
基于GRU-HMM声学模型的湖南方言辨识∗
2019-03-26 08:43谢可欣钱盛友
计算机与数字工程 2019年3期
谢可欣 董 胡,2 邹 孝 汤 琛 钱盛友
(1.湖南师范大学物理与电子科学学院 长沙 410081)(2.长沙师范学院信息科学与工程学院 长沙 410100)
1 引言
20世纪90年代,方言辨识开始逐渐被越来越多的人们重视,各国的研究人员对不同种类方言的特征和分类模型进行了大量研究,同时方言辨识在刑事案件中犯罪嫌疑人的归属地判定方面有重大贡献。中国是一个多民族的人口大国,各民族各地区的语言都有差异,因此对于方言辨识的研究是必不可少的,该领域的研究对语音识别技术的推广应用具有重要意义[1~2]。传统的声学建模方法是以HMM模型为基础框架,并采用混合高斯模型(GMM)来描述语音声学特征的概率分布。早年较为常用的声学模型主要有隐马尔科夫模型(HMM)和人工神经网络(ANN),像BP神经网络和RBF神经网络等,并且至今都在沿用以及不断优化中。而近年来,由于深度学习的广泛应用,使得深度学习在语音识别领域中取得了不错的成就,对多层神经网络采用深度学习算法,可以得到更好的初始化权值,使得网络在最佳的极值点处能够更快完成收敛,从而改善了传统神经网络的不足。本文通过对湖南长沙、株洲、衡阳、湘潭四地方言进行研究,以Matlab为实验平台,提出了一种基于GRU神经网络和HMM结合的声学模型。
2 基本理论
2.1 门控循环单元GRU
语音信号是一种非平稳时序信号,而循环神经网络(RNN)是一种网络节点带环状回路的模型,具有一定的动态记忆能力。2013年,Alex Graves等[3]最早将RNN用于语音识别的声学建模,并取得了很好的识别性能,但由于简单的RNN随着神经网络层数的增加,梯度会逐渐趋于0,即梯度消失。2014年,Cho等[4]提出了RNN的一个变种——门循环单元(GRU),通过增加的门结构,不仅解决了梯度消失的问题,同时在各应用领域中的能力也不断体现出来。
GRU的每个单元能够自适应地捕获不同时间尺度的依赖关系[5]。与简单的RNN不同的是,GRU具有调制单元内信息流的门控单元,但没有单独的存储单元。GRU结构中包含了一系列被称为记忆单元的循环连接的子网络,每个记忆单元包含了一个或多个自连接的记忆细胞和门控单元,即能够通过门控机制来抵消梯度消失。在数学上,GRU神经元可以由以下关于时间t=1,2,…,T的递推式描述[6~7]:表示当前隐藏节点的候选值,ht表示当前时刻的隐藏状态,ht-1表示上一时刻的隐藏状态,xt为t时刻的输入,⊙表示两个向量之间的内积,即按位相乘,W和U表式连接不同门的权重矩阵,σ表示Sigmoid函数。其结构图如图1所示。
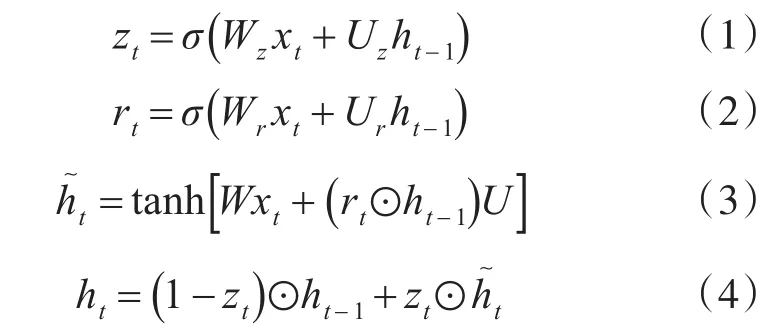
更新门:用来决定当前时刻的输入状态xt有多少要保存到状态单元中。
重置门:用来控制上一时刻隐藏状态ht-1对当前输入xt的影响,重置信号会判定对结果的重要程度。
隐藏状态:根据当前输入xt和重置后的ht-1可以得到候选的隐藏状态。
其中,zt和rt分别代表t时刻的更新门和重置门,
当前状态:最后由更新门zt决定有多少信息需要更新,混合上一时刻的隐藏状态ht-1和候选的隐藏状态得到当前时刻的ht。
GRU之所以对语音信号有很好的识别性能,是因为门控网络信号能够控制当前输入方式,与此同时之前的内存也被用来更新当前的激活状态与显示状态。这些门具有自己的权重集,其在学习阶段(即训练和评估过程)中被自适应地更新。同时,每个参数更新都将涉及与整个网络状态有关的信息。
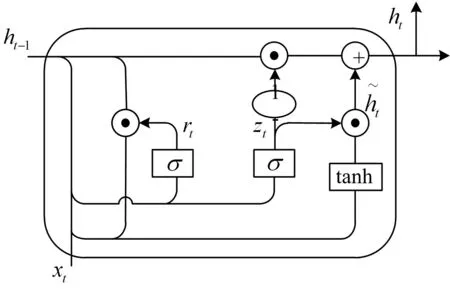
图1GRU结构图
2.2 MFCC参数
特征提取主要是通过对语音信号的处理分析,去除对识别无用的冗余信息,得到表征语音信息的关键参数。提取MFCC特征的总体过程如下[8]:
1)对语音进行预处理,即预加重、分帧和加窗函数;
2)对每一帧信号进行FFT变换,得到频域数据,进而求得功率谱;
3)将求出的功率谱通过Mel滤波器,得到Mel频谱;
4)对Mel频谱进行倒谱运算,获得MFCC。其计算公式为

