
智能产品语音用户界面的响应时间研究
2019-03-14 11:10陈宪涛关岱松周茉莉王任振魏欢
人类工效学 2019年1期
陈宪涛,关岱松,周茉莉,王任振,魏欢
(百度人工智能交互设计院,北京 100193)
1 引言
随着语音技术的不断成熟,自然语音交互正逐渐融入日常生活,人们与产品之间的交互媒介开始由图形用户界面转变为语音用户界面(Voice User Interface,VUI)。语音用户界面主要指基于语音识别技术,支持用人类语言与设备进行信息交互和实现用户意图的界面[1]。与图形用户界面相比,语音用户界面具有更自然、更高效的交互属性,为了实现类似日常人与人对话的互动体验,语音用户界面通常需要及时响应人们的指令和操作[2-3]。在技术实现上,语音用户界面性能的评价涉及很多方面,其中响应时间是重要的性能指标之一,产品实际的响应时间会受语音识别算法效率、声学模型质量、语言模型质量等多种因素影响[4-6]。不断优化语音用户界面的响应时间是提高语音产品实用性的关键[7]。
响应时间(Response Time,RT)是指人机交互过程中计算机对人们发出的指令进行响应所产生的延迟时间[8]。有研究表明在影响用户对产品评价的诸多因素中,响应时间是决定用户满意度的最重要因素[9]。关于响应时间对用户态度、行为和心理的影响,在图形用户界面交互领域进行了大量和广泛的研究[10-12],例如Dennis等研究网站加载延迟与用户行为和态度的关系,发现延迟时间到4 s或更长时间,用户任务绩效的减少开始趋于平缓,当延迟时间达到或超过8 s时,用户满意评价的减少开始趋于平缓[13]。Fiona对响应时间研究做了全面的梳理,并对网络用户可容忍的页面加载时间进行实验,研究发现理想的页面加载时间应设置在2 s以内[14]。王海霞等研究响应时间对人与信息系统交互效率的影响,发现系统响应时间在0.25~0.75 s的范围时交互效率最高,0.25 s以内的响应时间容易给人造成压力和紧张情绪[15]。针对语音用户界面的响应时间,Thomas等研究车载语音界面的响应延迟对驾驶员注意力的影响,发现较短的响应延迟可以减少驾驶员注意力从驾驶视野区转移,建议车载语音界面的响应延迟最好能控制在4秒以内[16]。Martin等针对美国家庭使用智能音箱的语音交互行为进行研究,认为语音用户界面的响应及对话设计需要参考人人对话的响应情况,发现过长的沉默等待时间经常会被人们视为麻烦[17]。
目前,针对语音用户界面响应时间的研究较少,且主要集中在车载或驾驶等特定场景,对语音交互在其它使用场景的关注度不够。另外,语音交互的过程涉及语音唤醒、语音识别、语义理解、语音合成等多个环节,不同环节的响应时间对用户态度的影响,尚缺乏系统性的科学研究和论证。
2 研究方法
