
NDN中一种基于节点的攻击检测与防御机制
2019-03-17 09:36赵雪峰王兴伟易波黄敏
网络空间安全 2019年9期
关键词:信息熵
赵雪峰 王兴伟 易波 黄敏

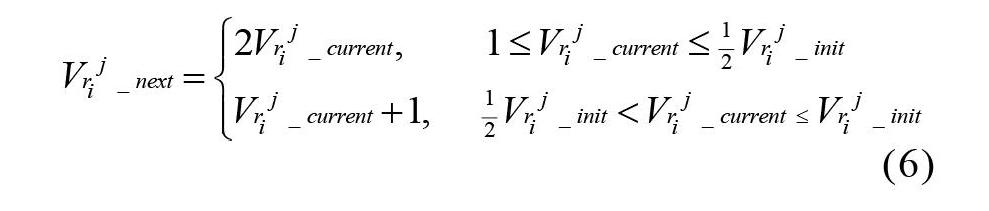
摘 要:为了解决命名数据网络(Named Data Networking,NDN)中由兴趣洪泛攻击(Interest Flooding Attack,IFA)导致的资源浪费和服务安全等问题,文章根据IFA发生时NDN网络流量的特征提出了针对分布式低速率攻击的基于节点的检测与防御机制,将其部署在可能受攻击影响最大的网络中心节点。首先设计了异常检测触发机制以减少传统周期性检测带来的资源浪费;其次攻击检测部分通过选取重要特征属性、计算信息熵以及利用K均值聚类算法训练好的模型检测异常点,避免了攻击检测的滞后性;最后通过概率替换的方法和“缓解-阻断”的方式对IFA进行防御,准确识别并删除恶意兴趣请求,快速恢复被攻击节点的服务功能,并从源头阻断后续IFA攻击。
关键词:命名数据网络;兴趣洪泛攻击;信息熵;K均值聚类
中图分类号:TP393.0 文献标识码:A
Abstract: In order to solve the problems of resource waste and service security caused by Interest Flooding Attack (IFA) in Named Data Networking (NDN), this paper proposes a node-based detection and defense mechanism of distributed low-rate attacks based on the characteristics of NDN network traffic when IFA occurs, and deploys it in the network center node which may be most affected by attack. Firstly, the anomaly detection trigger mechanism is designed to reduce the waste of resources caused by traditional periodic detection. Secondly, the attack detection part includes selecting the important feature attributes, calculating the information entropy and using the K-means clustering algorithm to detect the abnormal points, which avoids the lag of the attack detection. Finally, the method of probability substitution and the "mitigation-blocking" are used to defend the IFA, it identifies and deletes the malicious interest requests accurately, restores the service function of the attacked node quickly, and blocks the follow-up IFA attacks from the source.
Key words: named data network; interest flooding attack; information entropy; K-means clustering
1 引言
隨着互联网用户和数据的爆炸式增长以及互联网主要职能的转变[1],以内容为中心的网络应用逐渐增多[2],相对于信息的存储位置而言,用户更加关心信息的内容本身[3]。与此同时,命名数据网络(Named Data Networking,NDN)架构的成熟,使得基于NDN的各项研究也不断地引起大家的广泛关注。在安全方面,其屏蔽了传统网络下的拒绝服务攻击(Denial of Service, DoS)的同时,却引入了新型的安全问题兴趣洪泛攻击[5],其是针对NDN中包转发机制存在的安全漏洞进行攻击。
