
基于甲基化的年龄推断模型构建与效能评估
2019-03-22 07:52:56李姗飞彭付端王建宁仲建军赵慧王玲李永久刘凡李彩霞丰蕾
法医学杂志 2019年1期
李姗飞,彭付端,王建宁,仲建军,赵慧,王玲,李永久,刘凡,李彩霞,丰蕾
(1.山西医科大学法医学院,山西 太原 030001;2.公安部物证鉴定中心 现场物证溯源技术国家工程实验室 法医遗传学公安部重点实验室,北京 100038;3.中国科学院北京基因组研究所,北京 100101;4.临猗县公安局,山西 临猗 044100;5.德州市公安局,山东 德州 253012)
在法医学应用中,个体年龄推断一直是法医学研究的重点和难点。通过确定案件嫌疑人的年龄范围,可以缩小调查范围,为案件侦查提供重要的线索和证据[1-2]。当前推断个体年龄主要是通过检测骨骼、牙齿等骨性指征,运用法医人类学模型进行年龄推断[3-4]。在法医学鉴定案件中,法医人类学方法由于骨骼检材的缺失而受限。近年来的研究表明,生物分子标志物可用于年龄推断。已有研究人员针对线粒体DNA的损伤[5]、端粒缩短[6]、T细胞重排[7]以及蛋白质的改变,如天冬氨酸消旋[8]和晚期糖基化终末产物[9]与年龄的相关性进行研究,但是利用这些生物分子标志物进行年龄推断的准确性和实用性都相对较低,不适用于法医学检验[10]。在近期的法医学年龄推断研究过程中,发现血液DNA中的部分甲基化位点包含了丰富的年龄信息生物标志物。DNA甲基化是一种重要的表观遗传修饰[11-12],与衰老之间存在密切的相关性[13],DNA甲基化在机体生长、发育和衰老过程中存在着动态变化过程。基因芯片和下一代测序技术的出现,促进了全基因组范围的甲基化检测,基因组DNA甲基化总体水平随年龄增加而降低,部分位点的甲基化水平却随年龄增加而升高,并且发现特定位点的DNA甲基化与年龄呈现线性相关性,可据此构建年龄推断模型预测个体年龄[14-19]。本研究通过系统研究甲基化位点与年龄的相关性,建立基于DNA甲基化的中国北方汉族男性年龄推断算法模型。
1 材料与方法
1.1 样本
根据知情同意原则,采集河南、山东、北京共476份汉族男性(年龄15~75岁,根据采集人员提供的户口出生年月及采集日期确定样本年龄)无关个体的新鲜外周静脉血,其中国家人类遗传资源共享服务平台(YCZYPT[2017]01-3)176份、中国典型人群法医分子画像人群队列研究(2017JB025)150份、本课题组采集150份。尽量每个年龄样本都选取,并尽可能保持每个年龄段样本量大致相同,且样本在河南、山东、北京3个地区都有分布,保证模型的适用性。不同年龄段样本人数见表1。

