
基于云计算平台实现电网短期负荷预测算法的研究
2019-04-01 05:23:02志远
四川电力技术 2019年1期
,,志远,
(国网乌鲁木齐供电公司,新疆 乌鲁木齐 830011)
0 引 言
电力工业的根本目标是通过科学的规划最大限度地提高发电和用电效率,提高电力系统运行的经济性。而电力负荷预测一直是电力系统有效规划和经济运行的重要组成部分。
短期电网负荷预测是电力系统运行决策的关键,对电力系统的机组组合、减少发电备用、提高经济调度、保持系统可靠性以及维护调度都有重要意义[1-2]。近年来,准确的短期电网负荷预测在电力市场管制中得到了更大的重视和面临更大的挑战。
短期电网负荷预测算法需要处理从一个小时到几天的负载预测。由于短期负载具有极大的随机性,因此短期电网负荷预测的复杂性对电力运营者是一个极大挑战。在过去的几十年里,人们提出了许多预测模型。这些预测模型可以分为传统模型或基于机器学习的模型。前者包括时间序列预测器,如自回归移动平均外生变量模型[3]。这些传统模型是基于线性回归模型,不能准确代表复杂负载的非线性特征[4]。不同的机器学习技术也被用于短期电网负荷预测,如人工神经网络(artificial neural network,ANN)[5]、径向基函数(radial basis function,RBF)[6]、模糊神经模型[7]和支持向量回归[8]。
预测过程依赖于对某一国家或地区电力需求历史数据的分析,还可以考虑许多其他因素,如天气预报和商业计划。因此,需要整个历史数据来训练预测模型,但是这样的方法其缺点是,如果考虑到新的信息则所有参数都可能需要重新训练。此外,这种庞大的数据量和预期的复杂预测过程导致需要大量的计算能力。研究人员试图找到近似方法来最小化这一数据量,并将所需的计算能力降到最低。这些研究试图尽量减少数据采样量等。许多方法解决了这些回溯问题,其中一个采用了中的局部预测器[9-10]。
经济约束在任何算法研究中都起着主要作用。云计算的出现解决了研究人员和开发人员面临的许多经济问题。在云计算技术之前,超级计算机是获得巨大计算能力的唯一合适选择,显然这是一个非常昂贵的选择。有许多计算系统可以提供巨大的计算能力,如分布式系统、网格计算、互联网计算以及量子计算等,但云计算技术是最具性价比的选择,获得了广泛的商业应用。为此,一些研究试图借助云计算技术为短期负荷预测提供足够的计算能力[11-13]。
