
基于变分模态分解与多尺度排列熵的生物组织变性识别*
2019-03-11 08:55:40刘备胡伟鹏邹孝丁亚军钱盛友
物理学报 2019年2期
刘备 胡伟鹏 邹孝 丁亚军 钱盛友
(湖南师范大学物理与电子科学学院, 长沙 410081)
(2018 年9 月26日收到; 2018 年10 月26日收到修改稿)
根据高强度聚焦超声(HIFU)治疗中超声散射回波信号的特点, 本文利用变分模态分解(VMD)与多尺度排列熵(MPE)对生物组织变性识别进行了研究. 首先对生物组织中的超声散射回波信号进行变分模态分解, 根据各阶模态的功率谱信息熵值分离出噪声分量和有用分量; 对分离出的有用信号进行重构并提取其多尺度排列熵; 然后通过Gustafson-Kessel (GK)模糊聚类确定聚类中心, 采用欧氏贴近度与择近原则对生物组织进行变性识别. 将所提方法应用于HIFU治疗中超声散射回波信号实验数据, 用遗传算法对多尺度排列熵的参数优化后, 对293例未变性组织和变性组织的超声散射回波信号数据进行了多尺度排列熵分析, 发现变性组织的超声散射回波信号的多尺度排列熵值要高于未变性组织; 多尺度排列熵可以较好地识别生物组织是否变性. 相对于EMD-MPE-GK模糊聚类以及VMD-小波熵(WE)-GK模糊聚类变性识别方法, 本文所提方法中变性与未变性组织特征交叠区域数据点更少, 聚类效果和分类性能更好; 本实验环境下生物组织变性识别结果表明, 该方法的识别率更高, 高达93.81%.
1 引 言
高强度聚焦超声(high intensity focused ultrasound, HIFU)治疗是一种新的无创肿瘤治疗技术. 它通过聚焦方式将声能聚集于治疗靶区, 使靶区产生高温, 从而使病变组织细胞内的蛋白质发生固化、变性和坏死, 同时又不损伤靶区之外的正常组织. 通过监测生物组织的变性情况, 能掌握HIFU的治疗效果, 对确保HIFU治疗的安全高效有重要意义[1-3]. 迄今为止, 超声领域的研究人员从多个方面对所取得的超声信号进行研究, 期望提取出能准确反映组织损伤变性的特征参数, 如回波能量、声衰减系数、频率偏移、声速和熵等[4-8]. 当组织温度升高到65 ℃以上时, 背散射信号能量会发生显著变化[4-9]. Seip和Ebbini[10]采用回波信号的能量特征来检测组织损伤变性, 实验结果表明,信号能量识别准确率达到82%. 在文献[11]中, 生物组织的超声衰减系数特征被用于估计组织损伤区域的温度. 盛磊等[6]利用频率偏移等特征参数检测HIFU导致的组织凝固性坏死. 声速可以非侵入式地估计组织温度, 但是声速受非线性以及热膨胀的影响, 导致通过声速变化测量体内温度的准确性大大降低[7-12]. 明文等[8]采用超声散射回波信号的小波熵(wavelet entropy, WE)特征对HUFU治疗过程中的组织损伤变性进行评价研究, 同时对组织样本进行损伤级归类. 但到目前为止, 将超声回波信号的多尺度排列熵(multi-scale permutation entropy, MPE)特征用于生物组织变性识别是否有效的研究还未见报道.
经验模态分解(empirical mode decomposition,EMD)是将一个时间序列信号分解成一组有限的本征模态函数[13], 并且文献[14]已经将其应用至从人体获得的超声回波信号, 然而, EMD存在端点效应、模态混叠问题[15]. 为了解决上述问题,Dragomiretskiy和Zosso[15]提出一种新的变分模态分解(variational mode decomposition, VMD)方法, 能较好地抑制信号EMD过程中的端点效应和模态混叠现象, 对噪声具有更强的鲁棒性.
从非线性角度分析生物组织中获取的信号, 生物组织的损伤变性会导致信号的复杂度不同. 目前非线性分析算法可以通过其熵值有效地分析信号的复杂度, 例如尺度熵、近似熵、多尺度熵等[16-18].排列熵作为一种非线性分析算法, 具有计算简单、抗噪能力强、鲁棒性强的优点, 因此被广泛应用于时间序列的复杂性分析中[19]. 多尺度排列熵将多尺度和排列熵结合起来, 可以更加有效地分析序列信息[20,21]. 本文从非线性角度分析生物组织中的超声散射回波信号, 利用多尺度排列熵算法研究未变性生物组织和变性生物组织超声散射回波信号的差异, 为HIFU治疗诊断提供有效的依据和帮助. 然而, 若MPE算法中嵌入维数和尺度因子参数设置不合理, 将导致算法无法达到最佳的处理效果. 同时, 由于生物组织从未变性状态到变性状态的演变是一个渐变的过程[22], 因此提取的组织变性特征具有一定的模糊性, GK模糊聚类算法为解决这类问题提供了一条有效途径[23].
