
基于大数据Hadoop的股票利润分析平台设计与实现
2019-03-15 01:30张鲁奥
电子制作 2019年4期
张鲁奥
(山东省章丘市第四中学,山东章丘,250200)
1 研究背景
随着大数据技术的蓬勃发展,越来越多的数据等着我们去识别,读取,归类,计算。针对于股票市场,如何利用大数据技术去发掘股票中隐含的众多有价值的信息,帮助股民合理购买股票,获得最大利润是我们急需解决的难题,目前在股票领域的大数据研究尚不完善。因此,我们提出利用hadoop分布式框架来对每只股票的利润进行分析的方案,用到的主要技术是分布式并行计算(mapreduce)和分布式文件存储系统(HDFS)。对于每只股票的数据会冗杂在一起,形成庞大的数据量的情况,目前比较主流的海量数据存储系统主要采用HDFS文件系统。在本文中我们把每只股票的相关信息存储在HDFS文件中,然后读取出来,通过MapReduce对股票数据进行分析。
目前,在股票行业中,每支股票每天产生的数据量难以预估,隐含的有价值的信息难以提取,如,开盘时间,闭盘时间,开盘价格,闭盘价格,多个特征中如何提取有用信息,如何有效准确的计算股票数据,在该领域的研究还有待完善。对于股票数据的分析处理问题,我们提出了合理可行的方案,基于Hadoop的并行式计算框架运用了HDFS存储机制和Mapreduce的并行式运算,可以有效合理的解决上述问题。基于hadoop大数据的分布式并行计算框架设计方案,依赖快速高效的mapreduce,实现实时大数据的复杂计算,提供每一支股票的年利润、总利润、平均利润等特征,并对明年股票进行分析和预测。
2 系统的设计与功能设计
2.1 数据源
数据源模块的主要功能是利用API服务获取股票的数据,以庞大的股票数据做支撑,是整个框架的数据的唯一来源,上层数据的处理与整合都来源于数据源模块。
2.2 数据接入层
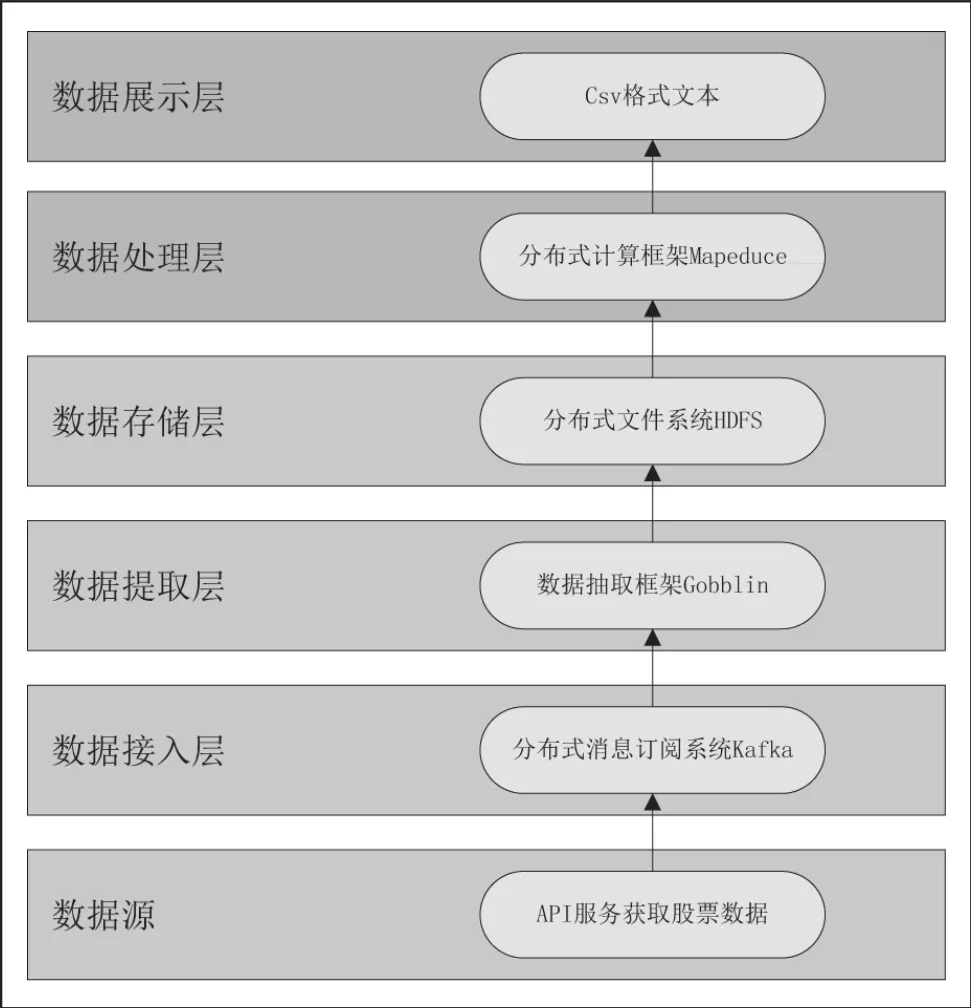
图1
数据接入层的主要功能是存储来源于数据源层的股票数据,利用分布式消息订阅系统kafka框架实现。它是一个针对流式数据处理的分布式消息订阅系统。主要包括如下几个模块:
(1)Broker:Kafka集群是由1个或者多个服务器组成,这种服务器即为broker
(2)Producer:消息数据的生产者。
(3)Topic:是指发送到集群中的消息分类,每一个类别都是一个Topic。
(4)Consumer:消费消息的一方,负责broker的Topic读取股票消息数据。
2.3 数据提取层
数据提取模块的主要功能是对数据做ETL(Extract-Transform-Load)处理,清洗数据,构建数据仓库,对数据进行分层处理。用到的主要工具的数据抽取框架Gobblin。
Gobblin是一种数据提取整合框架,可以接收以Kafka, fl ume等数据源的数据,并将这些数据采用定时的方式写入HDFS文件中中。这样便于集群拉取数据进行清洗、处理、分析等操作。主要包含如下组件:
(1)Source:主要起到适配器的作用。
(2)Converter:主要用来对股票数据进行清洗过滤操作,将数据转为需要的类型。
(3)Quality Checker:主要用于数据质量检测,以此保证数据质量,可通过手动或者可选策略的方式,将check的数据输出到指定的外部文件中。