1 基于支持向量回归的短期负荷预测算法
一般来说,电力负荷由不同的消耗单元组成。各种因素都影响着电力负荷的变化,如天气、重大事件、经济因素和随机因素。短期负荷预测可以被认为是一个多变量预测问题。它可以作为回归问题的函数来求解。次日负荷为回归模型的输出,历史负荷数据及其影响因素为回归模型的输入。历史数据库提供训练数据。该回归问题的最终目标是从历史负荷数据及其影响因素中找到一个具有良好泛化能力的预测负荷映射函数。历史负荷数据被分为两个不同的数据集:一个是训练数据集用来训练回归模型;另一个是测试数据集用来评估训练后的回归模型[14]。
基于统计学习理论提出的支持向量回归(support vector regression,SVR)[15]已被研究作为一种有前景的电力负荷预测方法。其优势主要来自于采用结构风险最小化原理,并作为经验风险最小化原则的替代方案,它可以通过求解二次问题来获得最优的全局解。
SVR的执行有两个主要特征:二次规划和核函数。二次规划问题将用线性约束求解得到SVR的参数。核函数的灵活性使该技术能够搜索宽范围的解空间。SVR的主要目标是通过非线性映射将数据x映射到高维特征空间,并在该特征空间中执行线性回归[16-17]:
f(x)=〈w,x〉+b
(1)
式中:<.,.>表示点积;w包含必须从数据中估计的系数;b是一个实常数。使用Vaunink的ε-不敏感损失函数[18],将整体优化为
(2)
约束条件为
(3)
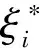
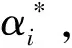
(4)
约束条件为
(5)
输出是一个独特的全局优化结果,其形式如下:
(6)
式中,Q(xi,x)是核函数。在SVR中采用核函数,所有必要的计算可以直接在输入空间中计算。核函数存在各种各样的内核,如线性、双曲正切、高斯径向基函数、多项式等[19]。在这里,使用常用的RBF内核:
Q(xi,x)=e-γ‖xi-x‖2
(7)