表1 各年龄段样本人数 (N=476)
1.2 样本制备
为验证模型对血斑的适用性和重复性,随机选取15份山东血液样本,各取100 μL涂在FTA血样采集卡上制作成血斑样本,室温放置3个月后提取DNA。外周静脉血按照QIAampDNA Blood Midi试剂盒(100)(德国Qiagen公司)说明书提取血液DNA;血斑样本按照MagAttract M48 DNA Manual试剂盒(200)(1064605,德国Qiagen公司)说明书提取血斑DNA,使用NanoDrop 2000c分光光度计(美国Thermo Scientific公司)对DNA浓度进行定量。
1.3 候选位点选择与引物设计
结合现有文献和基于前期研究[1,18,20-29]筛选位点,从中选择21个与年龄高度相关的位点,每个位点所在的序列都从UCSC genome browser(https://genome.ucsc.edu/)中下载,选择距离目标胞嘧啶-磷酸-鸟嘌呤(cytosine-phosphate-guanine,CpG)位点上下游各约200 bp的长度,共401 bp长度DNA片段,并下载DNA片段,使用美国Agena公司的Agena Bioscience EpiDesigner(http://www.epidesigner.com/)在线软件进行引物设计,引物解链温度(melting temperature,Tm)约为60℃。
1.4 EpiTYPER检测DNA甲基化
取 1 μg全基因组 DNA,按照 EZ DNA MethylationTM试剂盒(美国Zymo Research公司)说明书进行重亚硫酸盐处理,转化条件:95℃ 30s,50℃ 15min;20个循环。20 μL水洗脱获得转化后的DNA。同时设置两个对照:完全甲基化的DNA和完全未甲基化的DNA(甲基化程度分别为100%和0%)。
PCR扩增体系5μL,包括1μL重亚硫酸盐转化后DNA,1.37μL不含RNA酶的水,0.5μL 10×PCR缓冲液,0.09 μL PCR酶,0.04 μL dNTP混合物,2.0 μL引物混合物包括上下游引物(1μmol/L)。热循环参数:95℃ 4min;94℃ 20s,56℃ 30s,72℃ 60s,45个循环;72℃ 3min。多余的核苷酸将在下步纯化反应中被除去,纯化体系为2μL,包括1.7μL不含RNA酶的水和0.3 μL 1.7 U/μL虾碱性磷酸酶(shrimp alkaline phosphatase,SAP)。