
fMRI在注意缺陷多动障碍症的应用
2019-04-01 09:26张芳芳
计算机应用与软件 2019年3期
李 楠 张芳芳
(太原理工大学信息与计算机学院 山西 太原 030024)
0 引 言
ADHD是一种常见的神经发育和精神障碍疾病[1],主要症状有注意力不集中、注意时间短暂、活动过度等,如果不及时诊断和治疗,会影响患者学业、身心健康及以后的家庭生活和社交能力。目前,ADHD的发病机制尚未完全了解,其诊断主要依赖于行为分析[2],其诊断方法用2000年美国提出第四版DSM(Diagnostic and Statistical Manual of Mental Disorders)测评表进行诊断,由1~100分进行测评,这种方法误诊、漏诊率比较高,为了提高ADHD的诊断率,近年来ADHD分类研究就成了神经影像领域的一个研究热点[3]。rs-fMRI是一种神经影像学方式,且基于rs-fMRI神经影像的数据研究精神疾病的分类方法已经开展了很多研究,rs-fMRI技术已广泛应用于脑的基础研究和临床诊断。
目前,已有大量研究者对ADHD展开研究而且取得了较多的科研成果,研究主要集中在以下两个方面:(1) 通过脑功能网络对ADHD进行分类,2012年Dai等[4]提出了功能连接的方法对ADHD进行分类,得到的分类结果为65.87%;2014年Dey等[5]构建脑功能网络的方法对ADHD进行分类,得到的分类结果为72.55%,分类结果有明显提高,但是上述方法构造脑功能网络后均需要进行特征选择、降维,最后结合分类器进行分类,实验过程复杂,需要耗费更多的时间。(2) 通过特征提取与分类器结合进行分类,2015年谭颖等[6]提出了基于小波变换与SVM的方法对ADHD进行分类,得到的分类结果为62.7%,这类方法实验过程简单,耗费时间短,但是这类方法的分类结果可以进一步提高,为ADHD病人的研究提供更有效的方法。
针对上述问题,近年来,很多学者用ICA(Independent Component Correlation Algorithm)的方法研究rs-fMRI数据,但是ICA算法用于rs-fMRI数据存在局限性。首先,无论是在时间还是空间上,ICA是基于成分因素的独立性假设,违反了这些假设,ICA的性能就会降低[7];其次,ICA成功用于rs-fMRI数据是由于其处理稀疏分量[8]。字典学习算法因其具有更稀疏的表示而受到学者的关注和研究[9],所以本文提出了字典学习的特征提取方法对ADHD病人与正常人进行分类。