
数据挖掘在考古遗址功能研究中的应用
——以乌兰木伦遗址第一地点微痕研究为例
2019-03-26 06:52:32黄永梁
浙江大学学报(人文社会科学版)预印本 2019年11期
陈 虹 黄永梁
(浙江大学 艺术与考古学院, 浙江 杭州 310028)
一、 引 言
考古遗址是指人工制品、遗迹、建筑和生境遗存共存的场所,是考古学极其重要的研究对象。遗址功能研究通过遗址中的各种文化遗存来识别人类的某些活动迹象,从而探明人类的生活方式。遗址结构分析是一种遗址功能研究方法,即研究遗址中遗迹、器物与动物遗存的空间分布,通过研究这些遗存的关系来分析遗址居民的行为方式、群体规模与构成,更为综合地对遗址的性质和功能做出判断[1]。从考古学的角度出发,最理想的情况是根据遗迹特征来确定遗址的框架结构,继而研究这个框架结构与物品分布之间的关系。但是在许多情况下,考古遗址的埋藏情况和发掘过程对这个方法的应用有一定限制。
旧石器时代遗址功能的研究主要依托出土的文化遗物,从不同的角度进行研究。常用的研究方法有“操作链”分析、石制品剥片序列分析、石制品组合分析、石制品拼合研究、微痕分析、残留物分析、共生关系分析等。此外,民族考古学也为遗址功能研究提供了一定的资料。其中,石制品的功能与遗址功能有着相当紧密的联系,因此研究石制品功能与其空间分布之间的关系成为遗址结构分析的重要内容。与其他研究方法相比,微痕分析在石制品功能分析方面更具可靠性和有效性。将微痕分析与遗址结构分析结合起来,更有利于推测整个遗址的性质和功能。
在以往研究中,基于一定的假设,对石制品的测量数据与微痕观察的功能数据进行定性或定量的相关性分析,可能会忽略数据间潜在的联系。另外,由于微痕分析专业性强、耗时长等,很难获得一个遗址或地点较为全面的石器微痕观察数据。而数据挖掘作为一种数据分析手段,可以有效地分析大量数据间潜在的关联性,并可对各组数据关联性的支持度和置信度的量化形式进行对比。因此,对石制品的微痕观察数据与测量数据进行数据挖掘,在一定程度上可以更好地还原遗址结构以研究遗址功能。
内蒙古乌兰木伦旧石器时代遗址第一地点石制品已有的微痕观察数据数量庞大,是罕见的全地层优质样本。本研究以此为依托,基于2012—2017年对该地点全地层石制品的微痕观察数据和测量数据,利用数据挖掘这一分析手段分析遗址结构,并结合该地点的相关考古学背景进行遗址功能研究。
二、 遗址概况与研究对象
乌兰木伦遗址位于内蒙古自治区鄂尔多斯市康巴什新区乌兰木伦景观河北岸,是鄂尔多斯高原继20世纪20年代发现萨拉乌苏和水洞沟遗址后新发现的一处重要旧石器遗址。自2010年以来,中国科学院古脊椎动物与古人类研究所、鄂尔多斯青铜器博物馆、鄂尔多斯文物考古研究院联合对该遗址进行了连续数次发掘,研究成果颇丰。乌兰木伦遗址是一处由多个地点构成的地点群,目前确认三个重要地点,第一地点是石制品微痕研究的重点。其中,2010—2011年的发掘共出土5 200 余件人工打制的石器,3 400余件古动物化石,发现多处用火遗迹和两处动物脚印遗迹[2]。现有的测年结果表明,乌兰木伦遗址的年代为距今6.5万—5万年[3],属于旧石器时代中期,地层属于晚更新世中期[4]。
