
基于最大相关最小冗余-随机森林算法的多联机系统在线故障诊断策略研究
2019-03-19 07:52:50刘倩李正飞陈焕新王誉舟徐畅
制冷技术 2019年6期
刘倩,李正飞,陈焕新,王誉舟,徐畅
(华中科技大学能源与动力工程学院,湖北武汉 430074)
0 引言
据统计,建筑是全球能源消耗的主要产业[1]。在我国,建筑能耗约占全社会终端的21%[2-3],其中空调系统能耗约占建筑总能耗的40%~60%[4]。暖通空调系统设备复杂,在运行过程中会发生多种故障问题,造成大量能耗损失[5-6]。如果能在建筑中安装暖通空调故障诊断设备,确保设备运行正常,一个30年寿命的建筑至少可以减少30%的能源消耗[7]。多联机系统是暖通空调系统中的重要一部分,现广泛应用于中、小型商业、办公建筑以及大面积的住宅建筑等。制冷剂充注量若与系统不匹配将极大降低系统能效,增加系统的能耗。为了保证系统的稳定运行和正常使用,有必要针对多联机系统制冷剂充注量故障策略进行研究。
数据爆炸时代下,利用数据挖掘技术建立暖通空调系统故障检测与诊断模型[8-10],并进一步实现系统在线故障预测,是目前该领域研究的热点问题之一。王江宇等[11]提出一种基于分类回归树(Classification and Regression Tree,CART)算法的多联机压缩机回液故障检测,证明了决策树模型可以有效诊断回液故障。禹法文等[12]提出一种基于主元分析法的多联机压缩机排气温度传感器故障诊断方法。采用正常数据对主成分分析(Principal Components Analysis,PCA)进行建模,用故障运行数据进行验证诊断。结果表明该方法诊断效果良好。DU等[13]提出了小波分析与神经网络相结合的小波神经网络,用于诊断变风量系统中传感器的故障。丁新磊等[14]针对目前基于数据驱动的制冷系统故障诊断模型,只能对参与建模训练的已知类型故障进行诊断,提出一种优化神经网络的故障诊断策略,得到该模型对未知类型故障的诊断效果良好。XU等[15]利用小波分析方法和PCA方法,为离心式冷水机组开发了增强型传感器故障检测策略。结果表明,与传统的基于 PCA的传感器故障诊断策略相比,该策略使系统的性能更好。
目前国内外应用数据挖掘技术在暖通空调领域应用研究较少,而其应用在在线系统的故障检测与诊断策略的研究更少[16-17]。本文提出了一种基于最大相关最小冗余(minimal-Redundancy-Maximal-Relevance,mRMR)-随机森林(Random Forest,RF)算法的多联机制冷剂充注量故障诊断策略。该策略通过采用 mRMR算法进行特征选择,然后结合随机森林、支持向量机和决策树算法建立故障诊断模型,并采用网格搜索和十折交叉验证进行参数寻优,进一步提高诊断模型的泛化能力,改善模型过拟合问题,在3种模型中选择泛化能力更好的模型作为最终的诊断模型,最后在在线未知实例上验证该模型的诊断性能。
