
基于ICA和自适应混合智能算法的应用
2019-03-21 09:12陈艳
浙江水利水电学院学报 2019年1期
陈 艳
(池州学院 机电工程学院,安徽 池州 247000)
盲源分离(blind signal separation, BBS)一直以来都是信号处理领域的一个研究热点问题。盲源分离是从可观测到的信号中分离出隐含其中的独立源信号。“盲”是指独立源信号不可直接观测到,且观测得到信号的混合形成过程不知道。盲源分离问题的解决对混合信号的形成环境以及源目标信号的信息的依赖比较少,因此,它应用比较广泛。
独立分量分析(independent component analysis ICA)一般被用作盲源分离,它通过建立目标函数将盲源信号分解开来,由此达到恢复信号的目的,分解得到的信号称为数据处理中的独立成分[1]。ICA是基于信号的高阶统计量,研究信号之间的独立关系[2],它在数据处理中得到更广泛的应用。盲源信号经ICA进行分离后,得到的分离信号其形态和源信号有着高度相似性,然而在幅值方面却和源信号有着较大差异。
BP神经网络通过搜索最优值在信号处理中得到广泛应用。然而,BP神经网络采用梯度下降法连续优化权值和阈值,因而对初始权值和阈值的选择尤为关键,而初始权值和阈值的选择仅能凭经验,算法求解很容易收敛于局部极小值[3-4],最佳的权值分布很难得到。但搜索不依赖梯度信息的遗传算法是一种自适应全局搜索的算法。因此为了同时优化神经网络结构和权阈值,一般选用遗传算法。通常使用遗传算法来确定BP神经网络的初始权值和阈值[4]。
