
基于众包标注的中文微博命名实体识别
2019-04-01 09:10汤文兵桂海霞张顺香
计算机应用与软件 2019年3期
房 辉 汤文兵 桂海霞 张顺香
1(安徽理工大学计算机科学与工程学院 安徽 淮南 232001)2(安徽理工大学经济与管理学院 安徽 淮南 232001)
0 引 言
近年来微博发展迅速,微博社会群体日趋庞大并且社会影响力也越来越大。Q3微博财报数据显示,截至2017年9月,微博月活跃用户共3.76亿,与2016年同期增加27%;日活跃用户达到1.65亿,较去年同期增加25%[1]。
命名实体识别的目的是识别出语料中的时间、地点、人名等命名实体[2-3]。针对微博命名实体识别,Van Cuong Tran等提出一种称为TwiSNER的方法,通过结合条件随机场模型、人工制定的规则以及围绕实体特征词的共现系数的半监督学习方法,对微博中的命名实体进行分类[4]。Diego Esteves则提出一种不依赖任何特定语言资源和编码规则的新型多层体系结构,与传统方法不同,他们使用从图像和文本中提取的特征对命名实体进行分类[5]。
上述方法针对微博文本短小、语言不规范以及噪声多等特点,取得了很好的命名实体识别效果。但中文微博语境更加复杂,使用机器进行命名实体识别存在识别成本高以及识别速度慢等问题[6]。为了解决以上问题,本文提出了基于众包标注的中文微博命名实体识别方法,利用众包平台上大量的众包者来对命名实体进行高效的识别。首先在众包过程中对众包标注者的能力进行评估,确定每个标注者的能力值;然后使用最大期望值算法对评估得到的众包标注者的能力值以及评估过程中产生的临时标签进行分析学习,过滤掉其中的噪声;最后根据优化的众包标注者能力值对微博众包标记的结果进行纠偏,从而确定最后的命名实体。
1 相关工作
1) 众包标注 目前,深度学习在解决不同领域的人工智能问题方面取得了重大发展,这种成功主要归因于其能发现高维数据中错综复杂的结构。然而,学习复杂高维数据的深层表示的关键需求是大量的标记数据,在许多情况下,这些数据并不容易获得,需要人们手动标记大量的数据。
近年来,众包已经成为标记大型数据集的可靠解决方案[7]。众包标注的过程就是众包发起者在众包平台上向参与者分配众包任务,让他们来完成标注任务,并且每一个标注任务可以分配给不同的标注者来完成以保证质量,最后将标注的结果收集起来。众包标注的具体流程图如图1所示。
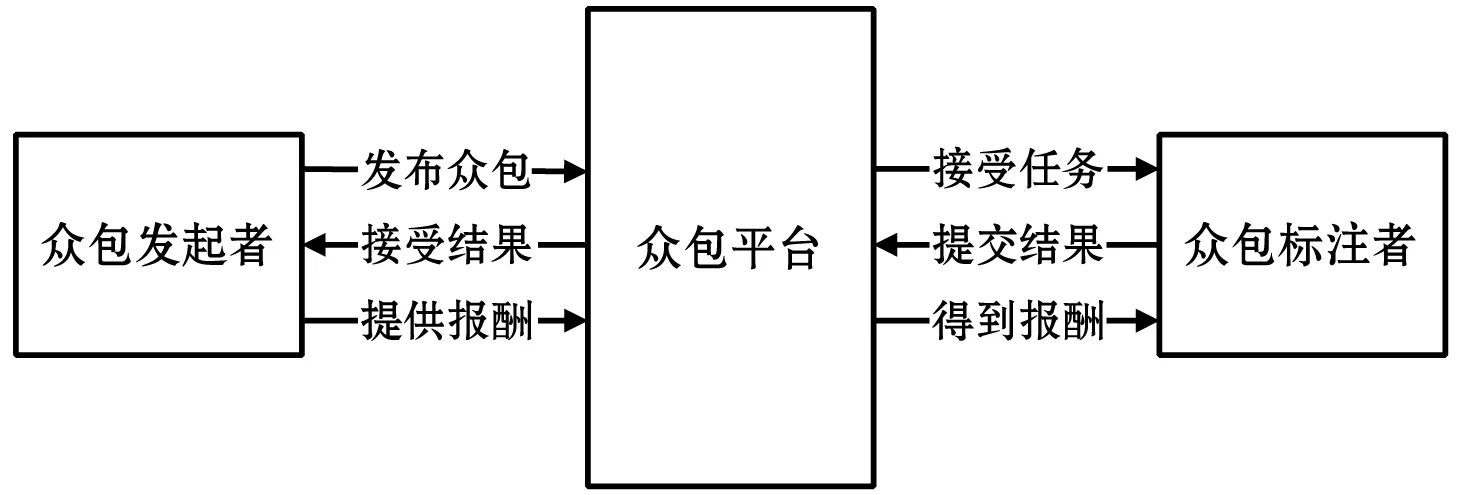
图1 众包流程