1 特征选择及分类算法原理
1.1 最大相关最小冗余(mRMR)算法
最大相关最小冗余(minimal - Redundancy -Maximal-Relevance,mRMR)算法是一种最大化特征变量与目标之间相关性、而最小化特征之间相关性的特征选择方法[18],以互信息量的大小作为衡量特征与特征、特征与类别变量间相关性的标准。
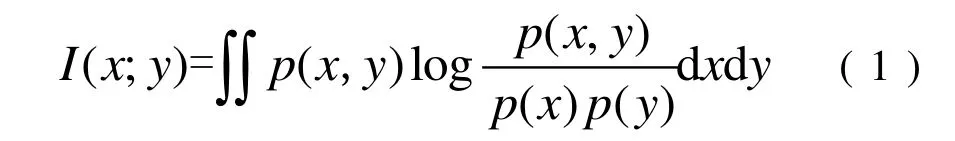
式中,x和y为给定的两个随机变量;p(x, y)为x和y的联合概率分布函数;p(x)和p(y)分别为x和y的概率分布函数。
为找出含有m个特征的特征子集S,最大相关性以I(xi, c)的适当顺序搜索与目标分类c相关的最佳m个特征xi,可用以下公式计算其相关性大小:
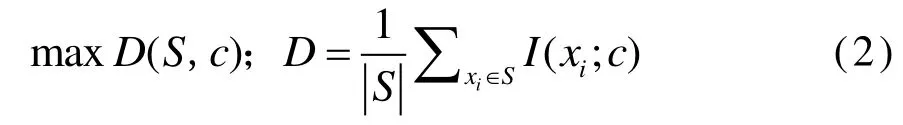
含有 m个特征的子集可能并不是最好的特征子集,当两个特征高度相互依赖时,其中一个被删除,各自的阶级判别力就不会有太大变化。因此,引入最小冗余标准来消除特征之间的冗余并选择互斥特征(式(3));然后采用加法整和最大相关系数和最小冗余度(式(4))。
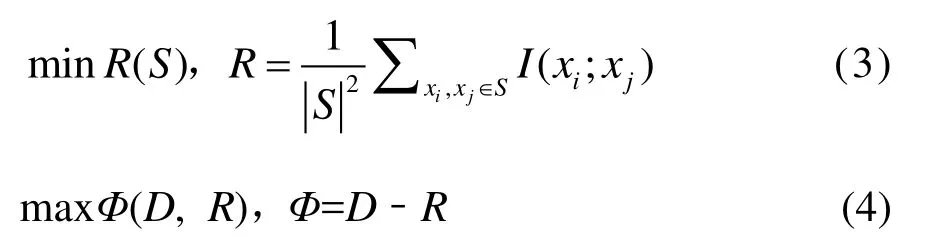
1.2 决策树、随机森林和支持向量机算法
决策树(Decision Tree,DT)算法是基于训练数据集进行训练学习,可以得到一个具有一定泛化能力的分类模型。决策树基于树结构进行分类诊断,进行每一步分类决策的过程如同树不断分支的过程,从根节点开始分支,经过若干的内部分支结点将数据集不断进行分类,最终得到对应不同决策结果的叶结点完成分类过程。
随机森林(Random Forest,RF)算法从 Bagging并行式集成算法中演变而来。若给定数据集中含有a个样本,从该数据集中抽取某一样本放入一采样集中,再将该样本放回原数据集中,进行a次随机抽样,得到含有a个样本的采样集。进行多次此操作,可以得到N个含有a个样本的采样集,每个采样集都可以训练出基学习器,每个基学习器都可以对样本进行分类预测,可得到 N个结果,此时Bagging会对分类结果进行简单投票法,即该模型将预测结果出现次数最多的作为最终分类结果。
支持向量机(Support Vector Machine,SVM)方法[19]基于样本进行计算:
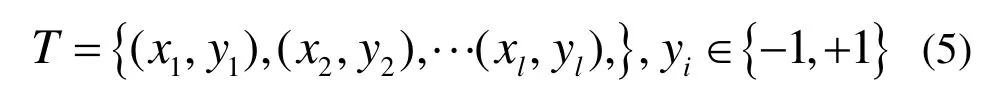
在样本空间中找到一个划分超平面,利用超平面将不同类型的样本分开,但是存在多个这样的划分超平面可以实现样本分离,由于训练集的局限性或噪声,需要选择最具鲁棒性的划分超平面。
划分超平面可以用式(6)来描述:

其中,w=(w1, w2, … , wd)为法向量,决定了超平面的方向;b决定了超平面与原点之间距离。
样本空间中的任意点x到超平面(w,b)的距离可表示为:

2 实验装置及数据获取
