
一种大容量数据文件抽取算法的优化研究
2019-04-10 06:09:00张志强王伟钧
成都大学学报(自然科学版) 2019年1期
张志强,王伟钧,施 达
(1.成都大学 信息科学与工程学院, 四川 成都 610106;2.成都大学 模式识别与智能信息处理四川省高校重点实验室, 四川 成都 610106)
0 引 言
目前,很多企业生产经营过程产生的数据大都以文件形式保存在磁盘中,例如,金融企业及证券企业每日的金融数据、证券交易数据及股票交易数据等都会存储在数据文件中.有时,大容量数据会存储在单个数据文件中,从而产生很多大容量数据文件,且以xlsx数据格式为主[1-2].从这些大容量xlsx数据文件中抽取数据以构建数据仓库是企业数据挖掘的重要过程[3].虽然一些学者对相关问题的数据抽取技术进行了研究,并提出了不同的解决方案[4-7],但针对大容量xlsx数据文件的抽取算法研究相对较少.对此,本研究通过对常规数据抽取算法的策略进行优化,提出并设计了一种优化的大容量数据文件抽取算法.测试结果表明,该算法具有数据容量自适应抽取、数据快速写入数据库等特点,从而极大提高了大容量数据文件抽取的效率.
1 算法的优化设计
本研究的思路是:针对大容量数据文件的抽取,数据抽取算法应该具备数据容量自适应处理、自动抽取和数据快速写入数据库的特点,这样才使得大容量数据文件的数据抽取效率能够真正被提高.
1.1 数据容量自适应处理
当对xlsx数据文件进行数据抽取时,常规算法一般采用Apache的简洁版模糊实现(Poor obfuscation implementation,POI)组件的用户模式进行xlsx数据文件的抽取操作.由于该模式将xlsx数据文件中的所有记录数据以二维数据表形式一次性全部读入内存后再进行处理,当数据记录条数|records|>10 000时,会出现内存溢出的错误.对于很多大容量数据文件,其数据记录条数超过3万条(|records|>30 000),常规策略显然无法抽取这些大容量数据.为此,本研究对常规策略进行优化处理,使得算法具有数据容量自适应处理的能力.
当xlsx数据文件的记录条数未超过内存溢出的阈值时,算法采用常规POI组件的用户模式进行数据抽取操作.对于大容量数据文件的抽取操作,算法采用POI的XML简单应用程序接口(Simple API for XML,SAX)模式进行处理:首先,将xlsx数据格式转换为逗号分隔值文件格式(Comma-separated values,CSV)数据格式;然后,用SAX模式解析数据,这种方式的最大特点是不需要将文件中所有记录数据以二维数据表形式一次性读入内存,而是以设定的记录数据为单位抽取数据到内存,从而避免了内存溢出错误.由于SAX模式中需要确定xlsx数据文件记录列数,本算法采用自动确定的策略,其主要体现为:对大容量数据文件,首先利用SAX模式读取第1行记录数据,计算记录列数,然后再将列数值作为参数,利用SAX模式从第2行记录数据开始依次抽取数据.该策略使得算法具有大容量xlsx数据文件自适应性处理的特性.数据容量自适应处理流程如图1所示.

图1 数据容量自适应处理流程
1.2 数据写入的优化设计
数据写入的常规策略是从数据文件中每抽取1行记录数据后,并以该行记录数据为单位写入数据库.当抽取大容量数据文件时,由于抽取的记录数据量非常庞大,如果仍然采用常规的数据写入策略,其数据写入的速度较慢,那么数据处理的总体效率非常低.为了提高数据写入数据库的速度,本研究对数据写入的常规策略进行了优化设计,提出了一种数据写入优化策略.
在该优化策略中,提高数据写入数据库速度的关键部分是将xlsx数据文件中抽取的数据以数据块为单位写入数据库,每次将1个数据块一次性写入数据库,极大地提高了数据写入数据库的速度,从而解决了记录数据写入的低效率问题.数据写入优化策略的处理流程如图2所示.
在数据写入优化策略中,算法首先将xlsx数据文件中抽取的记录数据存储到内存表中,将内存表以k条记录数据为单位划分数据块,每次根据数据块号i获取数据块,然后以数据块为单位一次性写入数据库.其中,数据块datablock、分块数datablocks、内存表中记录数据的条数recordsizes之间的关系如式1所示.