目前,关于兴趣洪泛攻击(Interest Flooding Attack,IFA)的检测与防御问题已经引起学术界的广泛关注,陆续出现了相关的解决方案,但是在准确识别,快速防御等方面仍有待改进。首先,当前研究中大多数对IFA的检测主要是基于路由器节点的PIT异常状态进行统计分析判断,该类检测方案具有滞后性。其次,目前的方案可能容易对正常流量波动过度反应,比如当有突发的正常流量时,也会对PIT表的统计特征造成影响。再者,目前几乎所有的方案都是针对网络中所有的节点进行检测,不具有针对性,检测粒度有待优化。基于上述原因,IFA的应对机制仍具有进一步研究的意义。
此外,目前的方案中很少研究如何准确识别恶意兴趣请求,这在后续的防御效果中有着至关重要的作用,精确的识别可在一定程度上减少对正常突发流量的误判以及更好的进行攻击防御,这一部分也迫切需要进行进一步的研究。
针对目前IFA攻击面临的问题挑战[6]以及一些解决方案所存在的如检测滞后性、检测粒度不具有针对性、资源浪费等问题,本文选择分布式低速率攻击,在网络中心节点设计并部署了一种基于节点的检测与防御机制,减少了周期性检测带来的资源浪费问题,避免了滞后性问题,并且能够准确识别恶意兴趣请求,从源头阻断IFA攻击,以快速恢复被攻击节点的服务功能。具体研究工作主要包括设计了以下机制:异常检测触发机制、基于信息熵和K均值聚类的攻击检测机制、基于概率替换的恶意兴趣请求识别机制、“缓解-阻断”防御机制,并对所提机制进行仿真实现以及性能评价。
2 兴趣洪泛攻击原理
NDN中的兴趣包基于内容名称前缀进行路由,并通过内容名称获取数据,因此攻击者无法轻易地直接针对特定中间节点或者终端发起攻击。但是,攻击者可以针对特定的命名空间发起攻击,在兴趣包寻路过程中造成网络中间节点拒绝服务[7]。IFA正是一种针对特定命名空间发起攻击的方式。
IFA基本工作原理如图1所示。如果内容提供者是“/Root/good”命名空间的独占所有者,则路由器B和内容提供者都将收到“/Root/good/ ...”的所有兴趣,且无法被网内缓存满足。大量此类恶意兴趣通过造成网络拥塞或耗尽路由器节点上的资源造成合法兴趣请求和数据包丢包,从而破坏网络整体的服务质量。而且,由于NDN中的兴趣包既不携带源地址也不需进行签名认证,很难立刻确定攻击源并采取相应的应对措施,因此会对网络造成非常大的攻击力和破坏力[8]。
IFA将会造成网络服务质量下降甚至是网络服务瘫痪,其有两种主要原因。第一,与传统网络中的数据包类似,NDN中的兴趣包也会消耗一部分网络容量。因为NDN中的路由基于名称前缀,通过针对一个特定的命名空间可将大量攻击流量集中在网络的某些段中,大量恶意兴趣包可能会导致拥塞并导致合法兴趣包被丢弃,影响网络服务性能。第二,由于NDN路由器维护每个转发兴趣的每个数据包状态,即其存储在未决兴趣请求表(Pending Interesting Table,PIT)中的信息,过多的恶意兴趣请求可能造成节点的内存被耗尽,从而使得该节点无法继续为传入的兴趣请求创建新的PIT条目,导致合法兴趣包被丢弃,影响为合法用户提供网络服务。
3 基于节点的攻击检测与防御机制
本文基于节点的IFA攻击检测与防御机制主要是针对分布式低速率的兴趣洪泛攻击情形。在这种攻击情形下,由于流量的汇聚,靠近内容提供者或者中心位置的网络节点的PIT条目数增长迅速,最先使得PIT缓存溢出,从而造成中心节点拒绝服务,造成合法兴趣请求丢包,影响巨大。
本节首先分别介绍了该机制包含的四大模块即异常检测触发、基于信息熵和K-means聚类算法的攻击检测、恶意兴趣请求的识别以及攻击防御。该方案的具体实现过程有四个步骤。
(1) 首先通过监控PIT的占用率来触发攻击检测。
(2) 一旦IFA检测触发,则计算PIT属性内容名称前缀、入口编号和兴趣请求条目的被访问频次的信息熵值,输入到已经训练好的分类器中,进行异常点识别。
(3) 利用概率替换方法识别出具体的恶意兴趣请求前缀,通过分析攻击流量的特征筛选特征属性的值,识别出具体的恶意兴趣请求条目。