2) 众包数据分析与处理 Amazon Machaical Turk以及CrowdFlower等众包平台的成功已经证明众包是获得标签数据有效、低成本的方式,但众包数据的质量并不能得到保证[8]。在众包过程中,众包标注者的能力、工作态度以及众包任务的难易程度都会对最后数据的质量产生影响。虽然传统的专家标注方法得到的数据质量问题不大,但是标注成本高、速度慢,并不适用于庞大的数据集。
为了保证数据的质量,对众包平台数据进行监督学习具有重要意义。目前最常用的方法是通过重复标记生成冗余的标注数据,然后使用机器学习算法过滤这些数据的噪声以获得高质量的标注数据。
2 众包标注者能力评估算法
众包标注者能力评估算法是对参与众包任务的标注者能力进行评估,筛选掉能力值较低的标注者,从而使得最后的标注数据准确性更高。由于参与众包的标注者的能力是未知的,因此,众包标注过程中最关键的部分就是对于众包标注者能力的评估[9-10]。
2.1 算法模型
该众包标注标注者能力评估算法由标注者的基础能力值和业务能力值两部分组成。算法的框架图如图2所示。
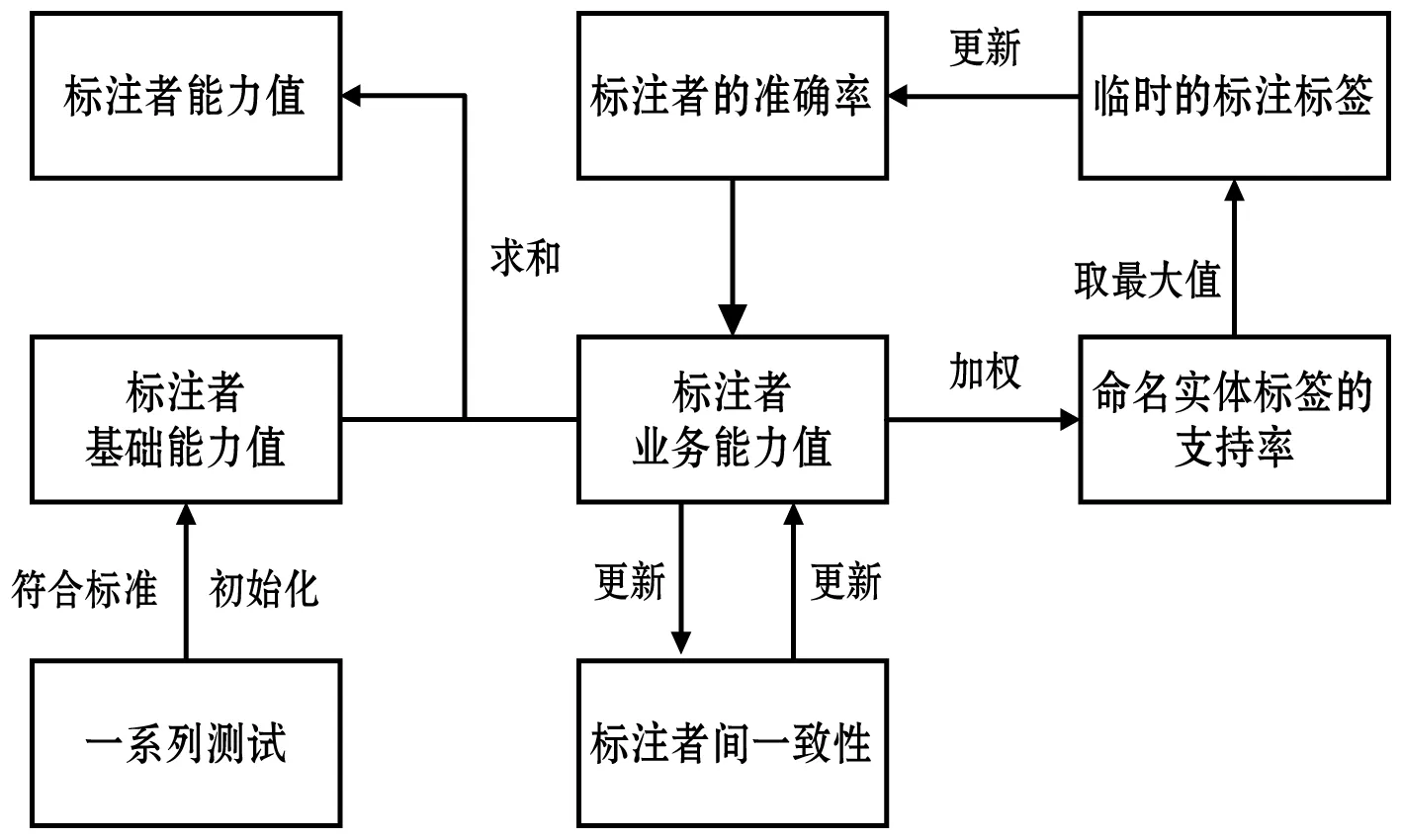
图2 众包标注工作者能力评估算法框架图
其中,标注者的基础能力值由申请众包任务前的一系列测试所决定。测试包括技能测试以及心理测试。通过测试能淘汰掉一些综合素质较差的众包申请者。此次测试能大致了解每个众包标注者的能力,确定每位符合标准的众包标注者的基础能力值。
业务能力值由众包标注者在进行微博命名实体识别时的准确率以及标注者间的一致性共同决定。如果众包标注者的识别准确率越高,则说明该标注者能力越高。一致性是指能力越高的标注者之间的标注结果通常是趋于一致的,如果该标注者与其他标注者的一致性越高,则说明该标注者能力越强。
2.2 算法描述
众包标注者能力评估算法基于标注者的基础能力值和业务能力值对标注者进行能力评估。通过技能测试以及心理测试得到标注者的基础能力值。在业务能力值确定过程中,根据标注结果不断迭代更新标注者的准确率以及标注者间的一致性,直到达到最大迭代次数。最后,得到标注者的能力值。
2.2.1 算法相关定义
定义1(实体对象集合) 给定的中文微博众包标注任务中需要对n个实体对象进行标注,实体对象集合记为x={xi|i=1,2,…,n},其中xi表示第i个实体对象。
定义2(众包标注者集合) 通过一系列测试后符合众包标注任务标准的标注者的集合为u={ur|r=1,2,…,m},共m个标注者,其中ur表示第r个标注者。
定义3(初始能力值) 每个标注者的初始能力值集合为w={wr|r=1,2,…,m},其中wr表示第r个标注者的初始能力值。