然后,孵化 37℃ 20 min,85℃5 min。纯化后,用1.5%的琼脂糖凝胶跑胶,取3 μL SAP产物,上样缓冲液2 μL,120 V电压电泳30 min。下一步进行转录和T裂解,体系为不含RNA酶的水3.15 μL,5×T7 RNA和DNA聚合酶缓冲液0.89 μL,T裂解转录混合物0.24 μL,二硫苏糖醇(100 mmol/L)0.22μL,T7 RNA和DNA聚合酶0.44μL,核糖核酸酶A(10 mg/mL) 0.06 μL,纯化产物2 μL。37℃孵育3 h。最后每个样本中再加入43 μL不含RNA酶的水和6mg清洁树脂并且在混匀仪上旋转15min,以离心力10 000×g离心6 min,用MassARRAY系统(美国Agena Bioscience公司)进行检测。
对15份制作血斑的血液样本进行2次重复性验证时,分别进行2次重亚硫酸盐转化并进行后续的PCR扩增及质谱检测,以保证所有步骤都进行2次重复。
1.5 统计学分析
分析与计算使用R软件(R-3.4.2),对大批量样本检测结果通过K最近邻方法(K-nearest neighbor,K-NN)补缺(最近的10个位点)。对数据补缺用R软件中DMwR软件包中“impute”函数,为了评估数据补缺后,最终数据分析结果是否仍然可信,选择352份没有缺失值的样本,每次设置不同比例的缺失值,然后进行K-NN方法补缺验证试验,再用补缺失后的值与真实值进行相关性分析,用Pearson相关系数评估补缺的可靠性,模拟的结果与实际结果有很强的关联性,表明经过补缺之后数据结果可信,反复1000次,求平均值。在实验中随机将缺失阈值设为10%、20%、30%、40%和50%(表2)5个阶段,K-NN补缺方法推荐的临界阈值是20%[30],因此在本研究中也以20%定为最大缺失阈值进行数据补缺,进而获得可靠的DNA甲基化数据。用“cor”函数,选择与年龄相关的甲基化位点,将Pearson相关系数设为|r|>0.5,选出与年龄相关的80个甲基化位点。然后用赤池信息量准则(Akaike information criterion,AIC)结合多元线性回归方法,设置P<0.005,进一步筛选出与年龄高度相关的22个DNA甲基化位点。运用“lm”函数及“step”函数拟合多元线性回归方程并求出最优模型,最后利用“drop”函数并结合相关性有统计学意义(P<0.005)的指标,筛选出与年龄高度相关的8个CpG位点[位点信息通过Genome Browser Gateway获取(“Human Assembly”选为 GRCh38,https://genome.ucsc.edu/cgi-bin/hgGateway?redirect=manual&source=genome.ucsc.edu)],并得出与年龄相关的多元线性回归模型。