SVR的参数C、γ和ε在SVR的性能中起着至关重要的作用。因此,选择这些参数的正确值可以最大限度地减少预测误差。基于核的SVRs需要计算数据集中每个点之间的距离函数
(8)
基于SVR解决短期电网负荷预测问题可以归纳为以下步骤:
1)加载历史数据并将其分为训练集和验证集;
2)准确确定SVR的参数;
3)使用定义的参数训练SVR以获得支持向量和相应的系数;
4) 利用式(6)得到预测的负载。
2 实验验证
为检验云计算平台在电力负荷预测领域的影响,实验旨在测试两点:一是使用Azure ML实现负荷预测技术的准确性;二是测试执行时间的改进。
2.1 数据集
该数据集收集了从2016年1月至2017年12月的0.5 h电力负荷、2016年至2017年的日平均温度以及2016年至2017年的假期信息。目标是预测2018年1月的每日最大负荷,并用2018年1月的负荷实际值验证计算预测值。
2.2 实验平台
设计实验的实现有两个选择:本地实现和基于云的实现。对于本地实现,可使用台式计算机及使用MATLAB软件实现所提出的算法。台式计算机具有以下规格: Microsoft Windows 10,Intel Core i7 2.7 GHz,RAM 16 GB。 对于基于云的实现,则用Azure ML[20]。
2.3 性能指标
实验考虑了两个主要的性能指标:第1个也是最重要的一个是执行时间(TExecution);第2个是预测准确性。所有实验将使用4个度量来评估预测准确度:平均绝对百分比误差(MAPE)、最大误差幅度(MAX)、平均绝对误差(MAE)和归一化均方误差(NMSE)。这些值由式(9)至式(13)定义:
(9)
MAX=max(|Ai-Pi|)
(10)
(11)
(12)
(13)

2.4 结果与讨论
实验包括了4种不同的实验方案,用以比较和评估所提出的基于SVR算法的短期电网负荷模型在云计算平台和单机计算平台上的性能差异。
所有这些实验方案的目标是使用训练集训练上面所述的预测模型,再使用这个预测模型来预测2018年1月的31天内的最大日负荷,并与实际负荷进行比较。所提出的各实验方案的训练数据有所不同,如表1所示。
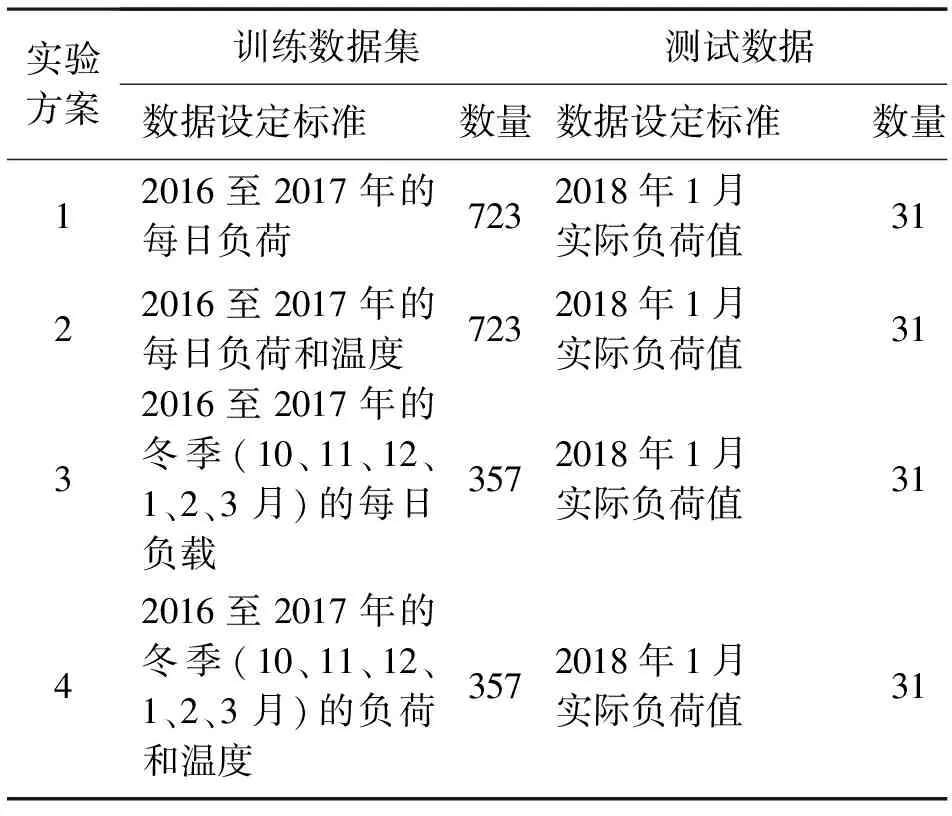
表1 实验方案的数据集
