
在线负面口碑处理的专家识别方法研究
2019-04-02 03:43蔡淑琴王艺兴秦志勇窦聪颖
中国管理科学 2019年3期
蔡淑琴,王 旸,王艺兴,秦志勇,窦聪颖
(1.华中科技大学管理学院,湖北 武汉 430074;2.深圳证券交易所,广东 深圳 518038;3.华中科技大学新闻与信息传播学院,湖北 武汉 430074)
1 引言
随着Web技术的快速发展和广泛应用,社会化媒体正以惊人的速度渗透到社会的各个方面,不仅为用户提供了获取信息的渠道,还为用户构建了发布内容和建立关系的平台。用户参与、用户主导、用户创造已经成为社会化媒体吸引用户、增强竞争力、提高企业价值的有力工具,生成了大量有商业价值的用户创造内容(User Generated Content,简称 “UGC”)。作为UGC的一种独特形式,在线负面口碑(Online Negative Word-of-Mouth,简称“ONWOM”)是消费者在互联网中对企业表达的负面观点和评论[1],具有数据大、传播速度快、破坏力强[2]、拒绝解释[3]等特点,相比企业发出的信息,负面口碑更容易得到他人信任[4]。如果企业未能及时响应处理,会引发大面积的消费者不满,进而造成企业声誉受损,品牌价值降低等严重后果[5]。然而,由于ONWOM有数量大、传播速度快等特点,企业单纯依靠传统人工处理方法会面临成本高、反应速度慢和资源短缺的困境。
社会化媒体为用户提供了交流互动的平台,用户可以在其中搜索信息、发布内容和建立关系,随着用户数量增加和用户间互动增强,少量拥有更多知识的用户逐渐凸显,成为专家用户。Riahi等[6]实验发现少量专家用户为网络社区提供了大部分知识,他们在为他人解决问题和分享知识过程中建立了个人权威,这不仅实现了其个人价值,也为所在平台提供了更多资源,使其成为社会化媒体高质量知识的重要外部来源。负面口碑处理中,企业过度参与可能会被怀疑而导致丧失自身公信力[7],若客户不满意企业对负面口碑直接做出的反馈将会带来更强烈的负面情绪[3]。因此,将UGC中的专家用户看作ONWOM处理资源进行ONWOM处理,可为企业提供ONWOM处理的新途径。如果能够识别出这些专家,并给予适当引导,企业可以依赖他们扩充自身知识库,扩展可调动资源范围,借助专家知识面广、知识成本低、容易与其他用户沟通等优势优化服务流程、提高服务质量、改善服务体验,进而提高整体服务水平。但是随机选择用户作为服务方很难达到满意的处理效果[8],因此如何提前识别合适的用户形成服务方专家库(专家识别)是需要解决的关键问题。
现有相关研究已有若干成果。闫强和孟跃[9]研究证明拥有较为极端的情感倾向和较长的正文的评论会正面影响在线评论的感知有用性。Archak等[10]通过实验证明可以从在线评论数据中提取可操作的信息资源,更好地理解客户的偏好和行动。Pfeffer等[11]讨论了负面口碑网络传播风暴的后果,并提供了网络负面口碑危机的行动指导。Surachartkumtonkun等[12]基于需求理论,用实证方法进行研究认为消费者抱怨是为了寻求相应的经济补偿和自尊补偿。蔡淑琴等[13]提出了RFMS模型来测量在线口碑发布者的影响力,应用人工神经网络识别出意见领袖。Yang等[14]以学术研究社区为背景,认为除了个人之间的链接关系,还需考虑研究者所在机构间的连接强度信息对专家识别的作用,通过整合关联信息、个人社交网络信息给专家建立多层次的人物画像,并验证了方法的有效性。