基于对乌兰木伦部分石制品工具的类型和技术分析,有学者认为该遗址的石器整体上表现出古人类在狩猎和屠宰方面的需求,这在一定程度上也反映出遗址的部分功能[5]。石制品拼合分析[6]、埋藏学、动物考古学(1)张立民《内蒙古乌兰木伦遗址埋藏学的初步研究》,中国科学院大学古脊椎动物与古人类研究所2013年硕士学位论文。和环境考古学[7]等方面的研究表明,遗址出土的石制品为原地埋藏且没有受到后期扰动,较好地保存了古人类活动最原始的信息。同时,所有经过发掘的石制品都有详细、精准的出土空间坐标记录[8],为进行遗址功能和结构分析提供了可能。
在乌兰木伦遗址第一地点2010年的发掘中,出土遗物包括2 198件石制品和2 179件动物化石,本课题组对其中398件石制品进行了微痕观察,并对227件石制品予以详细描述[9]。2011年对乌兰木伦遗址第一地点的第二次发掘显示,地层明确的石制品有3 039件,其中93件石制品经过微痕观察,58件石制品有详细记录(2)陈虹、汪俊、连蕙茹等《乌兰木伦石制品微痕研究的新进展(2013年度)》,见鄂尔多斯市文物考古研究院编《鄂尔多斯文化遗产(2013)》,第97-103页。。这些微痕分析数据一方面经过了前期的模拟实验[10-11],结论可靠性有一定的保证;另一方面经过前后五年的工作,数据完整,记录翔实,基本可以建立起一个全地层的石器微痕观察数据库,在国内外均不多见。
本研究仅限于发掘出土且地层明确的石制品。在剔除采集品和地层信息不明的石制品之后,研究的总样本量为254件石制品,包括2010年出土的197件石制品和2011年出土的57件石制品。
在具体分析中,除了将石制品个体作为分析的基本单位外,还将石制品所包含的功能单位作为分析的基本单位。功能单位用于记录石制品上使用部位的数量,在进行微痕定量分析或石制品功能分析时比标本个体更为具体和实用,能够反映的信息也更为详细,有利于更为系统地统计分析石制品的运动方式、加工材料及其涉及的人类行为[12]。从本次分析的样本来看,功能单位明显多于标本个数,说明一些石制品存在一器多用或重复使用的现象。经过统计,254件石制品共包含298个功能单位,其中40件石制品各存在2个功能单位,2件石制品各存在3个功能单位。
每一件石制品所具备的属性数据包括两方面:测量数据和微痕观察数据。测量数据包括长度、宽度、长宽比、厚度、重量、原料、类型、出土地层和三维坐标数据;微痕观察数据包括运动方式、加工材料和行为。“行为”这一变量为本研究中的自定义变量,指运动方式与加工材料的简单组合。本研究涉及的行为组合有23类,包括:剥皮、穿刺、锤击、割肉、刮干骨、刮干皮、刮鲜骨、刮鲜木、刮鲜皮、锯鲜木、砍砸鲜骨、刻划鲜骨、刻划鲜皮、捆绑、片肉、切筋、切锯鲜骨、切肉、切软骨、切鲜皮、剔肉、钻鲜骨,以及情况不明者。需要说明的是,为了确保分析结果的精确性,如果一件标本(功能单位)的运动方式或加工材料有一项被判断为不明,该行为就计为不明。