4种实验方案的执行结果如表2、图1和图2所示。结果表明,使用云计算平台的执行时间远远少于使用基于本地机器的单机计算平台的执行时间。特别是在训练数据相对较大的在实验方案2中,云计算平台与单机计算平台的执行时间相比,时间执行的改进在10倍以上。值得指出的是,在云计算平台上进行的第2次实验时比第1次运行更快,例如,实验方案2的第2次执行时间等于9 s,远低于第1次的72 s。此外,从预测精度来看,两者几乎相同,在实验方案4的情况下实现了最佳预测精度为2.04%。
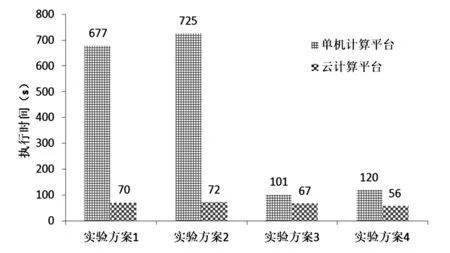
图1 单机平台和云平台执行时间对比
3 结 论
前面提出了一种基于支持向量回归预测(SVR)算法短期电网负荷模型,并通过实验分别在云计算平台和单机计算平台上实现了该模型。在两个平台的对比实验中,选择执行时间和预测精度作为性能指标。对于所使用的实验数据集,单机计算平台和云计算平台实现的算法预测精度是相同的;但是,在云计算平台实现的算法执行时间显著减小。一般来说,SVR并不推荐用于大型数据集,因为它的计算成本很高,而前面采用云计算平台体现了较好的计算效率,因此所进行的实验结果可为相关研究提供借鉴。
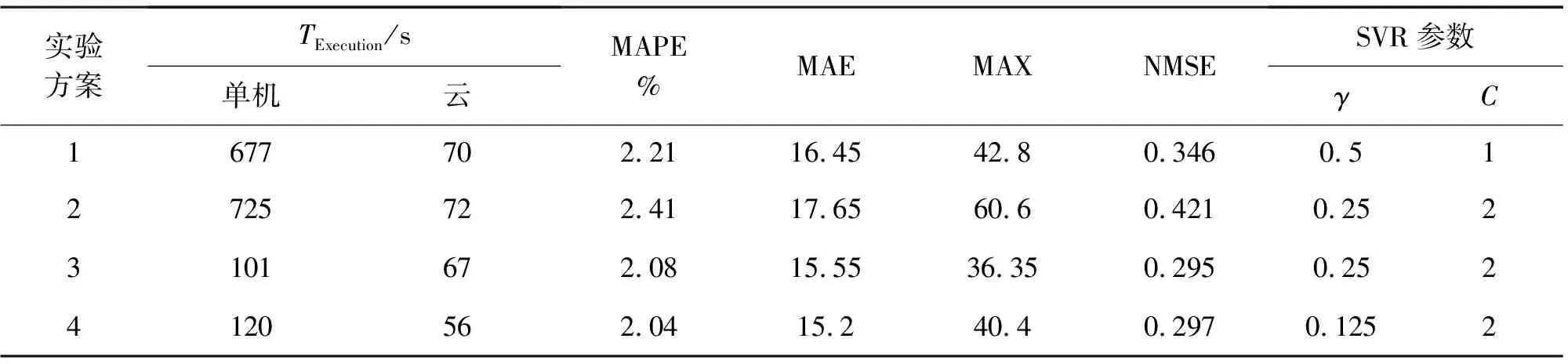
表2 实验结果
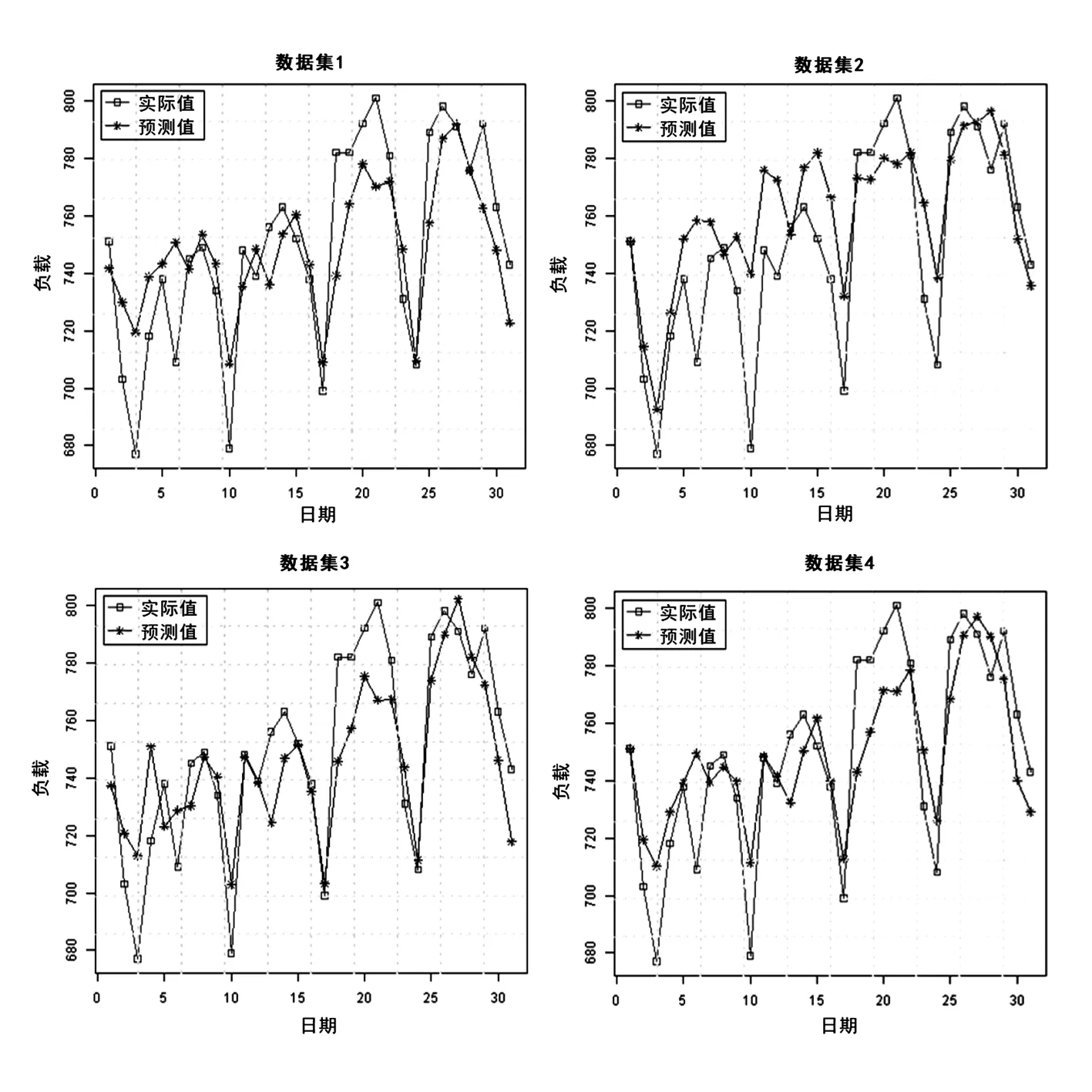
图2 各个实验方案下预测值和实际值的偏差
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
数学大王·趣味逻辑(2021年11期)2021-12-03 11:04:30
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
东北电力技术(2016年2期)2016-05-17 04:32:46
中国化肥信息(2016年35期)2016-05-17 04:25:50
河南电力(2016年5期)2016-02-06 02:11:32
核科学与工程(2015年2期)2015-09-26 11:56:59
河南电力(2015年5期)2015-06-08 06:01:46