字典学习算法在图像去噪、图像修复、面部识别[10]、图像分类[11]等领域有广泛的应用,且发展前景广阔。为了将字典学习算法应用到神经影像领域中,本文利用字典学习对rs-fMRI进行特征提取,最后用分类算法SVM对其进行分类。字典学习特征提取的方法比ICA提取的特征更稳定,与其他方法相比,耗费的时间也比较短,而且得到的分类结果优于其他方法。实验结果证明了字典学习特征提取方法有助于对ADHD的分类,对ADHD的分类研究提供了一种新方法。
1 字典学习理论
字典学习的最终目的是通过训练数据找到我们所需要的字典,字典对特征提取有至关重要的作用,本文通过rs-fMRI数据训练出一个理想的字典,并以最小重构误差为准则求出稀疏表示,即得到rs-fMRI数据的稀疏分量。求得字典和稀疏表示的的原理如下:
字典学习[12]的目的是把Y矩阵分解成D和X矩阵:Y≈D×X,即给定一组信号Y=[Y1,Y2,…,YN],我们的目标是找到一组信号Y的线性表示:[Y1,Y2,…,YN]≈D[X1,X2,…,XN],D称为字典,X为稀疏编码,且稀疏编码X要尽可能稀疏,字典D的每一列都是一个归一化向量,字典学习的目标函数为:
(1)
式中:L为稀疏度约束参数。因为式(1)中有两个未知变量D、X,所以其求解方法是先固定字典D,再去最小化稀疏编码X。这样交替更新字典D和稀疏编码X,直到满足迭代终止条件为止,得到的D和X即为我们所求解的D和X。所以字典学习包括两个阶段,稀疏编码阶段和字典更新阶段。
1.1 稀疏编码阶段
假设稀疏参数X=[X1,X2,…,XN],字典D=[d1,d2,…,dk],我们的目的是根据字典D使得X尽量稀疏,由式(1)得:
(2)
式中:i=1,2,…,N,l为稀疏度约束参数。
1.2 字典更新阶段
通过稀疏编码阶段,我们已经知道样本的编码X,然后交替更新字典和编码。我们根据逐列更新的方法更新字典,如果我们现在更新到字典的第k列dk,编码矩阵X对应的第k行xk、dk和xk分别为:
(3)
(4)
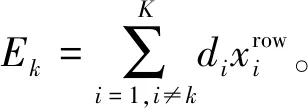
1.2.1 构造残差向量
首先用xi和di相乘重构出数据,然后计算出残差向量:
(5)
式中:j=1,2,…,N,Ekj为第j列的残差向量,由式(5)可以得出每列的残差向量,所以最后构造出的残差向量为:
Ek=[Ek1,Ek2,…,EkN]
(6)
1.2.2 更新字典
由式(3)、式(4)和式(5)得:
(7)
(8)
iter=iter+1
(9)
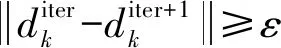