本文结合VMD与MPE算法的优点, 对生物组织变性的特征进行提取, 同时采用遗传算法确定多尺度排列熵尺度因子参数, 讨论了本实验环境下多尺度排列熵的最佳嵌入维数; 并用GK模糊聚类算法实现了生物组织变性的识别分类.
2 原理与方法
2.1 VMD理论
VMD是一种基于维纳滤波, 希尔伯特变换和外差解调的新型多分量信号分解算法. VMD可以将一个实际信号f(t) 分解成K个离散的模态µk(k=1,2,3,···,K), 与EMD算法不同,µk在频域中的带宽都具有特定的稀疏属性, 是调幅调频(AM-FM)信号, 可以有效地抑制EMD中出现的模态混叠现象. 每个µk紧凑围绕相应的中心频率,并且其带宽通过高斯平滑解调获得. VMD处理过程中的约束变分问题为
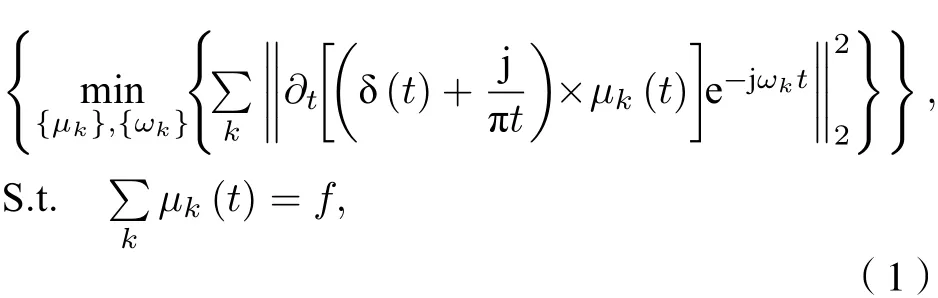
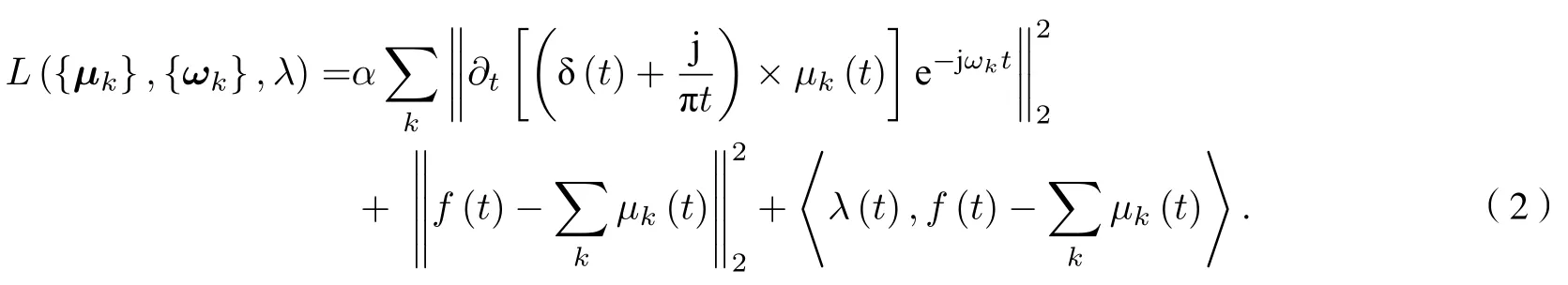
VMD将信号分解为K个模态分量的具体步骤如下:
1) 初始化
2)µk和ωk分别由(3)式和(4)式迭代更新:
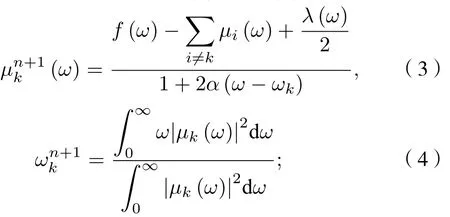
3) 根据(5)式更新λ:

4) 重复步骤 2)和 3), 直至满足迭代终止条件
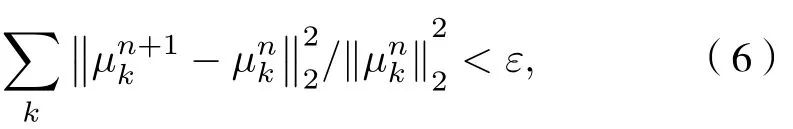
式中ε为判别精度,ε>0 ;
5) 输出结果, 得到K个模态分量.