图2数据写入优化策略的处理流程
(1)
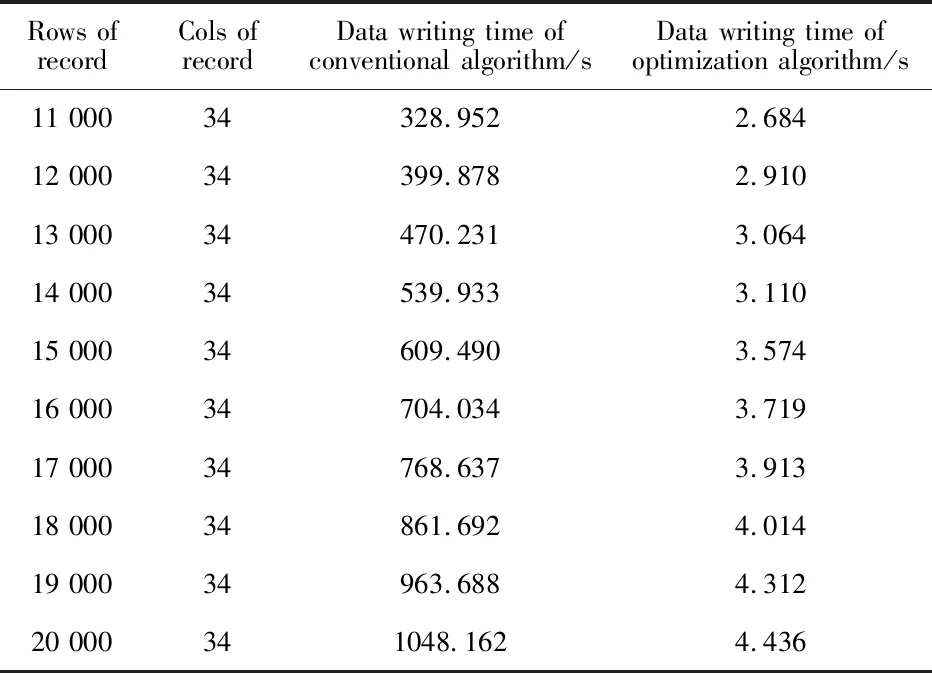
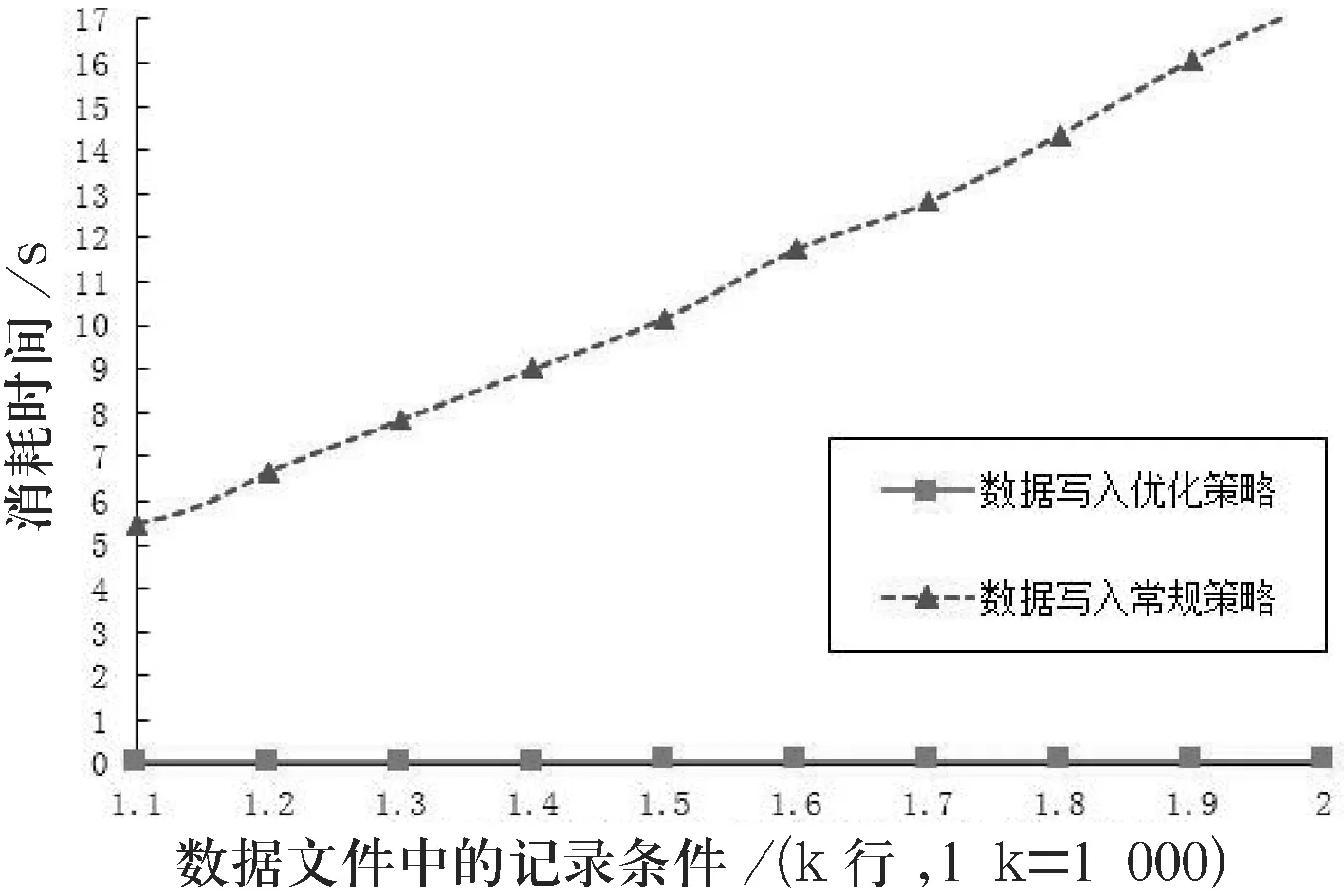
当内存表中记录数据的条数recordsizes 对内存表的记录数据进行分块读取时,数据读取位置按照分块进行变化,如式2所示, (2) 式中,offseti为第i个数据块在内存表中的数据读取位置. 大容量数据文件抽取算法的代码结构如下: Algorithm1 Large-Data-Capacity-extraction(log-datafilename) //log-datafilename:日志文件,记录数据文件的地址信息 begin 1:从log-datafilename获取数据文件datafilename的地址信息; 2:try{; 3:以POI的用户模式抽取数据文件datafilename的记录数据到内存表; 4:catch(内存溢出异常){; 5:以POI的SAX模式抽取数据文件datafilename的记录数据到内存表; 6:}; 7:清洗datafilename地址信息中的特殊字符; 8:以datafilename地址信息为名称在数据库中构建数据表datafilename; 9:以k为单位对内存表划分数据块; 10:i←1; 11:while i≤分块数do; 12:计算第i个数据块在内存表中的数据读取位置; 13:读出第i个数据块; 14:第i个数据块一次性写入数据表datafilename; 15:i←i+1; 16:end while; 17:释放资源; end 在测试中,Algorithm1算法采用Java、Apache的POI框架及JDBC接口编程实现;测试环境为:操作系统为Windows 7,CPU为Intel core i5,内存为12 GiB,数据库系统采用SQL Server 2008 R2,数据库服务器为localhost.本研究在实验中测试了算法的功能实现,并测试了数据的写入速度. 实验中,存储xlsx数据文件的地址信息日志文件如图3所示.“行情数据1.xlsx"的数据记录条数为10 000条,每条记录34列;“行情数据2.xlsx"的数据记录条数为45 000条,每条记录34列.通过Algorithm1算法的抽取操作,其数据分别存储在数据库的“dbo.c-6-行情数据1-xlsx"数据表和“c-6-行情数据2-xlsx"数据表,如图4和图5所示. 图3日志文件内容 图4数据库的存储形式 图5数据表的存储形式 从图3~图5可知,Algorithm1算法能够自适应数据文件的数据量并实现了自动抽取操作. 为了验证Algorithm1算法的数据写入优化的效率,本研究对算法的数据写入操作进行了测试.首先进行数据块的分块大小设置的测试实验,测试的xlsx数据文件的记录数据条数为10 000行,每个数据块设置后测试10次,测试结果如表1所示. 