
一种基于云模型的特征选择参数优化研究
2019-03-21 11:38:18张震雷杨新凯
计算机技术与发展 2019年3期
宋 丽,张震雷,杨新凯
(上海师范大学 信息与机电工程学院,上海 200234)
0 引 言
随着互联网技术的蓬勃发展,网络中的文本正以指数级的速度增长。因此,提取大数据量下的有效信息,提高文本分类的高效性和准确性、提高高质量和智能化的文本分类、满足用户所需要的信息服务具有重要的意义。特征选择和特征降维是实现特征研究的关键步骤。文中主要研究的是特征选择技术。文本特征选择技术[1]是实现文本分类的关键问题之一[2]。常用的方法[3]是降低短文本特征维数和去除冗余无关的特征[4]。文中通过常用的文本特征选择方法[5]进行预选;提出了一种基于云模型[6]优化的特征选择方法,预选的特征子集作为第二次特征选择的原始特征空间,解决了特征子集规模大小难以确定的问题。
1 研究现状
最原始的文本分类依赖于人工,该分类方式对参与文本分类工作人员的要求较高,需要他们对各领域的知识都有良好的认知和掌握。该分类方法效率极低、成本较高,不适用于大规模文本分类的场景。20世纪50年代末,相关学者开始对文本分类方法进行研究。1961年,Maron等[7]发表了一篇关于文本分类的具有里程碑意义的文章,推动了文本分类的进展。20世纪70年代初,Rocchio[8]将线性分类器应用于文本分类领域,该方法通过用户的反馈信息不断地修正分类器的权重参数,来提高线性分类器的学习与分类效果。90年代末,相关研究学者[9]将机器学习方法应用于文本分类任务中。20世纪末,Yoav和Robert[10]提出了提升树分类算法,进而形成强分类器,这一算法的提出将文本分类算法推向了高峰。国内关于文本分类方法的研究起步较晚。目前,研究学者分别从特征选择、权重、分类模型等角度对其进行研究。对特征选择的研究,主要集中于特征扩展、特征选择、特征权重计算和分类算法设计这几个方面。常见的特征选择方法大都是基于常用方法,包括模式匹配法、词频法、卡方统计法、互信息法等。例如,姚旭等[11]分析了特征选择方法的框架,从搜索策略和评价准则两个角度[12]对特征选择方法进行分析和总结,分析出对特征选择的影响因素,并指出了实际应用中需解决的问题;徐刚等[13]提出一种根据速度信息自适应调整参数的粒子群优化算法,该算法可解决复杂非线性优化时搜索失败的问题。
以上研究主要依赖于传统的特征选择、特征提取及特征技术的组合使用,云模型的应用相对较少。文中主要通过传统特征选择技术进行预选,提出一种基于云模型的粒子群优化方法进行二次选择。
2 参数优化模型
2.1 粒子编码
粒子编码一般有UTF-8编码、二进制编码、GBK、实数编码等形式。粒子群优化算法离不开编码问题的设置。其中,二进制是最常用的编码方式,二进制编码具有易实现,编、解码简单操作等优势,得到了广泛应用。文中也采用二进制编码,用0、1表示粒子的位置信息,1表示该粒子被选中,0表示该特征被丢弃;用特征模糊熵值初始化粒子群的初始化种群,如:含200个特征的文本集,5个种群数,生成一个初始矩阵[5*200],矩阵形式如下所示。
1 2 3 4 … 199 200

2.2 粒子群技术
在特征选择的过程中,特征子集空间规模的确定成为一个难点。一般采用最优化的方法,对特征集空间进行全局寻优。文中采用粒子群算法(PSO)。PSO是一种全局优化方法,将优化问题的每个解作为搜索空间的一个“粒子”,每个粒子由优化函数决定的适应度来评价粒子当前位置的优劣。每个粒子有一个速度来决定各自移动的方向和距离。在每次迭代中,粒子跟踪两个“极值”来更新自己:一个是个体极值(pBest),一个是全局极值(gBest)。
第i个粒子找到上述两个极值,更新自己的速度和位置:
(1)
(2)