2.2 功率谱信息熵
基于功率谱信息熵判断各模态分量为有效超声散射回波信号还是噪声以及无效超声散射回波信号的方法流程如下.
1) 计算各模态的功率谱, 并对幅值进行归一化.
2) 根据归一化后功率谱的最大值和最小值,得出功率谱的变化范围. 对功率谱的变化范围进行分段. 例如, 若信号归一化后功率谱幅值的变化范围是0—1, 分成10段, 那么幅值范围为0—0.1为第一段, 0.1—0.2为第二段, 依次类推.
3) 统计每一段在功率谱幅值中出现的次数,并求出该段在整个数据点中出现的概率.
4) 按照(7)式求解信息熵, 并根据熵值判断该模态是否为噪声分量或无效超声散射信号:
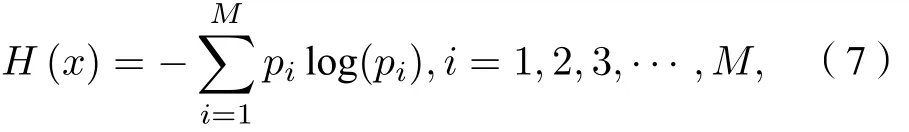
H(x)为功率谱信息熵, 其中pi表示功率谱分段后第i段所对应的概率,M表示总共的分段数.
2.3 多尺度排列熵
多尺度排列熵是在排列熵基础上的改进, 基本思想是将时间序列进行多尺度粗粒化,然后计算其排列熵. 计算具体步骤如下.
1) 对序列长度为N的时间序列X={xi,i=1,2,···,N}进行粗粒化处理, 得到粗粒化序列y(s)j
得到粗粒化序列

式中s为尺度因子; [N/s]表示对N/s取整.
2) 对y(s)进行时间重构得到
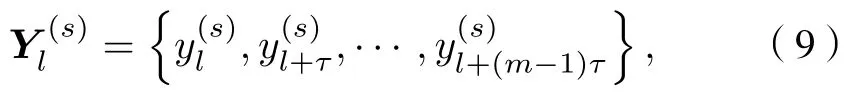
其中m为嵌入维数,τ为延迟时间;l为第l个重构分量,l=1,2,···,N-(m-1)τ.
4) 根据(10)式计算每个粗粒化序列的排列熵, 由此得到时间序列在多尺度下的排列熵.
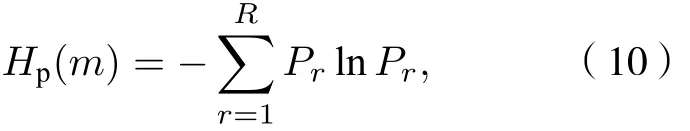
当Pr=1/m! 时 ,Hp(m) 达 到 最 大 值 l n(m!) ; 通 常将多尺度排列熵值Hp(m) 进行归一化处理, 即
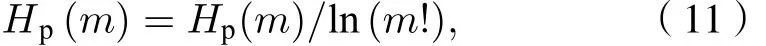
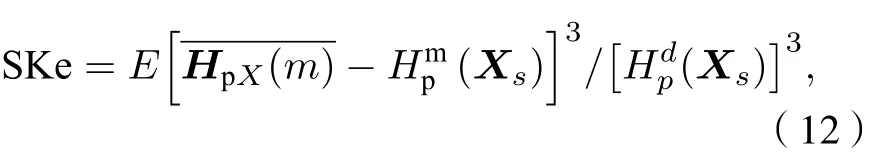

2.4 GK聚类与变性识别
GK模糊聚类算法是利用协方差矩阵能自适应动态度量的模糊聚类算法, 假设输入数据为GK模糊聚类的目标函数为
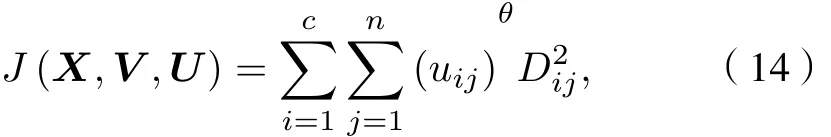
式中θ≥1 为模糊指数, 模糊指数会影响聚类效果,其值太大会导致各类之间相互重叠;Dij为第j个样本与第i类聚类中心的马氏距离,Di2j是一个平方内积范数.