将递阶遗传算法与BP神经网络组合在一起称为自适应混合智能算法。这种算法既能全局搜索寻优,又能快速收敛[5]。鉴于已有的研究成果,本文将ICA技术和自适应混合智能算法结合对信号进行分离,实验表明,该算法能达到更好的分离精度。
1 ICA方法
设存在m个未知源信号的s(t)=[s1(t),s2(t),…,sn(t)]T相互独立,通过采集系统获得n个传感器上线性叠加接收到的观测信号x(t)=[x1(t),x2(t),…,xn(t)]T。在条件为n≥m的情况下,总存在混合矩阵A,使x=As。如果在噪声环境下,线性混合系统模型为:
x=As+R
(1)
其中A是n×m维的矩阵,源信号s(t)和混合矩阵A都是未知的,x(t)混合信号是可以观测得到的,R是n维加性高斯白噪声,一般设m=n。
ICA算法的目的是求解矩阵B,使其满足:
y(t)=Bx(t)
(2)
可得y(t)=Bx(t)=BAs(t),y(t)是逼近于未知源信号s(t)的最优值,并且组成信号y(t)的各个分量尽可能相互独立。这里采用FastICA算法[6]。
2 递阶遗传学习神经网络算法
递阶遗传算法的思想是先把神经网络的结构和权值都编码成一个个体,再对神经网络的结构和权值通过遗传算法同时对其进行训练优化[7]。递阶遗传算法的染色体由两块结构构成[8-9]:一块是控制基因,另一块是参数基因。通常使用二进制数编码控制基因,对于激活情况下的下层基因用1表示,同时非激活情况下的下层基因处于用0表示;参数基因用来表示节点的连接权以及阈值系数,用实数编码的方式。其中控制基因又分为层控制基因和神经元控制基因[10](见图1)。