(4) 当检测出具体条目后,立即删除并生成与其具有相同内容名称的报警数据包,该报警数据包将回溯到攻击者终端,沿路限制接口速率阻断攻击。
本文根据NDN中包处理机制,结合本文提出的方案,设计了基于节点的IFA检测与防御机制下的包处理流程。
3.1 异常检测触发机制
为了避免现有方案中周期性收集PIT表项时间间隔太短和太长带来的大量计算资源消耗和检测滞后问题,在对PIT表项进行收集并检测之前应添加异常检测触发机制,当满足检测触发条件时才收集PIT条目进行分析检测。而且,这种触发机制应该满足易检测并且容易实施的条件,尽量减少路由器节点的负担。
IFA最显著的影响就是占用路由器节点大量的PIT缓存资源,造成PIT溢出,此观点已有多篇文献指出并验证,故本文采用PIT条目占用率作为异常触发的指标,PIT占用率的计算如公式(1)所示。其中表示PIT条目的占用率,用于表示其阈值。表示PIT现有的PIT条目数,表示PIT中可缓存的条目总数。
(1)
3.2基于信息熵和K-means聚类的攻击检测机制
本节详细介绍了基于节点流量统计的IFA攻击检测机制的设计。首先,分析了特征选择、信息熵的引入和计算。其次,通过实验数据验证了引入信息熵进行处理的合理性和可行性,并且利用K-means算法对原始数据进行多次迭代训练,得到攻击检测的分类器模型。最后,将进行多组实验对比得到的分类器模型进行检验和分析,并且对基于信息熵和K-means聚类算法的IFA检测方案的优势、缺陷以及产生的原因进行分析与说明。
(1)特征属性选择
IFA发生时,恶意兴趣请求填满PIT,此时,PIT中的条目分布必然呈现出异常状态,因此本文涉及的属性主要指PIT表项中的各属性值。PIT是用于记录已从该节点转发出去但还未获得数据响应的兴趣包的入口接口等属性的集合。
由于针对不存在的内容进行攻击时,攻击者可利用完全伪造的内容名称,也可利用前缀合法后缀随机的内容名称,这将导致PIT中内容名称项的随机性增加。与此同时,恶意兴趣请求大都来源于特定的某些端口,使得PIT中各条目的入口分布变得集中。再者,PIT中兴趣请求条目的匹配次数几乎都为1,因为攻击发生时,PIT中充斥大量的恶意兴趣请求,根据恶意兴趣请求的唯一性,该请求条目大多只被访问并匹配一次。综上所述,本文选择内容名称、入口以及PIT条目的匹配次数三个属性作为后文聚类分析的特征属性。
(2)信息熵的计算
本文的聚类算法主要是分析IFA发生前和发生后PIT条目各属性的变化趋势,而非PIT条目各属性的内容值。本文引入已被广泛应用在异常检测[9-12]的信息熵表征流量变化趋势,这有利于从根本上反应IFA对网络的影响。而且,本文所采用的K-means算法更适用于数值型数据,引入信息熵将各类型数据转化为数值型,这有利于提升IFA检测的准确率,下文首先对信息熵计算进行介绍,然后从信息熵的角度,通过实验数据分析以上三个属性在攻击前后的熵值变化情况,以论证方案的可行性。
给定一个集合X=(X1, X2,… XN),表示采集的PIT中各個特征属性下的内容数据的集合。每个属性中包含个类,表示属性中类的概率,其中,,, 则信息熵的定义如公式(2)所示。本文实验中,每100条PIT条目计算一次熵值。
(2)
以上三个特征属性即内容名称、入口以及PIT条目的匹配次数的信息熵计算如公式(2)所示,其中概率计算公式如式(3)所示,表示PIT中一组兴趣请求条目的总数,本文将该值设为100, 表示具有某相同特征属性的兴趣请求条目的数量。
(3)
内容名称前缀属性:IFA发生前,因为PIT中内容名称前缀分布相对均匀,随机性较高,熵值较高。当IFA发生时,攻击者短时间内发送大量内容名称前缀相同且后缀为随机产生的字符串的恶意兴趣请求。恶意兴趣请求的注入使得内容名称前缀的分布突然变得集中,不确定性下降,相应地信息熵急剧下降。此外,如果攻击者发送大量含有完全伪造的内容名称的恶意兴趣请求时,此时的内容名称前缀分布更加随机。相比攻击前来说,不确定性上升,相应地信息熵将急速上升。也就是说,不论以任何一种方式发起攻击,熵值的突变是必然的,而本文所需要的也只是熵值突变带来的差异而不是依赖具体的熵值大小。因此,不论熵值急速上升亦或是下降本文的方案均可适用。
