
基于混合特征的恶意PDF文档检测
2019-03-13 08:17杜学绘林杨东孙奕
通信学报 2019年2期
杜学绘,林杨东,孙奕
(解放军战略支援部队信息工程大学河南省信息安全重点实验室,河南 郑州 450001)
1 引言
PDF是由Systems[1]在1993年提出的,用于文件交换的一种文件格式,其优点在于跨平台、能保留文件原有格式、开放标准等。PDF文件格式自被提出以来,就以其高效性、稳定性和交互性而被广泛应用于政府、组织、企业等重要机构的日常办公。
自2008年第一个基于恶意代码的PDF漏洞[2]被提出后,针对PDF文件格式漏洞的利用技术迅速发展。近几年来,随着社会工程学和APT(advanced persistent treat)等攻击手段的兴起和发展,PDF格式的漏洞也不断被挖掘出来,利用嵌入恶意PDF文档的钓鱼邮件,结合社会工程学对政府、组织、企业等进行攻击的案例也屡见不鲜。
2016年9月,PaloAlto研究中心的安全研究人员首先发现了针对苹果系统的新型钓鱼邮件攻击,其技术核心在于钓鱼邮件中携带有木马病毒的恶意PDF文档。2017年5月12日,WannaCry勒索病毒软件借助高危漏洞“永恒之蓝”在全球范围内爆发,攻击范围覆盖医疗、教育、公安等多个行业,影响极其恶劣。相关人士表示,WannaCry勒索病毒主要通过钓鱼邮件结合恶意附件进行传播,然后嵌入文档、感染文档并对文档进行加密。
种种案例表明,钓鱼邮件是当前恶意文档的主要传播途径,攻击者通常将恶意文档作为邮件附件,结合社会工程学等,诱使用户打开恶意文档,从而执行进一步的恶意操作。现有的针对恶意PDF文档的反病毒系统大多是基于签名的方法和基于启发式规则的方法[3],其在应对多态攻击方面存在一定的缺陷,且无法应对新型安全威胁。为了解决这些问题,近年来,研究工作主要分为以下2个方面:1)着重关注恶意 PDF文档中的静态特征,如结构特征、内容元数据特征等,来判别恶意PDF,而不关注其恶意内容及具体的行为操作;2)利用静态分析和动态分析的方法,针对恶意PDF文档中的JavaScript特征进行检测。前一种方法的检测效果和检测效率均比后者更优,且可以检测不包含JavaScript的恶意文档,然而,这种方法由于选取特征的顽健性较弱,已被证明极易被攻击者通过简单的操作而绕过,因此,研究人员又重新关注恶意文档中JavaScript特征的相关研究。
为了解决现有检测方案特征顽健性较差、易被逃避检测的问题,本文提出了一种基于混合特征的恶意PDF文档检测方案。该方案采用静态分析技术从文档中提取出其常规信息(版本号、大小等)以及其结构信息,采用动态分析技术从文档中提取出文档执行时的API(application programming interface)调用信息。对于常规信息,本文根据对文档的分析结果进行过滤筛选;对于结构信息及API调用信息,本文采用K-means聚类算法对其进行聚类,从中聚合出最能表征文档恶意性的关键结构特征及API调用特征,以此3种特征构成特征向量,利用随机森林算法构建分类器并最终设计实验进行验证。结果表明,本文方法与现有已公开的3种最新检测工具相比,检测率和误报率均有一定提高,且在应对基于特征加法的模拟攻击上效果较好。
2 相关工作
2.1 PDF文档结构简介
由于 PDF使用起来方便快捷并且支持各类功能,其在我国信息化进程中逐渐成为主流的文档信息交换的主要格式,但与此同时也成为恶意代码传播的主要载体[4]。
一个典型的PDF文档通常包含丰富的文本、图像等信息,此外,在PDF中,往往还存在超链接、数据交换以及允许其他应用调用的接口等来为PDF文档的各类功能提供支持。因此,PDF拥有十分复杂的结构特征。
PDF文档由一组逻辑上相互连接的对象组成,其结构[5]主要包括文件头(header)、文件主体(body)、交叉引用表(cross-reference table)、文件尾(trailer)和其他可选部分。文件头主要记录了该文件使用的PDF结构标准规范,文件主体包括了所有的对象内容,交叉引用表记录了间接对象的地址索引表,文件尾主要记录了交叉引用表的物理位置。
文件头位于PDF文档的最前端,指定了文件使用的PDF规范的版本,如“%PDF-1.7”表示该PDF文档使用PDF 1.7版本的规范。需要注意的是,文件头可以被放置在PDF文件的前1 024 B中的任意位置。
文体主体由文件头和交叉引用表之间的所有对象组成,这些对象共同构成了PDF文件的具体内容,如页面、文本、链接、图像等。
交叉引用表为间接对象的随机存取提供了索引地址表,它的一个重要作用是保证了在整个PDF文件被完整加载之前,可以将部分文档先进行显示。对于一个PDF文档而言,其交叉引用表会随着PDF文件的更新而更新,不断添加新的内容。
文件尾位于文件的结尾,以“trailer”为起始标志,指定了交叉引用表以及一些特殊对象的物理地址,并以“%%EOF”为结束标志。
2.2 恶意PDF文档检测相关方法
恶意 PDF文档检测技术已有一定的基础。目前,对恶意PDF文档检测的分析方法主要有2种类型,即静态分析和动态分析。静态分析主要针对PDF文档中的静态特征,利用反编译的手段从文档中解析出结构、内容、JavaScript代码等特征,并以此建立恶意PDF文档检测模型;动态分析则是利用虚拟机、硬件模拟等技术,通过API挂钩等手段对恶意PDF文档及其内嵌代码的动态执行进行监控,并以此建立PDF文档行为检测模型。