由以上综述可知,现有研究存在以下局限:首先,现有研究大多是针对问答或学者推荐的专家识别,少有专门针对ONWOM处理的专家识别研究,本文针对ONWOM处理特殊情境的具体要求,需识别适合此情境的相关专家;其次,现有研究大多只考虑用户的知识能力并未将专家用户看作ONWOM处理资源进行识别,然而本文研究中,ONWOM发布方有寻求知识解决方案和情感抚慰两方面需求,ONWOM处理的特殊性使得仅从知识能力出发的专家专家识别性能不够,不能满足ONWOM发布方所有需求导致ONWOM处理失败甚至引发更强烈的抱怨;最后,基于链接的识别方法大多从用户权威角度出发,没有明确相应专家的能力结构,推荐的专家不具有针对性,面对ONWOM处理的特殊需求时,难以达到好的效果,不方便企业实际应用。
针对以上问题,本文研究社会化媒体中ONWOM处理的专家识别问题,认为用户属性、用户发布内容等UGC资源是用户隐性知识的显性表示,可以利用这些资源进行专家识别。设计的ONWOM处理专家识别方法中,将专家用户看作ONWOM处理资源,从资源视角出发,建立专家识别资源映射框架,专家识别过程除了考虑体现用户专业水平的知识能力,还融入了专家参与ONWOM处理的情感抚慰能力,并将用户互动程度引入到用户能力特征空间,以此构建ONWOM处理的专家能力得分计算模型,实现专家识别并显著提高了识别性能。
2 资源映射框架
原始UGC资源有非结构化、碎片化、去中心化等特点,无法直接用于ONWOM处理,需要经过处理加工转换为合适的形式,才能最大限度的提高ONWOM处理成功率。为清晰理解专家识别中资源的形式和转换规律,本节从资源视角出发,分析专家识别过程中资源的转换过程,或称为“资源映射”过程。
本文专家识别的资源映射过程涉及UGC资源、显性资源和隐性资源三种状态。其中,显性资源是对原始信息资源的结构化表示,描述了资源构成要素,剔除了无关或作用较小的噪音信息,并从集合层面对资源进行聚合,降低了UGC资源的碎片性。隐性资源也源自原始信息资源,但是以显性资源为基础,通过相关计算方法得到满足需求的知识或能力测量,是资源价值的量化表示。相对应,根据资源形式的不断转换,将资源映射过程分为显性资源映射和隐性资源映射两个阶段,以此提出面向ONWOM处理的专家识别资源映射框架如图1。
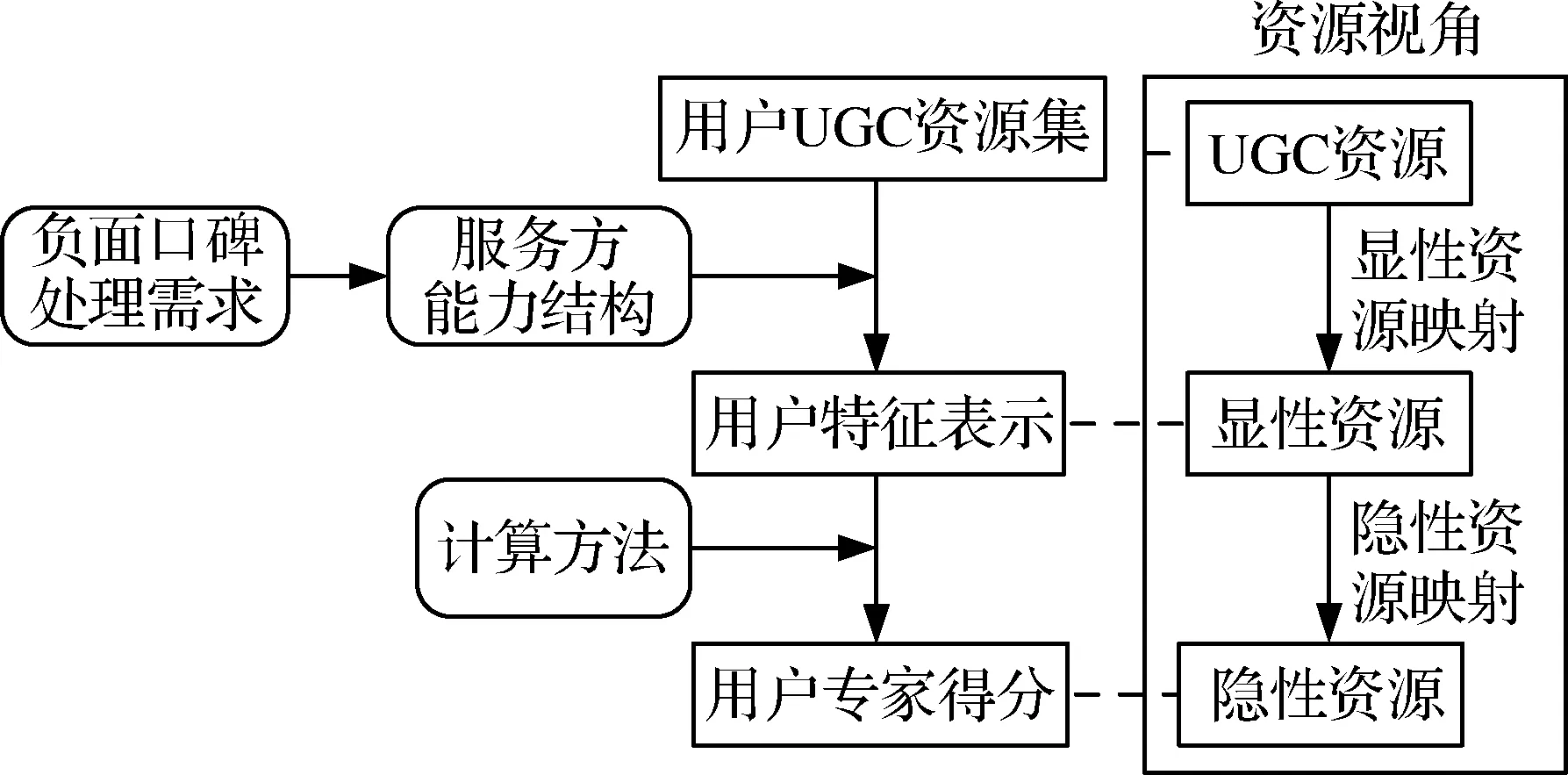
图1 面向ONWOM处理的专家识别资源映射框架
图1的框架中虚线左侧部分表示专家识别中由用户UGC资源集得到用户专家得分的过程,虚线右侧大方框部分是从资源视角理解的与获得用户专家得分过程对应的资源映射过程,虚线表示两个过程中资源的对应关系。