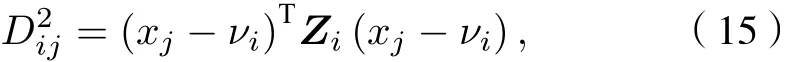

利用拉格朗日乘法对目标函数进行优化, 使(14)式取得极小值, 其必要条件为


GK模糊聚类算法的具体步骤如下:
1) 确定聚类中心数目c以及模糊指数θ, 根据(16)式对隶属度矩阵U进行初始化, 通过(18)式计算聚类中心νi;
2) 计算协方差矩阵Fi
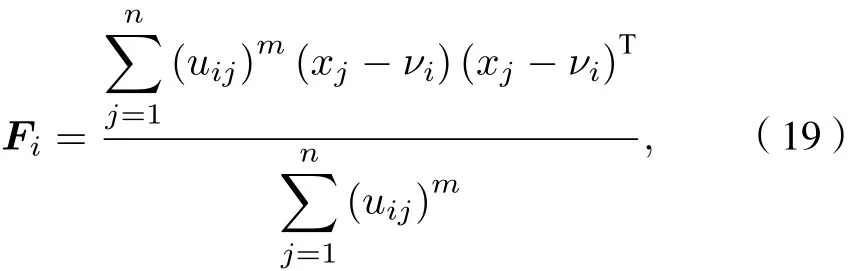
由协方差矩阵Fi求出正定对称矩阵Zi, 之后根据(15)式计算出平方内积范数利用得到的平方内积范数根据(17)式更新隶属度矩阵U,若不满足则增加迭代次数,若满足判断式, 则终止迭代运算.
GK模糊聚类的聚类效果可用划分系数和Xie-Beni (XB)指数进行检验.
划分系数为
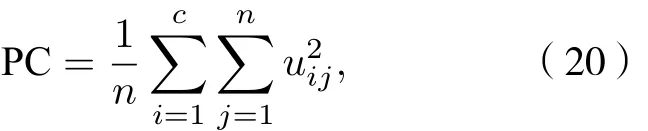
Xie-Beni指数为
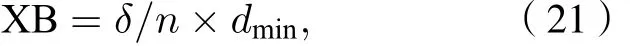
式中δ为类的平均方差,dmin是类间最短模糊距离;对于聚类效果评价, 其中PC越接近1, 代表划分越清晰, 反之划分越模糊; XB越小, 代表类间分离的聚类就越好.
本文采用欧氏贴进度和择近原则实现组织变性模式识别. 贴近度越大, 代表两个模糊子集的相近程度越大. 对于待识别样本模糊子集A、标准聚类中心模糊子集B, 其计算如下:
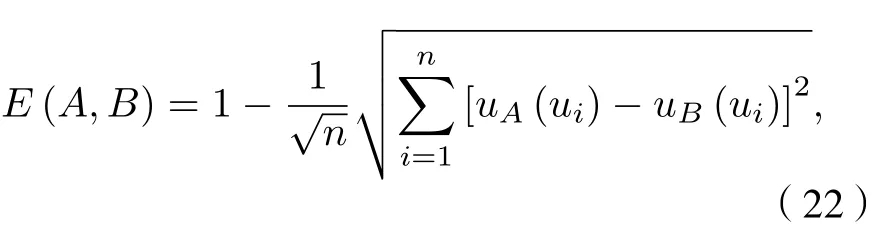
3 模拟仿真及应用实例
3.1 信号分解与去噪
为研究EMD与VMD算法对噪声的鲁棒性,对含噪仿真信号进行分析, 所采用的仿真信号表达式为cos(2π·288t)+η, 其中η为高斯白噪声, 标准偏差取0.1. 仿真信号及各对应成分如图1所示.

图1 仿真信号及其对应非噪声成分的时域图 (a)加入噪声的仿真信号时域图; (b)对应非噪声成分的时域图Fig.1. Time-domain diagram of the simulated signal and its non-noise components: (a) Time-domain diagram of the simulated signal with added noise; (b) time-domain diagram corresponding to non-noise components.
图2为加入噪声的仿真信号经EMD和VMD处理后的结果. 由图2(b)可以明显看出, 随着EMD分解层数增多, 分解结果出现严重失真, 产生虚假分量, 即模态混叠现象. 而根据图2(a)的VMD结果, 发现分解得到的前三个单频模态分量与原信号对应各成分比较一致, 说明VMD可以较好地解决信号分解过程中的模态混叠现象, VMD对噪声具有较强的鲁棒性.
图3(a)为实验获得的超声回波信号. 实验中用HIFU辐照新鲜离体猪肉组织来改变其特性, 通过B超监控来获取超声回波信号, 并经数字示波器(Model MDO3032; Tektronix)转化为数字信号后进行保存. B超探头的中心频率为3.5 MHz. 预先设定VMD算法中的分解模态的个数K= 5, 超声回波信号经VMD算法分解后, 不同K值下各模态分量如图3(b)所示.
