
二进制特征与联合层叠结构的人脸识别研究
2019-04-01 12:44:00陈冠豪
计算机应用与软件 2019年2期
胡 佩 陈冠豪
1(重庆工程职业技术学院信息工程学院 重庆 402260)2(重庆大学通信工程学院 重庆 400044)
0 引 言
在现有的人脸识别算法的研究与应用中,人脸验证或人脸鉴定采用的相似临近搜索技术成为影响算法速度的重要因素之一,如何进一步提高相似临近搜索技术的速度已成为研究的重中之重。
研究者们提出了两种思路来解决这个问题,一是在原始的特征表示上使用降维的方法来得到较短的特征表示,例如主成份分析PCA(Principal Component Analysis)[1]方法;二是如文献[2]中所述的方法将特征表示转换为二进制特征表示;更有将两者进行结合的方法,例如迭代量化方法ITQ(Iterative Quantization)[3]这些方法中,哈希算法在近几年受到广泛关注。哈希算法能在保持图像特征相似性的前提下,将图像特征映射为二进制编码,其在存储和在相似度计算上具有优势。近年来,基于监督的哈希算法越来越被引起重视,它们通过学习训练样本的关系来构建哈希函数,比传统的与数据无关的哈希算法更有效。但目前很多带监督的哈希方法[4-5]通常采用图像对或者图像三元组的方式进行训练,它使得训练阶段需要大量的计算代价和存储代价,最终使得模型训练几乎不可能实现。近几年,深度学习在图像分类、目标检测等多个领域都取得了较大的进展。从 NIN(Network In Network)[6]网络结构的提出到 Inception 结构的网络[7]在各方面取得较大提升,再到残差网络[8]在各种比赛中取得绝佳的效果等这一系列新的突破都说明了卷积神经网络学习图像特征表示上的能力。
根据深度卷积神经网络和哈希算法的优势,本文结合深度卷积神经网络与二进制哈希函数的编码方法构建名为深度二进制哈希的算法,将学习得到的二进制哈希码用于大规模的人脸识别当中。并针对哈希算法精度轻微下降的问题,通过联合级联结构进行人脸识别,通过层层筛选的方式在保持速度的前提下有效提升特征表达的准确率,最终在保证算法准确率的情况下,较大缩减计算时间。
1 深度二进制人脸哈希
1.1 定 义
深度二进制人脸哈希的基本思想为在卷积神经网络中构建哈希层,在学习特征表示的同时学习它对应的哈希函数,使得提取到的特征从浮点型的特征转换为二进制的特征。深度二进制人脸哈希的示意图如图1所示,网络前向传播后哈希层的激活值就是潜在的属性,也就是二进制特征。针对人脸这个场景,通过对哈希损失函数的优化来学习人脸专用的哈希函数,实现比传统哈希算法更好的特征二进制化。

图1 基于卷积神经网络的二进制人脸哈希示意图
深度二进制哈希算法与其他哈希算法的区别包括:
① 在原有的卷积神经网络中构建哈希层,将哈希层得到的编码输入分类器进行分类,Softmax分类损失函数作为优化目标之一。
② 通过图像的标签信息在学习分类的基础上还同时学习二进制编码对应的哈希函数。
③ 不仅仅考虑分类函数的误差,还考虑将浮点型连续值量化为二进制哈希码时产生的误差,使得哈希函数满足独立性和量化误差最小的约束,从而得到表达能力更强的哈希码。
④ 直接进行学习,不需要构建图像对或者三元组。
1.2 哈希层及二进制编码
假设图像集合表示为X={In}N,其中每个图像In∈Rd,N代表图像集合的大小;图像集合对应的标签集合为Y={yn}N×M,其中M为图像集合中类别的数量,每行为图像通过一位有效编码(One-Hot Encoding)后的结果,图像标签yn对应的列值为1,余下的值填充0。深度哈希算法的目的为学习一个映射,这个映射可以表示为:
H:X→{0,1}N×K
(1)
式中:X为K维度的输入特征;X代表映射;输入特征通过映射后得到的输出可以表示为K维的二进制编B={bn}∈{0,1}N×K。同时,该映射除了进行特征的二进制编码以外,它还需要保持着不同图像之间的相似性信息。
在如图1所示的基于卷积神经网络的二进制人脸哈希示意图中,特征提取层及其前面的所有层的前向传播操作共同组成上述映射,哈希层为Tanh激活函数,哈希层输出的激活值通过量化编码后就是二进制特征。

(2)

(3)

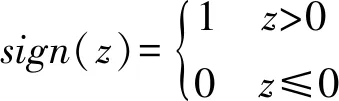
(4)
式中:sign(z)函数表示当z>0的时候为1,否则为0。对于矩阵类型的参数将对每个元素进行单独计算。因为Tanh激活后得到的范围为(-1, 1),故该公式通过取中间值 0 将松弛的“二值码”量化为二进制特征。
1.3 哈希损失函数及算法求解
同哈希算法构造的哈希函数差别巨大,最终的效果也是千差万别,但是有一点是相同的,那就是在保持数据的相似性的前提下使得二进制编码尽可能紧致。为了评判不同哈希函数的好坏,谱哈希SH(Spectral Hashing)[9]给出了对哈希函数的三个评价标准,本文对其进行了调整和修改:
① 它能够有效地创建并维持二进制编码之间的关系,学习得到的二进制编码能够保持图像类别之间的相似度关系,直接表现为同一类别的图像被映射到十分相似或者相同的二进制编码。
② 学习得到的二进制编码应该有区分性并且每位应该带尽可能多的信息,表现为更短的编码具有更好的效果。
③ 学习得到的二进制编码的每位独立并且均匀分布,表现为编码的每位出现-1或者1的概率都为 50%,即二进制编码的平均值为 0。