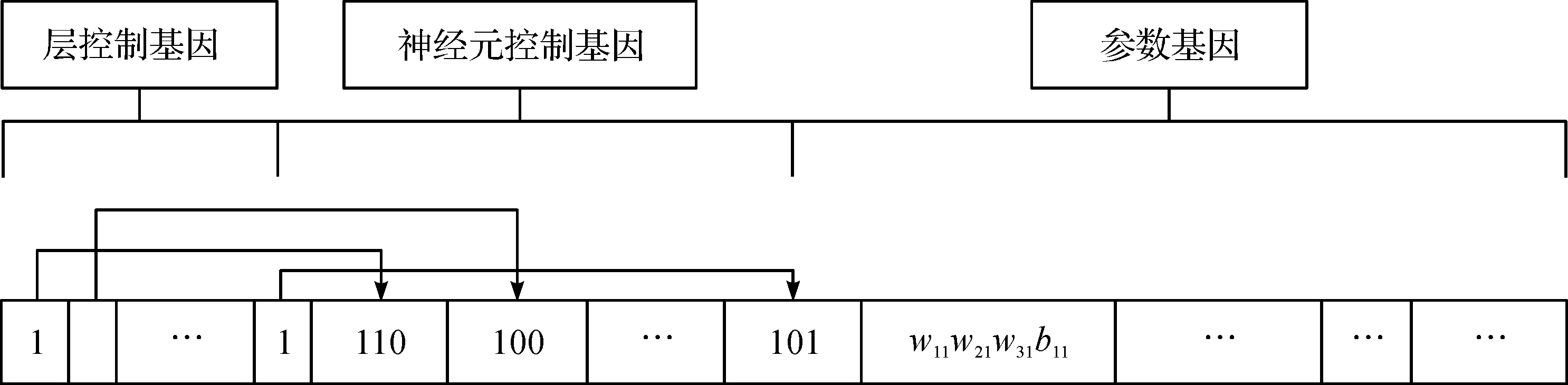
图1 网络结构和权值的编码示意图
递阶遗传学习神经网络算法实现的主要步骤:
(1)确定种群规模N,以上描述的编码方式被用作判断变量的编码方式[11]。给定交叉概率pc,变异概率pm。若进化代数t与进化终止代数T相等,则算法终止。
(2)取t=0,以一定的方式产生初始种群X(0)。
(3)计算种群X(t)中个体Xi(t)的适应值f(Xi(t)),对母体个数N的选择依据个体的适应值。
(4)为避免控制基因出现全0情况,对N个母体里面的控制基因仅使用均匀变异的方法;使用算术交叉以及高斯变异来对构造基因做出操作,保留下最优个体。
(5)若t=T,输出进行结果,否则转步骤(3)。
3 自适应混合智能学习算法的设计
自适应混合智能算法是在递阶遗传算法基础上引入BP神经网络,在遗传算法递阶编码的情况下,使用自适应交叉概率和变异概率训练网络。这种算法不仅能将遗传算法的全局搜索最优性保留下来,同时又能凸显出BP算法沿最速下降方向进行相应局部搜索的能力,从而达到兼顾全局寻优和快速搜索的目的[5]。
(1)染色体编码
控制基因包括层的控制基因和神经元的控制基因。为了较好的控制神经网络的拓扑结构,一般采用二进制数编码的形式[11],1表示激活情况下的下层基因,同时0表示非激活情况下的下层基因。参数基因表示网络的权值系数和阈值系数。若要达到网络权值系数的精度以及染色体的编码长度,这里参数基因采用表示非常直观的实数编码的形式。种群规模的选择对遗传算法的性能影响具有重要意义,种群太小往往得不到满意的结果,种群太大则导致网络训练的时间过长。一般种群的规模适宜取为50~150。