早期的恶意文档检测,普遍使用静态分析的方法。2007年,Li等[6]首次提出了利用机器学习结合n-gram分析对原始文档进行字节级分析,然而这些方法主要针对word文档、可执行文件(exe)等,并未在PDF文档检测方面进行尝试,其主要原因在于受编码、过滤和加密等技术的影响,无法定位到PDF文档中的主要特征。随着恶意PDF文档的危害性不断增强,后续的研究工作着重分析PDF文档中的JavaScript代码特征。
PDF文档中的JavaScript代码特征主要有2类,即动态行为特征和词汇特征。针对JavaScript代码的动态行为特征分析已经提出了许多解决方案,并设计出了 CWSandbox[7]、JSand[8]、Cujo[9]、Zozzle[10]、Prophiler[11]等多种 JavaScript代码分析工具,被广泛用于不同格式的文档中嵌入式JavaScript代码的检测,在此基础上形成了MalOffice[12]、ShellOS[13]、MDscan[14]等检测系统。然而,利用虚拟环境对JavaScript进行分析的时间开销和计算开销都较高,且攻击者可以利用不同的JavaScript引擎或不同的阅读器版本等来绕过检测。为了降低开销,研究人员逐渐关注于对JavaScript代码的静态词汇分析,通过解析器,对PDF文档中的JavaScript进行定位和提取,随后利用分类器进行学习,形成检测模型,典型的代表有PJScan[15]等。
然而,在针对PDF文件中JavaScript代码特征的分析过程中,由于存在压缩、加密、混淆等技术手段,JavaScript代码的定位、抽取及解析始终具有较大难度,因此,针对元数据[16-17]的分析方法应运而生。基于元数据特征检测的特征抽取过程一般较为简单,且不需要对JavaScript进行解析和执行,其关注的特征主要有内容特征和结构特征2类。内容特征主要关注PDF文档中的重要关键字,如/JS、/JavaScrip以及字体对象、流对象长度等一系列特征,其主要不足在于无法抽取出流对象中的数据,而流对象数据又容易被攻击者用来隐藏恶意内容,从而绕过此类检测。另一类利用PDF文档结构特征的检测方法[18]在检测率和应对新型威胁上均有进一步的提高,然而已被证明易被攻击者通过在正常文档中嵌入恶意内容来绕过[19]。
尽管通过对元数据的分析建立起来的检测模型的检测率及效率均较高,但其顽健性方面存在明显的不足,因而研究又逐渐转向PDF文档中的恶意代码。最新的进展主要有:通过在PDF文档中嵌入环境监控代码对PDF文档的动态行为进行监控[20];根据PDF文档运行过程中的API调用信息作为特征对PDF文档进行分类检测[21];利用沙箱来增强打开PDF文档从而保护系统的安全性等[22]。此后,Maiorca等[23]提出了结合PDF文档的结构和内容特征来对恶意 PDF文档进行检测,在一定程度上增强了纯静态的结构特征分析所带来的顽健性弱的问题,但由于采用的仍是静态分析,因此在对抗模拟攻击方面依然存在顽健性不足的问题。
3 基于混合特征的恶意PDF文档检测方法
通过对现有技术的分析,本文发现近几年对于PDF文档检测的研究大部分集中于检测其中的JavaScript代码以及相应的结构和内容元数据。
针对JavaScript代码的检测顽健性较强,但存在定位和解析JavaScript困难、分析代价较高、难以应对其他类型的安全威胁等问题;针对结构和内容元数据的分析检测效率和检测率较高,然而容易被攻击者设计特定文档而绕过,顽健性较差。
为了克服这些缺点,本文提出了一种基于混合特征的恶意PDF文档检测方法,在现有研究的基础上,着重关注恶意PDF文档的常规特征、结构特征及其API调用特征。方案框架如图1所示。
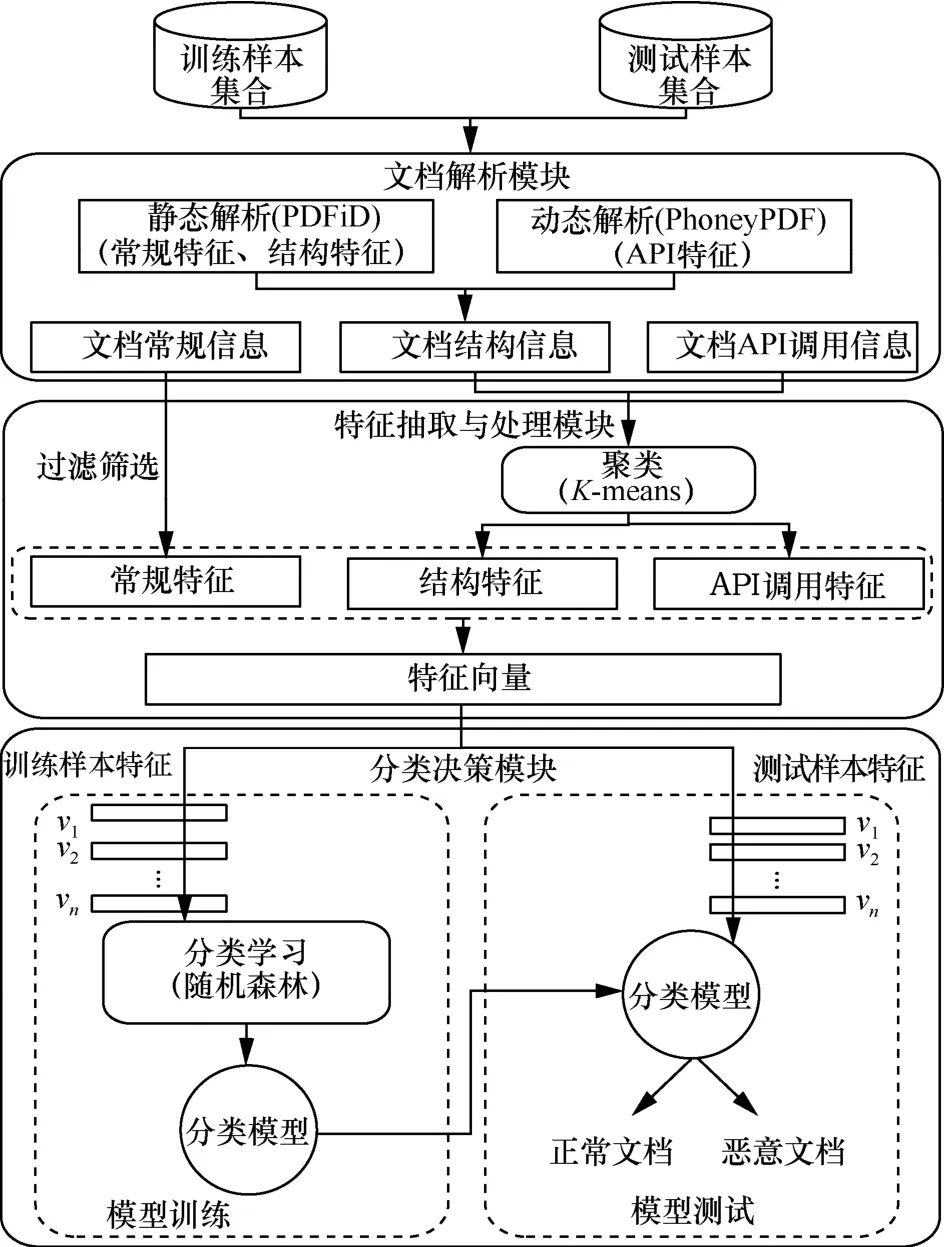
图1 基于混合特征的恶意PDF文档检测方案框架
本文以PDFiD和PhoneyPDF这2款工具为基础构建了文档解析器,采用动静态分析相结合的方法,从文档中提取内容信息和结构信息,并将JavaScript特征转化为对应的 API调用特征从而解决JavaScript代码定位难、代码混淆等问题,并通过聚类获得最能表征恶意 PDF文档的结构特征及API调用特征,去除了大量冗余信息,并将此特征集合与常规特征相结合作为混合特征向量用于分类器的训练学习,最终得到检测模型。
3.1 混合特征设计
由于单一特征存在顽健性差等问题,因此本文设计了一种混合特征,用以表征 PDF文档的恶意性,具体可分为常规特征、结构特征、API调用特征3类,下面进行详细介绍。
3.1.1 常规特征
通过对 PDF文档的分析,结合已有的在恶意PDF文档检测领域的相关经验结果,本文选取了以下7个重要特征作为常规特征,包括文件大小、文件版本号、包含JavaScript代码的对象数量、嵌入的文件数量、不完整对象的数量、交叉引用表的数量、特殊操作函数(如OpenAction、Launch等)数量。这些常规特征与PDF文档的安全相关性如表1所示。