首先,对于第r个标注者所完成的标注准确率Ar的计算就是求出该标注者在本次中文微博实体标注任务中所给出的标注标签与所有实体对象正确标注标签相同的比率。其中实体对象正确标注标签就是根据众包标注标签最后生成的最终标注标签。第r个标注者所完成标注的准确率为:
(1)
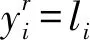
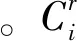
(2)
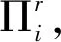
(3)

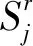
(4)
2.2.2 算法流程
基本流程如算法1所示。
算法1众包标注者能力评估算法
输入:收集到的众包标注集合yn,标注者初始能力集合w,最大迭代次数max
输出:标注者的能力值集合
1)i=1,迭代计数器p=1;
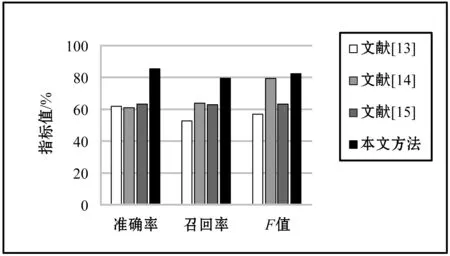
2) while(i 3) 取第i个命名实体对象的所有标注结果; 4) 计算标注结果对应于每类命名实体的支持率; 5) 取最大支持率或该类别能力值最大的标注者的标注结果确定为该命名实体对象的临时标签li; 6)r=1; 7) while(r 10) 计算第r个标注者在第i个实体对象上的标注准确率Ar; 12)r++; 13) endwhile; 14)i++; 15) endwhile; 17) 迭代计数器p的值加1,判断是否达到最大迭代次数max,若是,则跳转到步骤18,否则跳转到步骤2; 18) 返回标注者的能力值集合。 众包平台上的每个众包标注者之间都是相互独立进行众包标注,并且在众包标注者能力评估算法中通过计算众包标注的支持率可知命名实体种类li,因此可得式(5): (5) 式中:Θ表示众包标书进行中文微博命名实体识别的能力: (6) 式中:Ar由式(1)求得,代表每个标注工作者的标注准确率。 基于式(5),可以导出一个期望最大值算法,用来学习众包标注工作者的能力Sr。期望最大值算法求解由式(7)给出: Inp(D|Θ,{S1,S2,…,Sm})= (7) EM算法充分考虑了众包标注者的能力值误差因素,帮助众包平台排除能力值较低的工作者,具体步骤如下: q(li=c)∝ (8) (2) M-step 寻找能使E-step产生的最大似然期望最大化的参数值,将众包标注工作者的能力值更新为: (9) (10) 共进行两组实验,都是进行人名、地名、机构名的识别。第一组实验的目的是验证众包标注方法识别中文微博命名实体的有效性,第二组实验是考察不同参数对于实验结果的影响。 