实验采用国家标准检测多联机(Variable Refrigerant Flow,VRF)系统在制热和制冷两种运行工况下不同制冷剂充注量的工作性能。图 1所示为实验多联机系统原理。该系统由蒸发器、冷凝器和压缩机等设备组成,配备有5个室内单元和1个室外单元,实验多联机系统中压缩机为密封涡卷式,制冷剂为 R410A,标准充注量为 9.9 kg,室外单元额定功率为28 kW,室内单元额定功率为29.7 kW。操作数据均由原始制造商组装的传感器收集,通过内置控制器传送到计算机终端。

图1 实验多联机系统原理
多联机系统分别在制热和制冷工况下运行,其中5个室内单元全部运行,温度设置如表1所示。实验制热和制冷工况下制冷剂充注量水平从 63.64%至130.0%共 9个级别,按照充注量水平分为 L1(63.64%)、L2(75.45%, 80%)、L3(84.84%)、L4(95.75%, 103.74%)、L5(111.72%)和L6(120%,130%)6类。对于每一种实验工况,风机转速认为保持不变,实验通过调节压缩机转速和膨胀阀开度使制冷剂流量匹配冷凝负荷。当制冷剂充注不足或充注过量时,多联机系统依旧可以稳定运行。
在此实验基础上制热与制冷工况下共获得156,251组数据,其中制冷工况下有66,887组,制热工况下有89,364组,在不同制冷剂充注量水平下数据分布如图2所示。
实验获取的不同制冷剂充注量工况下系统运行数据中,根据其他学者前期所做的研究工作,实验选取了原始数据集中的 18个特征变量,选取的特征变量如表2所示。
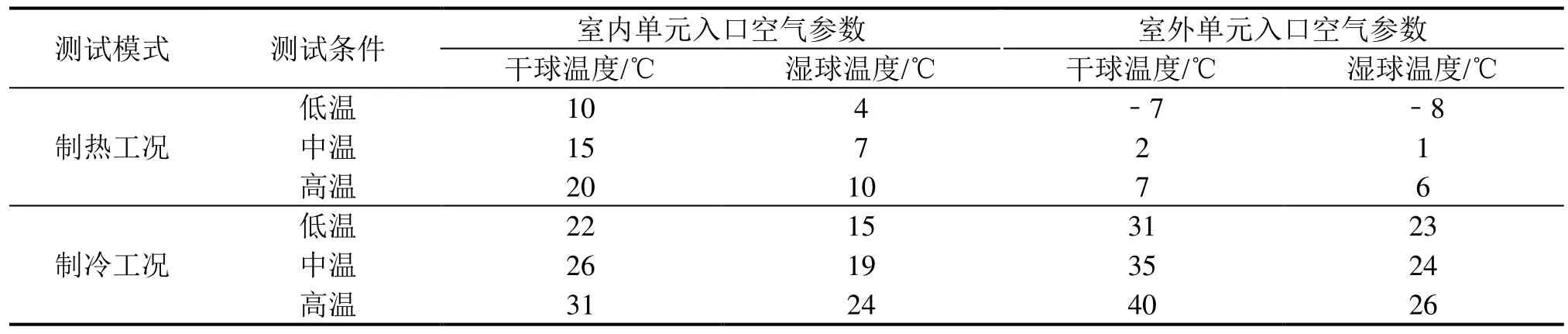
表1 系统运行工况表
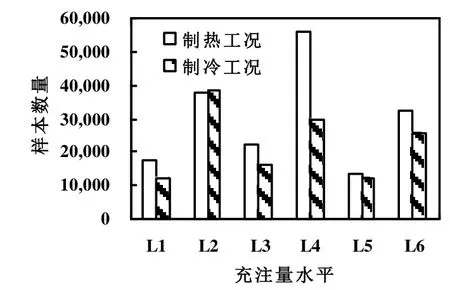
图2 不同充注量水平在两种工况上的分布
图3所示制冷剂充注故障诊断策略流程。由于实验中获得的数据往往存在缺失值和重复值,因此需要对数据进行预处理[20]。
在某些比较评价的指标处理中一般需要用到数据的标准化,一般是将数据按一定比例进行缩放,可以去除数据的单位限制,将其转化为无量纲的纯数值。实验中采用了R语言中的Scale函数进行数据标准化处理。

表2 特征变量

图3 制冷剂充注故障诊断策略流程
3 基于历史数据的多联机故障诊断
3.1 基于mRMR-RF的特征选择
利用分层抽样将数据集随机分为 70%的训练集和 30%的测试集,将训练集输入到集成 mRMR算法中,对特征变量集按照重要性进行重新排序,根据经验方法,在随机森林故障诊断模型中保持默认参数值,用训练集对随机森林故障诊断模型进行训练并检验,结果如图4所示。综合考虑模型的分类准确率和程序运行时间,取前6个特征变量时双工况下整体分类准确率已经达到98.63%,在相对更短的时间达到了理想诊断效果。两种工况下选取的6个特征变量依次为气分出管温度、电子膨胀阀开度、化霜温度、压缩机排气温度、本机当前运行能力和过冷器出液温度。
