
两水平线性模型的参数估计及调整
2019-03-14 13:09:26杨新平徐登国
统计与决策 2019年4期
杨新平,徐登国
(楚雄师范学院 数学与统计学院,云南 楚雄 675000)
0 引言
线性模型y=Xβ+e的GLS估计,作为一种较为经典的估计方法,国内外许多学者从各方面做了大量研究。Magnus(1978)[1]在较弱的条件下给出了一阶似然估计的条件,并且证明了GLS估计及信息阵的一些性质。Magnus等(1980)[2]又借助排除矩阵再次探讨了这一问题。对于更一般的混和线性模型,固定效应参数的似然估计方法与线性模型参数的似然估计方法类似,只是方差参数的GLS估计更复杂,需采用Newton-Raphson迭代算法或者Fisher-Scoring迭代算法进行处理。二水平线性模型作为混合线性模型中的一种,在社会科学和行为科学中得到了广泛的应用,它的参数估计也受到了普遍的关注。从理论上看,绝大多数研究都将二水平线性模型纳入混和线性模型范畴,应用矩阵直接和的相关知识,将水平2的各组观测值作为对角块,给出了精练的估计表达式[3,4]。对于初学者来讲,估计的公式较抽象,难理解。如果对水平2采用分组(块)探讨似然估计,虽然得到的公式复杂,但推导过程直观性强,容易理解。对此问题的研究,Raudenbush和Bryk(2002)[5]进行了简略陈述。该文针对这一问题,做了细致的推导,清楚地表达了相应结论,导出了一阶似然条件和Fisher-Scoring迭代算法的公式和调整的参数估计方法,用JSP数据作为例子进行了阐述和说明。关于JSP数据,Browne(2011)和 Goldstein(2015)[6]曾用方差成分模型进行了研究,并给出IGLS估计。石磊等(2013)[4]也进行了更深入研究,给出相应估计。本文先建立两水平对中模型,给出模型相应参数的IGLS估计,再对参数的估计进行调整,提高了各个参数的估计精度。