将筛选出与年龄高度相关的8个CpG位点的甲基化值(x)代入到年龄预测回归模型中,得到相应的预测年龄,并利用“plot”函数画出预测年龄与实际年龄的散点图。运用留一法交叉验证方法评估模型,352份样本数据,每次留下一个样本作为验证样本,其余样本重新训练模型,这个步骤一直持续到每个样本都被当作一次验证样本,用留一法评估模型时运用“boot”软件包中“c”函数。将352份样本按实际年龄大小排列,每10岁分为一组,求每个样本的预测年龄,并进一步计算出每个年龄段人数的平均绝对偏差(mean absolute deviation,MAD)值。用109份样本对年龄推断模型进行验证,将CpG位点的甲基化值代入到年龄推断模型中,求出109份样本的MAD值,验证模型的准确性。本研究检测了15份血液DNA样本,及相对应室温存放3个月的血斑样本,通过SPSS 17.0,采用配对t检验比较15份血液样本与血斑样本在8个CpG位点甲基化结果的差异。将CpG位点的甲基化值代入到年龄预测模型中求出相应的预测年龄,年龄预测误差及15份样本的MAD值。进行重复性验证时,将2次重复性实验的8个CpG位点的甲基化值代入年龄预测方程求出2次重复性实验的预测年龄和MAD值。

表2 K-NN补缺方法的准确性评价
2 结 果
2.1 年龄相关性位点筛选
为了筛选出适合推断中国北方汉族男性年龄的DNA甲基化位点,本研究以EpiTYPER技术平台为基础,结合文献[1,18,20-29]中已报道的及前期工作积累的血液中与年龄相关的21个位点,检测了476份男性血液样本检测了21个扩增片段内的153个CpG位点。其中352份没有缺失值的样本作为训练集构建年龄推断模型,通过分析年龄与153个CpG位点DNA甲基化值之间的相关性,从153个候选位点中筛选出80个与中国北方汉族男性年龄相关的DNA甲基化位点,然后运用AIC进一步筛选CpG位点,结果筛选出22个与年龄相关的CpG位点。以P<0.005为条件最终筛选出8个与年龄高度相关的CpG位点,位于7个基因片段上(表3)。
2.2 中国北方汉族男性年龄推断模型
352份样本作为训练集,基于这8个CpG位点(x1~x8),建立了年龄(y)推断模型:
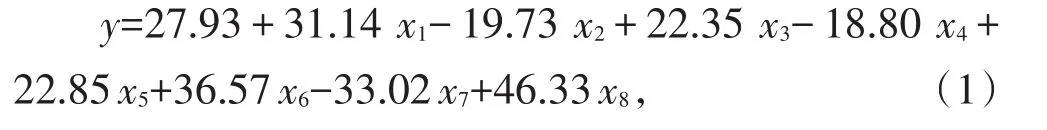