此外,一些学者在对功能单位的定义中将执握痕迹(3)执握痕迹是指因手握工具而在相关部位产生的微观痕迹。也作为单一功能单位的判断标准[13],本研究则不将执握作为一种特殊的人类行为,因此不对254件石制品涉及的执握痕迹进行计次。
三、 研究方法与流程
数据挖掘,也称数据库中的知识发现,是指从大型数据库或数据仓库中提取人们感兴趣的知识,这些知识是隐含的、事先未知的、潜在有用的信息[14]。在考古领域,数据挖掘目前主要是与GIS系统结合使用,以及用于聚落考古学研究。毕硕本等利用Apriori算法,对姜寨一期的房屋遗迹、土坑墓、窖穴以及灶坑的属性信息进行关联规则挖掘,发现这些属性数据之间存在关联规则,例如灶壁为红烧土硬面的灶坑略少于青灰色硬面的灶坑[15]。他们还利用K-means聚类算法,对姜寨一期聚落中的居住区和墓葬区进行了聚类分析,聚类结果显示,大房屋组可分为东、南、西、北、西北五组[16]。孙懿青等运用属性泛化算法,对姜寨一期房屋进行了分房屋组与分时代的数据挖掘,并且用可视化形式进行展示以说明房屋的演变情况[17]。陈济民利用GIS组件(SuperMap Objects),对郑洛地区四个连续文化时期的聚落空间进行了数据挖掘,开发了基于连续文化序列的空间数据挖掘系统,提取了空间分类规则与空间聚类规则,并在此基础上进行对比分析,得出了郑洛地区史前聚落的空间分布规律和初步的时空演变规律(4)陈济民《基于连续文化序列的史前聚落演变中的空间数据挖掘研究——以郑洛地区为例》,南京师范大学地理科学学院2006年硕士学位论文。。
目前国内的旧石器考古学从石制品微痕观察数据和发掘数据入手进行数据挖掘尚无先例。本研究涉及的数据挖掘技术包括关联规则挖掘和聚类分析。关联规则的概念由Agrawal等人提出,是数据挖掘中一种简单但很实用的规则,它能表示数据之间的相互关系,对统计和决策工作有重大意义[18]。关联规则挖掘的算法多样,大部分基于Apriori算法,本研究即采用这一基本算法,对石制品的微痕观察数据(包括运动方式、加工材料、行为)和测量数据(包括长度、宽度、长宽比、厚度、重量)的关联规则进行发掘,并利用支持度与置信度来衡量数据间相关性的强弱以及可信度(5)高伟峰《数据挖掘中关联规则的研究及应用》,武汉理工大学计算机科学与技术学院2006年硕士学位论文。。
聚类分析是按数据自身距离或相似度将数据分成一系列相互区分的组,它与归纳法的不同之处在于不需要背景知识而直接发现一些有意义的结构与模式。因此,聚类分析与分类不同,它是在没有给定划分类别的情况下,根据数据相似度进行样本分组的一种方法。聚类时输入的是一组未被标记的样本,聚类是根据数据自身的距离或相似度将数据划分为若干组,划分的原则是组内距离最小化而组间(外部)聚类最大化[14]。
本研究所做的聚类分析是利用石制品的出土三维坐标进行分析,属于一种空间聚类分析。空间聚类分析方法可采用拓扑结构分析、空间缓冲区及距离分析、叠置分析等方法,旨在发现目标在空间上的相连、相邻和共生等关联关系。本研究采用K-means聚类算法,主要目的是基于石制品的空间数据(出土三维坐标)对其进行分组,也就是利用石制品功能的空间分区来探索该地点的遗址结构。同时,在遗址中难免有不满足分区结果的孤立点存在,孤立点有时被处理为数据“噪声”,但对孤立点的研究和解释有助于推进遗址功能分析。