惯性权重:
(3)
其中,wmax为最大惯性权重;wmin为最小惯性权重;itermax为最大迭代次数;t为当前迭代次数。
2.3 基于云模型的粒子群方法
针对粒子群算法[9]存在早熟和不收敛的问题,通过权重生成策略来改变惯性权重的方法,保证收敛速度与全局收敛之间的折中。
2.3.1 适应度函数
特征选择主要是剔除不相关或无用的特征来对文本进行预处理。文本分类的三个评价指标中,准确率最能衡量特征与类别的关系程度。因此这里的适应度函数用准确率这一评价指标,公式如下:
(4)
其中,m为总类数;N为总的文本数;ni为类别i被正确分类的文本数。
2.3.2 权重生成策略
结合云模型的优点,提出一种基于云模型的粒子群优化算法,以动态确定惯性权重来避免粒子群的早熟收敛问题。

(1)fi>fpg:当粒子的适应度值大于当前全局最优值时,表示该粒子在群中是最好的,解与全局最优值很接近。为了加快全局收敛速度,缩短运行时间,这种情况下使惯性权重最小。此时惯性权重为:
w=wmin
(5)
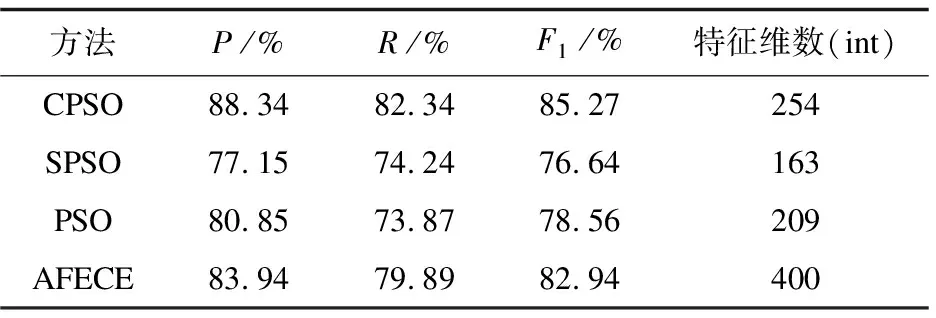
(2)favg (6) 从公式中可以得到,w与适应度函数值成反比,实现了较优的粒子与较小的w值的对应。经实验验证,式中c1=c2=4。 (3)fi w=wmax (7) 通过阅读文献资料,总结出惯性权重通常取[0.4,0.95]这个区间时,粒子的优化性能飞速提高。因此,wmin=0.4,wmax=0.95。 2.3.3 基于云模型的粒子群技术 基于云模型的特征选择方法由两阶段完成。第一阶段采用AFECE对原始的特征集进行预选;第二阶段将第一阶段预选出的特征子集作为第二阶段的原始集,采用云模型特征选择方法来进行第二次特征选择。 算法描述如下: 输入:原始特征集X' 输出:特征子集 (1)特征预选 (2)初始化粒子群各参数 (3)计算惯性权重,更新粒子的速度和位置 else∶fpg=fpi (6)根据结束条件来判断是否满足。否则返回到(3) 算法的结束条件是根据在全局寻优的过程中,不断变化的阈值来判断的。图1为算法的流程框图。 图1 CPSO特征选择方法 利用从http://kdd.ics.uci.edu网站上下载的reuters-21578数据集进行仿真,训练集占80%,测试集占20%。 reuters-21578数据集,经MI、CHI、ECE、AFECE四种特征选择方法进行特征预选,效果如图2和图3所示。 图2 不同特征选择方法在不同特征维数下的精确率 图3 不同特征选择方法在不同特征维数下的F1值 在预选特征子集的基础上进行二次特征选择,初始化各参数如表1所示。 