R2=0.93,MAD=2.69岁,其MAD的95%置信区间为[2.39,2.98],该年龄推断模型可以用于解释93%的年龄变化(图1)。
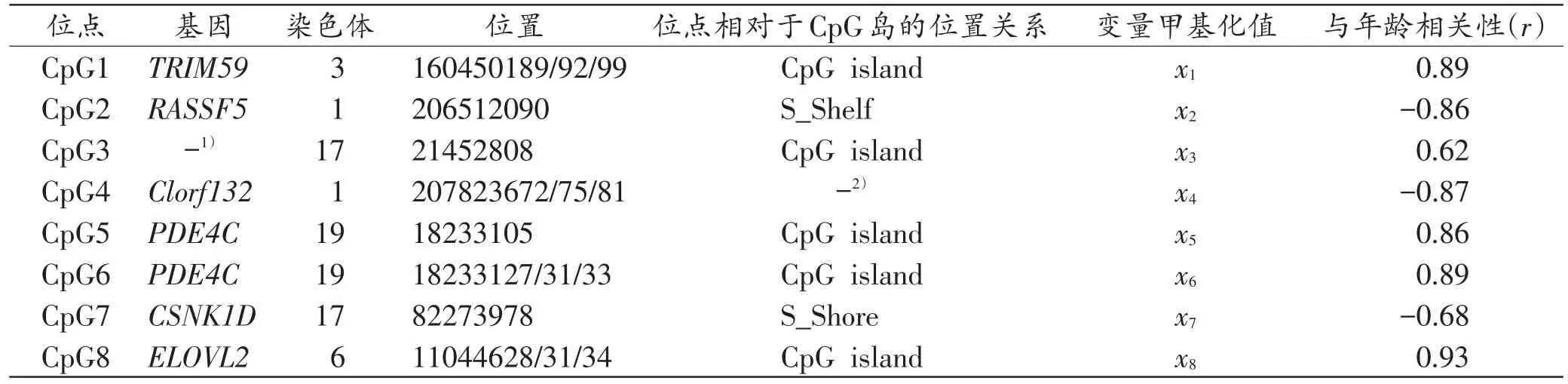
表3 筛选出8个年龄高度相关的甲基化位点
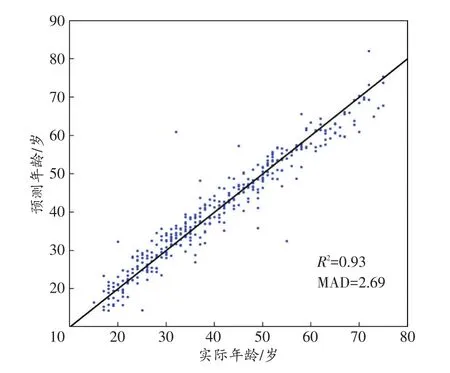
图1 年龄推断模型的预测年龄与实际年龄散点图
2.3 模型评估与验证
留一法交叉验证显示,MAD为2.76岁(图2)。6个年龄组的分析显示(表4),MAD值从小到大依次为45~<55岁、15~<25岁、35~<45岁、25~<35岁、55~<65岁、65~75岁。本研究建立的基于8个CpG位点的年龄预测模型,在年轻组(15~<25岁)和年长组(65~75岁)中,±5年的预测准确性分别为87.50%和78.90%,±6年的预测准确性分别为91.76%和86.24%。
运用109份样本作为验证集,对年龄预测模型进行验证,其MAD值为3.80岁(图3)。
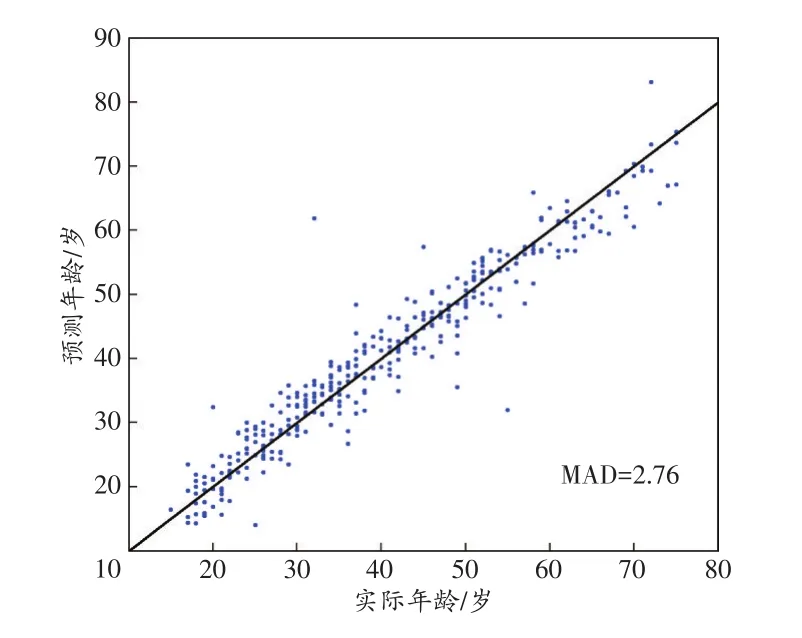
图2 预测年龄与实际年龄的留一法验证散点图
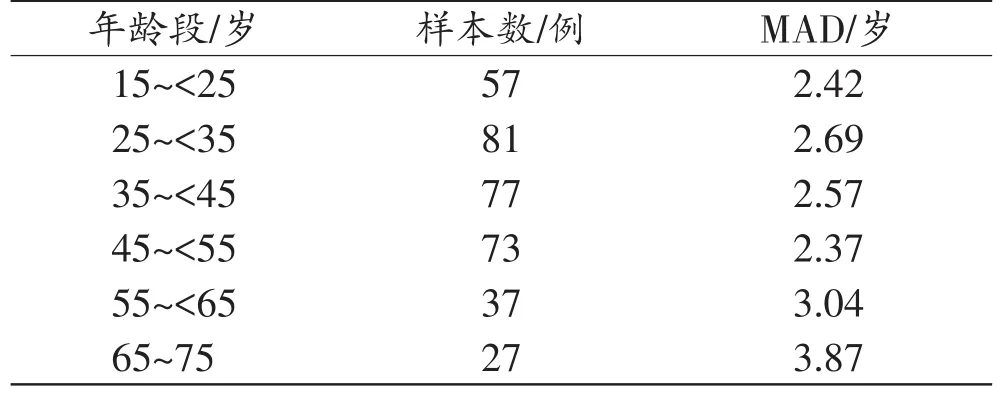
表4 不同年龄段的平均绝对偏差(N=352)
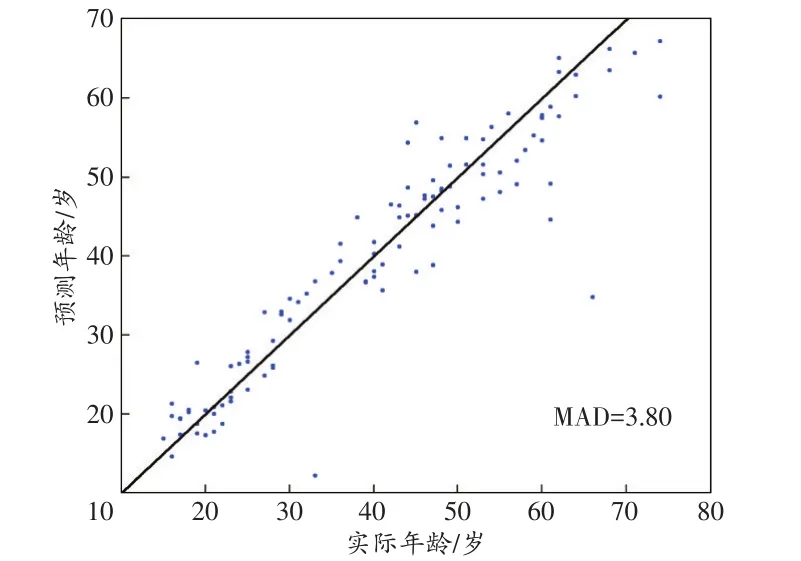
图3 109份样本验证散点图
2.4 血斑结果
15份血液样本与相应的血斑样本的8个CpG位点甲基化值(表5)配对样本t检验结果显示,在CpG1和CpG5,血液与血斑样本之间差异有统计学意义(P<0.05),其余6个CpG位点的血液与血斑样本之间差异无统计学意义(P>0.05)。使用建立的年龄推断模型,在血液样本和血斑样本中预测年龄与实际年龄之间的MAD值分别为4.08岁和3.99岁。15份血液样本和血斑样本的年龄推断误差最小为0.20岁和0.93岁,最大误差为9.84和10.12岁。
2.5 重复性初步验证
为了验证结果的重复性,对上述15份血液DNA样本,基于模型中的8个位点和相同的实验方法,重复2次试验,3次结果的MAD值分别为4.08、4.68和3.93岁,MAD值波动范围在1岁之内,基于8个位点建立的年龄预测模型结果的重复性相对较好。
表5 血液样本与血斑样本在8个CpG位点的甲基化值(n=15,±s)
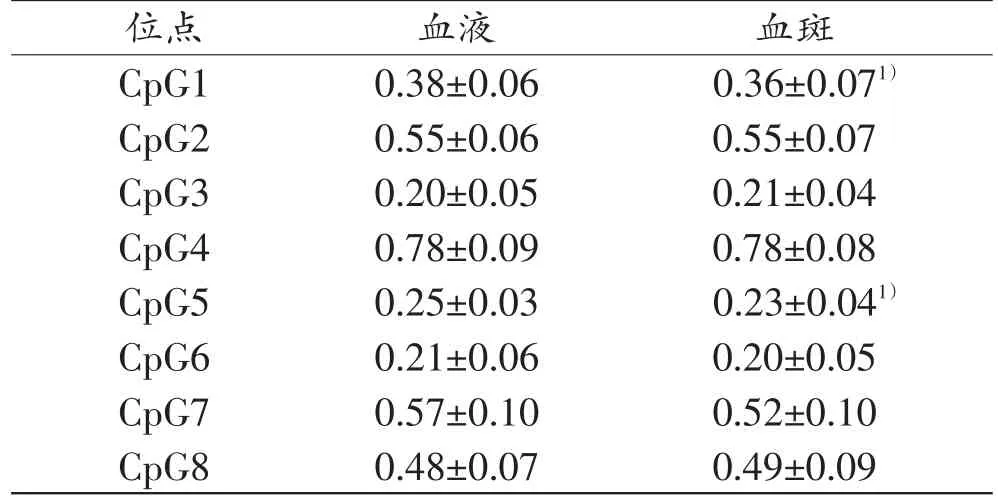
表5 血液样本与血斑样本在8个CpG位点的甲基化值(n=15,±s)