按照用户意图和交互阶段,可以将语音用户界面的用户任务分为两个基本的交互环节,如图1所示,即语音唤醒和语音对话,先进行语音唤醒继而开启语音对话的交互功能[18]。语音唤醒(Voice Wake Up)是指用户通过特定的唤醒词,将激活信号传递给设备以便实现语音识别系统的智能开启[19],例如唤醒词“小度小度”可以唤醒内置百度DuerOS对话式系统的智能设备。语音对话是指设备被唤醒后针对用户发出的一系列语音指令,设备进行语音识别、语义理解、语音合成和满足用户需求的过程[20],以智能音箱为例,用户的请求指令可以是点播音乐、查询天气、点播有声资源等。
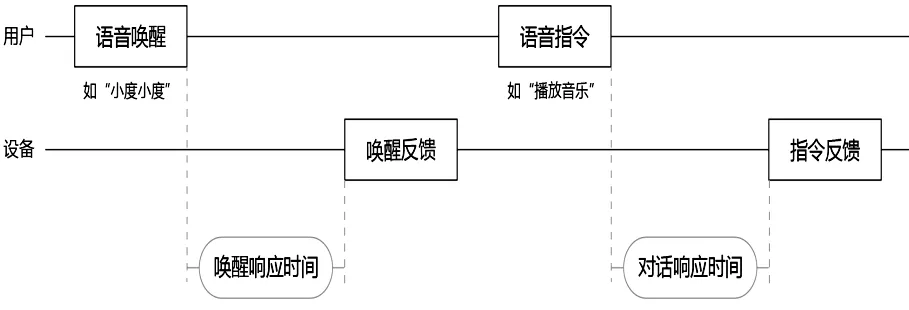
图1 语音交互的主要流程
语音唤醒和语音对话虽同属用户与语音用户界面交互的关键环节,但两者在技术实现方式及对用户体验的影响两方面均有所不同:在技术方面,相较于语音对话的大词汇量的语音识别,语音唤醒主要是一个基于小语料的识别系统[19];在体验影响方面,作为语音交互的第一步,唤醒效果的好坏直接影响用户的第一体验。因此,语音唤醒和语音对话应属语音技术系统性能优化的不同目标和对象。本研究聚焦语音唤醒和语音对话的响应时间,重点探索语音用户界面不同环节理想的响应时间范围,同时也探讨不同的响应方式对用户感知响应时间的影响。
2.1 语音唤醒响应时间实验
针对语音用户界面,了解语音唤醒环节用户感知舒适的响应时间。同时,针对目前智能产品常见的唤醒响应方式,探索不同唤醒响应方式对响应时间感知的影响。
2.1.1 被试
32名被试均是互联网公司员工,年龄在20~39岁之间,男性被试17人,女性被试15人。所有被试的视力或矫正视力正常,听力正常,实验后给予适量报酬。
2.1.2 实验设计
本实验采用9(唤醒响应时间:200 ms、300 ms、400 ms、500 ms、600 ms、700 ms、800 ms、900 ms、1000 ms)×3(唤醒响应方式:光效反馈、光效加“嘟”音效反馈、光效加“在呢”人声反馈)被试内设计,其中三种响应方式是目前市场上智能产品语音唤醒环节常见的反馈方式,唤醒响应时间的操作定义是用户说完唤醒词到设备被激活的时间间隔。每种条件下被试需要重复两次唤醒,以减低实验的随机误差,同时为了控制不同任务顺序带来的学习效应以及疲劳效应,我们对每个被试完成任务的顺序进行了随机化,即实验中先对响应方式进行分组和随机处理,然后对每种响应方式下的响应时间进行完全随机处理。
基于Mark等对人与智能产品对话响应的评价策略[21],我们将实验的因变量定义为被试对响应时间的舒适度评价(1-太快了,接受不了;2-有点快,能够接受;3-刚刚好;4-有点慢,能够接受;5-太慢了,接受不了)。
2.1.3 实验程序
实验程序是专门为实验开发的智能音箱,主试可以通过设备后台随时更改和设置不同的响应时间和响应方式。实验中,被试与智能音箱距离约为1.5 m,以远场语音交互为主。实验开始前,被试先试用一款普通的智能音箱,主要是为了熟练使用唤醒词“小度小度”。正式实验环节,要求被试分别在不同的自变量水平下对智能音箱进行语音唤醒,完成2次语音唤醒后对当前的唤醒响应时间进行主观打分。实验结束后,主试会针对响应时间和响应方式的评分及原因对被试进行访谈。