本研究的原始数据多为描述性语言,类型多样,包括非文本数据和文本数据,也存在部分数据缺失和错误的情况。因此,为了保证结果的正确性,在实施关联规则挖掘与聚类分析信息之前,对数据进行了相应的预处理,包括数据清洗、数据集成和数据变换等(6)数据清洗主要是删除原始数据集中的无关数据、重复数据、平滑噪声数据,筛选掉与挖掘主题无关的数据,处理缺失值、异常值等。数据集成是将来自不同数据源的数据合并存放在一个一致的数据仓库中的过程。数据变换主要是对数据进行规范化处理,将数据转换为适当的形式,以适应挖掘任务与算法的需要,一般包括简单函数变换、数据规范化、连续属性离散化、属性构造和小波变换。步骤。
四、 关联规则挖掘
本文关联规则挖掘以Python为平台,采用Apriori算法,分析总样本为298个功能单位,涉及的属性数据包括长度、宽度、长宽比、厚度、重量这5类测量数据和运动方式、加工材料、行为这3类微痕观察数据,总计15组、912条关联规则,其中强关联规则(7)对相关属性数据进行关联规则挖掘之后得到的每条关联规则都有一个支持度和置信度。强关联规则可以指示基于统计得出的“最佳范围”。有38条。
例如,运动方式、加工材料、行为与长度共产生199条关联规则。其中,运动方式与长度的强关联规则说明,运动方式为切和刮的石制品的长度分别集中在28—53.8 mm和21.6—42.7 mm(表1)。

表1 运动方式与长度强关联规则
加工材料与长度的强关联规则说明,加工材料为肉和鲜骨的石制品的长度分别集中在21.6—53.8 mm和21.6—34.7 mm(表2)。

表2 加工材料与长度强关联规则
行为与长度的强关联规则说明,行为为切肉和剔肉的石制品长度分别集中在28.3—42.7 mm和21.6—34.3 mm(表3)。
类似的,宽度、长宽比、厚度、重量分别与运动方式、加工材料、行为也产生了一系列强关联规则。这些强关联规则可以指示对于某类具体的加工材料、运动方式和行为,石制品在长度、宽度、长宽比、厚度和重量等方面具有共同特征。虽然用以分析计算的属性数据是石制品被使用之后残余的数据,但从石制品的微痕模拟实验来看,石制品在被使用的过程中,其长度、宽度、长宽比、厚度、重量并不会发生较大的变化,因此,这个计算得出的数据范围是具有参考意义的。

表3 行为与长度强关联规则
综合这些测量数据和微痕观察数据的强关联规则,可以发现从长度、宽度、长宽比、厚度和重量来看,不同运动方式、加工材料、行为所对应的石制品差异不大,规格比较统一,而其中涉及的石制品类型多样。
五、 聚类分析
聚类分析以Python为平台,所采用的聚类算法为K-means聚类算法。K-means聚类算法是基于欧式距离(8)欧氏距离,即欧几里得度量,是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。实现的,因此本文聚类分析所利用的就是石制品(功能单位)的出土三维坐标(xyz坐标数据)。