1 模型的似然估计
对于两个水平层次数据,用l表示水平1的第l个观测单位,j表示水平2的第j个分组,每组有nj个观测值,j=1,2,···,J。建立两水平模型时,先对水平1建模得到模型:

然后将αj进行随机处理,并表示为水平2相应解释变量的一般化模型:

其中,Wj是d×p阶矩阵,其元素由数据中的元素构成,β是p×1向量,uj~N(0,Σ),并且满足:Eujrj=0,β和uj,rj独立,Σ 是d×d阶正定矩阵。将式(2)代入式(1)得到一般的模型表达式:

引理1:在模型(3)的假设条件及β,Vj二阶可微的条件下,有如下一阶ML条件:
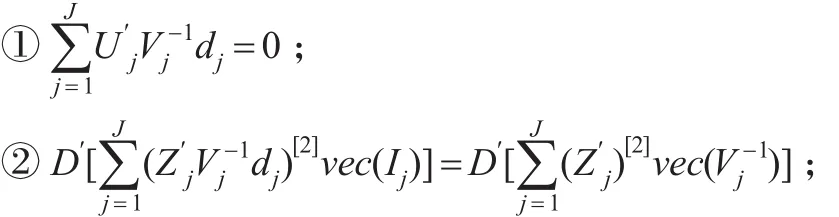
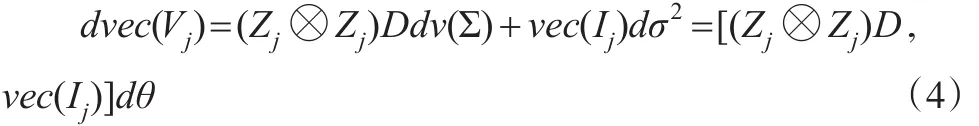
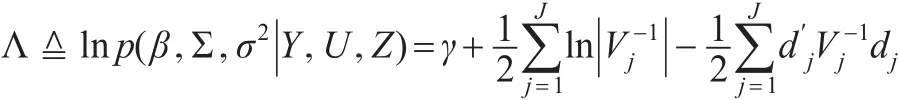
其中:γ=(2π)-n/2。
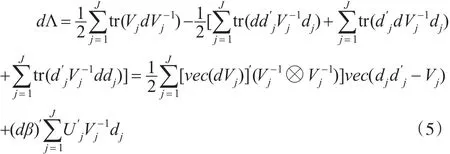
将式(4)代入式(5)得:
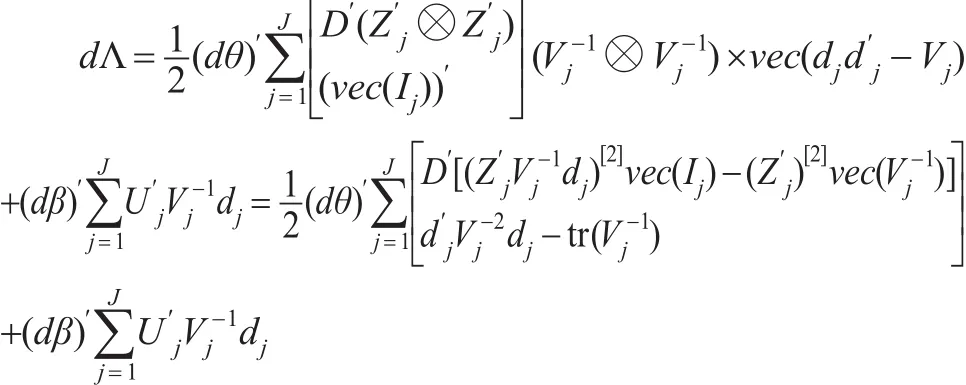
对于极大似然值θ,β,必须满足dΛ=0。但dθ≠0,dβ≠0。因此得到一阶似然条件方程:
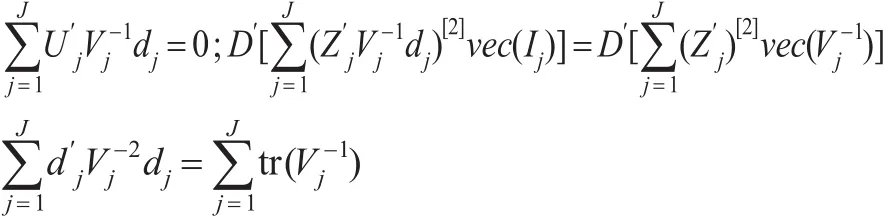
引理2:在模型(4)的假设及β,Vj二阶可微的条件下,参数β和θ信息矩阵是:
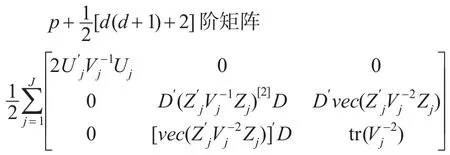
求二阶微分:
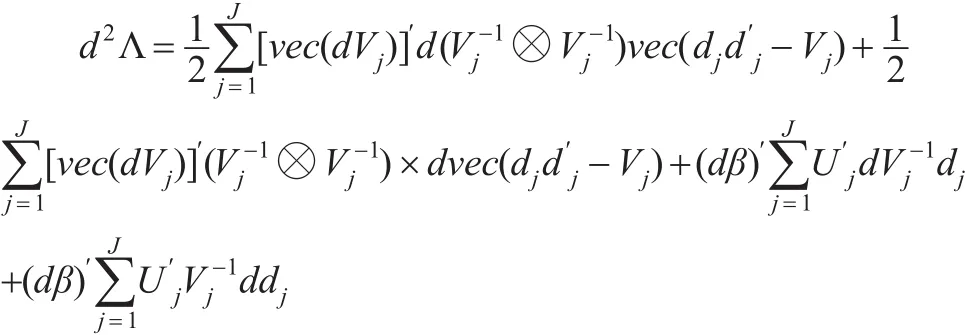