第一组实验选用的是1998年1月的《人民日报》(RMRB-98-1)语料库中前80%共15 850句的数据以及2018年5月在新浪微博上(XLWB-18-5)收集的20 000条微博的前80%作为开发训练集,剩余部分作为开发验证集,数据集的详细信息如表1所示。第二组实验的数据与第一组相同。由于微博更新速度快,为了避免在某一时间段内由于某个热门话题导致某些实体过度重复的问题,在5月的微博中,从时间上平均地选取了20 000条微博。 表1 数据集的详细信息 实验采用Python编程,运行服务器配置为2.80 GHz Intel(R) Core(TM) CPU和8 GB内存,软件使用的是Win10操作系统和PyCharm编译器。实验的评价标准是准确率P、召回率R以及调和平均数F值。 本文使用RMRB-98-1和XLWB-18-5作为开发集,让20位标注者对开发集进行标注,目的是标注出人名、地名、机构名三类实体。在标注过程不断对标注者能力进行评估,然后使用EM算法过滤噪声,得到最后的标注结果。实验结果如表2所示。 表2 众包标注模型实验结果 由表2可以看出,相比训练集,测试集的识别效果均有所下降,这说明某一标注者如果识别某一种命名实体的能力最高,但其标注结果并不能保证完全正确,相反某些能力较低的标注者的结果存在一定概率是正确的。 本文分别采用文献[13-15]的方法与本文方法在新浪微博数据上进行命名实体识别效果比较。人名、地名、机构名3种命名实体的准确率、召回率及其加权调和平均值F值分别如图3-图5所示。 图3 人名实体识别的准确率、召回率与F值 图4 地名实体识别的准确率、召回率与F值 图5 机构名实体识别的准确率、召回率与F值 通过比较四种方法在中文微博数据上进行命名实体识别的效果可以发现,本文提出的众包标注方法识别效果最好,证明了本文方法的有效性。从图3与图4可以看出,与其他三种方法相比,人名和地名的识别效果大大提高,准确率、召回率以及F值均达到了80%左右,识别效果十分可观。因为相比机器识别,人们在日常生活中会接触到大量的人名、地名,所以对这两种命名实体十分敏感,并且微博语句中的人名、地名也十分明显,但是识别效果依旧没能达到预期的90%以上。通过分析标注者的标注结果可以看出,很多标注者不能准确识别人物别名(例如,明星谢娜的别名叫娜娜或娜姐,很多标注者只能识别出谢娜,其他两种别名并不能准确识别)以及错误识别地名(例如“我在草地上”,有的标注者会将草地是识别成地名,准确来讲只能算作地理位置)。 