进行聚类分析的目的是实现对石制品功能的分区,探索石制品(功能单位)在该地点中是否存在以及存在于几个聚集中心,而石制品功能能够反映出古人类的某些行为,因此对石制品的功能单位进行聚类分析,可以在一定程度上还原其遗址结构,有利于对遗址功能的进一步研究。
为了保证聚类结果的有效性,必须选择代表性强和数据完整性高的样本。在本研究的总样本中,2010年发掘的样本在数量和比例上较高,因此,聚类分析的样本是具有完整坐标的2010年出土的石制品,所分析的具体对象为这部分石制品所有的功能单位,总计204个功能单位。一次聚类不一定能够得到具有意义的聚类结果,因此分别设定3、4、5、6、7个聚类中心,对石制品的空间数据进行聚类,再分别评估聚类结果的有效性。
经过五次聚类计算之后发现,当设定聚类中心为4个时,各类的类内相似性最大,类间差异性最大。聚类结果显示的石制品分布以及4个聚类中心坐标分别如图1和表4所示。“Cluster”代表簇,一个簇对应一个石制品聚集区域,xyz坐标单位均为cm,其中z轴坐标表示距离地面的距离。
对4个区域的功能单位中最主要的加工材料、运动方式和行为分别进行统计,结果显示:从加工材料来看,动物性材料主要集中在0区和2区,比如肉、鲜骨和鲜皮(图2)。从运动方式来看,切、刮、剔、捆绑、锯、钻、穿刺这些运动方式主要集中在0区和2区(图3)。
从行为来看,与动物屠宰食用相关的全系列处理流程都集中在0区和2区,包括剥皮、切肉、剔肉、片肉、割肉、刮鲜骨、切软骨、切鲜骨、砍砸鲜骨、刻划鲜骨、切锯鲜骨、钻鲜骨、刮鲜皮、切鲜皮、切筋,并且捆绑的行为也只出现在0区和2区(图4)。此外,0区和2区也出现了处理植物性材料的现象,包括刮鲜木和锯鲜木。

图1 聚类结果示意图

clusterxyz043855827018734136221965932703550356445

图2 加工材料区域分布柱形图
受限于样本数量,从运动方式、加工材料和行为三个属性数据来看,对0区和2区这两个数据最为集中的区域难以进行更为细致的区分。从0区和2区的聚类中心位置来看,两者近似位于同一平面,而这两个区中的功能单位都分别在空间上靠近这两个聚类中心,因此可以认为两个区中的功能单位都在空间上靠近z轴方向上坐标为270的平面。从z轴方向俯视这些功能单位的分布情况,可以看到0区和2区只是在水平分布上分别靠近遗址的两个边界(图5)。这说明在该地点中,能够指示古人类某种行为的石制品集中在距离地面270 cm的平面四周,对应地层大致为4层与5层的分界线,这也是该地点遗址结构的分析结果。
该地点的动物埋藏学显示,在所有保留切割痕的化石中,存在切割痕的披毛犀骨骼化石主要集中在4—5层,占到总数的75%,说明古人类的食肉行为可能主要集中在4—5层(9)张立民《内蒙古乌兰木伦遗址埋藏学的初步研究》,中国科学院大学古脊椎动物与古人类研究所2013年硕士学位论文。,这在某种程度上与石制品空间聚类结果大致是吻合的,也从另一个方面验证了聚类结果的有效性。