参考谱哈希的优化目标函数[9],为了平衡多个样本之间的关系,采用双通道网络结构来实现深度二进制哈希。在给定一个图像对(Ii,Ij),假设图像对应的特征为xi和xj,特征为输入图像在Rd维度下的表示,在这个维度下面特征之间的关系可以用欧式距离来代替相似度的关系。最终采用高斯核度量相似度G,相应的表达式为:
(5)
假设二进制哈希特征每位是相互独立的,相应的优化公式可以表示:
(6)

然而,这个方程存在一系列的问题,使得它没办法应用在神经网络当中,因此,将式(5)转化为采用多任务联合监督学习的方式进行优化。同时,因为将特征提取与哈希学习是结合在一起的,故只需要保证特征能实现正确分类,并保证特征哈希化正确即可。也就是说,通过Softmax分类损失函数和设计的哈希损失函数即可实现二进制特征的提取,相应的目标函数为:
(7)
式中:W代表神经网络中的所有参数;λ代表正则项系数;LS代表Softmax分类损失函数;LH代表哈希损失函数,其由两部分构成,表达式为:
LH=αLHB+βLHC
(8)
式中:α和β为超参,用于平衡多个任务的权重,表示不同任务的重要性。LHC为哈希紧凑损失函数,其表达式为:
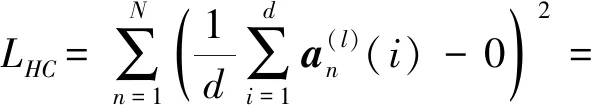
(9)
然而,如果单纯地使用紧凑损失函数,学习得到最优特征表示为所有的特征都为0。为解决这个问题,并将特征的数值尽可能拉开。故在卷积神经网络中,构建哈希二进制损失函数LHB,可以表示为:
(10)
通过哈希二进制损失函数,学习得到的二进制特征将尽可能地拉大与0 的距离。
2 联合级联结构的人脸识别
2.1 定 义
通过前一节的深度二进制人脸哈希,学习得到的二进制特征能有效地提高人脸识别搜索的速度。二进制特征的优点是提取特征和匹配速度快,但汉明距离不能完整地反映特征间的关系和未对姿态进行感知与学习等多个因素共同造成。所以,算法如何在保持速度的基础上进一步提高结果的准确率成为重要问题。
对于准确率和速度的矛盾,本文采用联合级联结构[10-12]进行结合,其中深度二进制哈希学习起到特征选择的作用。通过二进制特征来实现样本快速选择,经过选择后的样本使用高准确率并且抗姿态变化的人脸特征进行“精细”识别,最终实现在高精度下的高速识别。
2.2 识别流程
通过联合级联结构结合深度二进制人脸哈希与深度特征变换[13]的人脸识别,过程如图2所示。整个联合级联结构的人脸识别跟标准人脸识别算法的最大区别在于样本选择和有针对性的使用特征,最终实现层层递进地筛选匹配的样本,通过多种特征与多种度量的多次选择,匹配出最佳的目标作为结果。通过层层递进的选择过程在保持高准确性的基础上,还避免了直接使用高精度模型的高复杂度。
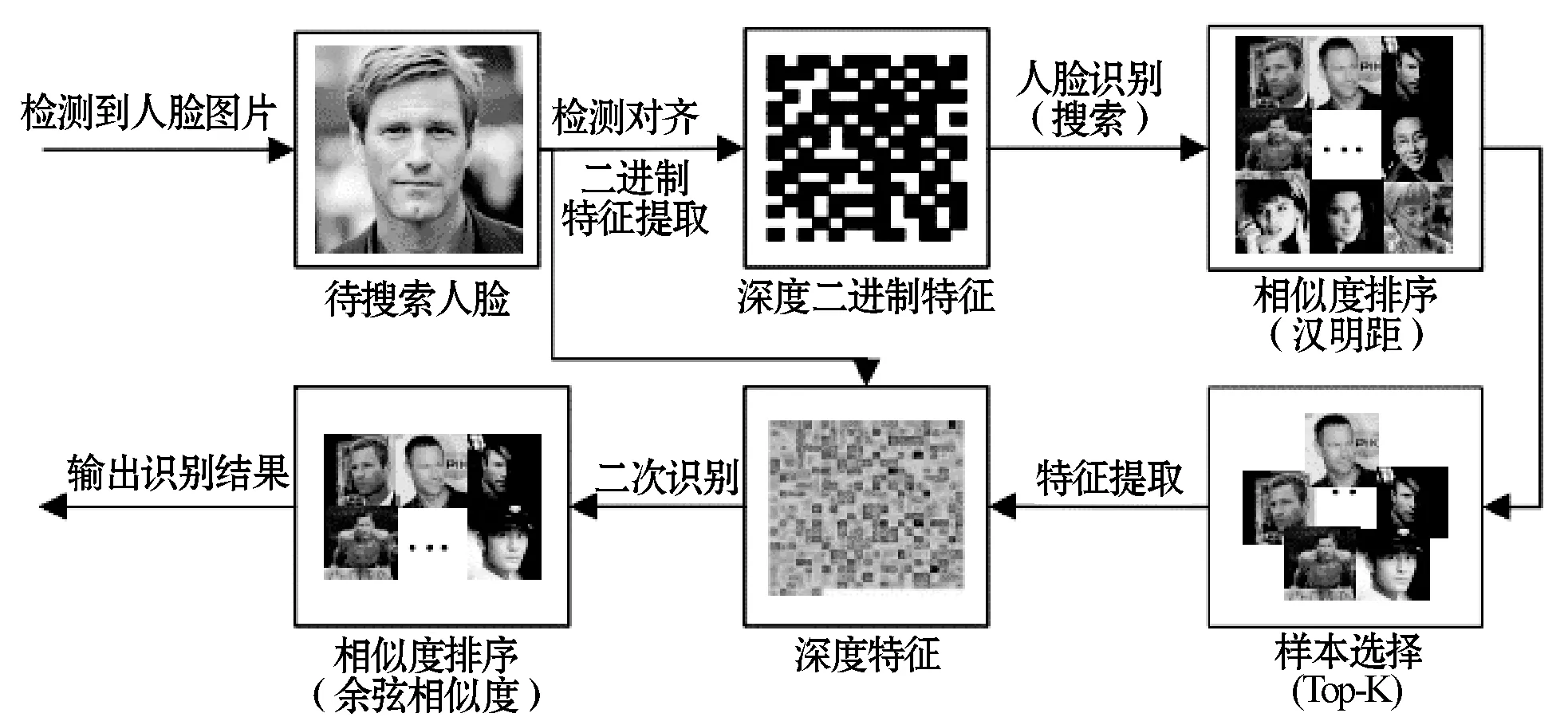
图2 基于联合级联结构的人脸识别示意图
