
基于长短期记忆网络的智能用电数据甄别方法
2019-03-18 02:43罗慧刘梅招周钰山张宸潘文文刘阳卫志农
广东电力 2019年2期
罗慧,刘梅招,周钰山,张宸,潘文文,刘阳,卫志农
(1. 国网江苏省电力有限公司运营监测(控)中心,江苏 南京 211100;2. 河海大学 能源与电气学院,江苏 南京 210098)
随着计算机、通信、传感器技术在电网中的广泛应用,配电网运营监测业务的不断推进以及大量监测计量装置的安装部署,电力系统在实际运行过程中产生海量的电流、电压及有功功率等时间序列数据,这些时间序列有着明显的时序性特征,随着时间的变化而变化,且彼此之间相互关联。时间序列数据中包含了丰富的电力用户用电行为信息和特征,从而为电力系统用户负荷预测、计划停电管理、电气设备检修、优化调度、合理应对大用户电力负荷变化对电网造成破坏性冲击、控制电网稳定、经济高效运行等工作的建模与预测工作提供科学的数据基础与指导依据,实现电网企业为电力用户提供个性化可靠供电服务。对这些数据的有效挖掘应用,能够进一步促进配电变压器台区的安全经济运行,同时这也是目前配电网所面临的一大挑战。
然而,在时间序列中经常出现与其他数据相比数值波动有着明显差异的观测点,也就是异常点。异常点破坏了电力系统正常运行时电流、电压和功率的变化规律与特征,在用这些异常甚至错误的数据进行其他相关业务建模与分析工作时,容易增加模型的复杂度或者降低模型的有效性,有时还会导致错误的结论。因此,有必要对时间序列中存在的异常数据进行检测与甄别,进一步采用相关数据挖掘方法对这些数据进行剔除或者再分析,从而提高数据的准确性及可利用价值,为开展用户负荷预测等其他重要业务提供科学、合理、可靠的数据保障[1-3]。
在此背景下,对异常点的检测可有效发现电表采集数据中的潜在问题,异常点检测作为一项数据挖掘手段,在智能用电系统中起到了非常重要的作用。异常数据检测可以及时发现用电数据时间序列中的异常点,恢复电力系统正常运行时电流、电压和功率的变化规律与特征,提高数据质量,并对故障电表及时进行检测和维修。
时间序列异常点检测作为一个相对成熟的研究领域,到目前为止已经出现了诸多方法,通常情况下可以分为无监督和有监督2种类型。其中,无监督检测方法主要有聚类方法,在文献[4-9]中距离聚类、密度聚类、模糊聚类等算法被提出用于寻找离群的数据点,以实现异常值检测。此类算法直观简单,但是对极值和噪声较为敏感,且模型属性构建不明确,难以设定各属性的变化范围。此外,频域谱分析法[10]、滑动窗口分析法[11]和时间序列法[12]等方法也被提出用于提升检测准确度。另一方面,有监督检测方法旨在于建立预测模型学习历史时间序列的分布规律,在此基础上判断下一时刻点是否属于合理范围内[13]。人工神经网络(artificial neural network,ANN)模型基于大量数据对网络参数进行训练,能够拟合任意复杂非线性函数映射,因此是最常用的有监督预测模型[14]。此外,在文献[15-16]中,支持向量机(support vector machine,SVM)被提出用于异常点检测,其基于结构风险最小化原则训练模型超参数,对小样本仍然具有良好的泛化能力,但其超参数范围不易选取,运行效率低。文献[17]对机场噪声时间序列降维并符号化,对时间序列进行度量并根据度量结果利用k近邻孤立因子进行异常检测,实现机场噪声单监测点时间序列异常检测,该方法减少了数据量并提高了计算速度。文献[18]为检测出正弦时间序列中的高斯噪声,对自回归模型进行改进,提出基于距离和距离因子递推最小二乘的联合异常值检测算法,但该模型运算复杂度高,实用性不强。文献[5]。提出基于边缘化后验比检验的异常值在线监测方法,并使用两窗口降低了算法的复杂度,适用于处理大量数据场景,但在参数设置上存在一定的困难。文献[19]将离散小波变换应用于异常点检测,取得了较好的结果。文献[20]为避免混淆突变点与异常点,结合线性滤波器和非线性滤波器,采用局部线性尺度近似法对异常点进行检测。文献[21]将通信网络核心性能指标时间序列分解成周期分量、趋势分量、随机误差分量及突发分量,对不同分量完成特征提取后进行异常点检测,对检测大量长期数据效率较高[22-23]。文献[24]中提出了一种基于负荷预测与关联规则修正的不良数据辨识方法,该方法能够在克服残差污染和残差淹没现象的前提下准确辨识出全部的不良数据。此外,卡尔曼滤波方法也经常被用于异常数据辨识[25]。