所以:

式(4)代入式(6)得:
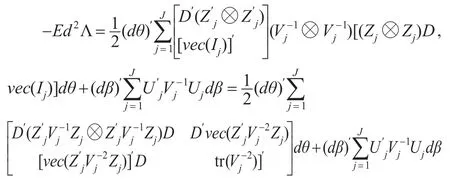
所以信息矩阵为:
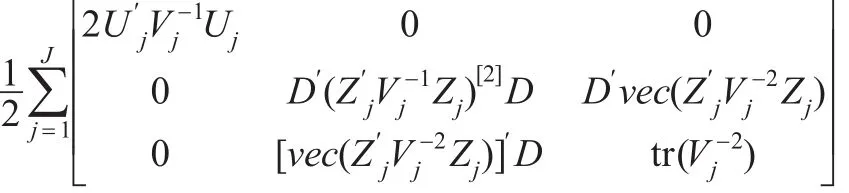
定理:模型(4)的假设及β,Vj二阶可微的条件下,参数的IGLS估计可通过下列三个迭代方程得到:
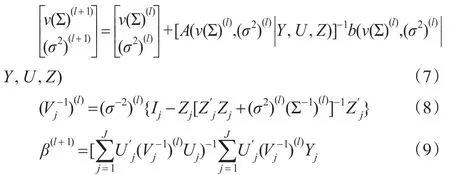
其中:Dv(Σ(l))=vec(Σ(l)),给定初始值,根据v(Σ0)意义,用v(Σ0)的元素构成 Σ0,始值 Σ0满足维列向量,阶方阵,它们分别由引理1及引理2计算得到,即:
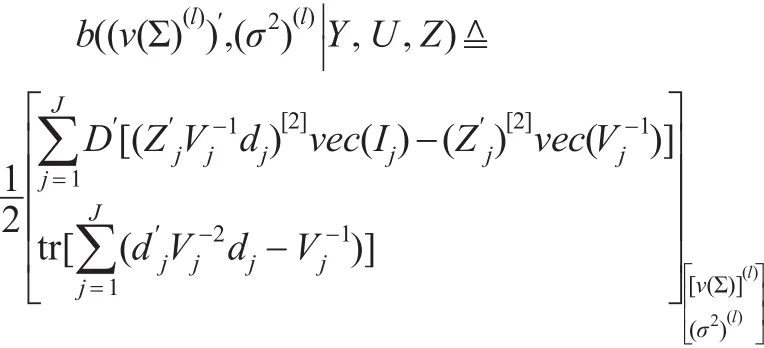
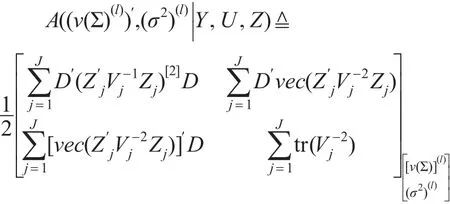
证明:对于方程(7),由引理1及引理2的证明容易得到向量及矩阵A((v(Σ))′,(σ2)|Y,U,Z),分别计算它们在第l步的值,再用计算出的第l步的值分别替换Newton-Raphson迭代公式中右边相应各项就得到方程(7)。对于方程(8),由于使用公式容易得到:写成迭代表达式即证。对于方 程(8),由 引 理 1,有得正规方程满足满秩的条件,则写成迭代表达式即证。
在迭代方程中,由方程(7)通过l步计算得到的Σ的更新估计并不能保证其正定性,因此,对于组间观测数量差异较大的数据,建立二水平线性模型后,并用迭代广义最小二乘估计方法得到的水平2协方差估计不一定正定。如果是负定矩阵,在进行bootstrap抽样之前,需进行估计值的调整,使得协方差阵估计正定。
2 估计调整
3 实例
