
基于深度学习的场景数字检出
2019-03-28 09:09
制造业自动化 2019年3期
(青岛大学 自动化与电气工程学院,青岛 266071)
0 引言
随着网络技术的发展,信息量剧增,现已进入到大数据时代。网络每天会产生庞大的信息量,面临的一个巨大难题就是从海量的信息中提取出对我们有用的信息。网上的图片、视频都包含大量的文本信息,这些信息称为场景文本信息。场景文字检出的研究早在21世纪初就开始了,目的是识别图片、视频中的文字。传统的方法有基于数字特征(连通域)的方法[1],支持向量机( Support Vector Machines)[2],BP神经网络[3]等,传统的检出思路大致分为两步,先检测定位文本,再进行识别[4]。现阶段一些算法将两步并作一步,定位与检测同步进行,称为端对端检测,本文采用的YOLO(You Only Look Once)算法,便可以实现端对端检测。许多新型应用都需要提取某些场景中的数字信息,例如:车牌号的识别;拍照翻译、搜题;马拉松过程中对运动员的实时监测;集装箱箱号的识别等,这已经成为计算机视觉的热门研究方向,该研究具有广阔的应用前景。
1 传统检出方法
传统的文字检出,大多是基于字符[5],即先检测字符,再对其进行组合,比如利用SVM和ANN实现的字符识别[6]。传统的检出方法一般分两步,首先要确定文本的位置。常见的方法,是假设文本之间是连通的,通过对图像进行二值化,膨胀,腐蚀等处理,将待检测文本真正连通起来,从而确定待检出文本的位置。但是如果图像质量不高,背景复杂,处理起来会很麻烦。第二步,要检测文本,需要先分割图像,将一串字符分割成单个字符,然后再逐步对单个字符进行检测,最后将检测结果输出。
这种方法的缺点就是在于只适合场景简单的图像,对于复杂场景下的文本,定位与检测都有难度。需要对图像做细致的处理,大大增加了工作量。通常现实场景都是很复杂的,所以这种方法在实际应用上会有很大局限。
2 基于深度学习的方法
近几年,深度学习越来越成熟,出现了很多新算法,在许多领域都取得了不错的成就[7]。本文将图像分类问题用目标检测算法来解决,目标检测算法主要分为两类:One-Stage和Two-Stage检测算法。Two-Stage检测算法是先产生候选区域,再对候选区域分类,代表算法有R-CNN、Fast-R-CNN和Faster-R-CNN算法。One-Stage算法不需要产生候选区域,直接进行分类,代表算法有SSD和YOLO算法[8]。两者都是基于深度学习的卷积神经网络,但是设计思路有些方面有所不同,各有优势。R-CNN系列算法检测的精准度比较高,速度略逊一筹,YOLO算法检测速度较快,但是在精度上不及R-CNN[9]。因为本文是用于检测数字,检测对象只是0~9十个数字,YOLO算法的精度完全可以满足,并且速度更快,所以选择YOLO算法。
2.1 检测思路
区别于传统方法,基于深度学习的文字检出,将定位与判断并作一步,同时进行,实现端对端的数字检测。
R-CNN算法,采用的是滑动窗口技术,即对于一张图像,用一个小窗口按照规定的步长在图像上滑动,每滑动一步,做一次图像分类,这样便做到对整张图像的检测。但是,对于不同的检测对象,滑动窗口大小的选择也是问题,而且选择不同大小的窗口,产生的候选区域太多,运算量太大,从而检测速度会降低[10]。Fast-RCNN就此做出了改进,用卷积层代替原来的全链接层,改进后运算量减小,检测速度便大大提高。
区别R-CNN,YOLO算法采用了一种新颖的思路,没有采用滑动窗口,而是直接将图像分割成若干个格子,再通过卷积得到每个单元格的特征图,然后每个单元格各自负责预测中心点落在自己区域内的目标。这样就消除了复杂的滑动窗口的计算量,所以在检测速度上要快一些。每个单元格会预测几个边界框和它们的置信度,边界框的置信度包括两个方面,包含检测目标的可能性和边界框的准确度。每个边界框的预测值包括五个元素:(x,y,w,h,c),(x,y)是边界框的中心坐标,(w,h)是边界框的宽和高,c为置信度。
边界框类别置信度计算公式:

Pr表示边界框包含目标的可能性;IOU表示边界框的准确度,即预测框跟实际框的并集;Pr(classi|object)表示这个单元格负责预测的目标属于各个类别的概率,即各个边界框置信度下的条件概率。每个单元格需要预测B×5+C个值,B表示边界框的数量,C表示类别数。
2.2 神经网络的结构
YOLO从诞生以来,不断更新完善,网络结构也越来越复杂。YOLOv1由24个卷基层和2个全连接层组成,卷基层负责获取特征,全连接层负责预测,卷积层和全连接层采Leaky-ReLU激活函数[11]。
YOLOv2采用高分辨率分类器,并且在每个卷积层后面添加了Batch Normalization层,Batch Normalization可以提高模型的收敛速度。YOLOv1是用全连接层直接对边界框进行预测,根据边界框预测的4个offsets tx,ty,tw,th,用下面的公式计算边界框的实际位置和大小:

其中(cx,cy)为cell左上角坐标,pw和ph是先验框的宽度和长度。
边界框相对整张图片的位置和大小:
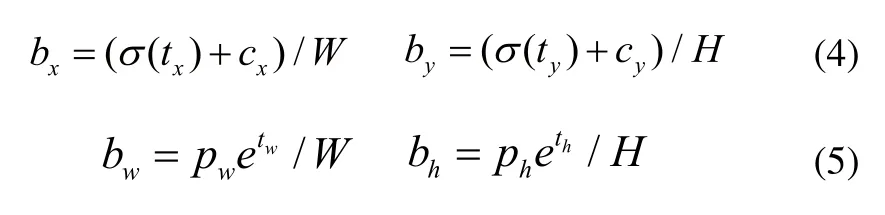
其中(W,H)是特征图的大小。
YOLOv2采用卷积层和anchor boxes来代替原来全连接层进行预测。YOLOv2的特征提取器,采用一种新的模型,由19个卷基层和5个maxpooling层构成。YOLOv2的输入图片大小要求为416×416,经过5个maxpooling层后,大小变为13×13的特征图。
YOLOv3采用残差网络和FPN架构,它的特征提取器是一个残差模型,包含了53个卷积层,网络构建更深,可以多尺度预测[12]。此外,基础分类网络和分类器也得到升级,Softmax不适用多标签分类,所以使用多个独立的Logistic分类器替代Softmax。
YOLOv3的网络结构如图1所示。

图1 OLOv3网络结构图
场景文字的检出,文字背景对检出干扰很大。相对来说YOLOv3的检测速度更快,可以进行实时检测,而且背景误检率低,所以采用最新的YOLOv3模型。
3 实验过程
3.1 样本采集
本文使用自己制作的数据集,训练样本10000张,测试样本200张。训练数据包含图片和标签两个部分,标签部分使用标注工具YOLO-mark来制作,标签以文本文件形式保存。样本图片的场景包括运动员的号码牌、车牌、超市物价牌和广告牌等,各类场景样本数量大致相同。此外,YOLO自带图像增强功能,实际上训练时会基于角度、饱和度、曝光和色调产生更多的训练样本。
3.2 样本训练
本文的训练是在Ubuntu16.04系统下进行,在该系统下配置了基于YOLO的开源神经网络框架-Darknet,用来训练和测试,训练过程的部分参数如表1所示。Region Avg IOU代表预测的矩形框和真实目标的交集与并集之比,IOU值越高说明预测框位置越准确;Class表示标注目标分类的准确率;Obj指标的值期望越接近1越好;No Obj指标的值期望越接近0越好,但不为0。随着迭代次数的增加,各项指标均有改善,在迭代了大约15000次后,各项指标趋于稳定,模型训练时长约为70小时。
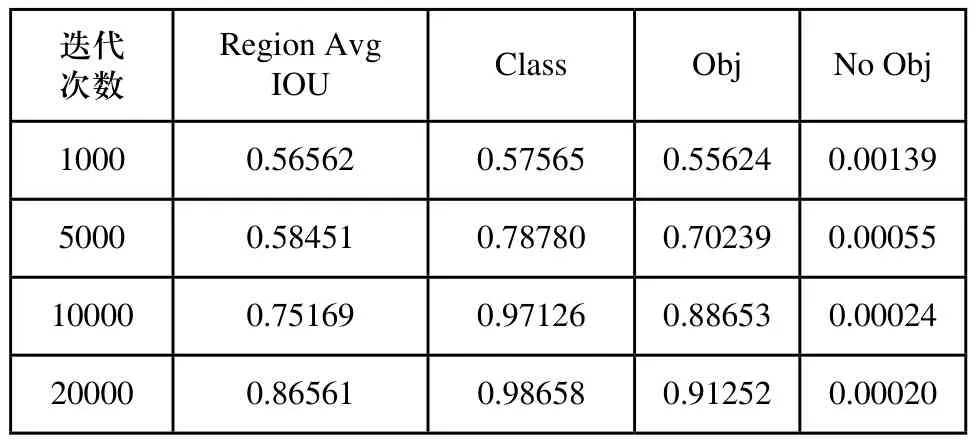
表1 训练过程部分参数
3.3 样本测试
利用迭代20000次后生成的模型,分别选取不同场景下的图片进行进行测试,部分测试结果如图2所示。

图2 部分测试结果图
图2中图片的的具体检测结果如表2所示。

表2 测试结果
测试结果表明YOLO算法可以实现场景中的数字检出任务。检测速度较快,平均在0.07秒左右即可完成一张图片的检出。准确率较高,几乎达到百分百检出,但当图像中的数字较小,很模糊的情况下,会出现漏检或者误检的情况,漏检的概率高于误检概率。针对这个问题,可以通过增加训练样本量加以改善。
4 结束语
针对传统方法在场景数字检测上,弊端较多。其中图像预处理在传统方法中工作量占比很大,本文采用深度学习方法进行场景数字检测,避免了图像预处理的工作,直接检测给定图像,减少了工程的工作量。采用深度学习方法进行场景数字检出,将定位文本与识别并作一步,实现了端对端的检测。实验结果表明该方法检测速度快,准确率高,具有较高的应用价值。该实验采用的YOLOv3的神经网络结构,但是其神经网络结构对于数字检出来说过于复杂,下一阶段研究要在YOLOv3的神经网络结构基础上进行改进,精简其结构,搭建出一种更适合场景数字检出的神经网络结构,进一步提升检测速度和准确率。
猜你喜欢
现代电力(2022年2期)2022-05-23
故事作文·高年级(2022年2期)2022-02-24
儿童时代·幸福宝宝(2021年11期)2021-12-21
北京航空航天大学学报(2021年9期)2021-11-02
小学科学(学生版)(2021年4期)2021-07-23
现代装饰(2020年4期)2020-05-20
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