图3 运动方式区域分布柱形图
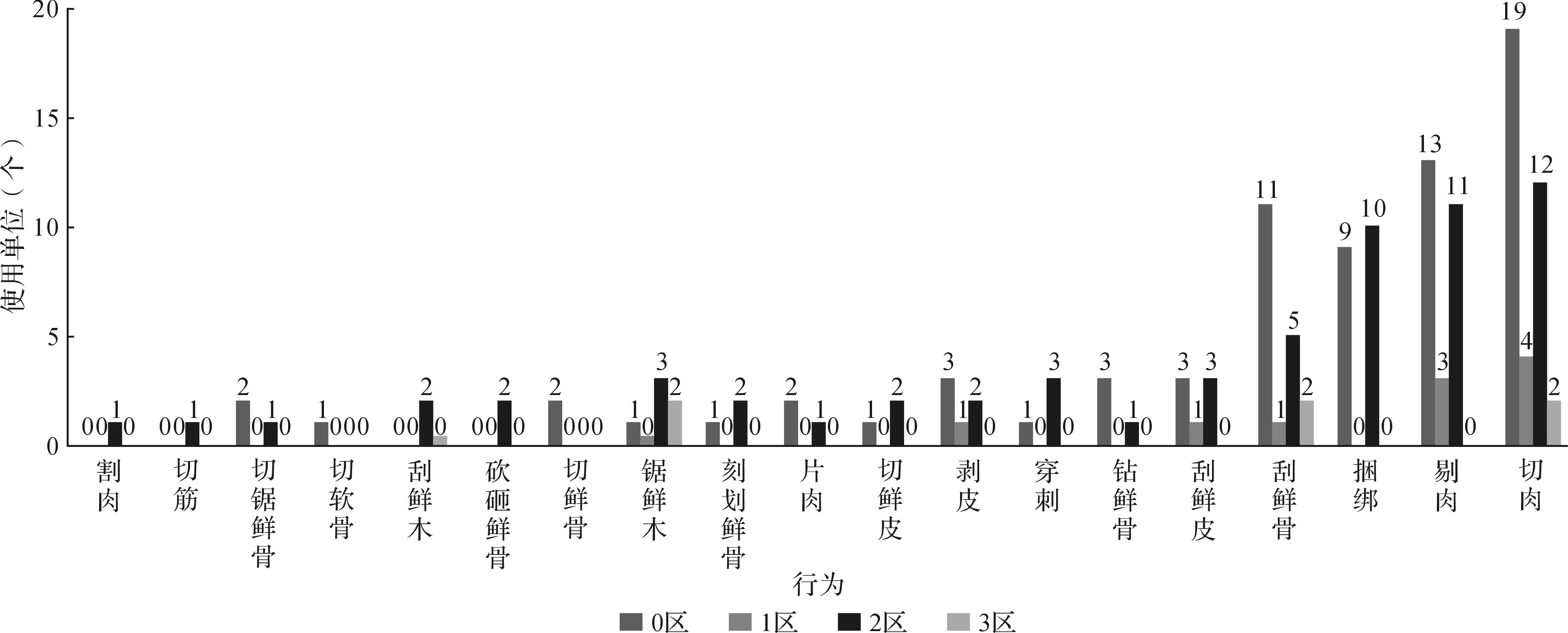
图4 行为区域分布柱形图

图5 聚类结构z轴方向俯视图
利用包含物(本研究中是石制品)的出土坐标进行聚类分析,能够直观地观察到整个空间中包含物的分布情况,在一个有效聚类中,结果中的一个区所对应的时间范围实际上能够反映一个生活面的使用时间范围。本研究最后的结果显示,所有具有行为指示性的石制品都以距离地面270 cm的平面为聚集平面,这个平面上下的一定范围很可能对应着一个比较真实的生活面,而这个生活面也是古人类进行动物屠宰行为最多的一个时期。而从动物埋藏学出发所判断的古人类食肉行为集中在4—5层,这个范围可能偏大也可能偏小。
六、 结 论
通过对乌兰木伦遗址第一地点出土的254件石制品的298个使用单位进行初步统计、关联规则挖掘和聚类分析,能够得到以下结论:
1.从石制品功能数据的结果来看,涉及动物屠宰加工的石制品比例较高(超过80%),说明乌兰木伦遗址第一地点确实存在一个动物屠宰加工场所。
2.石制品的长度、宽度、长宽比、厚度、重量和运动方式、加工材料、行为之间具有38条强关联规则,表明用于特定行为的石制品在长度、宽度、长宽比、厚度和重量上存在一系列共同特征。同时,主要运动方式、加工材料、行为所对应的石制品规格比较相近。
3.利用K-means算法对石制品功能单位的空间坐标进行聚类分析得到的遗址结构显示,在乌兰木伦遗址第一地点存在一个古人类进行动物屠宰加工非常集中的时期,这个时期在遗址中对应距离地面270 cm上下的空间范围。如果可以获得相关的动物骨骼化石和邻近地层中用火遗迹的空间分布数据,就能够对这个空间范围做出更细致的划分,得到更加明确的遗址结构。
本研究是数据挖掘分析方法在遗址功能研究中的初步尝试,研究结果显示出这一数据分析方法在考古学研究中的潜力。作为一种定量分析方法,数据挖掘能够准确、有效、客观地处理考古遗址中数量庞大的数据。数据挖掘能够应用于考古学研究的多个领域,并为考古发掘提供重要的指导。在考古发掘阶段,根据研究目的对相关数据进行完整而准确的记录,是数据挖掘的前提,有助于更好地提升考古学研究的准确性和科学性。
猜你喜欢
小猕猴智力画刊(2023年10期)2023-10-31 08:23:00
儿童时代·快乐苗苗(2023年5期)2023-06-27 06:44:32
人类学学报(2023年5期)2023-04-29 19:50:21
英语世界(2022年9期)2022-10-18 01:10:48
大众投资指南(2021年35期)2021-02-16 01:06:26
东方考古(2020年0期)2020-11-06 05:34:02
文物春秋(2017年2期)2017-05-31 22:26:56
电力与能源(2017年6期)2017-05-14 06:19:37
文物鉴定与鉴赏(2017年1期)2017-05-06 01:13:46
信息通信技术(2015年6期)2015-12-26 01:16:46