2 实验步骤
实验步骤分为三步:(1) 数据的获取及训练集和测试集的划分;(2) 用字典学习算法进行特征提取;(3) 利用SVM分类进行分类,具体的流程框图如图1所示。

图1 实验流程图
2.1 数据来源与预处理
本文研究的rs-fMRI数据来自Neuro Bureau[13]提供的预处理ADHD- 200[14]全球竞赛数据集中北京大学的数据集。数据库共有244个被试,其中ADHD被试101人,健康被试143人,所有被试均为右利手,平均年龄为12岁,智力水平在80分以上,且没有神经系统疾病、精神分裂症、发育障碍、情感障碍及药物依赖。本文选择数据库里所有的被试进行实验。实验数据的预处理步骤包括运动校正、时间层校正、配准、高斯平滑及被试间的配准[13]。
在实验中,将数据集划分为训练样本和测试样本,实验数据样本划分结果如表1所示。
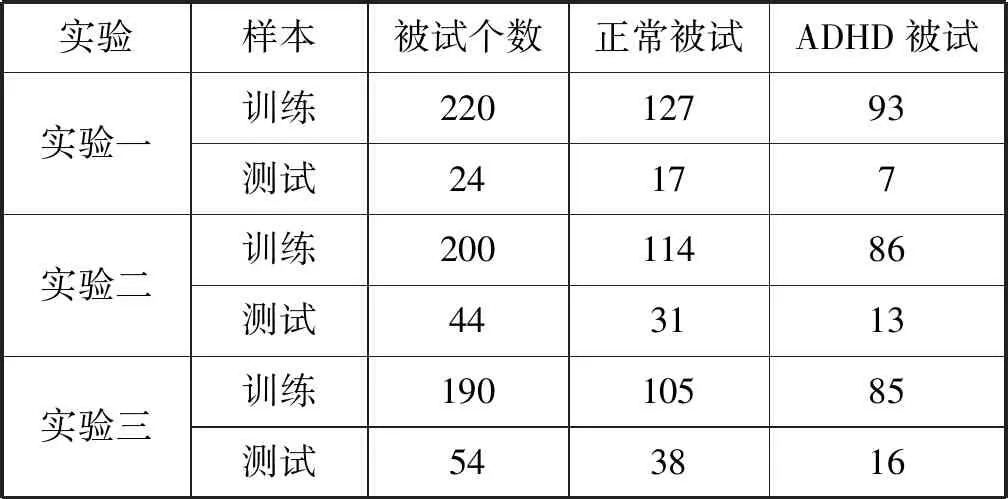
表1 实验数据样本划分结果
2.2 特征提取
在rs-fMRI的研究中,特征提取过程对分类准确率有重要影响。本文采用字典学习提取成分因素的方法进行特征提取。
首先对字典进行初始化,即对字典函数的参数进行设置,其中稀疏度为1,字典迭代20次,最重要的是设置成分因素,通过提取不同的成分因素对结果的影响,最终在实验中选择提取13个成分因素。这些成分因素分别对应若干个体素,然后用划分好的训练样本对字典进行训练,最终得到稀疏矩阵X。图2为训练字典的过程。
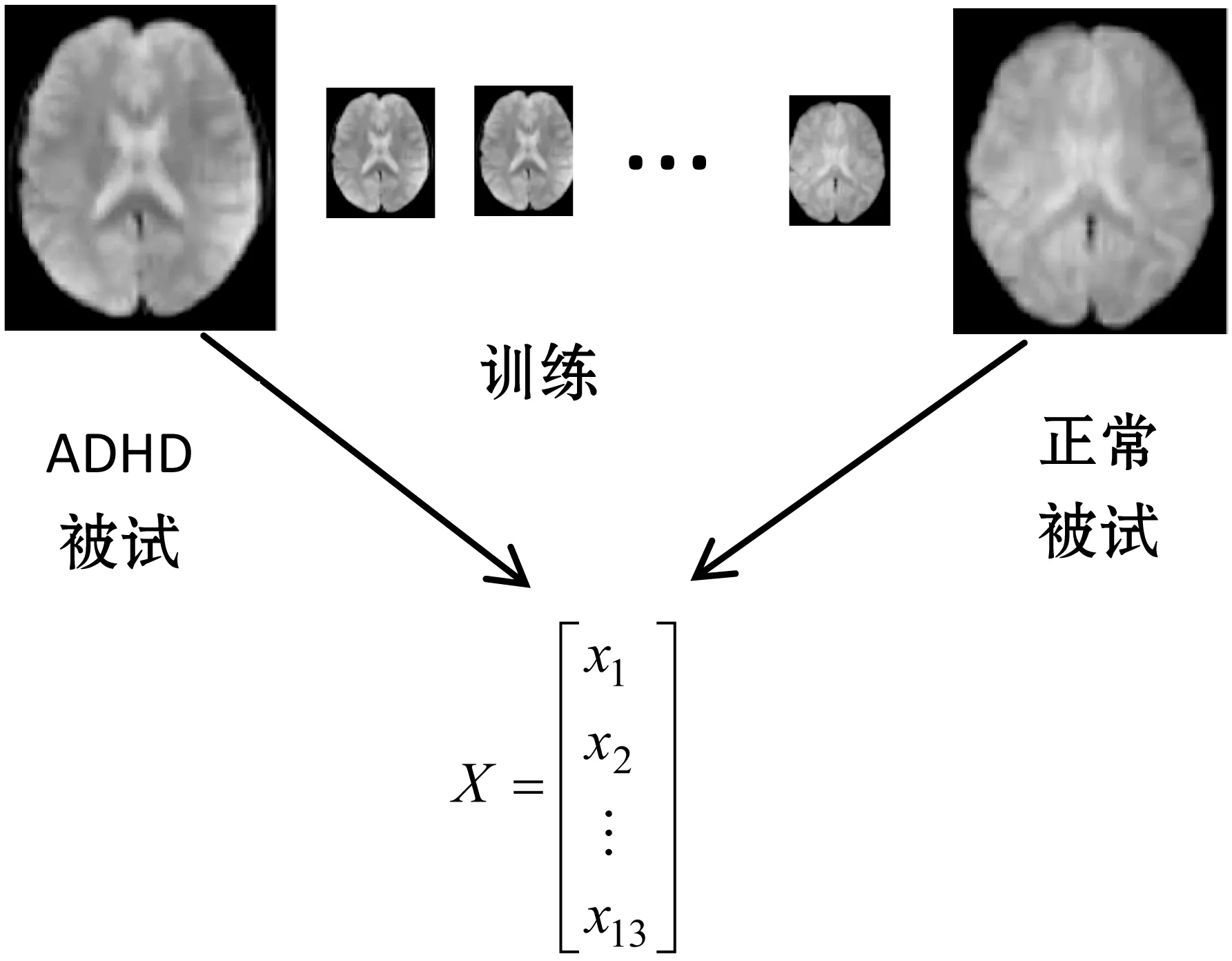
图2 训练字典过程
稀疏矩阵X包含提取13个成分因素,每个成分因素又包含63 061个体素,即X=[13,63 061],将所有体素映射到MNI(Montreal Neurological Institute)标准模板上,得到一个包含所有体素的四维脑图像。将包含所有体素的四维脑图像与每个被试对象进行拟合,得到每个被试对象的时间序列,由于得到的时间序列包含13个成分因素,不能直接进行分类,所以通过参数矢量化(vectorize=ture)将每个被试对象的时间序列转化为一维数组,得到的一维数组即为提取的每个被试对象的特征。其中一个被试对象的时间序列如图3所示,一个被试对象提取的特征如图4所示。图3和图4为同一个被试对象。
图3 时间序列

图4 提取的特征
2.3 SVM分类
