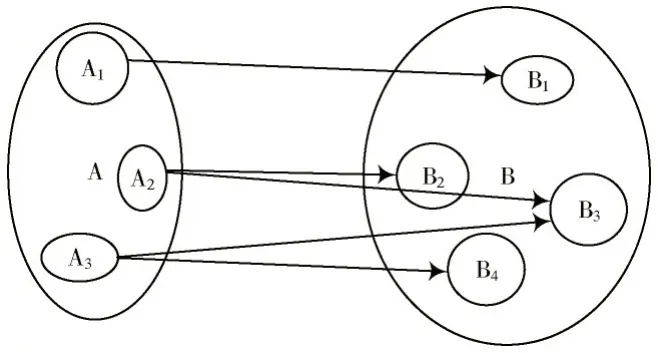
图1 档案与档案利用者关系Fig.1 Relationship between archive and archive user
因此,为了提高档案馆信息管理系统进行统计及分析的效率,设计了基于数据挖掘的档案馆信息系统工作流程,如图2 所示。
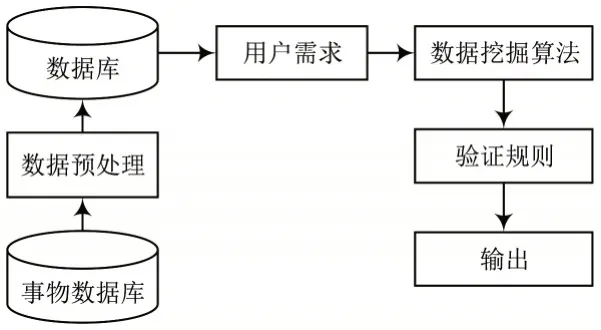
图2 基于数据挖掘的档案馆信息系统工作流程Fig.2 Workflow of archive information system based on data mining
2 采用的聚类算法及其改进
2.1 K-means聚类基本原理
作为一种基于距离的划分聚类算法,K-means 聚类算法具有算法结构简单、运行效率高且适用范围大等优点[7-9]。K-means 聚类算法一般通过式(1)所示的目标函数实现优化:
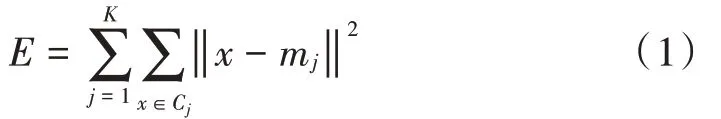
可以看出,式(1)所示的目标函数是一个误差平方和计算过程。其中,E为聚类准则函数;K为聚类的总数;Cj,j=1,2,…,K为聚类中的簇;x为簇Cj中的一个聚类目标;mj为簇Cj的平均大小。
K-means 聚类算法的输入参数为数值K和数据集X中聚类目标的数量n,输出为使聚类准则函数E达到最小的K个聚类。K-means 聚类算法的基本流程为:
1)输入参数并初始化K个聚类中心。
2)计算E的数值。
3)更新每个群集的中心并计算新E。
4)是否满足收敛条件。是,输出参数并结束;否,跳转到步骤2)。
通过上述典型K-means 聚类算法的原理和步骤分析,可以看出其具有一定的缺陷,在处理复杂的高维度数据时,算法的运行效率会大大降低,因此需要对其进行优化以便减少数据集合维度和去掉相似数据冗余。
2.2 聚类算法的改进
本文采用熵加权对典型K-means 聚类算法进行改进,首先定义聚类的目标函数:
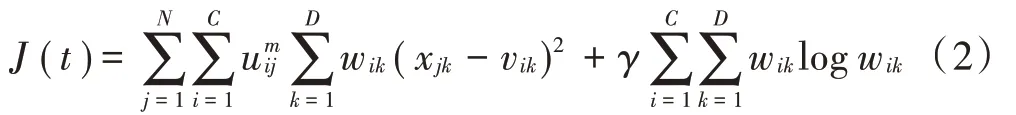
首先计算当前集合的隶属度:
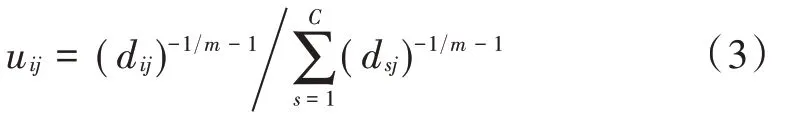
该数据集合的特征系数vik可通过式(4)得到:
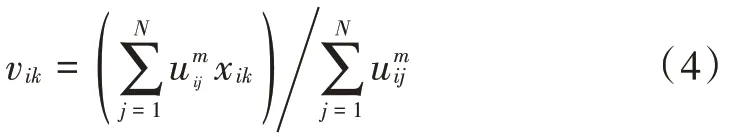
根据目标函数及式(3)可以计算隶属迭代:
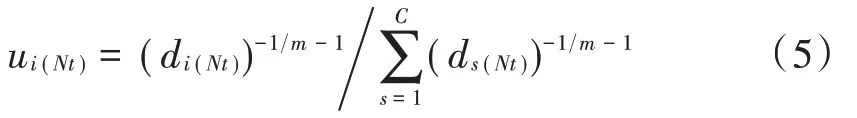
然后根据式(6)的结果推导聚类中心距离:
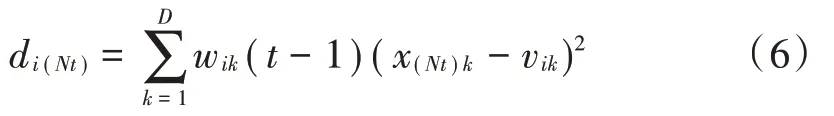