上述这些方法均基于统计学原理,认为异常点在模型训练过程中表现为其拟合值远远偏离真实值[19]。在此思想指导下,利用偏差的异常值检测方法,通过已知数据建立数学模型,然后依据拟合数据和真实值间误差与设定阈值的大小关系来判断该数据是否异常,其假设条件是拟合残差服从均值为零的高斯分布[15]。然而,这些传统方法诸如ANN、SVM等,均难于在大数据样本上进行训练,因而其检测精度通常难以保证。因此,本文提出了一种基于深度学习的新型预测模型,即长短期记忆(long short-term memory,LSTM)网络模型,能够更好地学习数据之间的时序关系,减少数据序列的拟合误差。本文主要贡献在于:提出一种基于深度学习的LSTM网络模型用于异常数据甄别,克服传统机器学习方法在大数据样本上性能不足的问题,进一步提升检测准确性。为充分验证本文提出方法的可靠性和准确性,分别选取人工添加噪声的时间序列和实际工程故障的时间序列样本进行测试,在无故障情况下为异常检测提供了一种可靠有效的检测依据。
1 电力系统用电数据特性
用户用电信息采集系统是用电领域最基础的、也是十分重要的系统[26-28]。该系统通过对配电台区变压器和终端用户的用电数据采集和分析,完成用电监控、推行阶梯定价、线损分析、负荷管理等业务,最终达到自动抄表、用电检查、错峰用电、负荷预测和节约用电成本等目的。实时数据采集内容主要有各相位电流、电压、有功功率、无功功率和抄表电量。其中,前4项每15 min测量一次(每日产生96个数据点),抄表电量每日测量一次。在搜集到的实际用电采集数据中,主要存在数据断点和异常点的问题。
用电异常数据是指在用电数据时间序列中经常出现与其他数据变化规律有明显差异的观测点。这些异常点破坏了电力系统正常运行时电流、电压和功率的变化规律与特征,影响了数据质量。其出现的主要原因有:读取、记录及计算时产生的错误;数据库合并重构时发生错误;特殊事件导致的畸变数据;由于计量装置故障导致量测数据出现明显误差。异常点的存在导致数据质量降低,严重影响建模过程与分析结果,不利于配电变压器台区监测正常工作的开展。通常,电网公司运营监测中心采用限定数据区间、异常事件上报和分析电压、电流、功率数据间的物理关系等方式筛选异常数据,并制定异常数据甄别规则对海量数据进行清洗。但这些手段不能有效区分计量异常导致测量误差变化而形成的异常点。针对这一种情况,本文采用LSTM网络拟合原始数据,结合偏差理论判断误差是否超出阈值,从而实现电流、电压及功率序列中异常数据的精确检测。
2 用电曲线异常数据甄别方法
本文采用LSTM网络模型用于电力系统中的用电曲线异常数据甄别,该模型属于深层循环神经网络(recurrent neural network,RNN)的一种,能够循环历史时间序列并学习曲线分布规律。该模型被广泛运用于新能源预测和电力系统电曲线拟合,包括电压、电流和功率等[29]。当实际用电曲线发生异常时,拟合数据与真实数据存在较大误差,可以通过设定阈值进行甄别。该异常数据甄别模型结构如图1所示。

图1 基于深层RNN的异常数据甄别模型Fig.1 An anomaly data discrimination model based on deep RNN
2.1 LSTM网络模型
LSTM网络模型是深层RNN的改进,通过在隐含层增加新的单元状态进行信息的传递,重新设计了计算节点,实现对远距离信息的有效控制,较好解决了梯度消失与梯度爆炸问题[30]。
RNN是由输入层、隐含层及输出层组成的全连接神经网络[31],图2所示为RNN结构展开示意图。其中:x为连接输入层的输入向量;U为输入层与隐含层的权重矩阵;h为隐含层输出,当前时刻(t时刻)输出ht由隐含层输入经权重矩阵和激活函数作用得到;V为隐含层与输出层的权重矩阵。由此可得当前时刻的输出
ot=g(Vht).