2.2 语音对话响应时间实验
在语音唤醒响应时间实验的基础上,了解用户在语音对话环节感知舒适的响应时间。
2.2.1 被试
55名被试均为互联网公司员工,年龄在20~39岁之间,男性被试41人,女性被试14人。所有被试的视力或矫正视力正常,听力正常,实验后给予适量报酬。
2.2.2 实验设计
采用被试内设计,自变量为语音对话环节的响应时间,即被试说完请求指令到设备开始反馈内容的时间间隔,实验选取了10个不同长度的响应时间值(响应时间:300 ms、500 ms、700 ms、900 ms、1100 ms、1300 ms、2000 ms、3000 ms、4000 ms、5000 ms)。实验使用相同的语音请求指令 “今天天气怎么样”,被试说完指令后提供完全相同的请求反馈内容。为了控制不同任务顺序带来的学习效应以及疲劳效应,我们对每个被试完成任务的顺序进行了随机化。
实验的因变量仍然是被试对感知到的响应时间的舒适度评价(1-太快了,接受不了;2-有点快,能够接受;3-刚刚好;4-有点慢,能够接受;5-太慢了,接受不了)
2.2.3 实验程序
实验程序是专门为实验开发的智能音箱,实验中我们提供了10种不同对话响应时间设置的智能音箱。被试与智能音箱的距离是1.5 m,实验开始前,先让被试体验一款普通的智能音箱。正式实验环节,要求被试分别对10种不同对话响应时间设置的智能音箱进行语音请求,然后分别对响应时间进行主观打分。为了平衡顺序效应,实验中10款智能音箱采用完全随机处理。实验后主试针对对话响应时间的评价及原因对被试进行访谈。
3 研究结果
对实验数据进行描述性统计分析,图2所示为3种唤醒响应方式下不同的唤醒响应时间被试感觉“刚刚好”的占比。当响应方式为光效时,唤醒响应时间越短,感觉舒适的被试占比越高;当响应方式为光效加“嘟”音效时,唤醒响应时间在300 ms左右时,感觉舒适的被试占比最高;当响应方式为光效加“在呢”人声时,被试感觉舒适的响应时间为500 ms左右。
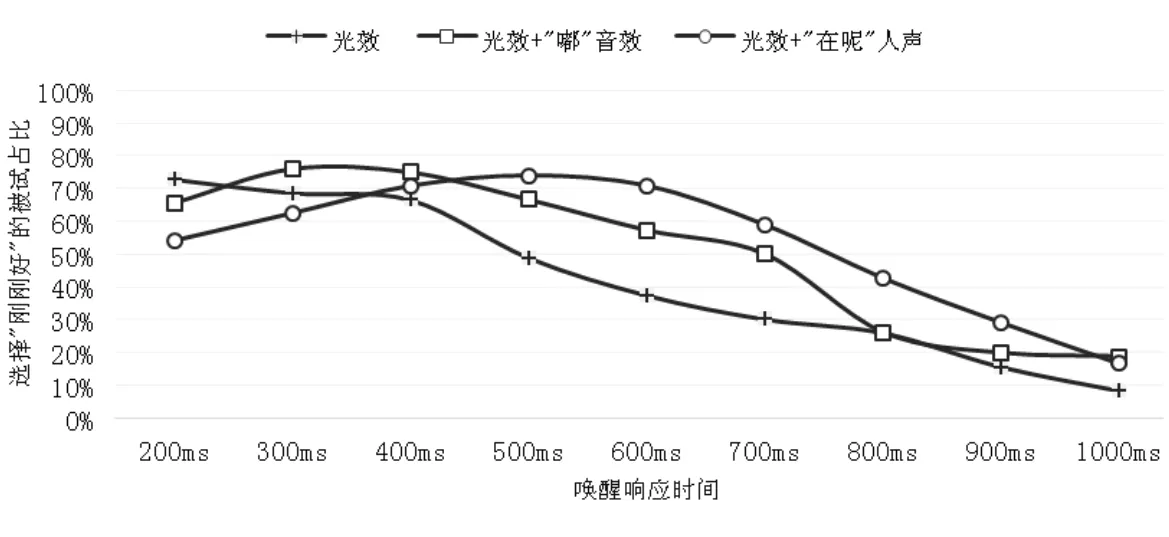
图2 不同唤醒响应方式下舒适的唤醒响应时间感知曲线
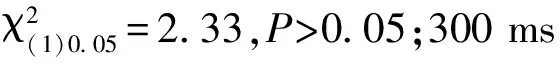

由于实验程序带来的误差,被试实际体验的对话响应时间在原来基础上分别增加了150 ms的时间。对实验数据进行描述性统计分析,如图3所示,数据显示当对话响应时间为650 ms时,感觉“刚刚好”的被试占比最多。当对话响应时间超过2 150 ms时,感觉“太慢了,接受不了”的被试占比开始明显增加,被试开始觉得响应太慢。
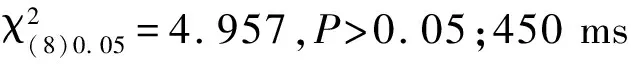

图3 舒适的对话响应时间感知曲线
4 讨论