如图2所示,为内容名称前缀信息熵的变化。图中0-100s以及200-300s没有攻击,200-300s发起兴趣洪泛攻击,恶意Interest的内容名称采用的是内容名称前缀合法而后缀为伪造的随机字符串。由图1可知,在100-200s之间发生攻击时,PIT内容名称前缀的熵值的确迅速降低,而且,在攻击期间都维持在较低值。
入口属性:当IFA攻击发生时,对于每个节点而言,如果假设接口一定,恶意兴趣请求的入口id一致,此时入口的随机性较低,信息熵值较低;如果假设接口数量不一定,即发生攻击后,恶意兴趣请求可能来自多个全新的接口,入口属性的随机性较高,信息熵值增大。本文更多关注的是熵值变化引起的熵值检测点之间的差异性,而非依赖具体的信息熵值的大小。此外,本文假设对每个内容名称前缀所采取的转发和路由策略一致,则出口和入口属性值的分布一致,熵值变化一致,所以,本文只讨论入口属性的熵值变化。
如图3所示,在接口数量不一定的情况下,IFA攻击前后入口属性信息熵值的变化情况由图可得,在100-200s期间发生IFA攻击时,信息熵值直线上升,并且,在攻击期间,熵值一直处于较高水平。
匹配次数属性:由于恶意兴趣请求是唯一的,故恶意兴趣请求记录在PIT条目后将只被访问一次,而合法的兴趣请求条目可能被不同的合法用户多次访问。因此,当发生攻击时,大量恶意兴趣请求条目缓存在PIT中,导致大多是PIT条目的匹配次数属性值为1,这将导致匹配次数属性值随机性会迅速下降,信息熵值也因此迅速减小,并且,在攻击期间信息熵值一直维持在较低水平。
如图4所示,为PIT中匹配次数属性的信息熵值的变化趋势。当发生IFA攻击时,熵值迅速下降,在100-200s攻击期间,熵值维持在较低值。
综上,可分别计算出一段时间内三个属性的信息熵值、和,表示为点,下一步的K-means聚类检测分析将针对这些熵值点进行异常检测分析。
(3)K-means聚类检测分析
本文实验模拟了300s,其中100-200s为攻击发生时间。首先收集了各个特征属性下的PIT条目,然后对每100条条目进行信息熵的计算,生成一系列熵值点 ,由于在发生攻击时,三个属性的信息熵值均发生明显变化,通过三个特征属性的相互作用,发生攻击时和没有攻击时的熵值点差异较大。经过信息熵值处理的原始数据可明显分为两类,数据簇呈凸型分布且距离特征明显,非常符合K-means应用条件。
基于K-means聚类检测的原理是通过对原始数据进行训练得到分类器。在实际检测中,当异常检测触发后,收集PIT表项,计算熵值点并输入到分类器模型中进行异常检测。在训练与检测时,通过欧几里得距离判断熵值点之间的相似性。假设被检测点为 ,簇心为 ,则可通过两点之间的欧几里得距离判定点 是否归为点 所在的簇,欧几里得计算如公式(4)所示。为了训练得到可靠的分类器模型,本文收集Node1上的流量数据迭代1000次进行K-means聚类。
(4)
通过分析攻击前后PIT属性值的变化规律,对PIT条目进行信息熵值的处理以及利用K-means对数据进行熵值聚类的效果较为理想,虽然仍然存在一些离散点,但是离散点数量很小,这些离散点的存在可能是因为在攻击前期PIT属性值的分布特征不明显或者某一时刻恶意请求超时删除所致。
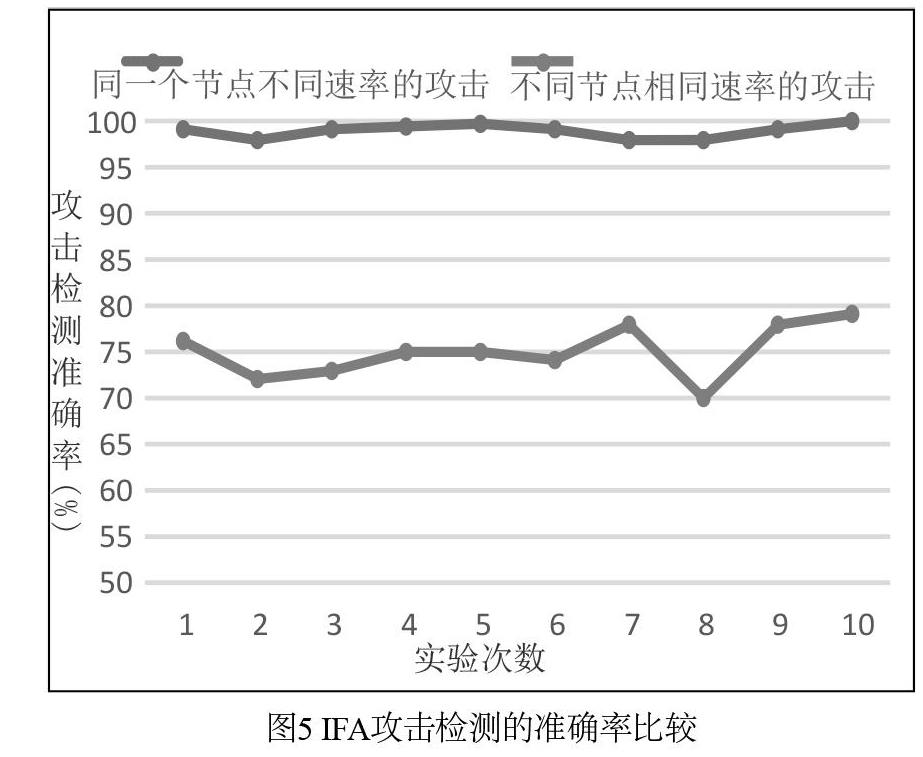
此外,为验证模型的可靠性和应用广泛性,本文进行了两组对比实验。对比实验一:调整攻击者和消费者的发送速率且仍在Node1上部署检测方案。对比实验二:在不同节点上(本文实验采用图6拓扑中节点Node3中的流量数据)部署检测方案。每组对比实验分别进行10次实验,统计两组不同方式下的攻击检测准确率,检测结果如图5所示。其中,对比实验1的结果如图中上方曲线所示,对于同一个节点,改变攻击速率,利用得到的模型进行攻击检测,效果较好,根据MCR参数统计,检测准确率基本分布在99%左右;对比实验2的结果如图中下方曲线所示,攻击检测的准确率较低,检测准确率主要分布在72%左右。
为了寻找上述结果产生的原因,本文多次收集了Node3上的流量数据进行分析并训练得到分类器模型。分析发现不同节点上的熵值变化一致,均可根据熵值差异在该节点高准确率的检测出IFA,但是,同样地,该分类器模型并不适用于Node1。根据Node1和Node3中统计的熵值的分析得出造成上述结果的原因:虽然相对于一类节点而言,攻击前后熵值变化明显,但是每一个PIT特征属性下的类别多样性不同(如:中心节点内容名称前缀的类别可能较多,而邊缘节点的内容名称前缀的类别可能就较少)造成了信息熵值量级的不同。但是,这也是由于实验规模的限制造成了节点之间的差异性,在真实网路环境中,随着网络规模的增大,流量数据的多样性增加,这种差异性将会减小。