表1 常规特征与PDF文档的安全相关性
这些单一特征并不足以用来标识 PDF文档的恶意性,但它们结合起来可以作为PDF文档的一个整体概述。例如,根据对大量文档的分析,恶意PDF文档的大小通常小于正常PDF文档的大小,因为一般恶意 PDF文档并不包含有用的文本、图片等内容,且文件越小,其感染效率就越高;同样,对象、交叉引用表通常用于隐藏文档中的恶意内容,与文档的恶意性存在一定的相关性;此外,JavaScript代码及特殊操作函数等是绝大部分恶意 PDF文档完成其恶意目的的必备内容,也能在一定程度上反映文档的恶意性。因此,这些特征构成了PDF文档的常规特征,其可以在一定程度上表征文档的恶意性,但并非充分条件。
3.1.2 结构特征
利用结构特征来表征PDF文档的恶意性,最早由Šrndic等[18]提出,其方案以恶意PDF文档在结构上与正常PDF文档存在的差异性为基础,设计了一种结构路径用于表征PDF文档的结构特征,其主要问题在于特征复杂,且不利于进一步分析。因此本文设计了一种更为简便的且更具有可解释性的结构特征。不同类别的文档,其文档结构上的关键字存在一定的差异,当一个关键字在正常样本或恶意样本中出现的频率较大时,其可在一定程度上反映文档的实际类别。因此,本文在对PDF文档进行解析并获取其结构关键字及其频率的基础上,设计了一种结构特征提取算法对所提取出的关键字进行聚类,从中筛选得到出现频率较高的关键字作为结构特征,从而以尽可能小的特征数量来最大程度地表征PDF文档。算法具体描述如下。