研究探讨了语音用户界面不同交互环节响应时间对用户感知的影响,发现用户感知舒适的响应时间受到响应方式以及交互阶段影响。被试在语音对话环节感知舒适的响应时间要略长于语音唤醒环节,而且唤醒响应时间和唤醒响应方式之间的交互作用显著,不同的唤醒响应方式下存在不同的最佳响应时间范围。
在语音唤醒环节,当响应方式为仅光效反馈时,理想的唤醒响应时间范围是200 ms~400 ms,结合实验后的访谈可以发现,被试倾向于响应时间越短越好,因为光效反馈时,被试主要通过视觉获得设备已经被唤醒的信息,并不会影响被试的思考。实际上,被试并不喜欢仅光效的反馈方式,被试认为仅光效反馈是不充分的,希望同时伴随听觉通道的反馈。当响应方式为光效加“在呢”人声反馈时,被试感觉最舒适的响应时间范围为300 ms~600 ms,访谈中被试提及当人声反馈太快时,感觉像被抢话,思路被打断,不像人与人之间的自然交流。当响应方式为光效加“嘟”音效反馈时,被试感觉最舒适的响应时间范围为200 ms~500 ms,访谈中也有被试提到音效反馈太快也会给人说话被打断和抢话的感受,只是程度没有人声反馈的影响强烈。
在语音对话环节,被试感觉最舒适的响应时间范围为650 ms~1050 ms,并不是越快越好,这与王海霞等[15]的研究发现类似,太短的响应时间容易给被试产生压力和紧张情绪。被试对语音对话环节理想的响应时间略长于唤醒响应时间,可能原因包括以下几个方面,首先,被试对两个环节响应时间的预期不同,例如访谈中被试提及语音唤醒很像日常交流时叫别人的名字,而语音对话环节则类似于具体的交流和谈话,被试希望在叫别人名字时能够更快地得到反馈,而对话时则预期对方有一定的思考时间。其次,被试已有认知因素的影响,由于被试均有互联网使用经验,他们理解语音对话环节相比语音唤醒环节,涉及更多的语音识别、网络请求、内容传输等处理环节,因此,评价和判断的标准可能会受到被试认知经验的影响。
5 结论
(1)语音交互的不同环节,被试对语音用户界面的响应时间有不同的要求;(2)在语音唤醒环节,当响应方式为光效时,建议将唤醒响应时间范围控制在200 ms~400 ms。当响应方式为光效加“嘟”音效时,建议将唤醒响应时间范围控制在200 ms~500 ms。当响应方式为光效加“在呢”人声时,建议将唤醒响应时间范围控制在300 ms~600 ms;(3)在语音对话环节,建议将响应时间范围控制在650 ms~1050 ms。
猜你喜欢
家庭影院技术(2021年1期)2021-11-20
家庭影院技术(2021年7期)2021-08-14
电脑报(2020年8期)2020-04-10
阅读(快乐英语高年级)(2019年5期)2019-09-10
计算机与网络(2019年12期)2019-09-10
家庭影院技术(2019年8期)2019-08-27
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
发明与创新·大科技(2017年7期)2017-07-17