其中,L为滤波器个数。流程图如图2所示。

图2 MFCC特征参数提取流程图
3 模型训练
声学模型在方言辨识系统中处于最为核心的部分,它是用来描述声学基元产生特征序列的过程[9]。本文通过GRU网络的训练先得到样本特征属于哪一种类别的概率,将得到的概率作为HMM模型的输入再次进行训练,进行一系列的统计迭代不断进行优化,最后进行解码得到最后的辨识概率。
3.1 GRU模型
GRU模型可以模拟任意函数,能够处理多帧输入,相当于引入了非线性的能力[10],GRU作为判别模型可以直接生成状态的概率输出。其训练过程的主要步骤为
1)将训练集数据输入到GRU的输入层,经过隐藏层,最后达到输出层并计算出zt、rt、ht的值;
2)由于GRU的输出结果与估计结果有误差,将该误差从输出层向输入层进行反向传播;
3)在反向传播的过程中使用链式求导法,根据误差对各个参数的值进行调整;
4)根据相应的误差项,计算每个权重的梯度,同时进行不断的参数调优来更新权重值。
在训练GRU网络的过程中,通过随机梯度下降算法来更新权重值,选取的代价函数为交叉熵代价函数[11~12],其公式为

其中,x表示样本,y表示实际值,a表示输出值,n表示样本的总数。
随机梯度下降算法对应的更新公式为
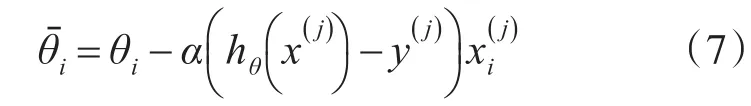
3.2 HMM模型
HMM模型作为一个统计模型,能够简单易行地从有限语音训练集数据中训练出模型近似参数,可以灵活地根据特殊的词汇、声音等改变认知系统的大小、种类或模型的架构,从而方便快捷地实现整个认知系统。
HMM是一个五元组[13]λ={ }N,M,π,A,B ,其中N表示隐藏状态的数量,M表示可观测状态的数量,表示每组样本的n个特征值,为初始隐藏状态的概率,为隐藏状态的转移矩阵,是混淆矩阵,即隐最大[14]。
给定模型参数λ,定义t时刻的隐藏状态为qi,t时刻部分观测序列为的前向概率为藏状态和观测状态之间关系的概率。对于已给定观测序列O,通过前向-后向算法来得到一组尽可能最优的HMM参数λ使观测序列出现的概率
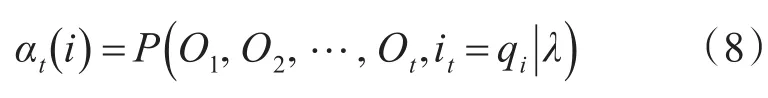
t时刻部分观测序列为 Ot+1,Ot+2,…,OT的后向概率为
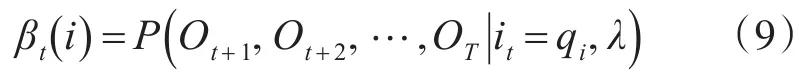
给定模型参数λ和观测序列O,在时刻t处于状态 qi的概率值[15]:
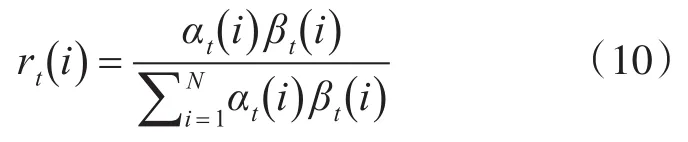
给定模型参数λ和观测序列O,在时刻t处于状态qi且在时刻t+1处于状态qj的概率:
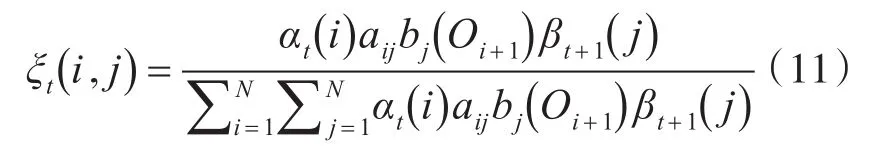
分别求出的是前向后向算法里面描述的两个变量值。根据以上两个变量,可以得到新的模型参数λ,又称为重估公式:
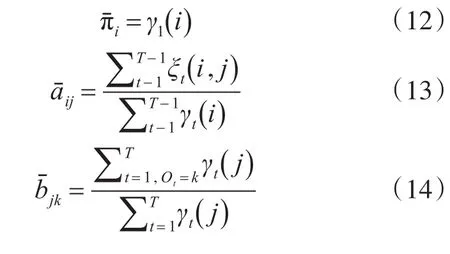
3.3 GRU-HMM模型
GRU-HMM声学模型在建模处理上,由于用GRU代替了GMM来进行建模,因此,比GMM有更加出色的对多帧数据的处理能力,并且属于深层次结构建模,拥有不错的记忆功能,能处理更多更长的数据。如图3所示为GRU-HMM声学模型的结构图。