由于rs-fMRI数据是线性可分的[6],所以本文选择线性SVM分类器[15]进行分类,惩罚参数C=1。在SVM分类之前,首先把ADHD病人的类别标签labels标记为1,正常人的类别标签标labels标记为0,每个被试分别对应一个特征向量和一个类别标签labels。然后将特征向量和类别标签labels输入到SVM分类器进行分类。最后用特异性、灵敏度、分类准确率以及ROC(receiver operating characteristic)曲线来量化分类器的性能。各个性能指标的计算方法如下:
式中:SN为灵敏度,也称真阳性率,指正确判断ADHD病人的程度,即实际有病且被正确诊断的百分比;SP为特异性,指正确判断正常人的程度,即实际无病且被正确诊断为无病的百分比;ACC为分类准确率,即正确判断所有被试的程度;TP为真阳性个数,即ADHD病人正确分类的个数;TN真阴性个数,即正常被试正确分类的个数;FP假阳性个数,即正常被试错误分类的个数;FN假阴性个数,即ADHD病人错误分类的个数;FPR为假阳性率。ROC曲线的横坐标为FPR,纵坐标为SN,曲线下的面积可以反映分类器的性能,面积越大,分类器的性能越好[6]。
3 实验结果与分析
为了排除单次实验结果的偶然性及训练集和测试集的划分影响实验结果的真实性,本文将数据集划分为训练集和测试集,分别进行三次实验,实验一的测试集为24个被试对象,实验二的测试集为44个被试对象,实验三的测试集为54个被试对象,对三次实验的结果进行均值化得到最终的分类准确率。用字典学习分别对训练集提取特征,然后利用参数矢量化将提取的特征转化为一维数组,最后利用SVM分类器对一维数组进行分类,字典学习的分类结果如表2所示,分类的ROC曲线如图5所示。
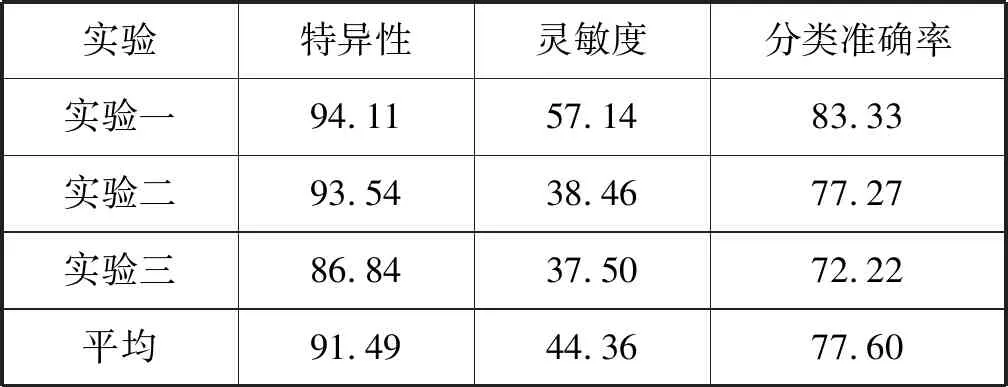
表2 字典学习分类结果 %
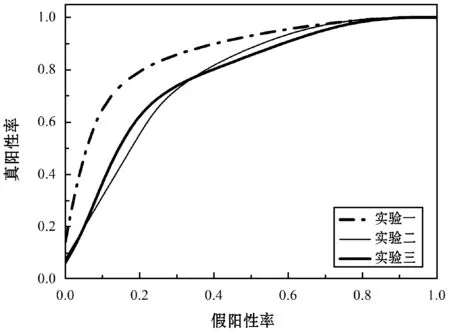
图5 分类的ROC曲线
特征提取的方法对分类器的性能有显著影响,为了与本文提出的方法进行对比,选择ICA的特征提取的方法进行对比,其他条件相同的情况下,用ICA对rs-fMRI进行特征提取,最后结合SVM分类器对提取的特征进行分类,ICA特征提取方法得到的平均分类准确率为71.92%,表3为本文方法与ICA及文献中的分类结果进行比较。
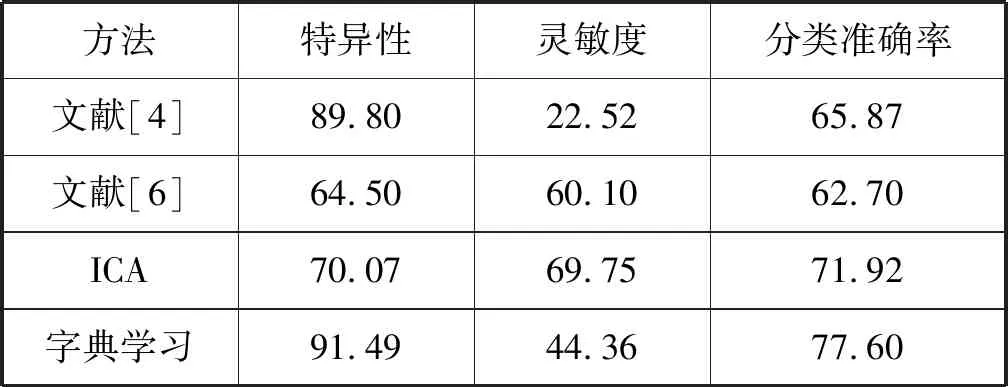
表3 本文以其他方法分类结果的对比 %