(1)
式中g(·)为输出层激活函数。

图2 RNN结构展开示意图Fig.2 Schematic diagram of unfolding RNN structure
RNN隐含层输入值在当前时刻包括2个部分:①t时刻输入xt经U作用后的值;②前一时刻t-1隐含层的输出ht-1并经权重矩阵W作用后的值。其中,权重矩阵W为前一时刻隐含层与当前时刻隐含层间的连接权重。因此,当前时刻隐含层输出
ht=k(Uxt+Wht-1).
(2)
式中k(·)为隐含层激活函数。
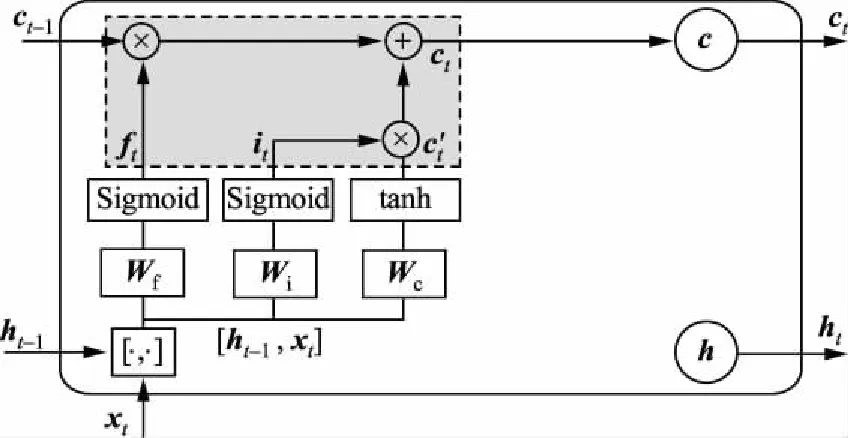
从图2中结构可以看出,RNN展开后时序关系复杂,较长的网络连接也使得模型的信息传递逐渐减少,进而导致梯度消失问题。为了解决这一问题,LSTM网络使用记忆单元状态c存储历史记忆,代替RNN的连接,提升了模型的可靠性[32-33]。LSTM网络包括记忆单元、“输入门”“遗忘门”和“输出门”,其结构如图3所示。

(a)“遗忘门”结构
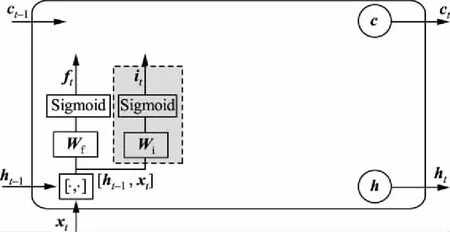
(b)“输入门”结构

(c)当前输入单元状态
(d)当前时刻单元状态

(e)“输出门”计算
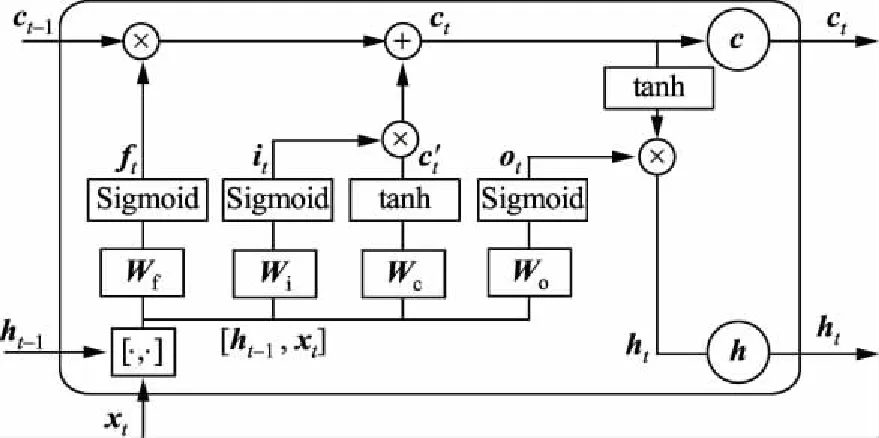
(f)LSTM网络完整结构图3 LSTM网络结构Fig.3 Network structure of LSTM
LSTM网络模型在t时刻含有3个输入:当前时刻网络的外部输入xt;前一时刻LSTM网络隐含层输出值ht-1;前一时刻单元状态ct-1。LSTM网络在t时刻含有2个输出:当前时刻LSTM网络输出值ht和当前时刻单元状态ct。