本文利用上述算法,分别对正常PDF集合和恶意PDF集合的特征关键字集合进行提取,最终得到正常样本关键字子集合Kb和恶意样本关键字子集合Km及其对应的出现频次,分别用以表示正常样本的结构特征和恶意样本的结构特征。本算法主要包括 3个步骤,对应的复杂度分别为O(|K||D|)、O(2T|K|)、O(|K|),其中,T为K-means算法中的迭代次数,由于迭代次数远小于样本数量,因此算法复杂度为O(|K||D|)。
结构特征集合中的关键字数量主要取决于样本集合和聚类结果。文档的结构特征通常与文件执行的特征操作相关联,并且主要通过关键字来执行对应操作,因此选择特征关键字来表示文档的结构特征是可行的。例如,/Font是正常样本中的特征关键字,主要是因为此关键字与文档中的字体相关联,出现此关键字说明样本内容中会显示不同字体,对于正常样本来说这是合理的,但恶意文档一般不包含具体内容,以轻便简单为主,因此一般不出现此关键字;又如,/OpenAction是恶意样本中的特征关键字,其主要功能是执行对象中的打开操作,常用来执行JavaScript代码,这与恶意样本中有90%以上的样本包含JavaScript相吻合[24]。
通过聚类,利用文档结构中的关键字特征来表征其结构特征,极大地降低了特征向量的复杂度,并且由于排除了大量冗余关键字,从而加大了攻击者在正常文档结构基础上构建恶意文档从而绕过检测的难度。
3.1.3 API调用特征
恶意 PDF文档中所包含的恶意代码往往都会经过复杂的混淆和隐藏,直接进行静态分析难以解决代码定位难与代码混淆等问题,为此,本文基于API调用与恶意代码执行过程的相关性,利用API调用特征来间接地表征 JavaScript代码的执行特征。现有的针对恶意PDF文档中JavaScript代码的分析中,最常见的是采用SpiderMonkey等工具进行分析,这些工具最大的不足在于其识别的标准为JavaScript 通用标准,对于PDF文档中特定JavaScript代码(如 app.doc.getAnnots、app. plugIns.length等)无法有效识别。本文采用了PhoneyPDF这一分析框架对PDF的内嵌JavaScript执行过程进行分析,它是一种基于Adobe DOM仿真的分析框架,可以执行并分析PDF中所使用的各类JavaScript代码。通过对其执行过程中的API调用进行抽取,设计了一种特征API调用提取算法对关键API调用进行了选择。
记R为Acrobat PDF标准中所有可调用的API函数集合,N为其元素个数。本文的任务即从全集R中筛选出对 PDF文档标签具有表征价值的 API函数子集合。
对于任意的r∈R,定义θ=∑φi为其有效性权值,则有