从表2可以看出三个实验的平均分类准确率为77.60%,实验一的分类准确率最高,达到83.33%,且分类灵敏度和特异性较好,实验二和实验三的分类准确率和灵敏度明显低于实验一。从ROC曲线也可以看出,实验一的ROC曲线下的面积达到0.76,实验二和实验三的ROC曲线下的面积只有0.60左右,实验一的曲线下的面积明显大于实验二和实验三曲线下的面积,综上所述,在本文的实验过程中,实验一的分类性能较好。
从表3可以看出,文献[4]通过构建脑功能网络对ADHD进行分类,得到的分类结果为65.87%,而且构建脑功能网络的过程复杂,需要耗费更多的时间;文献[6]通过小波变换与SVM对ADHD进行分类,得到的分类结果为62.7%,小波变换作为一种传统的方法,应用在很多领域,但是文献[6]是提取了大尺度功能时间序列的平均信号,对ADHD分类有一定的局限性;ICA特征提取的方法对ADHD分类,得到的分类结果为71.92%,ICA提取的特征为独立分量,但是有研究表明,ICA应用于rs-fMRI,是由于其处理稀疏分量,而不是独立分量,所以针对ICA提取的独立分量而不是稀疏分量;本文用字典学习的特征提取方法对ADHD进行分类,得到的平均分类准确率为77.60%,字典学习提取rs-fMRI的稀疏分量,在稳定性方面优于ICA,大大缩短了特征提取的时间,分类的结果分别比文献[4]、文献[6]、ICA方法提高了11.73%、14.9%、5.68%,实验结果验证了字典学习算法应用在rs-fMRI领域的有效性。由以上分析可知,基于字典学习特征提取的方法对ADHD的分类结果有明显的提升,其与SVM结合有助于ADHD病人与正常人的分类。
4 结 语
随着脑科学的不断发展,本文针对rs-fMRI数据提出了一种基于字典学习的特征提取方法,对ADHD病人与正常人的特征进行分类。实验得到的平均分类准确率为77.60%,在研究中发现,本文提出的字典学习的特征提取方法有助于ADHD病人与正常人的分类。但是本文提出的字典学习提取的不同成分因素针对的是全脑的体素,没有对全脑的体素进行选择,所以在以后的学习和研究中,重点对字典学习提取的部分体素和特征进行学习和研究,进一步探讨字典学习提取的不同成分因素对ADHD病人与正常人分类的影响。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
小学阅读指南·低年级版(2019年11期)2019-07-01
计算机测量与控制(2019年4期)2019-05-08
雷达学报(2018年5期)2018-12-05
小天使·一年级语数英综合(2017年11期)2017-12-05
读者(2016年14期)2016-06-29