LSTM网络模型通过3个控制开关实现对单元状态c的有效控制:“遗忘门”实现对前一时刻长期状态ct-1的控制,决定前一时刻单元状态ct-1保留到当前时刻ct的程度;“输入门”实现对当前时刻输入信息的控制,决定当前时刻网络输入xt保存到单元状态ct的程度;“输出门”实现对当前时刻长期状态ct的控制,确定当前时刻单元状态ct传递到LSTM网络当前输出值ht的信息量[34-35]。根据图3,可以得到如下各“门”结构的具体计算式[32]:
a)当前时刻“遗忘门”
ft=σf(Wf[ht-1,xt]+bf).
(3)
式中:Wf为“遗忘门”权重矩阵;[ht-1,xt]表示将2个向量拼接;bf为“遗忘门”偏置项;σf(·)为“遗忘门”激活函数。
b)当前时刻“输入门”
it=σi(Wi[ht-1,xt]+bi).
(4)
式中:Wi为“输入门”权重矩阵;bi为“输入门”偏置项;σi(·)为“输入门”激活函数。
c)当前输入的单元状态c′由前一时刻LSTM网络输出ht-1及当前时刻输入xt计算,计算式为
(5)

d)当前时刻单元状态
(6)
式中符号。表示按元素乘。此时,LSTM网络将当前记忆ct′和长期记忆ct-1相结合,形成新单元状态ct。
e)当前时刻“输出门”ot受到长期记忆对当前输出的影响,计算式为
ot=σo(Wo[ht-1,xt]+bo).
(7)
式中:Wo为“输出门”权重矩阵;bo为“输出门”偏置项;σo(·)为“输出门”激活函数。
f)LSTM网络最终输出由“输出门”和单元状态共同确定的,计算式为
ht=ot。tanh(ct).
