
Radon域下的K--SVD字典的混采分离
2019-04-09 03:00:42李慧韩立国张良贾帅
世界地质 2019年1期
李慧, 韩立国, 张良,贾帅
吉林大学地球探测科学与技术学院,长春130026
0 引言
传统的海上或者陆地地震数据采集中,为避免邻近炮源之间的干扰常常使用连续震源,但是连续震源激发需要震源间隔大,这就产生了时间长、资金消耗多的缺点。针对该问题,在近十年,提出了同步源采集的思想,它在减少采集费用及改善地震数据质量上有很大的突破[1]。同步源采集是多个炮点同时激发的方法,它实现了用更少的时间间隔来密集采样的要求,在同一时间内收集到多个炮点的混合数据,减少采集时间,增加了空间采样,但地震数据分析与处理目前需要传统采集的地震单炮数据,当前已相继用Seislet变换、多级中值滤波和单纯字典学习等来研究去除混采噪声,并取得一定成就。稀疏表示是一种高效的信号处理方法,为此2008年Berkhout[2]在此基础上进行扩展,提出混合采集的概念,阐述一种在邻近炮点之间、同一时间内的连续重叠方法,这在减少采集时间和增加空间采样方面有巨大的优势。
目前大部分的地震处理工作和叠前属性分析仍然依靠传统的单炮采样数据,需要将同步源采集的数据进行分离,便于地震数据分析及处理,即混采分离,以降低采集时间和资金花费。混合数据的处理是在混合数据中直接移除和分离数据:在相同时间内,相对于某一个震源,其他震源在随机延迟时间内激发,此时其他震源激发的能量类似于一个不同步噪声,几个震源的能量被记录在一个常规接收的时间域内,由于延迟的随机性,两个源之间的串扰能量类似于不同步的相干噪声,那么该问题也就转化为去噪的问题。Ikelle[3]在2007年指出,混采分离可以视为盲源分离问题,可以用独立成分分析算法解决。随后一些方法相继提出来去除典型噪声:Doulgeris和Huo et al.[4,5]提出基于相干滤波的算法,该方法计算效率较高而且得到了预期的结果;Mansour et al.[6]将混采分离作为一个反演问题来处理,然后优化这个方案的方法;韩立国等[7]提出多级中值滤波与Curvelet变换相结合的方法来去除混采噪声。
在压制相干噪声的方法中,二维面内所有点的函数值都与原始函数线积分有映射关系,Radon变换根据这个原理,沿同相轴进行积分求和使形状规则的同相轴的能量在Radon域中收敛,根据同相轴的截距和曲率不同使其在Radon域内分离,以此来去除噪声。
在地震应用中,字典学习主要被用来去除随机噪声,基于稀疏表示的字典在地震信号处理中效果显著,可以应用于地震去噪和一维信号重建[8]。然而由于初始字典的选择困难,用同步源采集和训练数据在实际处理中难以执行。除此之外,在假设字典有特殊结构的前提下,一个经过训练的紧框架能用于地震插值。字典的学习能用来设计数据驱动字典,可以更好地训练数据、改善稀疏信号[9]。字典学习的具体方法是:假设的参考信号通过字典原子线性地稀疏表示,用设计的最优化方法来学习字典。相对于固定变换基的字典,一个学习的字典更符合信号,也能更稀疏地表示信号。
笔者结合Radon域下的字典学习原理,用K--SVD的稀疏字典的学习方法,将数据转换到Radon域进行字典学习来分离混合数据,用合成数据和实际地震资料进行测试,相较于中值滤波、单纯字典和小波变换,该方法具有更好的分离效果。
1 方法原理
1.1 Radon变换
时间域Radon变换组顺着同相轴进行线积分,转换到Radon域收敛成一个点或一个线(图1),这一过程有明显的物理意义—将时间--空间域t-x的一条直线映射到τ-p域。一般地,Radon变换可以表示为:

(1)
该公式描述了一个二维无限连续方程d(t,h)的Radon正变换。

若从Radon域返回到t-h域则需进行反Radon变换,其定义为:

(2)
需要注意的是,这个方程并不是正演方程的精确反演,两个方程合成正反变换对。正反变换是由Radon变换对的算法实现的。
在地震勘探中,时间域和空间域的采样是离散的,不能使用连续的函数方程,故用离散的累加来替代连续的积分方程。同时Radon变换有抛物、线性和双曲线3种主要变换类型。双曲Radon变换(Hyperbolic Radon Transform)在地震资料的去噪、插值重建、速度估计和多次波衰减等方面应用广泛。双曲Radon变换可收敛类似于双曲线的反射波同相轴,从而使反射波与其他波分离,传统的双曲Radon变换是时变的,Bickel[10]改进离散双曲Radon变换方程为:
(3)
时不变的双曲Radon变换和传统的时变双曲Radon变换相比,具有可以在频率--空间域进行计算的优势,极大提高了双曲Radon正变换的计算效率,本文采用时不变的双曲积分路径。
1.2 混合数据的伪分离
在随机时间延迟假设下的同步源采集中,野外采集到的混合地震信号b用矩阵形式可以表示为:
b=Γf
(4)
式中:Γ为混合矩阵;f为常规采集的单炮记录,在已知b中恢复未知的f。这个式子是欠定的,所以我们可以求它的最小平方解:
Γ-1=[ΓHΓB]-1ΓH
(5)
在稀疏编码中进行线性组合,那么伪分离信号f′为:
f′=ΓHb
(6)
伪分离数据在不同时域呈现不同的分布[7],从图1中可以看出,伪分离数据在共检波点道集中,混叠噪声为随机分布,所以笔者将伪分离数据转换到共检波点域进行分离去噪。

图1 不同时域的伪分离数据Fig.1 Pseudo-separation data in different domains
1.3 字典分块的炮分离
基于共检波点道集的炮分离可以视为一个反演问题。通过字典学习的稀疏表示主要有两步:
第一步稀疏编码。信号f的恢复是复杂的正则化过程,在随机同步源采集的猜想下,f的恢复可以利用压缩感知和稀疏反演的公式(7):
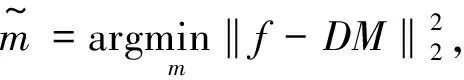
(7)
式中:D为预定义的字典;m为对应的稀疏系数向量;T为非零系数的数量。D与m按列对应,字典中的每一列按照Mi(稀疏系第i行)为系数进行线性组合就会得到单炮记录F。
第二步更新字典。思想是用获得的系数稀疏向量m,更新字典D,经过K次迭代完成字典的一次更新:
(8)
公式(7)和(8)是用来学习最优化字典和最稀疏的表示的迭代方法[11]。
同步源地震数据的字典首先从混合数据b中学习,但是由于混合记录中有很大的噪声,所以本文的字典从单炮记录中学习。训练字典时,单炮记录中每一块的数据被选择,等式变为

(9)
(10)
式(9)是NP-hard问题[12],只能用穷举法且不容易得到,本文用的是正交匹配追踪(OMP)算法解决,是贪婪的逐个穷举来找到最精确的解。迭代更新字典D的(10)式本文用了K奇异值分解(K--SVD)算法。
1.4 用K--SVD算法学习字典
K--SVD方法是解决等式(14)的一个有效地算法。在已知F和M的情况下,字典中的第K列在固定稀疏系数M的情况下一次次被更新,为更新第K列,等式变为:
(11)
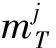
E=U∑VT
(12)
式中:这里U中的第一列为dk,V的第一列和Σ的第一个元素乘积为稀疏系数向量mk。在K列全部被更新之后,再用OMP算法解决第一个等式求出稀疏矩阵M,即可求出分离后的单炮数据:
f=dm
(13)
本文采用K--SVD与Radon变换相结合的双稀疏字典,在有效去除混叠噪声的基础上提升速度。
2 测试与应用
2.1 合成数据处理
资料处理时采用最小偏移距为20 m,道间距和炮间距均为2 m,每道采样点数226个,采样间隔1 ms的模型数据,常规采集得到90个单炮记录,之后对单炮数值混合成45个超级炮,混合度为2的混叠炮记录(图2)。

图2 模拟数据的混采Fig.2 Blended acquisition of simulation data
图3是混叠数据和伪分离数据在不同时域的伪分离记录,可以明显看出,在共检波点域将伪分离数据变换为有效同相轴和随机噪声,为之后的去噪工作提供条件;图4是原炮记录和伪分离记录分别在Radon域中的表示,可见炮记录在Radon域中能量收敛,而噪声则分散分布在Radon域中,在这里用阈值滤波进行分离去噪。分离后的数据(图5),虽然仍有一些残余噪声,但是分离效果较明显,接下来将用字典进行分离残余的噪声。可以看出,分离后的数据会稍有损失,这是使用Radon滤波的缺点。