这个过程中算法的基础组成和变化的步骤如下:
① 预处理 采用文献[13]的方式对目标图像中的人脸进行检测并对齐,得到对齐后的标准人脸图像I。
② 特征提取 通过随机梯度下降的方式训练并得到算法的模型,将标准人脸图像I作为输入,并行地输入文献[13]所述的卷积神经网络和论文所述的深度二进制哈希学习所示的卷积神经网络中,前向传播并提取相应的深度特征fP和深度二进制特征fB。
③ 样本选择 从人脸数据库中读取可能与输入样本有关的深度二值特征,计算标准人脸图像的深度二进制特征与它们的汉明距,并将结果的汉明距离作升序排序。考虑到汉明距离越小代表两者更加相似,故选取前K个对象作为样本选择的结果,将选择出来的样本编码输入到下一级的高精度人脸识别。
④ 高精度人脸识别 从人脸数据库中读取样本选择得到的K个对象的深度特征,计算标准人脸图像的深度特征与它们的余弦相似度并作升序排序。考虑到弦相似度越大代表两者更加相似,基于最近邻算法将相似度最大的样本作为识别的结果。
2.3 伪代码
人脸识别算法在测试阶段的伪代码如下:

算法: 基于二进制特征与联合层叠结构的人脸识别输入:对齐后的人脸图像集合I;人脸图像的关键点K;人脸数据库标签Y及对应的抗姿态变化特征fp和深度二进制特征fB;人脸图像集合的大小B;人脸数据库的大小D;预先定义的参数K;人脸识别最低阈值T输出:人脸识别标签集合Y⌒。1 for i=1…B do2 将对齐后的人脸图像Ii输入论文所述网络3 前向传播并提取深度二进制特征fiB4 for j=1…D do5 计算深度二进制特征fiB与fjB的汉明距离Hj6 end for7 根据汉明距离矩阵H对人脸数据库从小到大进行排序8 选取人脸数据库中汉明距离最小的前K条记录集合RK9 根据人脸图像的关键点Ki进行姿态估计,得到姿态角度YAWi10 对姿态角度YAWi进行分类,得到姿态类别Ci11 将对齐后的人脸图像Ii和姿态类别Ci输入文献[13]所述的网络12 向前传播文献[13]所述网络并提取深度抗姿态变化的特征fiP13 for j=1,…,K do14 计算深度抗姿态变化特征fiB与fRjKB的余弦相似度Sj15 end for16 根据余弦相似度矩阵S对人脸数据库从小到大进行排序17 if余弦相似度矩阵S的最大值小于阈值T then18 人脸图像Ii不存在于人脸数据库中19 continue20 end if21 选取余弦相似度最高的记录标签作为识别结果Y⌒22 end for
上述算法为基本的联合层叠结构的人脸识别的伪代码,并未包含主成份分析、三元组嵌入层[14]等多个实际场景中常常用来适配场景的步骤。
3 算法性能对比及实验分析
3.1 测试人脸数据集及测试子集