由图5可以看出,机构名的识别效果虽然相比较文献[13]和文献[14]有了一定提升,但与人名、地名的识别效果相比存在很大的差距,准确率只有62%左右,召回率不到50%。主要是因为标注者对于机构名储备知识不够,因此通过培训众包标注者对于基础知识的掌握能力,可以大大提高命名实体识别效果。 主要考察标注者能力值中的参数η。不同的η值会影响标注者的标注准确率和标注一致性对于业务能力值的贡献比例,从而影响算法对标注者能力值的评估,不同能力值的标注者识别命名实体的准确率存在很大误差。图6给出在λ=0.8,η取不同值时,人名、地名、机构名三种命名实体识别F值的平均值的情况。 图6 η取不同值时命名实体识别F值的平均值 从图中可以看出,随着η取值的不断增加,三种命名实体识别F值的平均值先不断增加,然后减少,当η=0.5时达到最大。其中η=0时的值明显大于η=1的值,这是因为η=0时,众包标注者的能力值只取决于众包标注者间的一致性,而η=1时,能力值则取决于标注者的标注准确率,在计算标注的准确率时,是以众包标注过程中产生的临时标签作为评价标准进行计算的,因此存在较大误差。 本文针对微博更新速度快,语言不规范和噪声多等特点,提出采用众包标注方法识别中文微博命名实体。通过能力评估算法对众包标注者的能力值进行初步评估,随后通过EM算法对能力值进一步优化。实验验证了相比较传统方法,众包标注方法有效提高了对于中文微博命名实体识别的效果,并且成本更低、速度更快。由于微博自身内容的特殊性以及标注者知识储备的局限性,本文方法对机构名的识别率还不够理想,因此,接下来工作将是如何提高结构名的识别效果。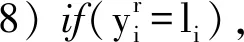
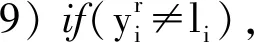

3 众包质量控制算法
3.1 期望最大值算法估计标注者的能力值
3.2 噪声过滤和正确结果估计

4 实 验
4.1 众包标注命名实体实验



4.2 参数对结果的影响

5 结 语
猜你喜欢
健康之家(2021年19期)2021-05-23医学食疗与健康(2021年27期)2021-05-13农业科技与信息(2021年2期)2021-03-27中学生数理化(高中版.高考理化)(2021年2期)2021-03-19健康体检与管理(2021年10期)2021-01-03中国外汇(2019年18期)2019-11-25当代陕西(2019年5期)2019-03-21东方女性(2018年3期)2018-04-16散文诗(2017年17期)2018-01-31中国诗歌(2017年12期)2017-11-15