(8)
2.2 异常数据甄别具体流程
通过建立智能分析模型,可以实现对异常数据的甄别,进而提升监测数据的质量。本文使用LSTM网络模型进行异常数据甄别,流程如图4所示。

图4 基于LSTM网络的异常数据甄别流程Fig.4 Flowchart of anomaly data discrimination based on LSTM network
图4展示的异常数据甄别的具体步骤为:
a)获取历史电流、电压、功率数据曲线,以历史一定长度的点为一组时间序列,作为训练样本特征;该序列下一个时间点的数值作为样本的标签。
b)按照上述要求,将电流、电压、功率的时间序列进行滚动抽样,构成模型的学习样本库。
c)设定LSTM网络模型结构,包括LSTM网络层的个数和层节点数,模型梯度下降算法、迭代次数及目标函数等。
d)训练模型,并预测电流、电压、电压时间序列值,得到目标模拟序列。
e)将模拟序列和真实的时间序列相减,比较各点的误差绝对值,检查精度是否满足要求。
f)使用训练好的模型模拟目标电表的用电曲线,将模拟曲线与实际曲线进行比较,误差大于阈值的点为异常点。
3 算例分析
本部分基于正常运行计量装置的用电数据,使用原型聚类法、密度聚类法、概率密度法、LSTM网络模型4种方法进行测试,检验异常数据甄别精度。本研究中的故障时间序列包括人工添加噪声的时间序列和实际运行工况下的故障时间序列,通过对故障时间序列进行异常点甄别,对选出的异常点进行分析。
3.1 人工异常数据构造
已知某编号电表连续23 d的A相功率、电压、电流曲线。分别在A相功率、电压、电流曲线中加入噪声,生成100个人为异常点,异常点的位置为第1 000点至2 000点,每10点添加一个噪声点。以电压为例,在电压曲线中添加噪声为符合正态分布的均值为0,方差为0.5 V2的随机数列。含噪声电压曲线与原始正常电压曲线对比如图5所示。

图5 电压曲线添加噪声前后对比Fig.5 Comparison of voltage curves before and after adding noises
3.2 异常数据甄别模型建立与仿真
本研究中,分别采用原型聚类法、密度聚类法、概率密度法、传统神经网络法和LSTM算法进行异常点甄别,对各类方法进行参数设置,见表1。
表1 LSTM网络模型结构及参数
Tab.1 Structure and parameters of LSTM network model

模型层模型超参数训练参数个数输入层输入个数:96LSTM网络层节点数:8;激活函数:tanh320全连接层节点数:4;激活函数:sigmoid36全连接层(输出层)节点数:1;激活函数:sigmoid5
a)聚类方法参数。原型聚类法中聚类类别设置为3,异常值点判断准则阈值设置为5,聚类最大循环次数为500,距离函数采用欧式距离。将电压实际值、电压变化值作为聚类属性。密度聚类模型中最大距离设置为0.5,样本点归一化范围为(0,4),每一类别的最少样本个数为5,距离函数为欧式距离。概率密度模型采用ksdensity函数拟合电压变化率时间序列的概率分布,获得概率密度函数,结合其概率密度函数,获得电压变化率出现某一值时的概率。
b)传统神经网络模型参数。该神经网络模型为一个典型的单隐层神经网络,属于浅层网络模型,其中包含输入层(96×1序列输入)、隐含层(8节点)和输出层(1节点)。模型优化选择标准梯度下降算法,迭代次数400次,目标函数为模型输出值与真实值的均方误差。模型使用最近历史96点的数据预测下一时刻的电流值(采样间隔15 min)。
c)LSTM网络模型参数设置为4层RNN输入层、1层LSTM网络层、1层全连接隐含层、1层全连接输出层,见表1。与传统神经网络模型一致,使用最近历史96点的数据预测下一时刻的电流值(采样间隔15 min)。模型优化为带动量的随机梯度下降算法,迭代次数为400,训练样本中验证集所占比率为5%。目标函数为模型输出值与真实值的均方误差。具体模型结构见表1。
确定模型参数并建立模型后,使用未添加噪声信号的时间序列建立训练样本库,训练LSTM网络模型并学习曲线的变化规律。训练完毕后,使用LSTM网络模型滚动预测获得模拟电压曲线,将模拟电压结果与噪声电压相比较,如图6所示。可以看出,模拟电压曲线较平稳地反映出了实际电压的变化趋势和规律,与噪声电压相比,部分异常噪声点的误差十分明显。