为了保证指标细节的可对比性和结果的可靠性,采用Facescrub[15]人脸数据集进行验证。Facescrub人脸数据集中包含106.9千张来自530位被采集者在非可控条件下采集到的照片。同时,因为仿真使用的计算机配置十分有限,而数据集中样本图像比较多,故本文算法通过随机下采样的方式从这个数据集中获取一个3万张图像的子集,总共300个个体,每个人包含100张图像。
3.2 平台及参数设置
图3为深度二进制人脸哈希的网络结构示意图。其中,卷积层均采用参数为3 × 3的卷积核,步长1,边缘填充1;子采样层均采用采样2 × 2的区域,步长为2,采样方式为最大值,采用汉明距离来度量特征之间的相似性。
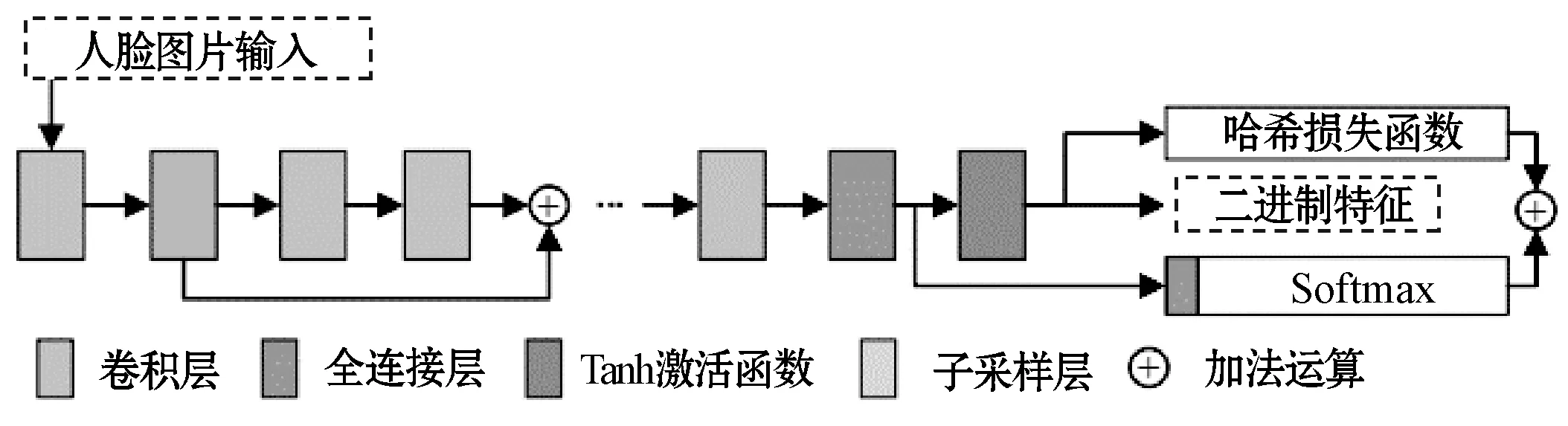
图3 深度二进制人脸哈希的网络结构示意图
3.3 性能指标评估及结果分析
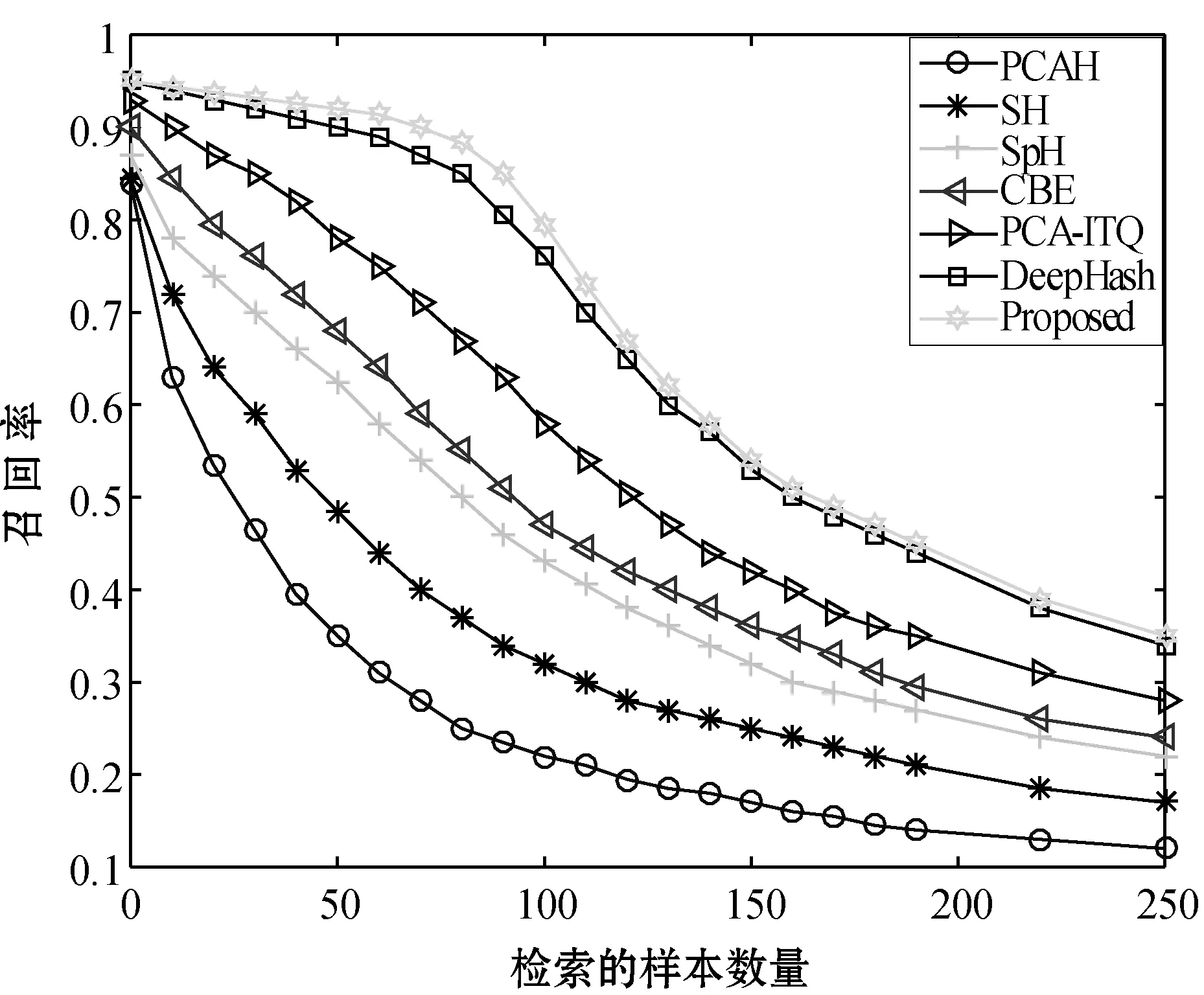
本文算法针对的是人脸识别这类索引问题,为了评价算法的好坏,本文采用准确率(Precision)、召回率(Recall)对人脸识别的效果进行评价。与目前主流的哈希算法进行比较,包括迭代量化方法ITQ(Iterative Quantization)[16]、基于主成分分析的哈希算法PCAH(Principle Component Analysis Hashing)[17]、基于循环二进制嵌入的哈希算法CBE(Circulant Binary Embedding)[18]、带监督的快速离散哈希FSDH(Fast Supervised Discrete Hashing)[19]、球哈希SpH(Spherical Hashing)[20]、谱哈希算法SH(Spectral Hashing)[9]。不同算法在不同编码长度下的准确率曲线如图4所示。

(a) 256位
(b) 512位图4 不同特征编码下算法的准确率曲线
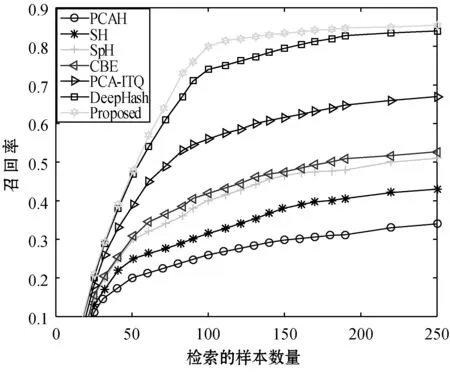
图4为不同特征编码长度下本文所述算法和常见哈希算法的准确率-检索的样本数量变换曲线,该曲线反映算法搜索结果排序的准确率。随着检索样本的增加,因为总的样本数量是有限的,对应的精度是不断下降的,本文所设定的单人图像数量是100张,故在检索的样本数量超过100张后曲线的下降趋势变快较多。从图中不难发现,本文所述的基于联合级联机构的人脸识别算法在精度指标上取得了较好的效果,其次是本文所述的深度二进制人脸哈希(DeepHash)。同时,随着编码长度的增加,如图4(a)和图4(b)分别所示,可以发现联合级联结构的人脸识别曲线没有较大提升,而深度二进制哈希学习对应的曲线不断得到提升,最终只是略逊于层叠级联结构的人脸识别。