3.3 恶意兴趣请求识别机制
需要注意的是,为了针对特定命名空间发起有效的攻击,攻击者发布的兴趣请求需满足两个条件。
一是发起的兴趣请求应尽可能地传递给生产者,而不是被网内缓存满足。这要求兴趣请求不能被中间路由器的网内缓存满足,因为如果兴趣请求可以从中间路由器的内容存储区满足,则被请求的内容从中间路由器返回给请求者,兴趣包将不向上游转发兴趣请求,无法发生IFA。
二是保证每个恶意兴趣请求都能创建一条新的PIT条目,并保证其以尽可能长的时间存储在中间节点的PIT中。这要求每个恶意兴趣包请求唯一的且相互不同的内容信息,否则所有请求相同内容的兴趣请求将在节点被聚合成一个PIT条目,无法发生IFA。
考虑到以上必须满足的条件,攻击者必须请求流行度较低的(即未在路由器中缓存)或不存在的唯一内容,这两种情形的实现难易程度不同,前者维持一段持续的大规模IFA攻击难于实现,故本文专注于第二种影响范围广且易于发起的IFA攻击模式,并且选择内容名称前缀合法而后缀随机的形式进行攻击实现,因为它不仅最大化了攻击的影响,而且易于发起并广泛适用于针对所有命名空间的攻击。
以下将针对检测到的IFA进行恶意兴趣请求识别,首先基于信息熵识别出恶意的兴趣请求前缀,然后从中进一步的识别恶意请求条目。
(1)识别恶意兴趣请求前缀
一旦基于信息熵的检测机制检测到IFA,将触发基于信息熵的恶意兴趣请求识别过程以保护合法流量不受影响,因此,本文NDN路由器记录几个连续时间间隔的兴趣请求前缀分布,以便分析识别恶意兴趣请求前缀。当触发恶意兴趣请求识别机制时,分别在集合S1和S2中记录检测到攻击时和攻击发生之前PIT中的兴趣前缀。计算S1和S2中每个兴趣前缀i的概率,分别表示为P1(i)和P2(i)。首先利用P2(i)计算H(S2)。然后,对于S2中的每个兴趣前缀i,通过用P1(i)代替其概率P2(i),得到新的概率分布P2,从而得到新的信息熵表示为Hi(S2)。之后,使用公式(5)来计算兴趣请求内容名称前缀i引起的信息熵变化。
(5)
通过迭代每个前缀,可以获得一系列的 。由于恶意兴趣请求前缀的注入使得S2中原始前缀的分布更加集中,因此加入了新前缀的原始集合的信息熵值将会变小。综上所述,使得 成立的前缀被认为是恶意前缀。
(2)识别恶意兴趣请求条目
为了后续攻击防御时生成伪造的报警数据包Data,需知道恶意兴趣请求的内容名称。但是,当检测出恶意兴趣请求前缀后并不能确定恶意兴趣请求条目,因为本文的IFA场景是利用合法的兴趣请求前缀和伪造的随机后缀字符串发起攻击,所以在检测出的恶意兴趣请求前缀中可能混合了合法的兴趣请求,因此,为了避免对合法兴趣请求的过度防御,必须筛除合法的兴趣请求。因此,我们必须在识别出的恶意前缀的基础上做进一步的筛选。
据此,本文同样利用PIT条目属性的分布特征来解决这一问题。恶意兴趣请求条目的匹配次数属性均为1,而合法兴趣请求因为可能有不同用户请求相同的内容,该值可能不为1。根据这一特性,本文通过筛选匹配次数的值来排除大部分的合法兴趣请求,即若PIT条目的匹配次数为1,则为恶意兴趣请求,否则为合法兴趣请求。在此,需要提到的是对于一些冷门或者一次性的内容如邮件,虽然其匹配次数属性也为1,但对于不带恶意前缀的条目则在第一步骤可能就被筛选过了,不会进入此步。对于此种特殊情况,也可能会存在部分误判。
3.4 基于节点的攻击防御机制
基于节点的IFA防御机制的主要思想“缓解-阻断”。其中,缓解的主要目的是当发生IFA后,及时识别出恶意兴趣请求条目并删除,以迅速恢复网络中的节点功能,阻断的主要目的是切断攻击源,从根本上阻断后续攻击,其通过伪造报警包回溯攻击者实现。
根据NDN中对称路由的特性,伪造的报警包会按照恶意兴趣请求的路径原路返回,追溯到攻击者。当伪造的Data到达中间路由器时,将删除PIT中与其匹配的大量恶意请求,及时恢复网络功能。同时,根据传统网络中拥塞控制的思想,调整出口的速率,限制恶意兴趣请求继续转发扩散。