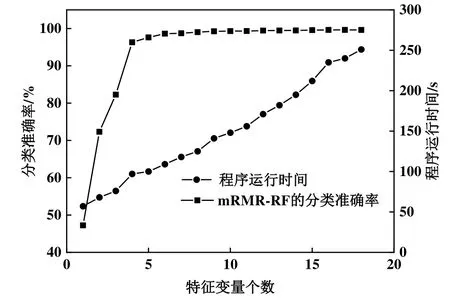
图4 双工况下分类准确率随特征变量个数的变化
表3所示为经过筛选后的特征变量之间相关性系数矩阵。原 18个特征变量中有些特征变量间相关性很大,如本机目标运行能力和本机分配能力间的相关性高达 1,对于相关性很高的两个变量,可以剔除其中一个,这样并不会对模型的泛化能力造成很大的影响。筛选后的6个变量间的相关性较小,进一步证明了特征选择后所剩余的6个特征变量的合理性。
3.2 参数寻优
网格搜索采用简单遍历给定参数组合进行参数寻优来优化模型。将模型可能的参数取值进行排列组合,所有可能存在的参数组合构成“网格”,网格搜索估计函数的参数再通过交叉验证的方式进行优化来得到最优学习算法。交叉验证可以评估统计分析、机器学习算法对独立于训练数据的数据集的泛化能力,能够避免过拟合问题。数据预处理的过程中,将数据集按照一定的比例划分成训练集和测试集。本实验中将全部数据按照 7∶3的比例划分为训练集和测试集。K折交叉验证是将训练集中的所有数据平均划分为K份,取第K份作为验证集,剩余的K-1份作为交叉验证的训练集。共得到K个评价分数,相当于训练了K次,验证了K次,然后对这K个评价分数求平均,作为最终的验证分数。
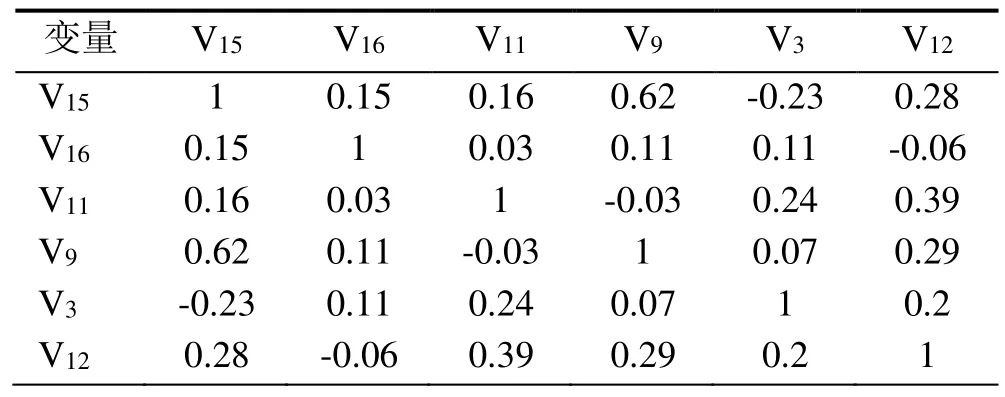
表3 筛选后的特征变量之间相关性系数矩阵
已选定6个特征变量,利用网格搜索和十折交叉验证优化3个常用的故障检测和诊断模型,分别为随机森林、决策树和支持向量机。随机森林模型优化一般选择对mtry和ntree参数进行优化,其中mtry用来确定结点中用于二叉树的变量个数;ntree可以确定随机森林中树的数目。通过网格搜索和十折交叉验证最终从mtry=c(2, 3, 4, 5, 6),ntree=c(50, 100, 150, 200,250, 300, 350, 400, 500, 750, 1,000)中确定最佳参数组合为mtry=5,ntree=300。在决策树模型中对cp参数进行优化,cp是指每一步拆分后,模型的拟合优度所必须提高的程度。对cp参数在10-8、10-7、10-6、10-5和10-4间寻优,当cp=10-5时,决策树故障诊断模型的错误率最低。支持向量机模型针对cost和gamma参数进行优化,在R语言的e1071包中,cost为惩罚因子,表示对支持向量机在优化模型时对导致模型预测效果变差的因素的惩罚力度,默认值为1。gamma是选择径向基核函数作为kernel后,该函数自带的一个参数。它隐含地决定了数据映射到特征空间后的分布,gamma值越小,支持向量越多。经过一定试算后,确定惩罚因子 cost和核参数 gamma的范围分别为cost=c(4, 5),gamma=c(4, 5, 6),最后确定 cost=5,gamma=6时模型最优。
3.3 三种模型比较评价