主要在于随着编码长度的增加,单位携带信息能力比较弱的二进制特征能携带更多的信息量,故表现出一定程度的增加。而层叠结构的人脸识别第二阶段采用的特征在较低编码长度下已经携带足够信息(每个特征携带的信息为二进制特征的32倍),这使得特征编码长度的变化对于精准度的提升表现不明显。接下来,对不同算法在不同编码长度下召回率曲线进行评估,结果如图5所示。
(a) 256位

(b) 512位图5 不同特征编码下算法的召回率曲线
图5为不同特征编码长度下本文所述算法和常见哈希算法的召回率-检索的样本数量变化曲线,该曲线反映算法搜索结果中出现的目标在总目标数中的比例。因为总的目标数量是有限的,故随着检索样本的增加,对应的召回率是不断上升的。不同算法的召回率性能它的准确率类似,表现为联合层叠结构的算法召回率最高,其次就是深度二进制哈希学习的召回率比较好。随着编码长度的增加,层叠级联结构的人脸识别曲线没有较大提升,而深度二进制哈希学习对应的曲线同样不断得到提升,具体的原因前面已经分析过,这里不再赘述。从召回率这个指标上,也说明了本文所述算法在召回率上较高的表现。
3.4 算法时间评估及分析
本文通过哈希的方式对特征进行二值化来提高系统运算速度,故算法的运行时间是评价的指标之一。
本次实验选取的人脸数据集为CASIA-WebFace[21],样本为250×250 大小的彩色人脸图像。人脸识别的全过程包含人脸与关键点检测、人脸姿态估计与分类、人脸对齐、特征提取以及利用相似度来搜索人脸图像的人脸识别阶段。
提取特征后,因不同协议有着不同的流程和时间复杂度,故接下来对不同的协议进行单独分析。对于人脸验证(1:1)协议,假设人脸图像对的数量为N,单次相似度计算需要的时间为T,显而易见人脸验证(1:1)需要的时间为:
Tv=N×T
(11)
对于人脸鉴别(1:N)协议,假设要搜索的图像数量为S,人脸数据库的大小为N,单次相似度计算需要的时间为T,则人脸鉴别(1:N)需要的时间为:
Ti=S×N×T
(12)
因论文对于时间复杂度的改进主要在最后的相似度计算上,因此,接下来在三种不同平台上对不同的相似度计算方法的性能进行仿真实验,相应的结果如表1所示。

表1 不同相似度计算方法千次计算所需要的时间
在表1中,不同的相似度计算方法都随着编码长度的增加而需要更长的时间;不同语言在速度上也存在差别,C++在常见语言中花费的时间是最小的,MATLAB和Python语言与C++相比花费的时间要长很多,主要原因是C++编写更加底层和存在编译器优化,而MATLAB和Python语言存在较大的IO开销和数学库优化的差异。仿真结果表明在三种编译环境中,本文所用的非紧凑汉明距离在时间性能上远优于其他两种相似度的计算方式。