注:1)与血液样本比较,P<0.05
血斑0.36±0.071)0.55±0.07 0.21±0.04 0.78±0.08 0.23±0.041)0.20±0.05 0.52±0.10 0.49±0.09位点CpG1 CpG2 CpG3 CpG4 CpG5 CpG6 CpG7 CpG8血液0.38±0.06 0.55±0.06 0.20±0.05 0.78±0.09 0.25±0.03 0.21±0.06 0.57±0.10 0.48±0.07
3 讨 论
年龄推断一直在法医学领域备受关注。众多研究报道显示[1,2,22],DNA 甲基化作为年龄预测分子标记,在法医学应用中具有许多独特的优势。目前,大多研究[19-22]都是以欧美人群为研究对象。本研究基于EpiTYPER技术平台,检测了476份汉族男性样本,运用多元线性回归方法和AIC方法构建年龄推断模型(R2=0.93,MAD=2.69岁)。AIC是建立在熵的概念基础上,衡量统计模型拟合优良性的一种标准,可以作为模型选择的一种方法,也可以权衡所估计模型的复杂度和此模型拟合数据的优良性,AIC越小,结果越好。该模型的8个CpG位点中,CpG1、CpG3、CpG5、CpG6、CpG8与年龄成正相关,随着年龄的增长,DNA甲基化程度逐渐增加;CpG2、CpG4、CpG7与年龄呈负相关,随着年龄的增长DNA甲基化呈现去甲基化状态。位于6号染色体的ELOVL2基因被证明与年龄具有高度关联性[18,20-21],TRIM59[20]、PDE4C[21]、Clorf132[20-21]、CSNK1D[19]、RASSF5[19]基因上DNA甲基化水平都被证明与年龄具有关联性,这些位点应用于不同的年龄推断模型中。此外,chr17:21452808[29]位置上DNA甲基化水平也被证明与年龄具有关联性。
本研究建立的基于8个CpG位点的年龄预测模型,随着年龄段的增加,预测准确性出现相应的下降,MAD值大体上逐渐增大,在年轻组(15~<25岁)MAD值为2.42岁,在年长组(65~75岁)MAD值最大为3.87岁,该实验结果与前期已经报道过的结果[1,21]一致。
HANNUM等[18]基于甲基化芯片数据建立了基于71个CpG位点的年龄预测模型,在训练集和验证集该模型的MAD值分别为3.9岁和4.9岁。WEIDNER等[22]报道了基于3个CpG位点的年龄预测模型,在训练集和验证集中MAD值分别为5.4岁和3.9岁。