有效性权值θ表示对应的API函数在恶意样本和正常样本中出现的比率,θ越大,说明其在恶意文档中出现的可能性越大,可作为表征恶意文档的特征;反之,θ越小,则可将其作为正常文档的特征。
本文利用K-means算法,根据有效性权值θ,计算对应的欧氏距离,对训练样本的API调用进行聚类,找到阈值t2并将其分为2个簇(k=2),对应的子集Rt={rj||θj|> t2}则为对应的特征 API集合。算法具体描述如下。


在特征API调用提取算法中,K-means算法的迭代轮数远小于本文的样本集合大小,因此本文算法复杂度为O(|R||D|)。为了提升算法的效率,本文使用样本中出现的所有 API调用集合来代替AcrobatPDF标准中可调用API集合R,从而在一定程度上降低了算法的复杂度。
3.2 分类检测算法
为了对训练集中的良性和恶意样本进行学习,建立模型并利用测试集进一步优化和调整模型,本文采用半监督学习来建立检测模型。由于本文所设计的混合特征在数据结构上存在差异,因此需要选择一种能适应多种不同数据结构的分类算法。决策树算法可以较好地解决此问题,然而决策树存在容易导致过拟合、泛化效果较差等问题,因此,本文采用随机森林算法。随机森林算法是对决策树算法的一个集成和改进,它在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择,能较好地应对本文所设计混合特征存在的异构性,且计算开销小、集成的泛化性较好。最终,选择了10棵树的随机森林算法进行分类器的构建,并采用十折交叉验证过程。
3.3 方法评价指标
评价本文方法的功能指标主要是对恶意 PDF文档的检测效果进行评价,恶意文档分类结果混淆矩阵定义如表2所示。

表2 恶意文档分类结果混淆矩阵
表2中,DMM'表示恶意PDF文档被正确检测为恶意的样本数量;DMB'表示恶意PDF文档被错误检测为良性的样本数量;DBM'表示良性PDF文档被错误检测为恶意的样本数量,DBB'表示良性PDF文档被正确检测为良性的样本数量。对应的几项评价指标如下。
1)真正类率(TPR, true positive rate),又称为检测率,表示被正确检测为恶意的恶意PDF文档数占恶意PDF文档总数的比率,计算式为

2)假正类率(FPR, false positive rate),又叫误报率,表示被错误检测为良性的恶意PDF文档数占恶意PDF文档总数的比率,计算式为

3)准确率(accuracy),表示检测结果是正确的样本数占样本总数的比率,计算式为

4 实验设计与结果分析
4.1 实验样本集合与环境配置
在测试实验中,本文构建了5 928个恶意PDF文档以及5 881个良性PDF文档的实验样本集合。其中,恶意样本主要在VirusTotal上收集而来,类别如表 3所示,包括近几年来 Adobe Reader及Acrobat的高危漏洞以及2004—2011年用户提交到VirusTotal的未经过鉴别分类的恶意PDF文档样本。这部分未鉴别的样本涵盖了常见的利用恶意 PDF文档进行攻击的多种类型,如内嵌代码、内嵌其他恶意文件等。
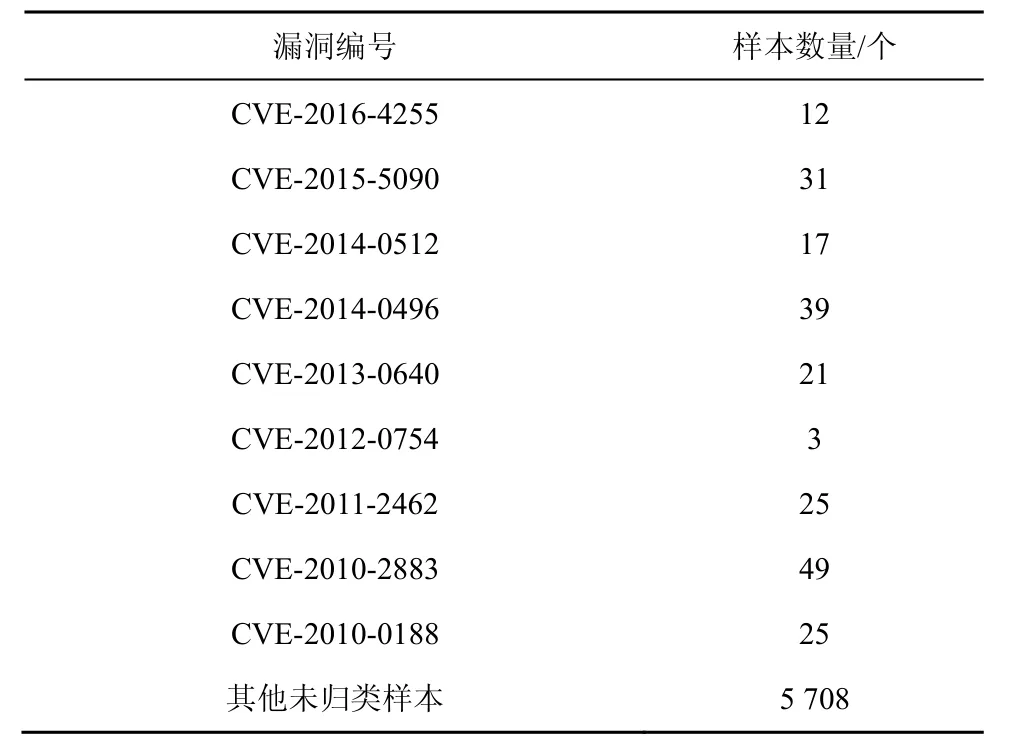
表3 恶意PDF文档样本类别
正常样本主要通过在Google、Yahoo上下载得到,包括论文、销售广告、报告等PDF文档,并通过卡巴斯基杀毒软件检测为正常样本。在此需要强调的是,本文对正常样本集合进行了控制,着重增加了包含3D图像、flash、视频、JavaScript等内容的正常PDF样本,保证了正常样本集合的全面性,降低了由于样本不平衡性所导致的结果误差。正常PDF样本类别如表4所示。