JSP数据来源于伦敦市48所小学728名学生,是数据集的一个子样,在收集数据时,同一个学生考察在两个时段的成绩,变量名分别是:math.yr.3(记为yij),math.yr.1(记为x1ij),Gender.boy.1(记为x2ij),Social.class.manual.1(记为x3ij),School.ID。建立对中两水平线性模型:
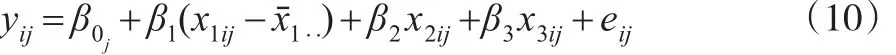
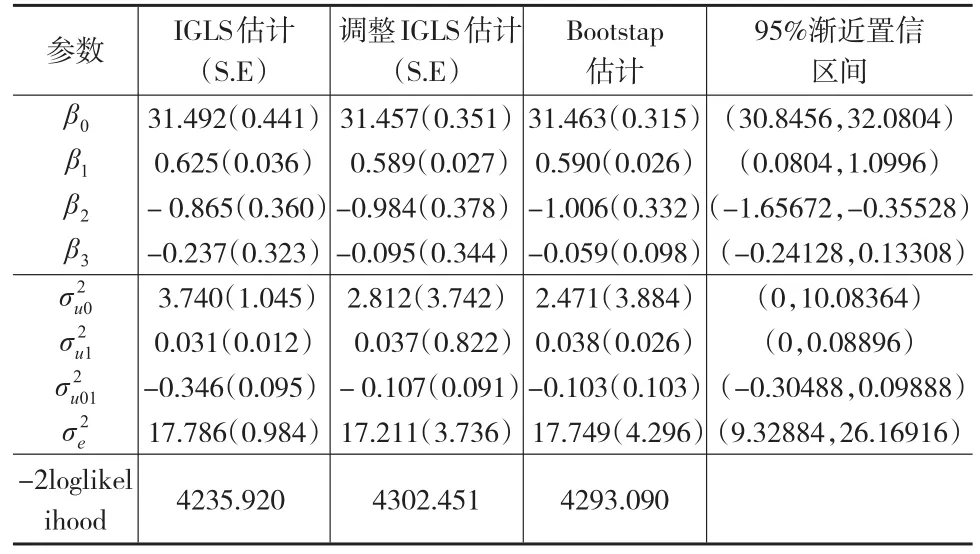
表1 JSP数据的二水平对中模型(10)的参数估计及调整后的参数估计汇总表
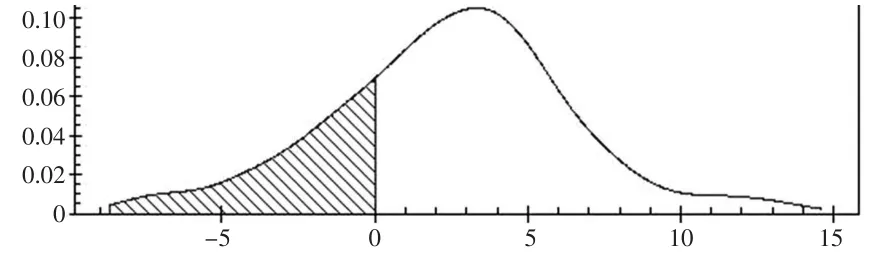
图1 核密度估计,均值2.471(0.328),众数3.332
模型(10)参数在Bootstrap链中的收敛性可通过由它的均值链的稳定性来判断,这里只给出-2loglikelihood、固定效应参数β1和各个随机效应参数的均值链曲线(见图2至图7),其他均值链曲线略。
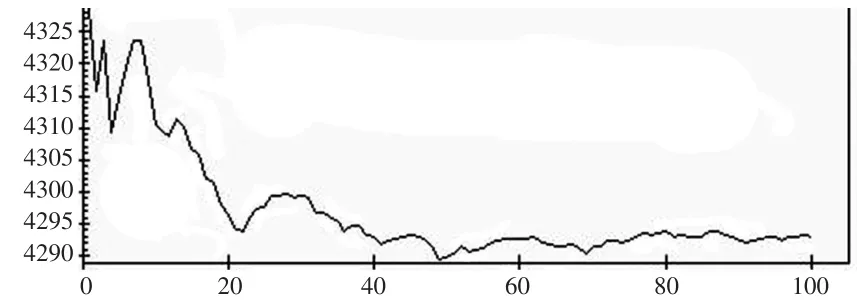
图2 -2loglikelihood=4293.090的均值曲线
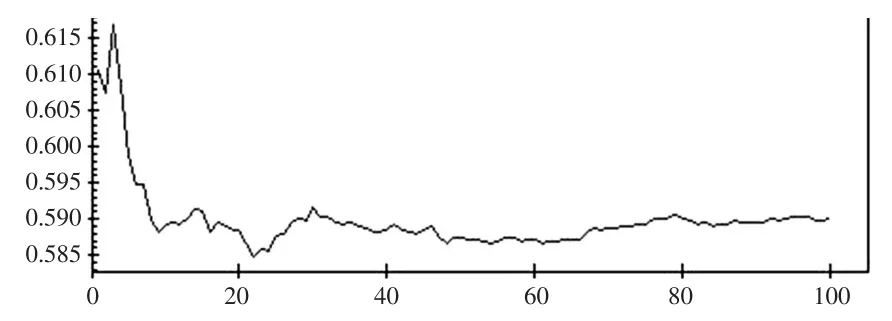
图3 β1=0.590(0.026)的均值曲线
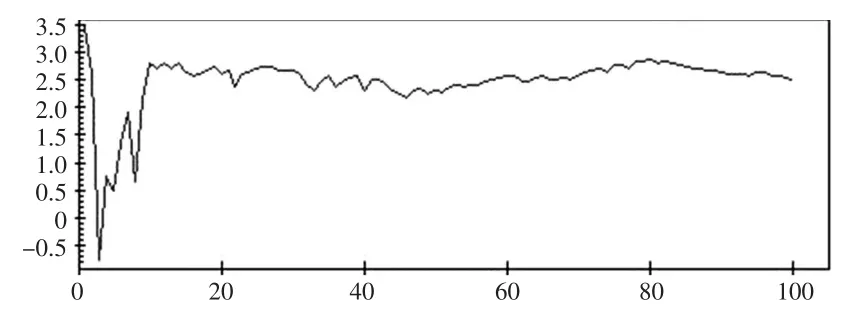
图4 =2.471(3.884)的均值曲线
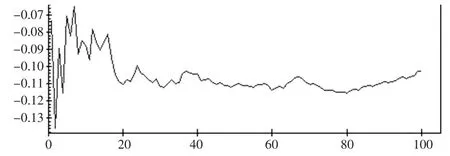
图5 =-0.103(0.103)的均值曲线
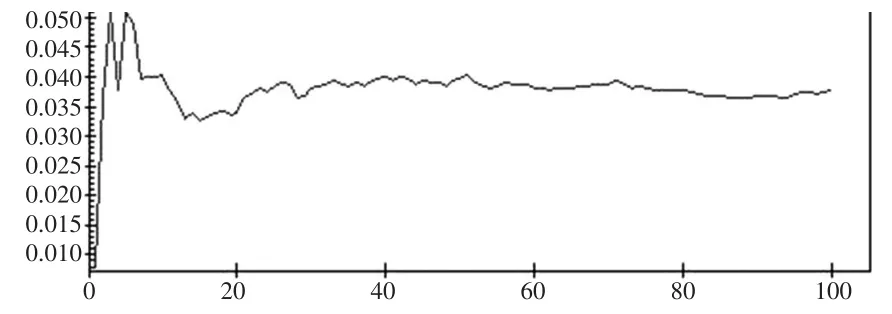
图6 =0.038(0.026)的均值曲线