当定位到具体的被攻击接口后,引入传统TCP/IP网络中控制网络拥塞的加性增乘性减(Additive Increase Multiplicative Decrease,AIMD)思想进行接口速率限制。假设路由器节点i的接口j的初始速率为,当检测到攻击时,将接口接收速率迅速减少为1,然后如公式(6)的上半部分所示,随着时间的推移,接口的速率按指数规律增长即速度值依次为1、2、4、8等。当速率达到初始速率的一半时,如公式(6)的下半部分所示,接口的接收速率按“加性”增长进行加一操作,直至接口的速率恢复到初始速率。
(6)
3.5 算法描述
由于在NDN中,只支持兴趣包和数据包两类报文,数据的传送过程首先由消费者发送兴趣包,然后数据包沿着相反的方向、相同的路径返回,其转发机制相对IP网絡是智能转发,弱化了路由作用。
因此本文将所提出的基于节点的攻击检测和防御方案应用在NDN中智能的包转发机制上,设计了基于节点的IFA检测与防御机制下的包转发和处理过程。该过程涉及到对合法兴趣包、恶意兴趣包、合法数据包以及报警数据包的处理,在对各个包的处理过程中包含了本文基于节点的攻击检测与防御机制的具体策略。算法3.1为在包转发和处理过程中基于节点的攻击检测机制,包含了异常触发机制、攻击检测机制、恶意兴趣请求识别机制,算法3.2为基于节点的攻击防御机制。
基于节点的IFA检测与防御机制下的包转发和处理过程如下:
(1)节点判断接收报文并判断是否是兴趣请求包。若是,则转向对兴趣包的处理。即首先查看CS表中是否有对应的内容信息,若存在,则兴趣包是合法的,直接将内容信息返回给消费者;若不存在,则查PIT中是否有与之相对应的条目,若有,则需要将入口添加到对应的PIT条目的入口列表中,防止兴趣包的重复发送,否则插入新PIT条目,并更新PIT占用率。当PIT占用率 超过阈值时,执行攻击检测机制,包括数据筛选、信息熵的计算、以及异常点的判断。如果通过分类器模型检测到异常点,则进一步执行恶意兴趣请求前缀的识别并筛选出恶意PIT请求条目,从而执行算法3.2的攻击防御策略。
(2)若不是,则转向对数据包的处理,即接收该数据包的数据并查找PIT表,若在PIT中未找到匹配的条目,则将数据包作为重复数据包而丢弃。如果匹配条目中列出了多个接口,首先判断是否是用于攻击防御的伪造的数据包,若不是,则作为合法的数据包进行处理,若是,则转向步骤(3)对伪造的报警数据包的处理。
(3)由于伪造的报警数据包的内容名称字段和恶意兴趣请求的内容名称相同,则将其作为恶意兴趣包按照算法3.2进行处理。
算法3.1 基于节点的攻击检测算法
输入: 节点接收的报文 msg ;
输出: 得到统计信息, 如PIT条目中出/入兴趣包、出/入数据包、丢弃的兴趣包数量;
1. 初始化Ρ; // Ρ为阈值
2. IF msg 是兴趣请求包 THEN
3. IF CS表中存在对应的内容信息
4. 兴趣包合法,直接将内容信息返回给消费者;
5. ELSE
6. IF 查找PIT中有对应的条目 THEN
7. 将入口添加到对应的PIT条目的入口列表中;
8. ELSE
9. 插入新PIT条目;
10. 根据公式(1)计算并更新PIT占用率ρ;
11. IF ρ>Р THEN //PIT占用率超过阈值
12. 筛选PIT条目的特征属性数据;
13. 根据公式(2)(3)计算信息熵记为 (x1,y1,z1);
14. 输入(x1,y1,z1) 到训练好的用于异常点检测的 分类器中;
15. IF (x1,y1,z1) 属于异常点 THEN
16. 得到,并据公式(2)计算熵值 ,;
17. ;
18. IF THEN
19. 得到恶意前缀i ;
20. IF 前缀i 的PIT条目的匹配次数属性 为1 THEN
21. 识别为恶意兴趣请求;
22. 恶意兴趣请求条目作为输入执行算 法3.2;
23. END IF
24. END IF
25. END IF
26. END IF
27. END IF
28. END IF
29. ELSE IF msg 是合法數据包THEN
30. 接收该数据包的数据并查找PIT表;
31. IF PIT中有请求该数据的兴趣请求 THEN
32. CS 中缓存数据信息;
33. 找到PIT中对应的兴趣请求入口,将数据从该 接口转发给消费者;