表1 初始化各参数 表1是二次特征进行选择时各参数大小的设置。第一阶段的特征子集空间选择400作为第二阶段的原始特征空间。这里的种群数与类别数是一一对应的。其他各参数是通过数据训练的调试及经验进行设置的。表2是第二阶段的三种特征选择方法与第一阶段的AFECE特征选择方法所得的实验结果。可以得出,SPSO所需的特征维数最少,就能达到较好的分类效果,但它的性能是四种方法里最低的。AFECE特征选择方法性能优于PSO、SPSO,但它是以牺牲空间换来的。CPSO特征选择方法性能有所改善,在精确率方面提高了4.4%,且所需的特征空间小。 表2 reuters-21578语料上各参数优化方法的 对比实验结果 基于特征子集空间规模大小难以确定的问题,提出了一种基于云模型的特征选择算法,由以下2个阶段组成:第一阶段比较MI、CHI、ECE、AFECE四种特征选择方法在性能上的优缺点,得到AFECE特征选择方法性能最好;第二阶段通过AFECE特征选择方法选出的特征子集作为这一阶段的原始特征空间,提出基于云模型的粒子群算法进行二次特征选取,避免了粒子过早收敛达到局部最优而不是全局最优的不足。实验结果证明了该方法的有效性和可行性。文中在特征选择方面做了一定程度的研究,在分类器设计方面没有进行尝试。因此提出适合的分类方法和改进分类器参数的确定将是今后研究的工作之一。除此之外,将该方法应用于产品智能推荐研究领域也是下一步重点研究的工作。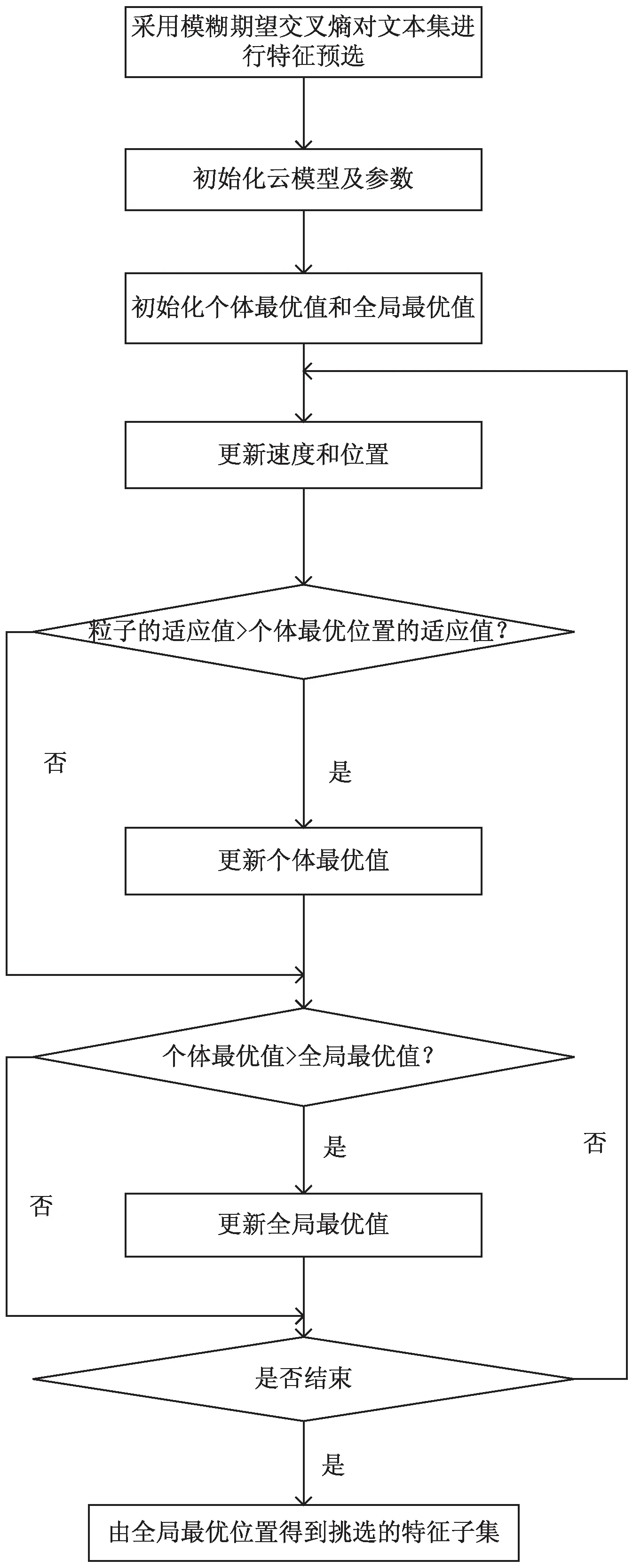
3 实验与结果分析
3.1 预选的特征子集性能


3.2 基于云模型的粒子群优化方法

4 结束语
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02当代陕西(2020年17期)2020-10-28 08:18:18人大建设(2018年5期)2018-08-16 07:09:00电信科学(2017年6期)2017-07-01 15:44:57电子制作(2017年23期)2017-02-02 07:17:06中国塑料(2016年11期)2016-04-16 05:26:02西北工业大学学报(2015年4期)2016-01-19 03:31:47振动工程学报(2014年4期)2014-03-01 01:15:41计算机工程(2014年6期)2014-02-28 01:26:36河南科技(2014年15期)2014-02-27 14:12:51