因此,本文所述算法具有十分重要的意义。例如在MATLAB环境中,采用本文所述的二进制特征来计算相似度时,对于人脸验证,假设人脸图像对的数量N为1 000张,特征编码长度为1 024 bits,则根据表1可以计算得到基于非紧凑汉明距离的人脸验证消耗的时间为5.5毫秒,远小于余弦相似度和欧几里德距离所用时间。对于人脸鉴别,假设要搜索的图像数量为10,人脸数据库的大小为10 000,故可以看出识别出10张人脸的身份只需要550 ms,时间属于可以接受的范围。
通过联合层叠的方式进行人脸识别,根据式(12),它对应的时间为:
TC=S×(N×TH+K×TE)
(13)
式中:S代表要搜索的图像数量;N代表人脸数据库的大小;TH代表计算单次汉明距离需要的时间;TE代表计算单次计算欧几里德距离需要的时间;K代表排序重选的样本数量。式(13)相对于式(12),多出的时间为:
(14)

TC=S×(N×TH+K×TE) (15) 本文针对人脸识别这个场景,通过构建哈希层、哈希损失函数与卷积神经网络相结合来直接提取二进制特征,将人脸哈希算法通常采用的特征提取后,再独立地将哈希二进制化的流程简化为直接提取二进制哈希特征。同时,最终提取到的二进制特征能有效地提高计算速度并节约需求的存储空间,这对于移动端、嵌入式等计算能力比较弱的场合具有巨大的意义。 针对哈希后算法精度轻微下降的问题,通过联合级联结构进行人脸识别,这种方式通过层层筛选的方式在保持速度的前提下有效提升特征表达的准确率,最终实现算法在准确率几乎不下降的情况下,计算时间较大缩减。针对手机等嵌入式设备上计算能力比较弱并且存储空间代价比较高昂的场景,可以单纯采用基础的二进制特征进行计算;针对需要高精度的场合,可以采用联合层叠结构进行识别,实现在保持高精度下的高速识别。最后,论文通过在FaceScrub人脸数据集上做人脸识别仿真来评估算法的效果。4 结 语
猜你喜欢
作文中学版(2022年1期)2022-04-14 08:00:34
中等数学(2021年8期)2021-11-22 07:53:38
学生天地(2020年31期)2020-06-01 02:32:06
数学大王·低年级(2019年10期)2019-11-25 08:23:26
中等数学(2019年4期)2019-08-30 03:51:44
工业设计(2016年8期)2016-04-16 02:43:34
计算机工程(2015年8期)2015-07-03 12:20:04
计算机工程(2015年8期)2015-07-03 12:19:07
计算机工程(2014年6期)2014-02-28 01:25:40
电子设计工程(2014年12期)2014-02-27 11:58:03