表1 数据块的分块设置测试结果 在表1中,Rows of record(datablock)为数据块的记录数据条数(数据块的大小),Cols of record为数据块的记录列数,Best time为数据写入的最小时间(以s为单位),Worst time为数据写入的最差时间(以s为单位),Average time为数据写入的平均时间(以s为单位). 从表1可知,当数据块大小设置为400时,数据写入的速度相对最快. 另外,本研究将常规的数据写入策略和优化的数据写入策略所消耗的时间进行了对比测试实验.数据块大小设置为400,每个数据文件测试10次,实验结果如表2所示. 表2 数据写入策略的对比测试结果 在表2中,Rows of record为数据文件的记录数据总条数,Cols of record为数据文件的记录列数,Data writing time of conventional algorithm为常规策略的平均数据写入时间(以s为单位),Data writing time of optimization algorithm为优化策略的平均数据分块写入时间(以s为单位). 数据写入时间的曲线变化图如图6所示. 图6数据写入策略消耗时间的曲线变化图 从图6可知,数据写入优化策略所消耗的时间均低于1 min.从表2可知,数据写入优化策略所消耗的时间均明显小于数据写入常规策略所消耗的时间,数据写入速度平均提高了187倍. 为了解决大容量数据文件常规抽取策略的局限性问题,本研究对常规策略进行了优化,提出了一种优化的大容量数据文件抽取算法.为了验证算法的优化效果,本研究进行了自适应数据量的数据抽取实验和数据写入速度对比实验.实验结果表明,算法既能够实现不同数据容量的文件抽取,又能以远远高于常规写入速度的方式完成数据快速写入数据库的操作,从而验证了算法优化的有效性.1.3 算法实现
2 算法测试实验
2.1 实验分析



2.2 数据分块写入测试

3 结 论
猜你喜欢
酒·饮料技术装备(2018年1期)2018-04-28 09:09:06
网络安全和信息化(2018年9期)2018-03-03 18:11:15
信息安全研究(2018年1期)2018-02-07 01:44:46
数学小灵通(1-2年级)(2017年12期)2018-01-23 03:37:05
网络安全和信息化(2017年12期)2017-11-08 10:39:14
非公有制企业党建(2016年1期)2016-07-19 13:02:52
工业设计(2016年7期)2016-05-04 04:01:00
开心素质教育(2016年2期)2016-04-20 05:07:48
读写算·小学低年级(2015年4期)2015-12-04 11:27:22
中国科技信息(2015年6期)2015-11-10 03:35:44