表4 正常PDF文档样本类别
本文随机地将这些数据分为训练样本以及测试样本,其中,训练样本共包括3 949个恶意PDF文档和3 916个良性PDF文档;测试样本包括1 979个恶意样本和1 965个良性样本。实验的软硬件环境配置如表5所示。

表5 实验环境配置
4.2 检测性能测试
为对本文所设计方案的检测性能进行验证,在训练集(3 949个恶意PDF文档和3 916个良性PDF文档)的基础上,对本文的模型进行了训练,从而建立检测模型,并对测试集(1 979个恶意样本和1 965个良性样本)进行测试。最终将测试结果与现有的 3种最新公开的恶意 PDF检测工具(PJScan、PDFRate、Wepawet)相比较。由于 PJScan使用的是单分类SVM算法,其训练数据不包括正常样本,因此本文仅使用训练集以及测试集中的恶意样本作为PJScan的训练集和测试集,从而进行对比实验。而另外2款公开的工具均为在线服务,其中,PDFRate使用了5 000个恶意PDF样本(收集于 Contagio)和 5 000个正常样本进行训练,而Wepawet的训练数据集及大小均未知,因此,想要设计实验对这2款系统进行相同的准确训练并不可行。但通过比较这3类系统与本文方法对测试样本的检测结果,可以在一定程度上反映本系统的检测性能。
4种方法对测试集最终的检测结果如表6所示。本文主要从检测率(真正类率)、误报率(假正类率)和准确率这3个方面对模型的检测性能进行比较,表6中括号内为标准差。
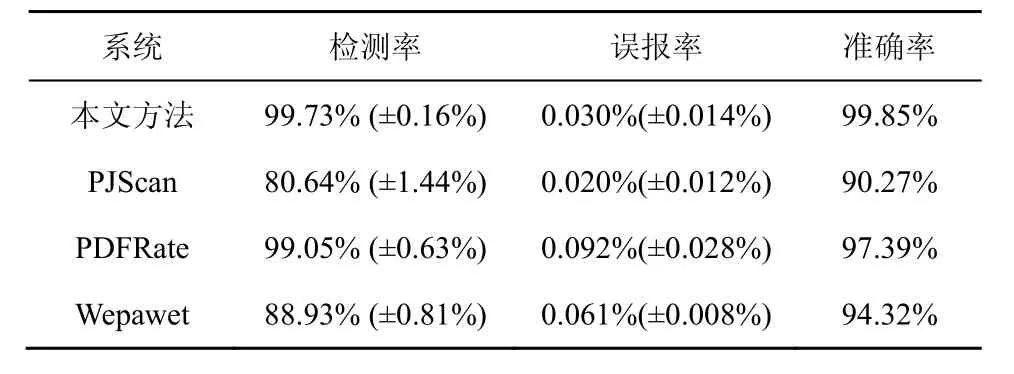
表6 4种方法检测效果对比
在实验过程中发现,所有不包含JavaScript代码的文档均会被PJScan系统分类为正常文档,这是由于PJScan系统仅针对文档中的恶意JavaScript代码进行检测,但这显然是不合理的。此外,Wepawet系统在解析结构不完整的PDF样本时,会出现分析出错的情况,这是由于其没有实现全部Adobe的规范,而仅是模拟嵌入式JavaScript代码和可执行文件的运行结果。
实验结果表明,本文方法在检测性能上明显优于 PJScan和 Wepawet,PJScan的误报率最低,但其检测率相较于本文方法而言差距较大;Wepawet的检测率及误报率均弱于本文方法;PDFRate在检测率方面与本文方法较为接近,而在误报率方面则存在一定的弱势。总地来说,本文方法在检测性能上要优于其他3类工具。
为对本文检测模型的检测效率进行进一步的分析,将本文方法的单个文件的平均检测时间与其他已公开该项数据的方案进行对比,结果如表7所示,其中,本文方法以及PJScan的数据为实验得出,其他方案的数值均为从文献[13-14,22]中获得。此外,由于Wepawet以及PDFRate为在线服务,本文无法得到其准确检测时间,并且在公开文献中也无法找到相关描述,因此本文并未对其进行分析。