图3GRU-HMM声学模型结构图
模型参数设置为:隐藏层的激活函数为Sigmoid函数和tanh函数,输出层的分类函Sigmoid函数,参数调优是选择交叉熵作为代价函数,用随机梯度下降算法来更新权重值。其训练步骤如下:
1)按2∶1的比例随机划分训练集和测试集;
2)训练GRU模型,得到GRU模型预测的概率prob,GRU模型的准确率acc;
3)将得到的概率prob作为HMM模型的输入,训练HMM模型;
4)对HMM模型进行解码,求解出隐藏状态的时序路径;
5)对隐藏状态进行决策树的训练,并且测试,然后统计测试的正确率。
4 实验结果与分析
方言辨识实验的语音数据来自出生于湖南长沙、株洲、衡阳、湘潭各地人的发音,每人对表1中的40个单字用当地方言进行发音,每人每字发音3遍,共取得样本480个。对语音数据加汉明窗,窗长为 32 ms,帧移16 ms。按1:2的比例,随机取若干个样本的MFCC特征参数作为测试数据,构成测试集,剩下样本的MFCC特征参数作为训练数据,构成训练集。

表1 实验所用单字表
采用Matlab仿真,对实验中的单字方言分别加入了信噪比为0 dB、15 dB、30 dB的高斯白噪声,得到带噪语音数据,然后提取16阶MFCC特征参数,分别作为不同模型的输入,比较它们的辨识率。各个实验分别进行100次,取其平均值,结果如表2所示。传统的GMM-HMM声学模型的最高辨识率为80.18%,GRU-HMM的辨识效果明显优于高斯混合模型。随着信噪比的增加,各个模型的辨识率均逐渐增加,其中HMM模型的辨识率增加幅度较大,而GRU网络的辨识率比较平稳。在信噪比为零的情况下,GRU-HMM的辨识率仍旧比GMM-HMM辨识率高。并且可以看出,HMM在低信噪比情况下的辨识率都不高,而GRU神经网络对信号的处理有很好的抗干扰性,无论是否有噪音,都能较为准确的辨识并保持稳定。因为GRU神经网络对信号能够实时更新并记忆,对于多输入的信息有良好的分类性,从而训练出的声学模型能有较高的辨识率。

表2 不同方言用GMM-HMM声学模型和GRU-HMM声学模型进行辨识的效果比较
5 结语
本文提出了一种基于GRU-HMM声学模型的湖南方言辨识方法。通过与传统声学模型的对比,证明该方法在不同信噪比的噪声影响下,对湖南各地方言都有很不错的辨识性能。而传统的声学模型不但容易发生过拟合,对特征的学习能力也远远没有此声学模型的学习能力强。由于GRU能够对信息进行长期的学习并保存记忆,本文使用的方法比传统的声学模型具有更好的辨识效果,并且有良好的鲁棒性。
猜你喜欢
东方少年(2022年28期)2022-11-23
环球人物(2022年4期)2022-02-22
今日农业(2021年15期)2021-11-26
小资CHIC!ELEGANCE(2021年32期)2021-09-18
家庭影院技术(2020年5期)2020-08-24
家庭影院技术(2020年6期)2020-07-27
意林·全彩Color(2019年6期)2019-07-24
卷宗(2018年24期)2018-11-07
中学生数理化·中考版(2014年5期)2016-12-22
中学生数理化·中考版(2016年5期)2016-05-14