(2)交叉和变异
层控制的基因和神经元控制的基因在这里采用单点交叉的方式。单点交叉首先在个体编码串中随机设置一个交叉点,然后在该交叉点相互交换两个配对个体的部分染色体。由于参数基因使用实数编码,因此使用算术交叉方式对参数基因进行操作。算术交叉方式通过两个个体的线性组合而产生两个新的个体。
交叉概率的取值既影响遗传算法产生新的个体,又会影响其算法的收敛性。若交叉概率取值偏大,将对种群中的优质结构造成破坏,干扰进化运算;若取值小到一定程度,又将使产生新个体的过程变得十分迟缓,通常建议的取值区间为0.4~0.99[12]。为了避免遗传算法收敛过早,本算法中使用自适应的交叉概率:
(3)
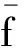
变异操作不仅包含对控制基因的操作而且包含了对所控制的网络权重、阈值的操作。控制基因的变异操作是利用一定概率把控制基因串里面的位在“1”与“0”之间互换,变异操作将对隐层结构造成影响,利用选择操作保留进化变异。
考虑到参数基因采用实数编码,对于算法初期,种群中会出现少数几个个体的适应值相对非常小,在确定个体的遗传数量时假使依照常用的比例进行算子的选择,那么这几个相对较好的个体将在下一代群体里占据比较大的比例。