框架左侧部分包括两个阶段,第一阶段完成了从用户UGC资源集向用户特征表示的转换,此部分对应资源视角的显性资源映射,第二阶段完成了从用户特征表示向用户专家得分的转换,此部分对应资源映射视角的隐性资源映射。在第一阶段中,确定用户特征表示包含的特征元素是其中的关键,随意选择特征不仅无法识别出合适的专家用户,甚至可能导致ONWOM处理失败。为此,如框架左侧上方的两个圆角方框所示,本文从ONWOM处理的问题背景出发,以ONWOM发布方的价值需求为起点,可以确定成功实现ONWOM处理的需求,这些需求一方面是资源需求体现,另一方面是专家能力结构体现。专家识别中,在通过以上分析过程获得专家需要具有的能力结构后,将其与用户UGC资源集的真实数据集合,可得到体现用户能力结构的用户特征表示,实际上这是一个从用户创造的数据中挖掘体现其能力结构的显性表示的过程。在第二阶段中,由于前一阶段得到的用户能力结构只是对用户具有相关能力的特征描述集合,而专家识别中需要能体现用户能力的单一量化指标,即专家得分,此得分是用户能力和价值的量化表示,根据得分对用户进行降序排序,获得分数靠前的用户即是专家用户。可以设计或选择合适的计算方法实现从用户特征表示到专家得分的转换。
框架右侧部分是从资源视角对左侧专家识别相关过程的理解,包括显性资源映射和隐性资源映射两个映射阶段。其中,显性资源映射是从UGC资源向显性资源的转换,隐性资源映射是从显性资源向隐性资源的转换。
3 方法设计
与传统专家识别不同,本文专家识别过程中不仅考虑了直接体现用户专业水平的知识能力,还考虑了专家参与ONWOM处理的情感抚慰能力,并借助情绪感染机制获得情感能力的量化指标。此外,本文将用户互动程度也引入到用户能力特征空间,以此构建人工神经网络模型,实现专家识别。
3.1 专家特征表示
本文研究中,ONWOM发布方有寻求知识解决方案和情感抚慰两方面需求,相对应,如果要成功处理ONWOM,作为服务方的专家需要具有满足这两方面需求的能力。即可认为知识方案提供能力(简称“知识能力”)和情感抚慰能力(简称“情感能力”)是专家能力的组成部分。其中,知识能力是专家满足ONWOM发布方寻求知识解决方案需求的能力,情感能力是专家满足ONWOM发布方寻求情感抚慰需求的能力。每个用户的时间和精力是有限的,在特定情境下,有处理能力的用户并不一定都愿意参与ONWOM处理,而有参与意愿的用户也不一定有足够的处理能力。因此,专家需具有参与ONWOM处理的意愿,只有处理能力而不愿参与ONWOM处理的用户不是本文所指的专家,只有参与意愿而没有足够处理能力的用户也不是本文所指的专家。因此,为保证价值共创过程的实现,互动阶段对服务方专家有互动能力的要求,即服务方除了具有上述知识方案提供能力和情感抚慰能力外,还需具有较高的参与价值共创互动的程度,简称“互动程度”。
由上述分析可知,ONWOM处理的服务方专家能力包括知识能力、情感能力和互动程度三方面,其中互动程度是发挥专家能力的前提条件,知识能力和情感能力是实现ONWOM处理的能力体现,用户参与ONWOM处理的意愿各不相同,具有的知识能力和情感能力也往往参差不齐,而且人数众多[8],要想保证ONWOM处理的成功率,需要从以上三方面特征出发,识别用户中的专家。因此,可将用户特征表示形式化如式(1):
U=(KC,EC,DI)
(1)