34. ELSE
35. 丢弃数据包;
36. END IF
37. END IF
38. ELSE IF msg 是报警数据包
39. 提取报警数据包的内容名称;
40. FOR PIT中的每个条目 Do
41. IF 报警数据包的内容名称匹配用于攻击防御 的伪造数据包的内容名称 THEN
42. 报警数据包的条目信息作为输入执行算法3.2;
43. END IF
44. END FOR
45. END IF
算法3.2 基于节点的攻击防御算法
输入:恶意兴趣请求条目的信息;
1. 初始化 Δt, Flag[]; //Δt表示执行限速策略时速率的调整周期,Flag[]用于標记接口是否正处于防御状态
2. 获取恶意兴趣请求的内容名称以作为报警数据包的内容名称字段;
3. 获取恶意兴趣请求条目入口列表中的入口编号i;
4. 向接口 i 返回报警数据包回溯攻击者;
5. IF THEN //不在防御状态,执行限速策略
6. ;
7. 将接口速度迅速减为1
8. FOR 每个调整周期 Δt Do
9. IF < THEN
10. ;
11. ELSE IF < THEN
12. ;
13. ELSE
14. ;//正处于限速,不做处理
15. break;
16. END IF
17. END FOR
18. END IF
19. 删除恶意兴趣请求条目
4 性能评价
本文对基于节点的攻击检测与防御机制进行了仿真实验和性能评价。先介绍了实验的仿真环境,包括实验平台、兴趣洪泛攻击场景以及实验拓扑;其次给出评价指标的定义,并借此验证本文设计方案的有效性;最后与现有IFA攻击应对方案进行比较分析,验证了本文方案的优势。
4.1 仿真环境
由于命名数据网络还处于探索和研究阶段,目前还未正式投入使用,因此本文所提出的方案目前只能在模拟环境中实现。本文的网络模拟主要基于ndnSIM平台,采用版本ndnSIM2.1,运行在ubuntu14.04之上。
为了模拟影响范围较广而且最易实现的IFA,本文通过合法的内容名称前缀和伪造的后缀来伪造恶意兴趣请求的内容名称,从而发起攻击,模拟IFA场景。
本文实验采用的拓扑为小规模二叉树拓扑,如图6所示,其中深色用户表示攻击者,本文在不同位置总共设置三个攻击者,可用于模拟分布式低速率的IFA攻击,浅色用户表示合法用户。此外,拓扑图中还包括一个内容提供者以及7个内容路由器。在路由器节点中,在中心节点Node1处部署本文设计的IFA攻击的检测与防御机制,使其解决的是IFAs攻击影响最严重的情况。
4.2 有效性分析
本文根据有无攻击以及有无防御策略划分了三种情景,并从PIT占用率、合法兴趣请求满足率以及合法兴趣请求丢包率三个指标分析本文方案的有效性。
(1)评价指标
1)PIT占用率
PIT占用率可从根本上反应IFA攻击对节点的影响程度.计算公式如式(7),其中表示PIT条目的占用率,表示PIT中可缓存的条目总数,表示节点中PIT当前缓存的PIT条目数。
(7)
2)合法兴趣请求满足率
合法兴趣请求满足率可表征当前节点对用户请求的响应能力。计算公式如式(8)所示,表示节点收到的合法兴趣请求总数,表示节点收到的合法数据包总数。
(8)
3)丢包率分析
合法兴趣请求丢包率可反映当前节点的状态,其计算公式如式(9)所示。其中,表示节点收到的合法兴趣请求总数,表示节点丢弃的合法兴趣请求总数。
(9)
(2)性能评价
1)PIT占用率
如图7所示Node1的PIT占用率变化趋势。由蓝色曲线变化趋势可知,当没有攻击发生时,PIT条目占用率基本维持在15%左右。NDN中兴趣请求内容名称的聚合机制、数据包返回后合法兴趣请求条目将被删除的机制以及超时机制等因素都将使PIT的缓存将维持一个稳定的值域内,而且该值不会过高,属于正常现象。由红色曲线变化趋势可知,当在100s发起分布式低速率的IFA时,PIT的占用率几乎呈直线迅速上升平均达到100%。当200s停止攻击时,PIT占用率将快速恢复常态,这是因为PIT条目超时会自动删除,也体现了NDN中节点的自恢复能力。由图中绿色曲线变化趋势可知:当安装了本文的防御方案之后,即使发生攻击,在PIT缓存未溢出时便迅速下降至20%,这避免了PIT因为缓存溢出而丢弃合法用户的兴趣请求包而无法提供正常服务。由此可见,本文基于节点的策略是有效的。