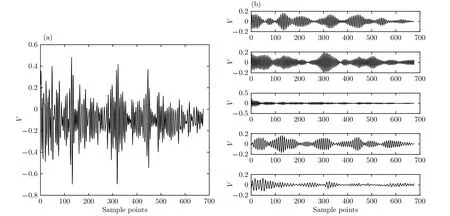
图3 实际超声回波信号与VMD结果 (a)实际超声回波信号; (b)超声回波信号VMD结果Fig.3. Actual ultrasonic echo signals and their VMD results: (a) Actual ultrasonic echo signals; (b) VMD results of ultrasonic echo signals.
对于每个模态分量, 其对应的功率谱信息熵值越小, 就表示是噪声分量或无效超声散射回波分量的概率越大, 反之就认为其中含有用超声散射回波分量概率越大. 在本实验环境下得到的超声散射回波信号经过VMD算法分解得到各阶模态分量, 计算各模态的功率谱, 利用2.2节的方法得出各模态的功率谱信息熵. 实验发现各模态分量的功率谱幅值分段数为16—21时, 噪声分量、无效超声散射回波模态分量与有用超声散射回波模态分量区分效果最佳. 对于本实验环境下的293例超声回波数据经过VMD得到的各阶模态分量, 其中噪声分量和无效超声散射回波信号模态分量的功率谱信息熵在0.028—0.055之间; 如果模态分量中含有明显的散射信号波形, 其功率谱信息熵在0.13—0.35之间. 上述两类模态分量功率谱信息熵值的差异, 可以较好地区分噪声分量、无效超声散射回波模态分量和有用超声散射回波模态分量.
3.2 多尺度排列熵的计算
通过筛选功率谱信息熵值在0.13—0.35的模态分量对信号进行重构, 对重构后的信号进行参数优化后的MPE分析, 利用遗传算法来优化尺度因子s. 参数设置为: 最大进化代数为100; 种群最大数量为20; 交叉概率为0.4; 变异概率为0.09; 超声回波信号的截取点数为675, 一般来说, 嵌入维数m通常取3—8, 延迟时间τ=2 . 