ZBIECPIEKARSKA等[20]建立了基于5个CpG位点的年龄预测模型,在训练集中MAD为3.4岁,在男性和女性样本中其MAD值有稍微的差别,分别为3.7岁和3.0岁。在验证集中MAD为3.9岁,在男性和女性样本中其MAD值略有差别,分别为4.0岁和3.7岁,±5年的预测准确性为72%。PARK等[1]报道的基于3个CpG位点的年龄预测模型,在训练集和验证集的MAD值分别为3.16岁和3.35岁,±6年的预测准确度在<60岁分组中为77.30%,在年老组(>60岁)为57.30%。与上述研究建立的模型相比,本研究建立的年龄预测模型准确度较高。
此外,模型利用的样本是新鲜血液检测出的数据,而实际检材中往往难以获得大量血液样本,更多的是血斑,因此需要评估血液与血斑之间是否存在显著差异,这在实际应用中有重要的意义。本研究检测了15份血液样本DNA和相对应的室温存放3个月的血斑DNA,MAD值分别为4.08岁和3.99岁,CpG1和CpG5的甲基化值差异有统计学意义,其余6个CpG位点之间差异无统计学意义。血液样本与血斑样本的年龄预测误差范围在0~10.12岁,预测误差相对较小。关于血斑样本的模型优化,需增加血斑样本检测数量,验证该模型是否适用于血斑样本。另外,15份血液样本进行了3次重复实验,3次结果的MAD值相差不大,证明年龄预测模型具有较强的稳定性和重复性。由于建立年龄预测模型时仅使用了我国3个地区的样本,对其他地区样本适用性需要进一步验证。
本研究运用多元线性回归方法建立的基于8个与年龄高度相关的DNA甲基化位点的年龄预测模型,可以作为法医学应用中年龄预测的一种可靠又有效的方法。年龄的正确推断可为案件提供更多更准确的侦查线索,缩小案件的侦查范围,有利于案件的快速侦破。
(感谢公安部物证鉴定中心闵建雄研究员为本研究提出非常有价值的建议。)
猜你喜欢
罕少疾病杂志(2022年9期)2022-09-03 11:04:14
医学理论与实践(2021年24期)2022-01-04 10:37:40
上海金属(2021年6期)2021-12-02 10:47:20
昆明医科大学学报(2021年3期)2021-07-22 07:40:04
检验医学(2020年3期)2020-04-21 03:10:54
生物学通报(2019年3期)2019-02-17 18:03:58
刑事技术(2016年4期)2016-12-22 01:55:24
现代检验医学杂志(2015年2期)2015-02-06 02:00:48
沈阳医学院学报(2014年4期)2014-12-27 13:44:30
遗传(2014年3期)2014-02-28 20:58:49