[6] 李杨,辛永辉,韩言妮等.内容中心网络中DoS攻击问题综述[J].信息安全学报,2016,2(1):91-108.
[7] Pang B, Li R, Zhang X, et al. Research on Interest Flooding Attack Analysis in Conspiracy with Content Providers[C]. The 7th IEEE International Conference on Electronics Information and Emergency Communication (ICEIEC). Macau, China: 2017. 543-547.
[8] Choi S, Kim K, Roh B H, et al. Threat of DoS by Interest Flooding Attack in Content- centric Networking[C]. The International Conference on Information Networking. Bangkok, Thailand: 2013. 315-319.
[9] Lee W, Xiang D. Information-theoretic Measures for Anomaly Detection[C]. IEEE Symposium on Security and Privacy. Oakland, USA: 2001. 130-143.
[10] Yuan Z, Zhang X, Feng S. Hybrid Data-driven Outlier Detection Based on Neighborhood Information Entropy and its Developmental Measures [J]. Expert Systems with Applications, 2018, 112: 243-257.
[11] Chen Z, Yeo C K, Lee B S, et al. Power Spectrum Entropy Based Detection and Mitigation of Low-rate DoS Attacks [J]. Computer Networks, 2018, 136: 80-94.
[12] Koay A, Chen A, Welch I, et al. A New Multi Classifier System Using Entropy-based Features in DDoS Attack Detection[C]. IEEE International Conference on Information Networking (ICOIN). Chiang Mai, Thailand: 2018. 162-167
作者简介:
赵雪峰(1996-),女,汉族,新疆哈密人,东北大学,硕士;主要研究方向和关注领域: 软件定义网络、网络安全。
王兴伟(1968-), 男,汉族,内蒙包头人,东北大学,博士,教授;主要研究和关注领域:未来互联网、云计算、网络空间安全。
易波(1988-),男,汉族,湖北天门人,东北大学,博士,讲师;主要研究方向和关注领域:网络功能虚拟化和服务链。
黄敏(1968-),女,汉族,辽宁沈阳人,东北大学,博士,教授;主要研究方向和关注领域:智能算法设計与优化、调度理论与方法。
猜你喜欢
青岛大学学报(工程技术版)(2019年1期)2019-09-10
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
中国水运(2017年1期)2017-02-27
中国水运(2016年11期)2017-01-04
电脑知识与技术(2016年27期)2016-12-15
犯罪研究(2016年5期)2016-12-01
科技与创新(2016年18期)2016-11-04
中小企业管理与科技·中旬刊(2016年6期)2016-06-20
考试周刊(2016年15期)2016-03-25
电脑知识与技术(2016年2期)2016-03-22