其中U表示用户,KC表示知识能力,是Knowledge Capability的缩写。EC表示情感能力,是Emotional Capability的缩写。DI表示互动程度,是Degree of Interaction 的缩写。由用户的UGC资源得到式(1)的形式化表示,对应图1的显性资源映射过程。
为使设计能落到数据层面,下面分析以问答社区为现实环境,认为在此环境中进行ONWOM处理,分别对知识能力、情感能力和互动程度三个特征维度中涉及的细化指标进行分析,并给出具体的测量方法,假设UGC资源均以文本形式出现。
3.1.1 知识能力特征
粉丝数经常被用来说明用户的权威性[15],这在社交网络较强的社会化媒体中效果较好,高粉丝数对用户等级有很大提升作用,但在知识为导向的问答社区中,通过粉丝关系很难获得提问者的认同,得到其他用户直接求助才是对其知识能力的最直接认可。文本长度是体现文本质量的重要指标,较长的文本意味着更详细的解释,相比短文本更容易被接受[16]。同时,较长的文本能包含更生动的内容,面对内容接收者时更有说服力[17],在ONWOM处理中,发布者就更容易接受服务方提供的服务。每个提问者会根据自身情境提出问题,而每个人所处的情境大多不同,答案被最了解问题情境的提问者采纳是对回答者问题解决能力的认可,被采纳的答案越多说明回答者的知识能力越高。提问者和回答者之外的其他用户同样可表达对回答的看法,如果他们赞同回答者提供的答案,说明这些用户认为回答者提供了提问者需要的知识。作为第三方平台,问答社区常对质量符合一定规范的高质量答案给予标记,如有些答案被标记为精华答案标签,这是对回答者知识能力的社区认可。
根据以上分析,本文选择以下指标为描述用户知识能力的特征,包括满意答案数、采纳率、收到求助数、赞同数、精华答案数、答案平均长度。其中满意答案数为提问者接纳用户答案为满意答案的总数,收到求助数是提问者指定此特定用户为回答者的次数,答案平均长度指用户提供的所有答案的文本长度的平均值。
3.1.2 情感能力特征
在心理学领域,情绪感染指个体之间感知捕获环境中其他人的情绪变化,包括无意识、不自觉的的情绪模仿或趋同,或者有意识、主动的情绪认知和控制下,实现的不同个体间的情绪交互和聚合过程[18]。发布方的负面情绪在服务方正面情绪的影响下得到缓解是一个情绪感染过程。因此,本文假设用户情感抚慰过程是一个情绪感染过程,服务方相对发布方的情感越正面,其能成功进行正面情绪感染的可能性越大,进而实现情感抚慰的可能性就越大。杜建刚和范秀成[19]采用环境刺激方法,实证研究了在服务失败和服务补救中服务者对消费者的情绪感染。发现服务失败过程中,服务者的负面情感越强烈,消费者的负面情绪增加就越多,在服务补救中,服务者的正面情感越强烈,消费者由负面情感向正面情感转化幅度越大。本文并不研究社会化媒体中不同媒介与情绪感染的关系,而是认为专家通过文本对ONWOM发布方实现情绪感染,达到情感抚慰的目的,以此说明专家能力需包括情感能力特征。
根据以上分析,本文选择以下指标为描述用户情感能力的特征,包括答案平均情感得分,答案情感相对正面率。