(4)Writer:依据程序指定的配置文件,按照指定的数据格式,将股票数据输出到最终的存储路径下。
(5)Publiser:将数据输出到配置文件指定的路径下。
2.4 数据存储
数据存储模块的功能主要针对股票数据的存储,用到的主要存储工具是分布式文件系统(HDFS)。具有如下几个特点:
(1)故障分析
针对HDFS一些无效的部件或者无效的文件片进行合理的分析、处理。
(2)数据访问
hadoop的hdfs读取和写入数据采用的是流式读取和写入的方式,这一般程序读取数据的方式。HDFS比较适合离线的、批量的数据存储,针对的是高吞吐量,体现在数据吞吐量上。
(3)大数据集
HDFS分布式文件系统主要是针对高吞吐量的作业,需要依赖海量数据集,如果数据量较小,无法体现HDFS分布式文件系统的特性和优势,通常一个分布式集群可以支持成百上千个数据节点和成千上万的文件量。
(4)简单一致性模型
HDFS文件操作具有简单一致性的特点,对文件的操作都是采用一次写入多次读取的方式。HDFS文件只要经过创
2.5 数据计算层
计算海量数据的能力,是目前处理高吞吐量数据比较可靠的方法。
2.6 数据展示
通过数据读取,计算,最后会得到反馈,我们会得到每只股票的年利润,平均利润,通过利润计算来预测这只股票下一年的走势。
3 海量数据的存储与计算
3.1 海量数据的存储
对于海量的股票数据存储主要是采用分布式文件系统HDFS。HDFS文件系统主要针对离线、高吞吐量的数据存储系统,采用流式数据读取和写入的方式处理大文件数据。
Block:block是HDFS文件存储的基本单位。数据的读取和写入都是以block为单位的,默认大小为64M,在本文中,股票数据被分成64M大小的block块进行存储。
NameNode:名称节点,主要的功能是保存文件系统的元数据,主要维护两个数据结构:fsimage和editlog。editlog记录对HDFS文件的增删改查操作。
DataNode:datanode是客户端读取或者写入数据的节点,数据节点会定期采用心跳机制和namenode节点交互,以此获取整个集群的资源信息。
HDFS读取股票数据的过程:
(1)客户端通过API采用远程调用的方式和namenode进行通信(此过程的通信协议依然是Tcp/Ip协议),得到股票数据块信息。
(2)Namenode节点返回保存每一个block数据块的地址信息,并按距离远近进行排序。
(3)给客户端获得存储block数据的地址信息后,调用API,读取存储股票数据的block块。
(4)客户端调用API的开始读取数据。当block数据块数据读取结束时,关闭相应数据节点的连接,然后连接和下一个需要读入文件距离最近的节点,继续读入股票数据。
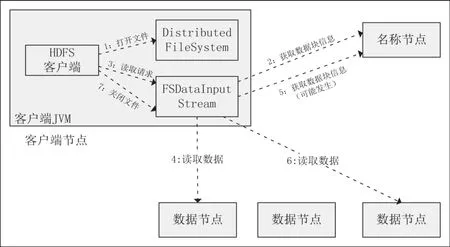
图2
(5)当客户端(client)读取股票数据结束的时候,通过调用API的close方法,关闭股票输入流即可。
3.2 海量数据的计算
股票的数据计算采用的是分布式计算框架MapReduce。MapReduce采用分布式计算的方式,采用主从架构的模式,执行的过程主要可分为map和reduce两个过程。