本文将采用均方误差(Mean Square Error,MSE)、整体检测率和单类检测率这3种标准比较3种模型的优劣,其中:
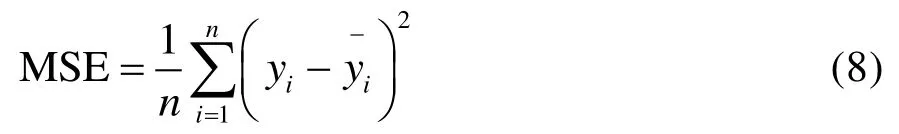
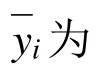
在前期的工作下,经过网格搜索和十折交叉验证对随机森林、决策树和支持向量机进行参数寻优,在最优参数的设置下,将测试集输入到3种故障检测和诊断模型中,检验3种模型对未知数据集的故障诊断效果,结果如图5所示。
由图5可知,决策树、随机森林和支持向量机这3种故障检测诊断模型对测试集的整体分类准确率分别为 92.6%、97.06%和 95.1%,3种故障诊断模型的均方误差分别为0.364、0.169和0.229。从3种模型的整体分类准确率和均方误差都说明随机森林泛化能力最好,决策树的诊断效果最差。

图5 对测试集的整体分类准确率和MSE比较
图6所示为决策树、随机森林和支持向量机对6种充注量水平的单类分类准确率比较。由图6可知,在6个充注量水平中,随机森林均显示出最好的分类效果,而决策树的仍然最差。图7所示为3个模型对测试集在6个制冷剂充注量水平上的均方误差。由图7可知,在6个充注量水平上,随机森林模型的均方误差均最小,决策树几乎在6个水平上都表现为均方误差最大,说明随机森林故障诊断模型的整体准确率上泛化能力和各单类制冷剂充注量水平上分类准确率均最好。随机森林模型对测试集的分类混淆矩阵如表4所示。
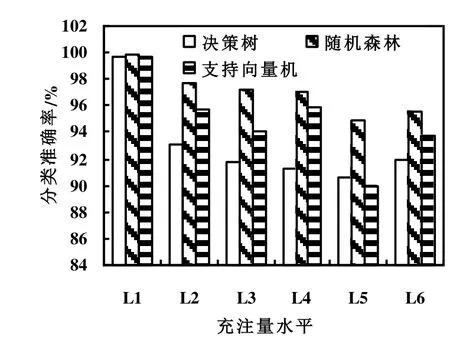
图6 对测试集的单类分类准确率比较

图7 RF、DT和SVM模型对测试集的MSE比较
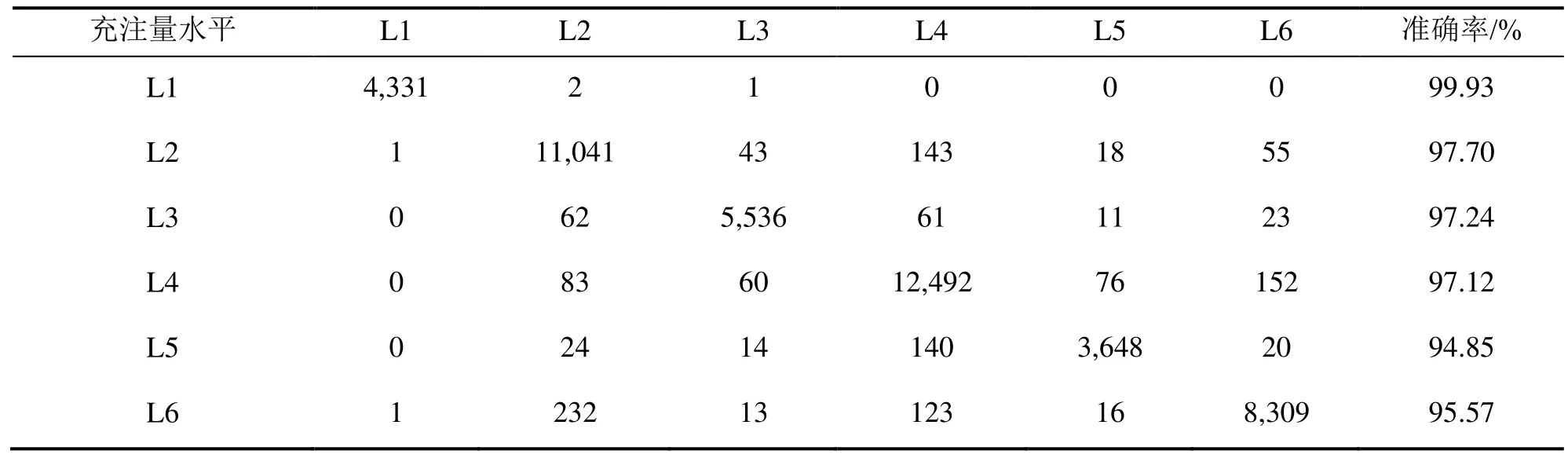
表4 随机森林对测试集故障诊断的混淆矩阵
通过对以上3种模型对比发现,随机森林故障检测和诊断模型比其他两种模型泛化能力更强,同时以上模型是将制热和制冷双工况下的数据来训练充注量故障检查和诊断模型,检测双工况下对未知数据集的故障检测和诊断效果。
图8所示为在制热工况、制冷工况和双工况下的已知数据集对诊断模型进行训练,然后分别在 3种情况下的未知数据集上进行测试。由图8可知,当训练集和测试集是同一种工况时,准确率较好,均在96%以上,用制热工况下的训练集训练出的故障诊断模型对制冷工况下故障诊断准确率为20.49%,制冷工况下的训练集训练出的诊断模型对制热工况下故障诊断准确率为28.13%;单工况下训练出的诊断模型对双工况制冷剂充注量水平诊断效果较差,但是双工况下的训练集训练出的故障诊断模型对单/双工况下的未知测试集均有较好的故障诊断效果。

图8 不同工况训练RF模型对不同工况测试集故障诊断准确率
4 基于mRMR-RF的制冷剂充注量故障在线诊断策略