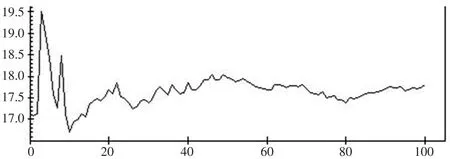
图7 =17.794(4.296)的均值曲线
从各自的均值链曲线可知,在5个重复集的情况,迭代次数达到80次以上,固定效应参数β1、-2loglikelihood值、随机效应参数的稳定性较好,而的稳定性稍差的核密度估计接近正态分布密度(见图8),用正态分布密度作近似分布得到的置信度为:
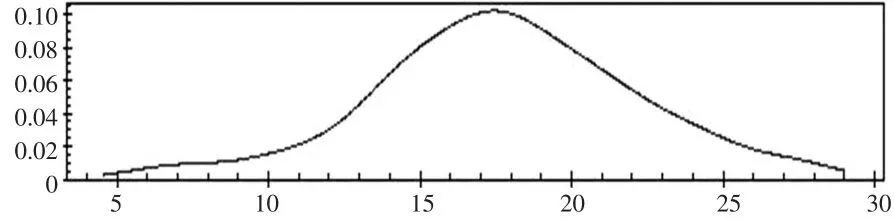
图8 核密度估计,均值17.794(4.296),众数17.454
95%的置信区间为(9.32884,26.16916),其他参数的渐近区间估计同样计算。如果要提高稳定性,减少模拟的误差,可以通过增加重复集的数目和每个重复集的迭代次数实现,但会增加较大的运算量,程序运行需要大量时间。
由表1中的计算结果可知:经过调整计算后的固定效应参数只是在社会背景上有变化,其他值变化不大,特别是固定效应的截距项均为31.4,说明若某一名学生在8岁时的数学绩如果能达到平均成绩25.97,在社会背景不变的条件下,那么在11岁时其期望的数学成绩为31.4分。-2loglikelihood由4235.920增加到4293.09值保持稳定的值有一定的改变,固定效应参数的标准误差减小,估计精度有所提高。
4 结论
(1)本文前半部分采用分组(块)来探讨似然估计,经过详细的推导,公式虽然相对复杂,但直观性较强,对于初学者来说,较容易理解。两水平线性模型在正态性假定及满足引理1中三个条件的情况下,极大化对数似然函数首先得到固定效应的参数估计,再通过定理中的迭代方程(7)至方程(9)进行迭代计算,直至各个参数的序列收敛,就得到参数的IGLS估计。已经证明:在正态性假定下,IGLS估计等价于极大似然估计ML[9]。IGLS估计是进一步实现Bootstap抽样的基础,通过自助抽样,得到各个待估参数的自助样本,求出各个参数的核密度估计,可完成进一步统计推断。