当群体的规模还比较小的时候,这样的少数几个个体就会组成新的种群,但是对于产生新个体作用较大的交叉算子就无法发挥作用了,由此为了扩大搜索空间,只有通过均匀变异增加群体的多样性。同时变异概率的设置影响较大,如果设得过大容易对优质结构造成破坏,而设得较小将会限制变异操作产生新个体以及早熟现象的抑制,所以采用自适应变异率pm:
(4)
(3)适应值计算
递阶遗传算法不仅优化神经网络结构,并且也对神经网络的权值和阈值作出求解运算。因此这种算法属于一个双目标优化问题,其要求网络的误差函数和复杂度函数均为最小。适应值函数记为:
f=fe+α×fs,0<α<1
(5)
式(5)网络训练数据的均方误差用fe代表,网络复杂度代表网络里激活的连接权值数与网络里面的全部连接权值数的比值,用fs代表。一般适应值系数取在0.1~0.5之间,用α表示。
由于BP的最速下降特性,所有个体通过遗传算子操作后都会朝着极值点靠近,也就是局部搜索。局部搜索虽然有一些点可能会陷入局部极值点,但因此可以保留最优点。由此下一代经过选择、交叉、变异算子的搜索后,会产生一些适应值大的较优点,保留较优点,删除适应值小的局部极值点。
3.1 自适应混合智能学习算法的流程图
自适应混合智能学习算法(见图2)。
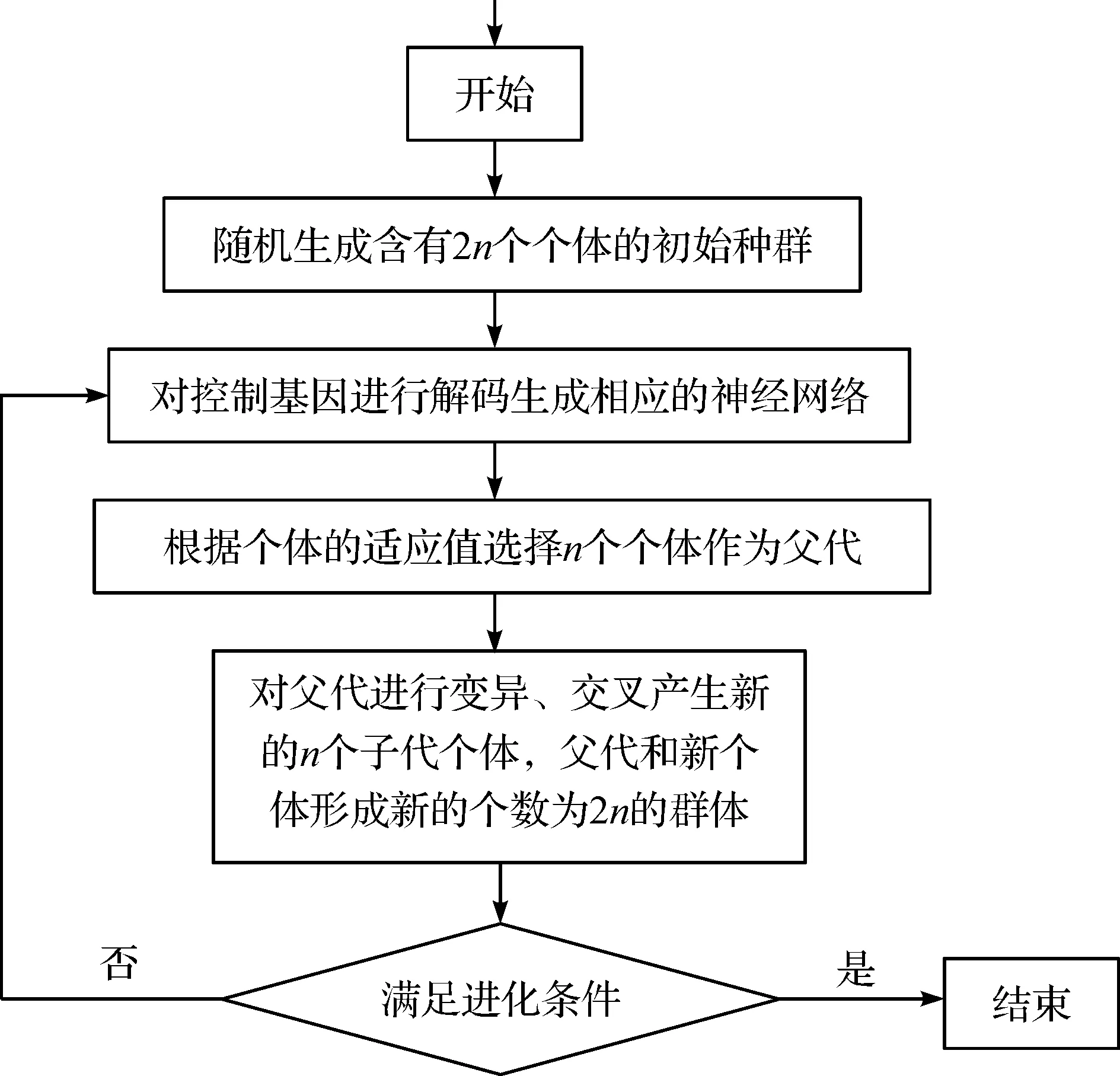
图2 自适应混合智能算法流程图
3.2 自适应混合智能学习算法的优化模型
基于混合智能算法建立以下优化模型,采用三层网络结构(见图3)。
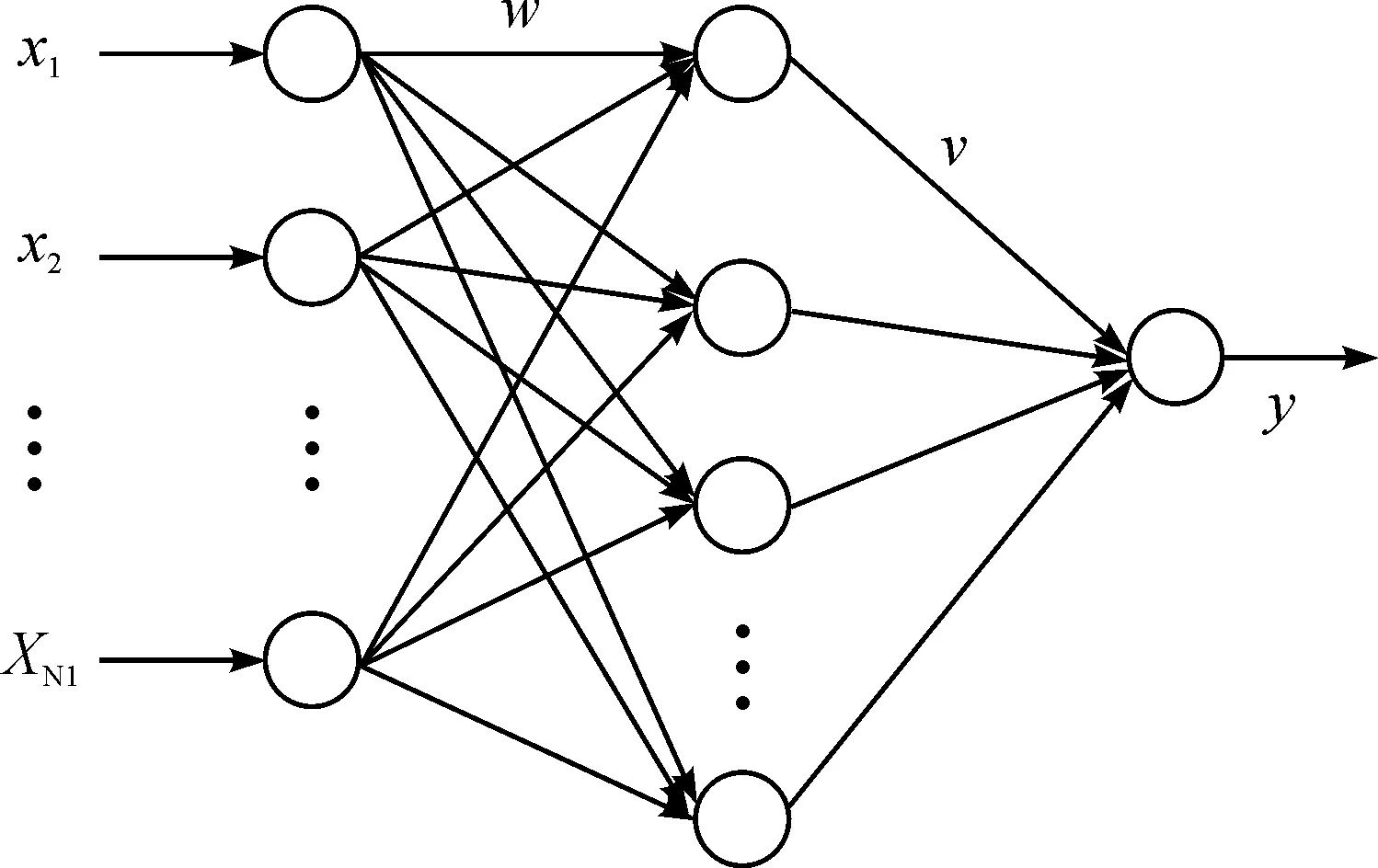
图3 自适应混合智能算法的网络结构