本文在计算问题和回答文本d的情感极性和强度时,首先对文本d进行分词、去停用词处理得到其结构化表示,然后将得到的每个词与情感词典中的词进行匹配,匹配到的正面、负面和中性词极性分别记为1、-1和0,将d中包含的所有情感词的极性与强度乘积和作为其情感得分,形式化如式(2):
(2)
其中SSd表示文本d的情感得分,|d|表示d中包含的情感词数,SPi表示第i个情感词的极性值,SIi表示第i个情感词的情感强度,且1≤i≤|d|。SS、SP、SI分别是Sentiment Score、Sentiment Polarity和Sentiment Intensity的缩写。
由(2)计算得到用户提供的所有答案的情感得分后,可用用这些答案情感得分的平均值作为用户的答案平均情感得分。统计用户回答的所有问题中答案情感得分比问题情感得分高的问答对个数,可得答案情感相对正面数,形式化如式(3)和(4):
(3)
(4)
其中P={p1,p2,…,p|P|}表示某单个用户提供的所有答案所在的问答对集,|P|是此集合包含的问答对个数,其中第j个问答对pj=(qj,aj)包含一个问题qj和一个答案aj,PLN表示问答对集P对应用户的答案情感相对正面数。此时,可计算用户的答案情感相对正面率,如式(5):
(5)
其中PLP表示用户的答案情感相对正面率。
3.1.3 互动程度特征
ONWOM处理的专家识别中,虽然用户的知识能力和情感能力是其专家能力的直接体现,然而,知识能力和情感能力传播的广度和深度却决定了用户能力展现的程度,广泛而深入的交互是扩大传播广度和深度的必要手段,具有良好互动能力,互动程度高的用户,更有可能成为ONWOM处理专家,因此,用户互动程度是体现其专家能力的特征。
Chae等[20]研究信息质量和影响力,强调了交互质量在信息影响力中的关键作用,进一步则说明交互在表示为UGC资源集的用户影响力中的重要作用。互动程度的一个重要指标是交互频率,体现了用户参与解决问题的次数。用户提问次数同样可显示用户主动创造交互激活的特点,是其互动程度的一种体现[21],但在本章识别的专家是答案提供者,是信息的提供方,专家互动程度应该反映信息提供中的互动程度,而提问数反映的是用户获取信息的互动程度,因此此时不考虑用户提问数。Liao Hui[22]认为对客户抱怨的快速回应对抱怨处理有积极作用。及时对相应问题进行处理能减少客户需求无法得到及时满足而进一步扩大传播面积的可能性,及时性可以通过用户回答问题与提问的时间差来描述。问答社区为调动用户参与问答的积极性,常组织一些线上社区活动,参加此类活动的用户可以得到一些社区荣誉,也即用户获得此类荣誉的数量从侧面反映了其参与社区互动的程度,可作为用户互动程度的特征。
根据以上分析,本文选择以下指标为描述用户互动程度的特征,包括回答数、平均回答时差、社区活动荣誉数。
其中平均回答时差指用户提供答案的所有问答对中回答时间与提问时间的差值的平均值,表示为如式(6):
(6)
其中AATI表示某用户的平均回答时差,atj表示问答对集P第j个问答对中回答发布的时间,qtj表示问答对集P第j个问答对中问题发布的时间。
基于价值共创的负面口碑处理中,服务方专家识别的指标体系如表1。
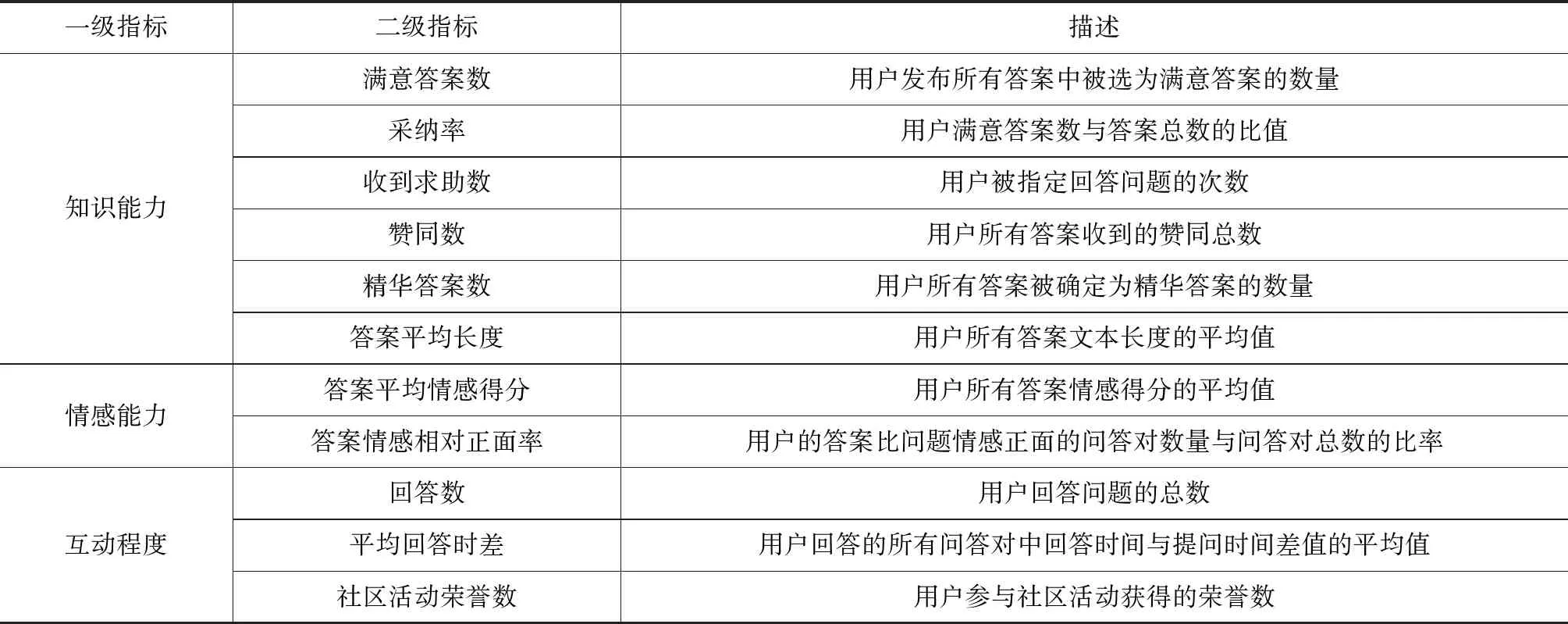