mapreduce的对股票数据的计算过程如下。
(1)客户端要编写好脚本程序,打成可运行的jar包,准备需要读入计算的数据源,也就是我们的股票数据。
(2)提交任务,提交股票数据是提交到Resource Manager上的,ResourceManager就会构建这个股票任务的信息,给这个需要运行的任务一个id,即为JobId,同时检查作业的输出目录是否已经存在,若不存在,正常运行;如已经存在,要进行资源的重新分配。
(3)作业初始化操作,将股票数据放到一个内部队列中,通过调度器进行初始化工作,创建一个正在运行的股票数据对象。
(4)初始化过程结束后,作业调度器(schema)读入输入分片信息如果分片较小,会先聚合成大文件读入,减少I/O带来的时间延误。接下来就是任务分配的过程了,先遍历每一个分片的数据,并根据分片数据的远近进行排序。
(5)执行任务。将运行任务的jar包从HDFS拷贝到本地并进行解压.并创建一个JVM,将Application程序加载到JVM中来执行具体的任务。
·输入分片(inputsplit):HDFS文件理想的split大小是一个HDFS块,本次实验采用默认的64M为一个block块。
·map阶段:①读取HDFS中的文件。每一行按指定分隔符进行分割,将分割后的结果解析成一个<key,value>键值对。②对分割后输出的<key,value>键值对进行分区操作;③对不同分区(partition)的股票数据按照key值进行排序操作。④对分组排序后的数据进行归约,减少传输到reduce过程的数据量
·reduce阶段:①对于map的输出结果,按照分区(partition)的不同,通过http协议,远程拷贝到不同的reduce节点上:②将reduce处理后的<key,value>结果输出到HDFS文件系统。
4 总结
本文提出了基于hadoop的股票利润分析设计方案,对股票数据进行了提取,存储,计算,得到股票的利润信息。通过对股票利润进行分析,对股票的发展趋势进行了合理的预测。在大数据时代,采用分布式并行计算框架和存储框架解决实际问题已经成为一种必然趋势。最近几年,股票市场研究一直在不断加大,对股票信息进行分析,预测已经成为一个热门研究方向。股票的分析预测可以帮助股民提取股票中的关键信息,精准把握股票市场的动态,以此获得更高的利润,避免股票陷阱。
影响股票价格走势和利润多少的因素多种多样,我们无法把所有因素全都考虑到平台中,因此想要实现股票价格的精确预测十分困难,难以实现。纵使我们能够把每一支股票的利润都分析出来,依然存在误差,但对股票的整体的走势分析依旧有很大的帮助。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
电气技术(2022年8期)2022-08-20
导航定位学报(2022年2期)2022-04-11
今日农业(2021年17期)2021-11-26
军民两用技术与产品(2021年5期)2021-07-28
软件(2020年3期)2020-04-20
当代陕西(2019年14期)2019-08-26
电脑爱好者(2018年14期)2018-08-05
中学数学杂志(初中版)(2016年5期)2016-11-01
电脑知识与技术(2016年8期)2016-05-19