通过历史数据对该模型的检验,一定程度上证明了该策略具有实际应用意义。可以使用相应的具有代表性正常操作和特定系统的故障数据来训练所提出的模型,并将该故障诊断模型纳入到 VRF系统微机控制中,可以实现实时监测、控制制冷剂充注量水平。
经过前期的工作,最终确定了原数据集中的 6个特征变量作为模型训练集的特征变量和未知实例中所需变量。对比发现随机森林故障检测和诊断模型可以获得对多联机系统制冷剂充注量水平更好的分类效果。将前面建立的随机森林故障诊断模型分别用于室内分别有5个、8个、11个和12个单元的多联机系统,进一步验证该故障检测诊断模型是否对在线数据仍然具有良好的诊断效果,如表5所示。
由表5可知,将此模型用于在线动态数据中时,对 5个室内机的多联机系统分类准确率达到95.82%,说明前文提出的随机森林故障检测与诊断策略在类似的 VRF系统上具有理想的分类性能。对于有8个和11个室内机的多联机系统,此模型的分类效果较差,分别为85.74%和88.24%,此模型对不同的多联机系统诊断准确率均在85%以上,说明该诊断策略具有强大的泛化能力和鲁棒性。

表5 对不同多联机系统制冷剂充注量的检测与诊断性能
5 结论
本文研究了多联机系统制冷剂充注量故障检测与诊断策略,构建了基于mRMR-RF的故障检测和诊断模型,进行特征选择。基于选择后的特征子集,进行参数优化,在测试集上进行验证,对3种诊断模型比较和评价,得到如下结论:
1) 采用mRMR算法进行特征选择,输入前6个特征变量时对已知数据的分类准确率达到98.63%,且运行时间适中;
2) 在经过特征选择后的训练集的基础上,随机森林、决策树和支持向量机的整体分类准确率分别为97.06%、92.6%和95.1%,且在各单类制冷剂充注量水平以及均方误差上,随机森林模型的表现最好;
3) 训练集的选择对故障检测与诊断模型的影响很大,单工况下训练的模型只能对相同单工况下的未知测试集有较好的泛化性能,而双工况下训练的模型对3类情况的未知数据均表现出较好的鲁棒性;
4) 该诊断策略对多联机系统在线故障检测和诊断具有较好的泛化性能及良好的鲁棒性。将该模型分别用于5个、8个、11个和12个室内单元的多联机系统,其分类准确率分别为95.82%、85.74%、88.24%和93.96%。
猜你喜欢
交通医学(2024年5期)2024-01-01 00:00:00
江苏安全生产(2023年10期)2023-12-18 23:48:32
甘肃科技(2020年20期)2020-04-13 00:30:56
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
中国科技博览(2018年3期)2018-01-12 11:32:58
制冷技术(2016年2期)2016-12-01 06:53:11
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
化工生产与技术(2014年2期)2014-02-27 13:41:40