表1 ONWOM处理的专家识别指标体系
3.2 神经网络模型
人工神经网络(Artificial Neural Networks,简称“ANN”或“神经网络”)通过利用计算机程序和电子线路对人类神经系统的抽象和模拟,是计算智能的核心内容之一,其特有的非线性、自适应信息处理能力,适于处理多变量之间的复杂关系,并且已经在智能领域取得很好效果。本文的ONWOM处理中涉及知识能力KC、情感能力EC和互动程度DI三个维度,他们又分别细分为11个二级指标。这些指标涉及到对不确定的隐性知识、人类情感和用户行为的描述,而且之间关系错综复杂,很难用线性的、学习能力较弱的模型准确描述。神经网络作为非线性的自适应模型,通过多层神经元之间的权值调整可描述多指标间的复杂关系,实现对专家得分的计算。
本文专家得分计算的BP神经网络拓扑结构如图2所示:
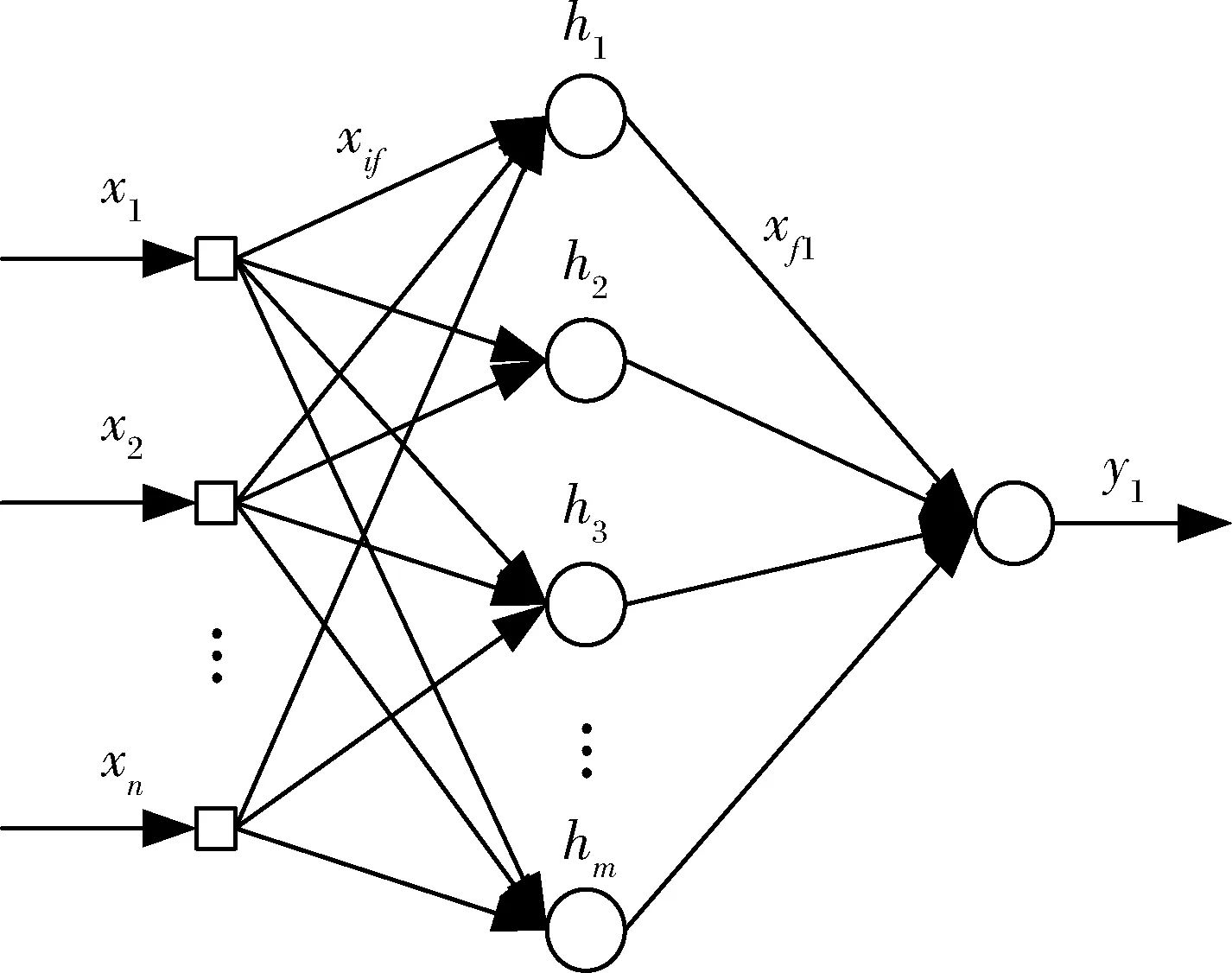
图2 专家得分计算BP神经网络拓扑结构
设神经网络的输入层一个样本X对应的特征向量为(x1,x2,…,xn),n是输入层的特征维度;隐藏层向量表示为H=(h1,h2,…,hm),m是隐藏层的神经元个数;输出层输出向量表示为Y=(y1),输出真实值表示为D=(d1),因为计算的专家得分是一个数值,所有将输出层表示为只有一个维度的向量;输出层和隐藏层之间的权值表示为V=(V1,V2,…,Vm),其中Vj=(v1j,v2j,…,vnj)是输入层的所有n个节点与隐藏层神经元hj的连接权值;隐藏层与输出层之间的权值表示为W=(W1),W1=(w11,w21,…,wm1)是隐藏层的每个神经元与输出层神经元的连接权值。
BP神经网络的在训练前需要初始化,根据系统设计确定网络输入层节点数n,隐藏层节点数m和输出层节点数1,初始化权值矩阵V和W,初始化隐藏层阈值a和输出层阈值b,给定学习速率η,确定网络的最大训练循环次数M和学习精度ε,隐藏层激活函数φ(Zj)通常选择logistic函数,定义如式(7):
(7)
(8)
其中Zj是第j个隐藏层神经元的输入,aj是相应阈值。输出层激活函数选择线性函数,表示如式(9):
(9)
其中O=(O1)为输出层的输出,b1为相应阈值。根据网络输出值O和输出真实值D可以计算网络预测误差,表示如式(10):
e1=y1-d1
(10)
误差向量为e=(e1)。判断迭代次数是否达到最大次数要求,以及误差是否符合精度要求,如果不符合,需根据误差反向传播对网络进行调整,更新网络权值的表示如式(11)和(12):
vij=vij+ηφ(Zj)(1-φ(Zj))xiwj1e1
(11)
wj1=wj1+ηφ(Zj)e1
(12)
其中η是学习率。根据误差对网络节点阈值的调整如式(13)和(14):
aj=aj+μφ(Zj)(1-φ(Zj))wj1e1
(13)
b1=b1+e1
(14)
对网络权值和阈值调整完后,继续计算在调整后输出层的输出,直至收敛。
4 模型构建与测试
4.1 数据收集
实验使用的数据采集自搜狗问问,搜狗问问是搜狗旗下最大的互动问答社区,用户可以在社区中提出问题、解决问题、或者搜索其他用户沉淀的历史内容。