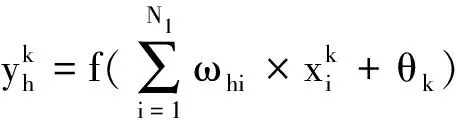
对比传统遗传算法,自适应混合智能算法不仅具有更快的收敛速度和更高的收敛精度,收敛过程
稳定,而且在进行权值训练时,对神经网络的拓扑结构进行优化,学习效率较高。另外在遗传过程中,自适应交叉和变异概率的采用能有效加快遗传速度,避免早熟现象的出现。
3.3 基于ICA分离和自适应混合智能优化算法的步骤如下:
(1)读取混合信号,数据经过去均值[13]和白化处理。
(2)采用文中ICA分离的方法分解得到分离信号y。
(3)对步骤(2)中得到的分离y信号运用自适应混合智能学习算法的优化模型输出分离精度更高的信号。
4 计算机仿真实验
自适应混合智能算法中种群规模选为120,种群进化总代数为4万代,交叉概率依据式(7)、交叉概率依据式(8)进行自适应调整。
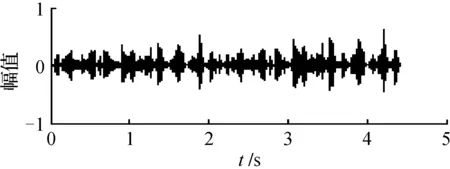
图4 源语音信号s1(t)
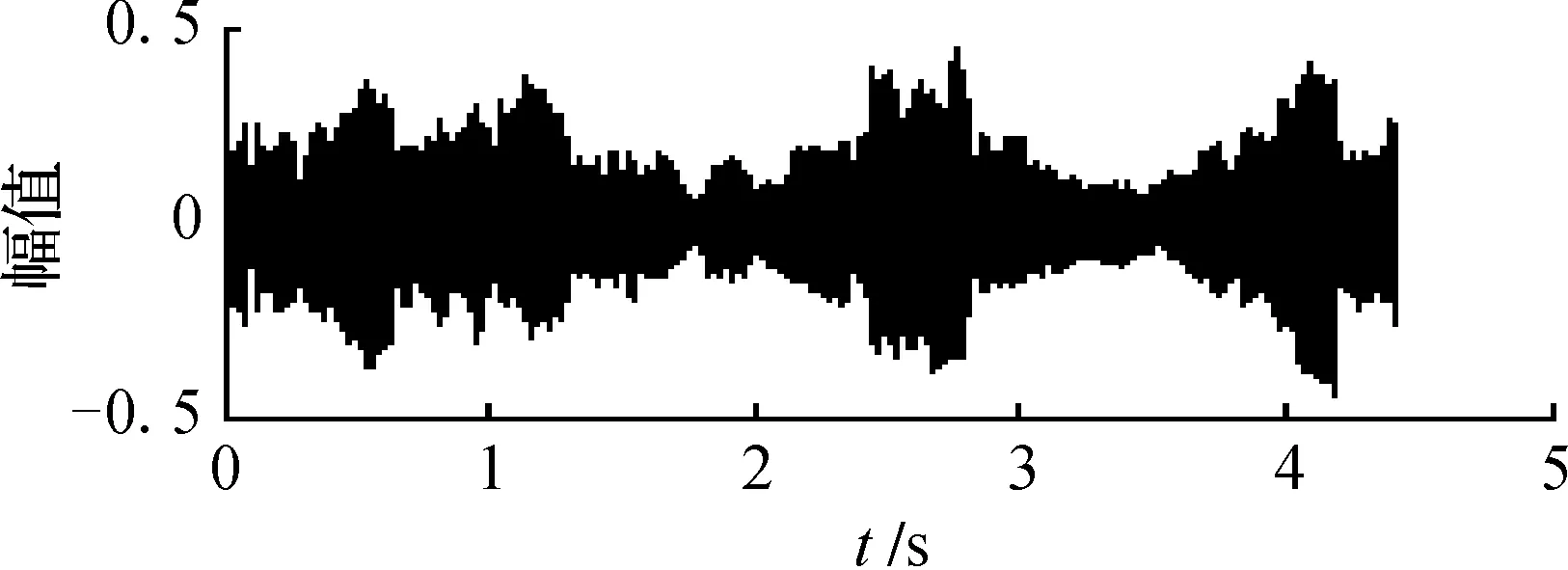
图5 源语音信号s2(t)
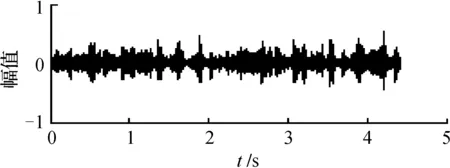
图6 混合语音信号x1
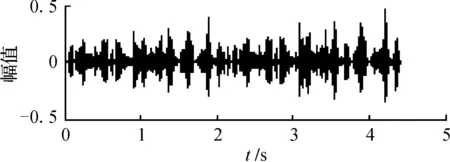
图7 混合语音信号x2
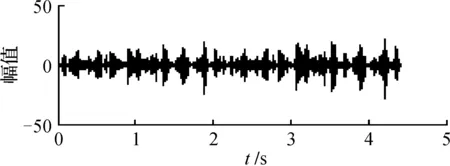
图8 ICA算法分离语音信号
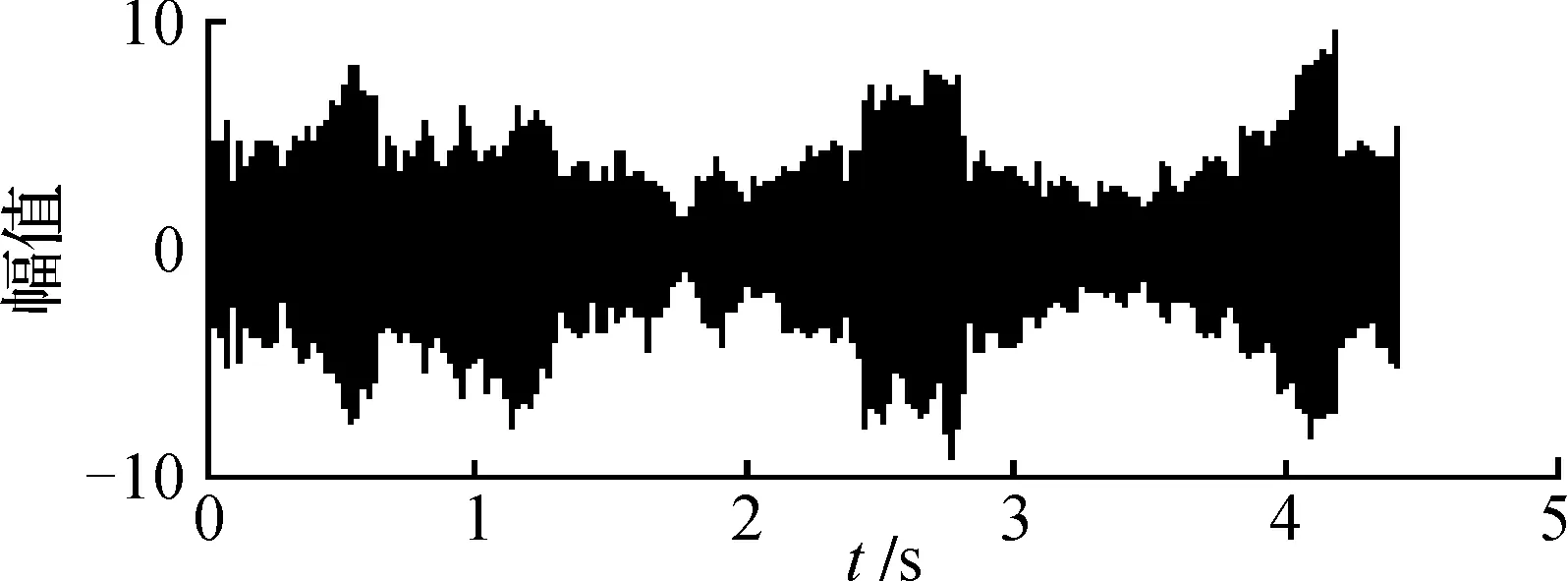