表7 几种不同方法检测效率对比
本文方法针对正常文档的平均检测耗时为650 ms,针对恶意文档的平均检测耗时为1 200 ms,可以满足终端机器上的实时检测需求。在实验过程中发现,正常文档的检测耗时主要取决于文档的解析过程,这是由于正常文档往往包含丰富的内容(文本、图片、表格),而仅小部分文档包含JavaScript代码,其文档解析过程耗时较长;恶意文档一般只包含执行漏洞或恶意代码的对象,其具体页面内容较少,因此文档解析过程较快,其检测耗时主要取决于执行JavaScript的时间。
可以看到,检测效率主要与采用的分析类型有关,总体趋势为纯静态分析<动静态混合分析<纯动态分析。PJScan和基于结构路径的方法在检测耗时上比本文方法更优,但本文方法使用了模拟Adobe DOM,可以对PDF文档进行更全面的分析。此外,与同类型的MDScan相比,本文方法的检测耗时更少,主要原因在于本文方法间接地使用特征API调用来表征JavaScript代码特征,而MDScan则是对Shellcode进行进一步的执行与分析。
4.3 抗攻击测试
通过对本文设计的方案进行分析不难发现,攻击者要想攻击本文提出的检测系统,主要可从3个方面进行:1)彻底研究本文系统的检测框架,设计出本文系统无法提取到的恶意特征;2)使用恶意样本破坏本文的数据集,干扰模型的建立过程;3)分析本文选取的检测特征,进而操控样本对应的特征,最终找到可绕过检测的恶意样本。这3种方法均可实现对本文系统进行攻击,但很明显,前两种方法十分复杂,且需要操控本文系统的数据集,因而不易实现;而第三种方法则仅需要攻击者不断修改并提交自制恶意样本到本系统进行检测,直至被误报为正常样本,即攻击成功。
为测试本文系统对上述第三种攻击手段的防御能力,本文选择了基于特征加法的模拟攻击作为对抗模型。模拟攻击是指通过微弱地改变文件的整体结构,从而将恶意内容嵌入正常PDF文档中,形成相应的恶意PDF文档,这种攻击模型已经被证明能十分简便有效地逃避基于结构路径检测系统。为简化实验过程,本文在其思想的基础上,通过直接对已抽取出的恶意PDF文档特征向量进行调整,在其特征向量中加入正常PDF文档的相关特征,从而模拟攻击过程。此过程可以简单地理解为,通过不断增加恶意文档的正常性,来引起检测模型的误报,从而达到逃避检测的目的。
嵌入的良性特征主要从正常样本特征集合Kb和Rb中选取。Kb和Rb为利用本文的特征提取算法对样本集合进行特征提取得到的集合。由于一般情况下,正常样本不包含JavaScript代码,嵌入对应的API调用特征,可能导致文档恶意性的增加,因此,本文仅选择正常样本的关键字特征进行嵌入。定义特征关键字在样本集合中出现的概率p,平均每个样本中出现的次数为c,则特征关键字在样本集合中出现的期望值e可表示为

特征关键字的良性表征度γ为

其中,eb、em分别表示特征关键字在正常样本和恶意样本中出现的期望值。
为最大限度地考量模型应对模拟攻击的能力,本文根据特征关键字的良性表征度,选取了最能表征良性PDF文档的20个特征,具体描述如表8所示。