数据收集过程如下:从搜狗问问专家栏目“电脑/数码”领域的所有249位用户中随机抽取150位用户,爬取内容涉及三部分,包括用户社区统计数据、用户回答所在问答对内容数据和用户回答所在问答对属性数据。因为可能出现一人用多账号违规行为,首先删除姓名和个人信息有大量重复或交叉的共7个用户。然后因为网页差异,导致数据爬取过程中有些用户数据相比其真实数量少,为避免因数据不完整对实验结果的影响,剔除爬取的问答对数量低于30,且比率小于50%的9个用户,最终获得有效用户134人。对134个用户包含的数据,其中由于网页格式差异导致部分数据爬取失败,删除属性缺失和异常的数据,同时,由于本文模型和算法都是在文本数据的前提下进行设计,虽然其他形式的数据可以转化为类似的表达形式,但为了使叙述更为一致,实验部分将问答中涉及大量图片等非文本形式的数据删除,剩余有效问答321910条。每个用户由以下部分组成:采纳率、收到求助数、赞同数、精华答案数、答案数、勋章数、用户回答所在问答对应文本内容、用户回答所在问答对应的提问和回答时间。
4.2 建立模型
本章采用3层BP神经网络结构,包括有输入层、隐藏层和输出层。输入层有11个节点,对应用户的11个特征,分别为每个用户的满意答案数、采纳率、收到求助数、赞同数、精华答案数、答案平均长度、答案平均情感得分、答案情感相对正面率、回答数、平均回答时差和社区活动荣誉数。隐藏层节点数的选择目前没有统一的方法。这里利用已有的经验公式,首先借助公式确定节点数的大致范围,然后用试凑法确定最佳节点数。选择经验公式为(15):
(15)
其中l为隐藏层节点数,m为输出层节点数,n为输入层节点数,a为0到10之间的常数。不拘泥于经验公式,本章选择的隐藏层节点数试凑范围是从5到25个,共试凑21次,其中当节点数为15时,误差较小,且训练时间在接受范围。因此,选择的神经网络结构为11-15-1,神经网络的相关参数设定如表(2):

表2 神经网络参数
本文从134名用户随机抽取80%作为训练集,共107人,对神经网络模型中的参数进行训练。将剩下的20%共27人作为测试集,评估模型的效果。在模型训练过程中,将107名用户的11个特征作为网络输入,将社区赋予用户的经验值作为每个用户的输出,此时选择3位专家对原经验值进行了人工调整,增大了解决负面情绪问题的权重,以使识别出的专家更适合负面口碑处理。
为避免量纲不同对模型的影响,需对所有的指标进行归一化,如式(16):
(16)
其中NVxi表示某指标的测量值xi归一化后的对应值,xmin表示所有样本在此指标测量中的最小值,xmax表示所有样本在此指标测量中的最大值。
4.3 实验结果
测试集包括27个用户,将此27个用户的归一化特征值输入到训练好的神经网络模型中,可以预测每个用户的经验值,经验值代表了用户专家能力的得分。为说明本文方法的有效性,这里构造另外4个模型进行对比,分别是只考虑知识能力和情感能力8个特征的神经网络模型ANN_KS,只考虑知识能力和互动程度9个特征的神经网络模型ANN_KI,只考虑知识能力6个特征的神经网络模型ANN_K。同时,选择均值模型作为基线模型参与比较。