对重构后的超声散射回波信号进行尺度因子参数优化, 取整后得到多尺度排列熵算法的尺度因子优化参数. 三组样本的MPE参数优化结果: 第一组和第二组样本的MPE分析中, 尺度因子参数为12; 第三组样本的MPE分析中, 尺度因子参数为13.
每组样本包括总共15例超声回波信号数据,其中未变性状态8例, 变性状态7例. 图4为嵌入维数m分别取3, 5和7时样本1的MPE随尺度因子的变化情况.
从图4可以明显看出, 嵌入维数m= 3和5时, 变性组织与未变性组织各尺度因子下的MPE值有较多交叠, 此时MPE不能较好地区分变性组织和未变性组织; 而嵌入维数m= 7时, 变性组织和未变性组织的MPE值有明显区别, 变性组织的多尺度排列熵值要明显高于未变性组织的熵值. 表1为嵌入维数为7时, 三组样本中变性与未变性组织的各尺度排列熵平均值.
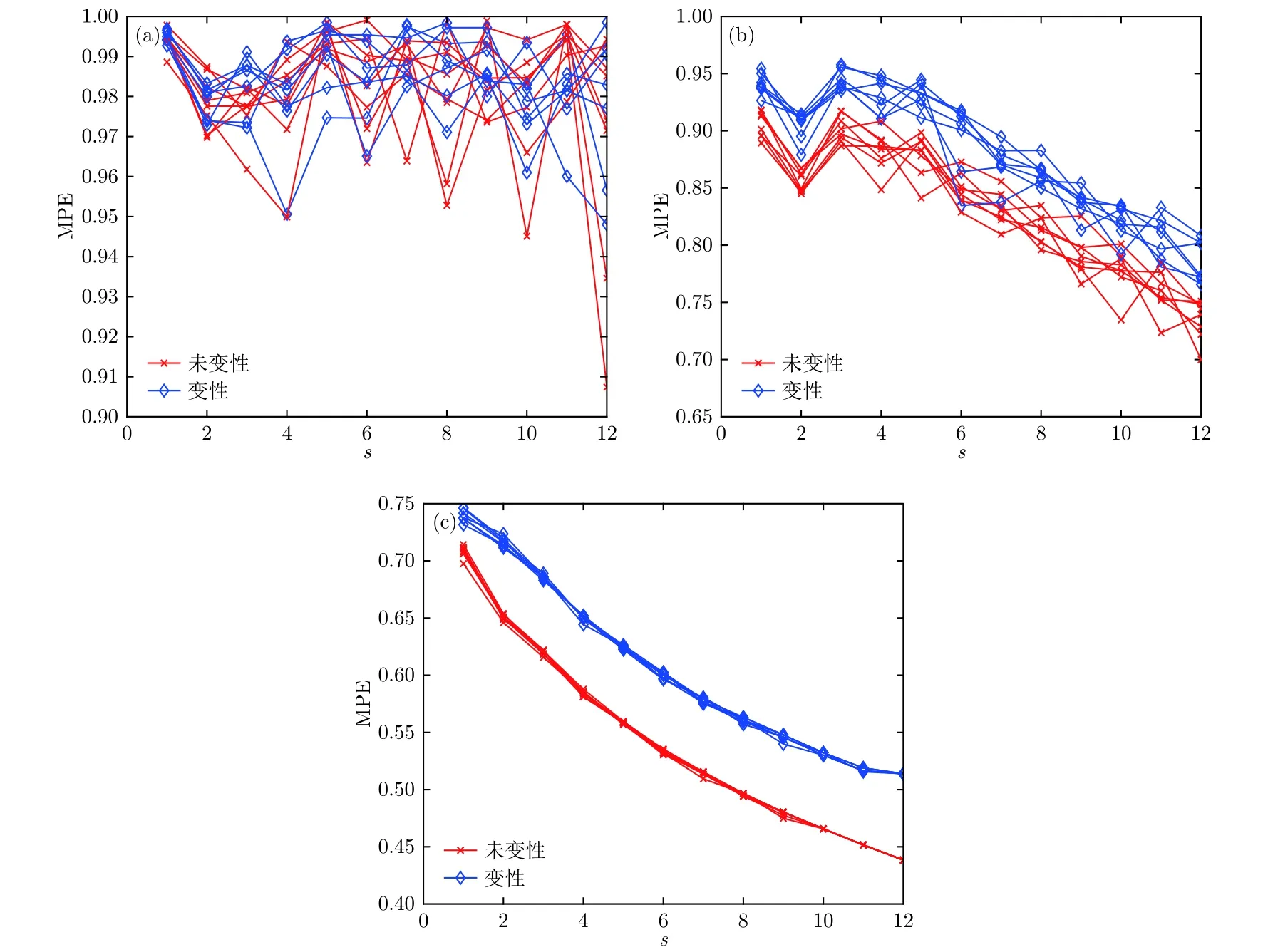
图4 不同嵌入维数时变性与未变性情况的MPE分布 (a) m= 3; (b) m= 5; (c) m= 7Fig.4. MPE distribution of denatured and undenatured cases with different embedding dimension: (a) m= 3; (b) m= 5; (c) m= 7.
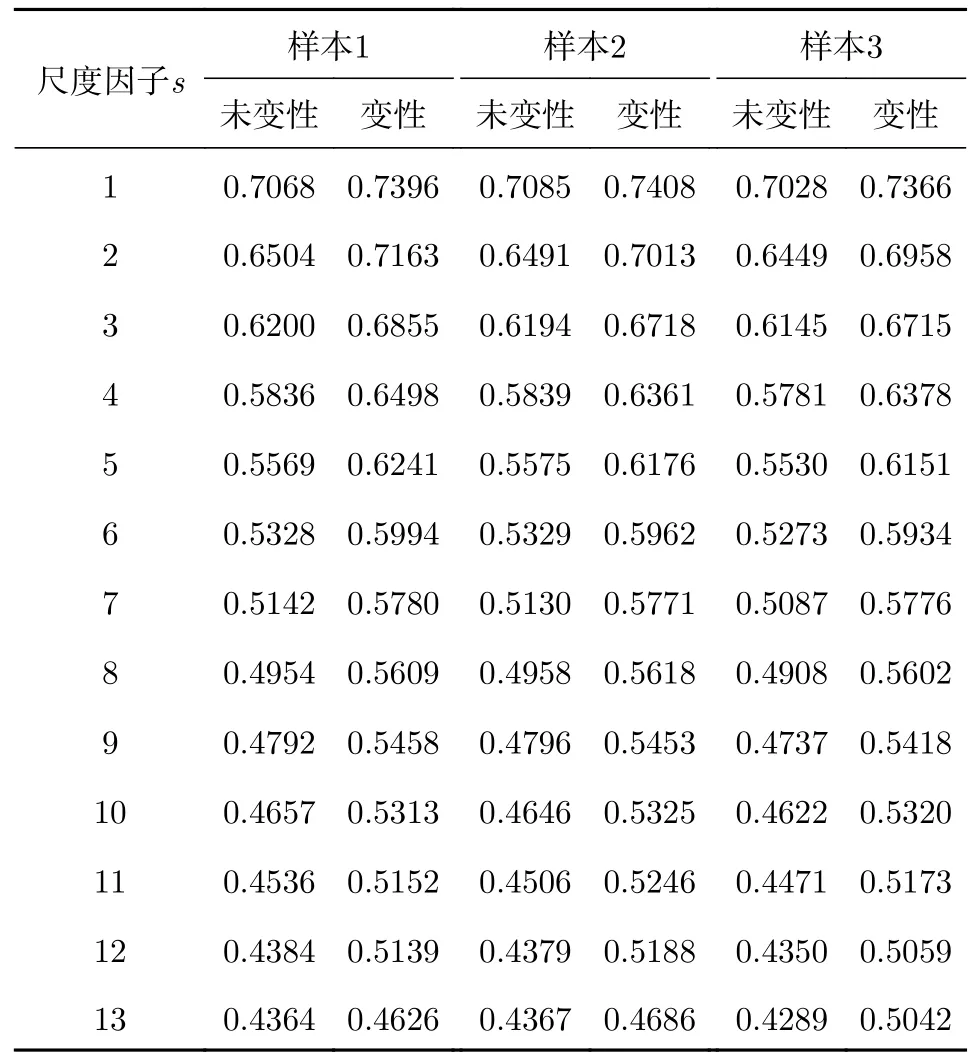
表1 三组样本在嵌入维数m= 7时各尺度下排列熵平均值Table 1. The average entropy of the three samples at each scale when the embedding dimension m= 7.