(2)实例中用到的JSP数据,共有728个样本数据,分成48个组,第46所学校有44个观测值,分组观测值个数最多,第42所学校有4个观测值,分组观测值个数最少,数据不平衡,用经典的IGLS估计模型(10)的参数,得到的水平2的协方差估计负定,结论适用性差,通过用Bootstrap方法进行重抽样求IGLS估计,估计值得到了改进,表现在获得了正定的水平2协方差估计,固定效应的参数估计的标准差比IGLS的标准差小,同时还可以利用核密度估计进行统计推断。因此,在经典的统计方法的基础上,采用自助抽样或者贝叶斯方法改进参数估计精度的方法是值得推荐的。
猜你喜欢
廊坊师范学院学报(自然科学版)(2022年3期)2022-10-11 04:32:06
北京航空航天大学学报(2022年8期)2022-08-31 08:58:24
哈尔滨工业大学学报(2022年5期)2022-04-19 13:26:28
科技视界(2021年4期)2021-04-13 06:03:56
统计与决策(2017年2期)2017-03-20 15:25:22
数学物理学报(2016年5期)2016-08-24 07:38:48
高中生学习·高三版(2016年1期)2016-05-30 05:45:06
系统工程与电子技术(2016年2期)2016-04-16 05:17:08
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:20
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01 02:54:01