本文选择MSE(mean squared error)来对比模型间的预测性能,而均值模型的MSE值,可作为鉴别模型的基本标准,MSE的计算公式如(17):
(17)

根据待比较的几个模型的特征结构,分别构建相应结构的神经网络,并利用数据对模型进行训练,由训练好的模型对测试集计算得到MSE值如表3:

表3 模型MSE值对比表
表3显示,同时考虑知识能力、情感能力和互动程度特征的神经网络模型ANN_KSI的MSE值最小,说明其性能最优。4个神经网络模型的MSE值比均值模型都要小,说明相比均值模型,基于本文特征结构的神经网络较好的模拟了特征与专家能力之间的关系。ANN_KSI相比ANN_KS模型在性能上提升23.69%,表明在知识能力和情感能力的基础上考虑用户互动程度,有助于提高专家识别准确率。ANN_KSI相比ANN_KI模型在性能上提升26.45%,说明在考虑知识能力和互动程度的基础上加上情感能力,能更好的识别专家。ANN_KSI相比ANN_K模型又更大程度的性能提升29.99%,进一步说明了,ONWOM处理的专家识别中,除了考虑知识能力,融入情感抚慰能力和互动能力的模型能显著提高识别性能。
5 结语
现有专家识别方法大多只考虑专家解决问题的知识能力,而在ONWOM处理背景中,单考虑知识能力的传统方法无法满足发布方寻求情感抚慰的需求,更无法达到ONWOM处理的互动性要求,容易导致处理失败。
针对以上问题,本文将UGC中的专家用户看作ONWOM处理资源,从资源视角出发建立专家识别对应的资源映射框架,并将此过程分为显性资源映射和隐性资源映射,显性资源映射是原始UGC资源到结构化用户特征空间的映射,实现用户信息资源的结构化表示,隐性资源映射是从用户特征空间到用户价值的映射,实现用户价值的量化,用专家得分表示。与传统专家识别不同,本文专家识别过程中不仅考虑了直接体现用户专业水平的知识能力,还考虑了专家参与负面口碑处理的情感抚慰能力,并借助情绪感染机制获得情感能力的量化指标。此外,互动作为资源整合的条件和情绪感染的前提,本文也将用户互动程度引入到用户能力特征空间,以此构建人工神经网络模型,实现专家识别。实验证明本文方法能更好的识别负面口碑处理的专家。提出的资源映射框架为专家识别提供一种新的指导方法,构建的模型为理解负面口碑处理专家能力结构提供一种新思路。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
现代电力(2022年2期)2022-05-23
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
计算机应用(2022年2期)2022-03-01
电子制作(2019年19期)2019-11-23
当代陕西(2019年10期)2019-06-03
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2017年12期)2017-04-23
宠物世界·猫迷(2016年3期)2016-04-23
少儿科学周刊·少年版(2015年3期)2015-07-07