图9 ICA算法分离语音信号
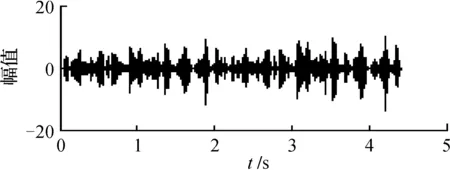
图10 自适应混合智能优化算法分离语音信号
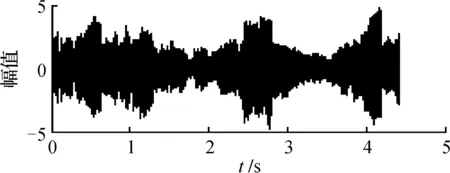
图11 自适应混合智能优化算法分离语音信号
通过图6和图7对比表明,采用ICA分离后得到的信号再经自适应混合智能优化方法得到的信号主观上观察更加标准(见表1)。客观实验数据也表明,该方法具有较好的分离精度。

表1 自适应混合智能优化算法分离语音信号分离信号的相关系数
5 结 语
自适应混合智能算法具有更高的收敛精度,在进行权值训练时学习效率较高。将ICA与自适应混合智能算法结合,可以增强信号分离精度。实验表明本文提出方法具有可行性,与单纯的ICA方法相比,具有较好的分离效果。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
大电机技术(2022年1期)2022-03-16
今日农业(2021年12期)2021-11-28
初中生世界·八年级(2019年6期)2019-08-13
计算机与数字工程(2018年5期)2018-05-29
计算机测量与控制(2018年3期)2018-03-27
数码世界(2017年5期)2017-12-29
价值工程(2016年32期)2016-12-20
小学生导刊(低年级)(2016年9期)2016-10-13
小学生导刊(低年级)(2016年6期)2016-07-02