图3 不同时域的伪分离数据Fig.3 Pseudo-separation data in different domains
图6a为Radon域的炮记录训练成的字典,字典原子总数为64个,图像块尺寸大小为8×8。图6b是经过字典学习后的数据,将Radon域的数据转换到时间域,得到图7a,将Radon阈值未去除的噪声去除得更加干净。图7b为分离后的数据和单炮记录的差值,可以看出有效波有损失的,但是完成了混采分离的目标。图8是单纯使用中值滤波或者字典、二层小波进行处理,可以看出中值滤波的有效波损耗比较少,但是滤波效果较差,能量较高的随机噪声残留太多;字典处理仍有部分损耗,而且去除效果差,比中值滤波更差;小波处理效果最差,基本没有去掉较大的能量。相比较而言,用本文方法的处理结果比较干净,有一定优势。
2.2 实际数据处理
继续处理混合度为2、常规采集为90个单炮、90个道的实际地震记录(图9),以进一步验证方法的有效性。数据道间距25 m,炮间距25 m,每道采样点数900个,采样间隔为1 ms。图10为Radon域的数据,用双曲Radon变换,将单炮数据变换到Radon域。
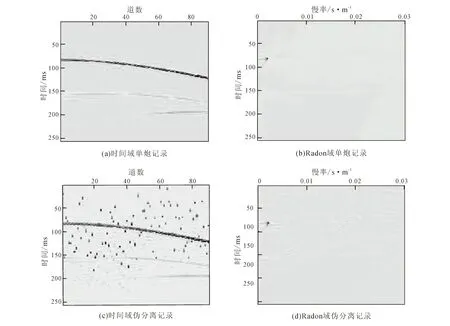
图4 Radon域中的伪分离记录Fig.4 Pseudo-separation data in Radon domain

图5 Radon域分离去噪Fig.5 Denoising in Radon domain

图6 分块的字典和字典分离后的结果Fig.6 Blocking dictionary and result of dictionary separation

图7 最终的分离结果及去除的噪声Fig.7 Results of separation and noises attenuated

图8 单纯中值滤波或字典或小波的处理结果Fig.8 Results of median filter or dictionary or wavelets

图9 实际数据的混采Fig.9 Field data by blended acquisition

图10 Radon域数据Fig.10 Data of Radon domain
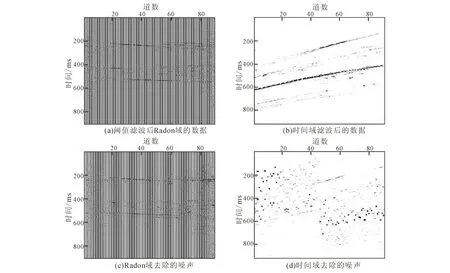
图11 Radon域分离去噪Fig.11 Denoising in Radon domain

图12 训练字典进行分离Fig.12 Separation by training dictionary

图13 单纯中值滤波处理和字典、小波处理结果Fig.13 Results of median filter or dictionary or wavelets
将数据转换到共检波点域使混叠数据变为随机分布的噪声(图9),对伪分离信号进行Radon变换(图10d),可以看出由于噪声较大,压制了有效波的显示。在图11中可以看出Radon去噪的有效性,滤掉的部分是图11d,同时也去掉了一些Radon域内能量较小的有效波,这个方面还需后续的改进;再进行K--SVD字典去噪,将Radon域内有效波进行分块字典处理,字典原子依然是64个,图像块尺寸大小为8×8,完成最终分离过程。图12c是最终的分离结果,虽然有效波损失但是证明了方法的有效性。图13是用中值或字典、二层小波来进行数据处理,可以看出中值滤波效果最差,噪声残留明显,字典处理较好,二层小波去掉的主要是小能量噪声,实际效果不大,都没有本文方法的处理结果干净。
3 结论
(1)同步源采集具有省时、省资金和有效的特点,是未来采集方法的发展方向。在Radon域中进行阈值滤波和K--SVD字典学习,满足了伪分离数据分离为常规单炮数据的要求。
(2)从模拟数据和实际数据的处理结果中可知,该方法分离效果明显,同中值滤波、单纯字典和小波变换相比,虽然会有少量振幅损耗但能更有效地去噪,达到分离的目的,在实际处理中具有实用价值。
猜你喜欢
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
石油管材与仪器(2023年5期)2023-09-26 00:42:36
石油地球物理勘探(2022年3期)2022-06-11 01:21:12
军事文摘(2021年22期)2022-01-18 06:22:48
中国化工贸易·上旬刊(2020年1期)2020-09-10 09:45:33
华东师范大学学报(自然科学版)(2020年1期)2020-03-16 03:14:55
数学物理学报(2017年3期)2017-07-01 16:18:49
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
读者(2016年14期)2016-06-29 17:25:50