由表1可见, 嵌入维数为7时, 尺度因子改变,同一样本的MPE值发生变化; 尺度因子越大,MPE值越小, 且在不同尺度因子下, 变性组织的MPE值均高于未变性组织的MPE值. 另外, 尺度因子为12时, 第一组样本与第二组样本变性状态与未变性状态的MPE平均熵值差别较大, 与本文尺度因子参数优化结果相符合; 三组样本的MPE值随尺度因子的变化趋势类似. 后续研究中,延迟时间τ为2, 嵌入维数m取为7, 综合考虑优化结果选取尺度因子s为12. 通过以上分析可以发现, MPE特征可以作为识别生物组织是否变性的一个重要特征参数.
3.3 GK聚类与生物组织变性识别
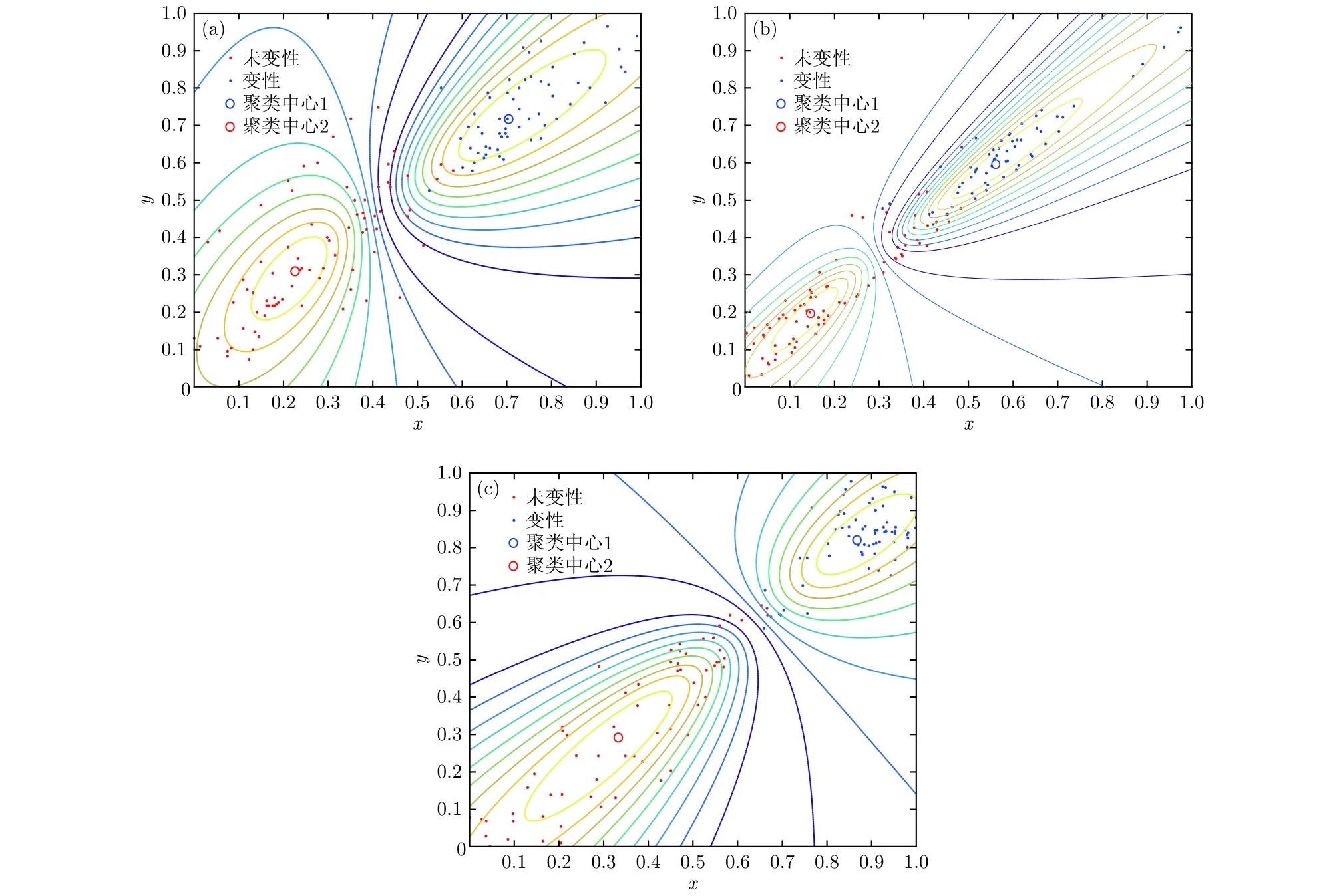
图5 不同聚类方法对未变性与变性生物组织超声散射回波信号的聚类效果 (a) EMD-MPE-GK; (b) VMD-WE-GK;(c) VMD-MPE-GKFig.5. Clustering effect on ultrasonic scattering echo signals of undenatured and denatured biological tissues through different clustering methods: (a) EMD-MPE-GK; (b) VMD-WE-GK; (c) VMD-MPE-GK.