通过式(7)进一步计算t时刻的聚类中心值:
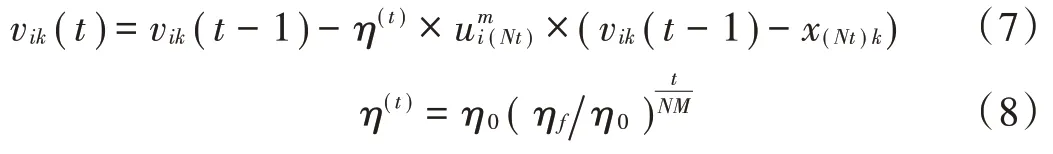
接着,通过式(9)计算熵加权系数[10]:
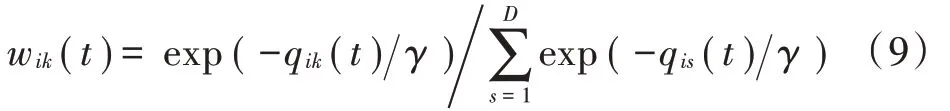
3 实验结果与分析
3.1 实验设置及评估指标
仿真实验环境配置为:Windows 7 操作系统,CPU为I7 处理器,6 GB 内存,Matlab 2010仿真平台。测试数据来自某档案馆近三年的历史文档,并随机选取了400 GB的数据,涉及多个类别。
此外,为了更直观地显示算法分类的性能,采用单一的F1测试值来评估改进聚类算法的性能,F1的计算公式如下[9]:

3.2 结果分析
典型K-means 聚类算法和本文算法处理档案信息数据集的结果对比如表1 所示。
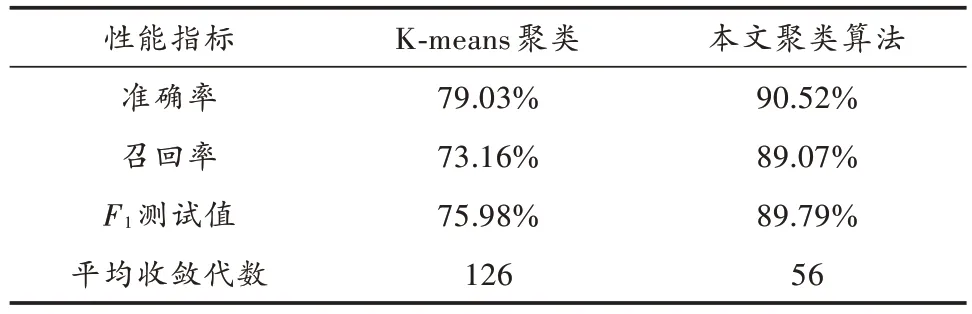
表1 档案信息数据集的实验结果Table 1 Experimental results of archive information dataset
从表1 可以看出,相比于典型K-means 聚类算法,本文提出聚类算法在准确率、召回率和F1测试值方面均有明显提高,分类结果的平均F1值约89.79%,在精度上能够满足实际应用需求。此外,本文聚类算法的平均收敛代数只需典型K-means 聚类算法的一半,因此数据挖掘的速度更快,验证了该方法的先进性。
4 结 论
本文提出一种基于数据挖掘技术的档案馆信息快速分析算法。分析了典型K-means 聚类算法解决数据集合维度和相似数据冗余的必要性,并采用熵加权对典型K-means 聚类算法进行改进。得出如下结论:相比原始的K-means 聚类算法,提出算法的聚类精度较好,分类结果的平均F1值约89.79%,在精度上能够满足实际应用需求;提出算法的运行效率较高,对档案管信息管理系统具有一定的参考指导意义。
猜你喜欢
小学生作文(低年级适用)(2022年10期)2022-10-31
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
大众投资指南(2021年35期)2021-02-16
现代临床医学(2021年1期)2021-01-26
电力与能源(2017年6期)2017-05-14
浙江档案(2017年10期)2017-03-31
信息通信技术(2015年6期)2015-12-26
档案与建设(2015年9期)2015-03-30
中学生英语·中考指导版(2014年9期)2015-03-30
电子设计工程(2014年18期)2014-02-27