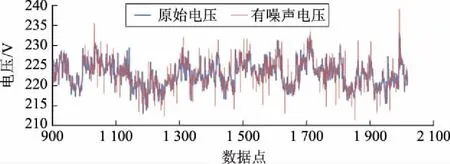
图6 使用LSTM网络模型模拟电压曲线Fig.6 Simulated voltage curves by using LSTM network model
其中,为了甄别误差较大的异常点,设置筛选异常点的阈值为电压历史数据变化幅度的5%,即1.12 V。当模拟电压与噪声电压之间的差的绝对值大于阈值,则该点电压判定为异常值。选用正确率和误判率作为指标,即
(9)
式中:kac、ker分别为检测正确率、误判率;Nb为异常点个数;NT为正确判定的异常点数;NF为判断错误的点数。
通过改变噪声大小,进行多次检测试验,可以得到检测结果见表2。
表2 异常点检测结果
Tab.2 Detection results of anomaly data

类型噪声方差LSTM网络kac/%ker/%传统神经网络kac/%ker/%电压0.5 V285.0022.7352.0056.75电压0.75 V278.0017.0259.0056.05电流0.01 A280.0023.0859.0049.03电流0.05 A282.0029.9165.0047.19功率0.01 kW257.0032.1474.0032.87功率0.05 kW274.0026.7377.0030.63平均76.0025.2764.3345.42类型原型聚类kac/%ker/%密度聚类kac/%ker/%概率密度kac/%ker/%电压55.0055.6545.0043.0477.0037.90电压58.0055.3855.0051.7564.0052.24电流60.0048.7257.0051.2867.0054.42电流66.0045.4560.0050.8271.0046.21功率77.0031.8671.0029.7073.0039.67功率78.0029.7377.0022.2278.0030.36平均65.6744.4760.83 41.4771.6743.47
从该比较结果可以看出,在不同的聚类方法中,原型聚类法检测出来的异常点个数较多,因此其误检率最高;密度聚类法不能有效检测出异常点,其检测正确率最低;概率密度法较为灵敏,可以检测出大部分存在异常的点,但仍有较大的误判可能性。对于传统神经网络模型,其检测原理是直接将历史数据输入,进而对下一时刻的电表数据点进行简单预测,无法考虑数据直接的相关性,其可行性较差。根据表2的检测结果,传统神经网络的检测正确率与原型聚类方法相近,稍高于密度聚类法;而其误检率极高,甚至超过原型聚类方法的误检率。这是由于传统神经网络仅做了简单预测,没有考虑电表数据之间的相关性。而本文提出的LSTM检测法,其中所用模型既建立了历史电表数据与未来时刻电表数据的映射关系,又同时考虑了电表数据点之间的相关性。从比较结果可以看出,本文所提方法平均检测正确率最高,达到76%;且同时具有最低误检测可能性,误检率仅25.27%。
3.3 异常数据甄别精度对比测试
为了验证异常点LSTM检测法在实际用电曲线序列中的效果,取故障电表A从2017-04-08日至2017-06-08日共计5 952点A相电压值序列。通过滚动抽样连续96点序列构建学习样本库,样本标签为序列下一点电压值,据此获得训练样本。使用该训练样本训练LSTM网络模型,并选取测试集样本评估模型性能。
在测试集样本中,使用LSTM算法对2017-06-09日第1至96点电压值进行模拟,比较模拟值与实际值。实际故障电表A电压如图7所示,在第33点至64点处电压与其余点电压相比明显偏小,且经过突变后电压恢复正常范围。确定第33点至64点为异常点,异常原因属于电压偏低,异常点甄别有效。
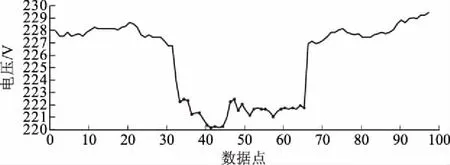
图7 实际故障电表A电压(2017-06-09)Fig.7 Voltage series of actual faulty meter A