表8 嵌入的良性特征关键字
从表8可以看到,根据本文的选取原则,得到的特征关键字大部分与 PDF文档中具体内容的展示、存储相关,如提纲、颜色、字体、过滤器等,这与正常PDF文档往往比恶意PDF文档包含更多的实质性内容(如文字、图片、表格等)是一致的。
本文以嵌入的特征数量为变量,在已被本文系统正确检测为恶意的PDF文档中,根据嵌入良性特征的数量,将恶意PDF文档特征向量中对应值修改为正常样本中出现的取整期望值。例如,在恶意PDF文档原特征向量中,上述20项特征的值所组成的向量为(0,0,0,0,1,1,0,1,0,1,0,0,0,0,2,0,0,1,3,0),则本文的操作为当嵌入正常样本数量为 20时,恶意 PDF文档特征中上述 20项特征值将被修改为(3,4,5,1,15,15,2,14,1,15,6,27,4,4,32,5,22,24,41,12)。
通过这种方式,近似地模拟攻击者修改后的恶意PDF文档的特征向量,并对所构建的恶意特征向量进行检测。实验重复此过程5次,统计其每次攻击成功的样本数量并计算其绕过本文检测系统的平均成功率,实验结果如图2所示。

图2 基于特征加法模拟攻击的成功率曲线
从图2可以看到,随着添加良性特征数量的增多,攻击成功的样本数量呈上升趋势,并最后趋于平稳,其中,成功率峰值为1.29%,并在添加的良性特征数量超过 16个后趋于平缓。一般地,特征向量中增加良性特征的数量越多,基于特征加法的模拟攻击成功率就会越高;所添加的良性特征越有代表性,则其攻击成功率越高。而即便选择了 20个最具有代表性的良性特征进行嵌入时,本文系统在应对基于特征加法的模拟攻击的检测率仍能高达98.71%,这充分证明了所提取的混合特征的顽健性。
事实上,在现实攻击中,攻击者并不清楚本文的训练数据集以及所选取的特征,因此,其攻击过程远比上述模拟攻击复杂。攻击者需要对系统内部参数进行逆向工程,例如,通过设计梯度下降攻击来计算逃避模式,构建系统的代理副本等。为此,攻击者需要收集数据集,并且复制本文的提取特征过程,最终构建一个模拟的代理分类器。这种攻击虽然可行,但其攻击过程较复杂,且攻击代价较高。
4.4 实验局限性
实验证明,本文方法与近几年提出的3类公开的检测系统相比,检测率、误报率均有一定的提升,且在检测效率上能满足终端用户实时检测的需求。此外,通过设计基于特征加法的模拟攻击实验,证明了本方案所提取混合特征的顽健性。但是本文的实验仍然存在一定的不足,主要是在验证和研究良性特征数量与混合特征的顽健性、系统的检测率之间的联系缺乏实验证明。理论上,增加混合特征向量中良性特征的数量,可以有效提高检测准确率;但另一方面,良性特征的增多会导致逃避攻击的成功率增高,原因在于攻击者通过在恶意文档中添加良性特征可能会提高分类器错误分类的概率。此外,由于本文采用了聚类算法对特征进行筛选,进而构建了特征向量,特征数量取决于聚类过程,因此未设计实验对特征数量与检测准确率和顽健性之间的关系进行分析,而只是进行了定性分析,但特征数量是否最优、是否会导致过拟合,仍需要进一步的研究与讨论。
5 结束语
本文提出了一种基于混合特征的恶意 PDF文档检测方法,通过对文档进行动静态分析,对文档基本信息、结构信息和API调用信息进行聚合,抽取出表征文档安全性的混合特征,并利用随机森林算法构建检测模型,在一定程度上解决了现有检测模型易被逃避检测的缺陷,提高了模型的顽健性。但本文方法还存在一些有待改进的地方:1)所选取的3类特征相互之间无权重关系,而实际上API调用特征往往更能反映文档的安全性,其权重还需通过实验进一步研究与讨论;2)抗攻击实验中未对特征数量与检测模型的准确性、顽健性之间的相互关系进行分析,无法确定模型选取的特征数量是否最优、是否会导致过拟合;3)模型的检测效果对训练数据的质量较为敏感,且存在部分无法解析的文档,需设计额外的操作进行筛选和剔除,还需进一步对解析器进行改进和优化。
猜你喜欢
客联(2022年3期)2022-05-31
华人时刊(2022年1期)2022-04-26
中国新闻周刊(2021年26期)2021-07-27
商品与质量(2019年34期)2019-11-29
动漫界·幼教365(大班)(2019年10期)2019-10-28
计算机系统应用(2019年3期)2019-03-11
电脑爱好者(2017年7期)2017-05-06
中国信息化·学术版(2013年1期)2013-05-28
环球时报(2009-11-25)2009-11-25
