
基于LIBSVM的视觉信息页面块分析模型
2019-03-22 01:41:36董婷
榆林学院学报 2019年2期
董 婷
(榆林学院 信息工程学院, 陕西 榆林 719000)
引言
从用户的角度来看,在观察web页面时,把语义块作为单一的对象来看,而不会研究web页面的内部是怎样的。分块之后页面快的高度、宽度,色素点等一系列的属性对于整个页面块对于人视觉的影响是怎样的,这些通过人的感官是无法进行准确判断的。随着机器学习手段的发展,采用支持向量机这种方式研究问题,分析问题规律的案例也在不断增多,为通过SVM技术分析页面块的联系提供了更多的理论支持。
1 模型分析
1.1 数据来源
数据源来自UCI数据库中的Page Blocks Classification数据包,该数据来自54个不同的网页文档,特性如下:实例共5473个,属性共10个,所有的属性都是数字,都是可通过C4.5的可读格式,没有未知量。根据测试得到的输入变量包括10个,分别是height、lenght、area、eccen、p_and、mean_tr、blackpix、wb_trans。这几种属性分别对网页页面被分割后的宽度,高度,偏心块长度以及高度,黑色块内的像素点的比例,黑色像素总数RLAS后的位图块等一系列的的描述。
1.2 支持向量机简介
支持向量机是根据Vapnik提出的结构风险最小化原则来提高学习机泛化能力的方法,其本质是一个凸二次优化问题,能够保证找到的极值解就是全局最优解[1]。求两个样本的最优分类面是它的主要目的[2]。最优分类面既要将两类样本正确分开,又要使它们之间的间隔最大。一般用一次方程来表示分类面方程即(w·x)+b=0(b为常数)。经过归一化后,得到的样本集(xi,yi),xi∈χ=Rn,yi∈1,-1},i=1,…l,是线性可分的并满足
yi((w·xi)+b)≥1,i=1,…,l
(1)
这时的分类间隔为2/‖w‖ ,要使间隔取最大值,那么就要使
Φ(w)=1/2‖w‖2=1/2wTw=1/2(w·w)
(2)
取最大值[3]。
2 建立模型
2.1 理论依据
SVM的两大重要思想是[4]: (1)线性不可分时,SVM利用非线性映射算法,样本的非线性特征会进行线性分析;(2) SVM建构最优分割超平面,使整个样本空间风险低于某个概率的上边界。
SVM在它坚实的理论基础上;使它结构风险变得最小,它不仅解决了传统的过学习方法而且解决了陷入局部最小的问题,它的泛化能力也很强;SVM在不增加计算的复杂性和维数灾难的情况下,采用核函数方法,向高维空间映射,大大减小了计算量等优势得到了广泛应用。本课题正是在这一系列坚实的理论基础之上开展的。
2.2 实验过程
在求解分类问题,我们采用支持向量机时,首要选择非常合适的核函数,再选择相关参数。LIBSVM-2.86软件包中对刚才得到的数据进行分析和对比,找到最合适的模型[5]。
(1) 收集样本,整理数据,进行标准化设置
LIBSVM按一定的数据格式把每一个样本特征设置成实数行向量,格式设置为:
其中:label是训练数据集的目标值,对于分类可以是任意实数[6]。index是从1开始的整数,表示特征值的序号;value是用来训练或预测的数据,即特征值或自变量,一般为实数。以下为本样本中的部分数据:

表1 样本部分数据
集合构建完之后,任意选取部分数据来进行训练。进而对数据进行预测,我们先按照比例为1:1来选取样本,我们从总数据集合的数据中随机选取样本,建立page_predict和page_train两部分。
(2) 训练数据,生成模型
进行训练,输入命令:svm-train page_train page_train.model,其中page_train是训练文本、page_train.model是训练后的输出文本,输出权系数及各支持向量。
(3)利用获取的模型进行测试与预测
用已经分类好的数据集page_train对page_predict进行预测,page_predict.predict可以与元数据进行对比从而判断预测数据与预测结果的正确性。

表2 生成模型
2.3 结果分析
从图1可以看到不同颜色等值线,由于C和g的取值不同,表现出不同分类效果,如绿色线条a,曲线趋于复杂,拟合效果好[7]。黄色线条f,曲线趋于平滑,拟合效果略差。当核函数参数g取不同的值,惩罚因子C需配以不同的值,拟合效果才好,因此存在核函数参数数和惩罚因子的最佳匹配问题[8]。当C = 32768 和g=0.0078125取最佳参数时,交叉验证精度高达97.004%,这就是最优结果。实验表明该方法能够对页面块的相关属性快速有效的评判。
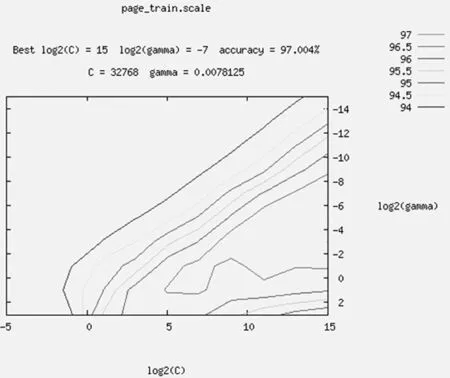
图1 调优时gnuplot训练文本所形成的向量机
3 结束语
SVM的分析模型不受样本空间维数的限制,关键在于支持向量的数目,所以支持向量样本集具有一定的鲁棒性。该模型为客观数据驱动评判方法提供了理论依据,并为理化数据测试方法的研究与应用奠定了理论基础。
猜你喜欢
保健医苑(2022年1期)2022-08-30 08:39:14
新高考·高一数学(2022年3期)2022-04-28 07:02:46
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
电脑爱好者(2011年11期)2011-06-22 08:20:18