取故障电表B从2017-04-03日至2017-06-03日共计5 856点A相电压值序列,使用LSTM算法对2017-06-04日第1至96点电压值进行模拟,比较模拟值与实际值。从图8所示的实际故障电表B电压值可以看出,在第72、74、76点处电压与其余点电压相比明显偏大,最高达到274.8 V,属于曲线的明显毛刺,且随后电压经过突变恢复正常。将其判定为异常点,异常原因属于电压异常高、电压突变,异常点甄别有效。

图8 实际故障电表B电压(2017-06-04)Fig.8 Voltage series of actual faulty meter B
同理,实际故障电表的电流和功率异常点也可以通过LSTM网络模型的模拟得出,其中电流和功率异常点检测结果如图9所示。可以看出,在故障电表的测试集样本中,第22、34、55及60点处存在异常点,其模拟值与实际值的误差超过阈值,实际反映出的异常原因为电流或功率的异常突变,与模型甄别结果一致。

图9 实际故障电表电流和功率(2017-05-02)Fig.9 Current and power series of actual faulty meter
本文研究的算例数据主要来源于电网配电变压器台区的专用变压器数据。特别是对于居民用电负荷,虽然其用电数据波动较大,但是由于其具有较为明显的日相关性和日周期性规律,LSTM网络模型能够学习这种特性并提升预测精度,进而能够有效挖掘出特定的异常点。此外,由于LSTM网络模型同时建立了历史数据与待预测数据的映射关系和历史数据之间的映射关系,克服了传统神经网络预测精度差的问题,成功地将预测方法和深度学习技术引入了异常数据甄别领域,并提升了异常检测的准确性。
通过本研究中算例分析,无论是人工添加噪声的异常曲线或是实际运行故障的异常曲线,在保证有足够量历史训练样本的前提下,本文所提出的基于LSTM网络的甄别方法都能够有效检测。此外该研究结果同时表明,在实际运行工况中若无故障曲线,可以通过人为添加噪声点构造异常曲线,以此试验异常数据甄别方法的准确性和可靠性。因此,本文提出的方法作为一种基于深度学习的异常甄别手段,进一步提升了异常检测的准确性和靠性,能够有效地指导电力系统的运行检修人员,进而及时对异常电表进行排查维护。
4 结束语
本文结合当下人工智能和深度学习领域研究热点,对用电异常数据甄别开展了如下研究:
a)获取计量装置历史电压数据曲线,以连续96点数据为一组时间序列,采用滚动抽样作为训练样本特征。样本标签设置为每一组时间序列下一个时间点数据值,构建学习样本库。同时,分别测试了人工添加噪声的时间序列和实际运行工况下的故障时间序列,充分验证了本文所提出方法的优越性。在智能电网大数据发展背景下,因电表数据采集和存储技术的不断提升,可获得大量的历史训练数据样本,为基于深度学习方法的异常数据甄别手段提供了可靠的保证。
b)提出了一种基于新型深层神经网络模型的异常数据甄别方法,即LSTM网络模型。该模型能够同时建立历史数据与待预测数据的映射关系和历史数据之间的映射关系,对目标计量装置的历史用电曲线进行有效拟合,进而获取更为准确的电力系统模拟序列。通过设定阈值并将模拟序列和真实序列进行比较,成功地将预测方法用于判断筛选异常点。
c)比较了所提出的LSTM检测方法和原型聚类法、密度聚类法、概率密度法和传统神经网络模型在异常数据中的检测正确率。比较结果显示,本文提出的模型能够对历史序列数据进行深层特征挖掘,并学习历史序列中的时序规律,克服了传统机器学习预测方法在异常检测上的不足,异常甄别准确率明显提升。该方法适用于配电变压器台区下的专用变压器用电数据和居民用电数据,能够有效地指导电力系统的运行检修人员,进而及时对异常电表进行排查维护,保证了电力系统的长期稳定可靠运行。
猜你喜欢
中学生数理化·中考版(2022年10期)2022-11-10
环球人物(2022年4期)2022-02-22
中学生数理化·中考版(2021年10期)2021-11-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
中学生数理化·中考版(2020年12期)2021-01-18
活力(2019年15期)2019-09-25
中学生数理化·中考版(2018年12期)2019-01-31
Special Focus(2019年1期)2019-01-30
小学生必读(中年级版)(2018年10期)2019-01-04
小学阅读指南·高年级版(2014年2期)2014-05-27