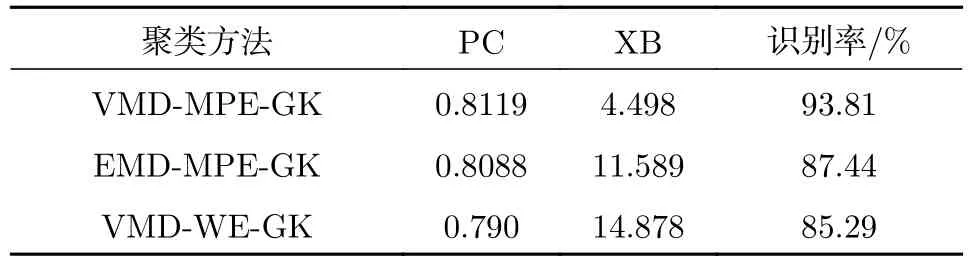
表2 变性与未变性组织识别结果Table 2. Recognition results of denatured and undenatured tissues.
取超声散射回波信号的重构后信号293例数据, 构成20组样本. 随机选取其中150例数据(共10组样本)作为已知样本, 后143例数据(10组样本)作为待识别样本, 选取各自的参数优化后的MPE值作为特征参量. 提取的特征向量经过GK模糊聚类算法处理后, 结合择近原则计算欧氏贴近度, 从而实现生物组织变性的模式识别. 为进一步验证所提方法的有效性, 分别采用EMD-MPE方法以及文献[8]报道的WE分析(VMD-WE)方法提取特征参量, 最后采用GK模糊聚类对生物组织变性分类识别, 图5分别为利用EMD-MPE,VMD-WE和VMD-MPE提取组织超声散射回波信号多尺度排列熵的特征向量、经GK模糊聚类后的二维空间分布以及二维等高线. 计算可得出各种方法的聚类PC, XB以及变性识别率, 识别结果见表2. 由图5可以看出, 带有组织变性与未变性特征的超声散射回波信号经本文方法处理后, 多尺度排列熵特征参量按照变性与未变性基本分布在2个聚类中心的周围, 并且不同类型之间区分较为明显, 相较于EMD-MPE-GK聚类和VMD-WEGK聚类方法, 本文方法变性与未变性特征二维空间交叠区域数据点更少, 而且隶属度等高线区分变性组织与未变性组织的误识别数据点更少, 类内变性MPE特征更紧密, 分类效果更理想, 这说明基于VMD, MPE和GK模糊聚类的算法对生物组织是否变性具有较好的分类识别效果.
由表2可知, 对比VMD-MPE-GK聚类方法与EMD-MPE-GK聚类方法的识别结果, VMD分解重构信号的XB更小, PC与变性识别率高于EMD分解重构信号; 对比VMD-MPE-GK聚类方法与VMD-WE-GK聚类方法的识别结果, MPE的聚类效果优于WE, 且变性识别率更高. 基于VMD, MPE和GK模糊聚类的生物组织变性识别方法能够较准确地识别生物组织是否变性, 变性识别率高达93.81%, 且本文所提方法相较于EMDMPE-GK聚类和VMD-WE-GK聚类方法, PC系数更接近1, XB指数更小, 从而证明了所提方法对生物组织变性识别分类的优越性.
4 结 论
本文针对HIFU治疗中超声散射回波信号的特点, 利用VMD与MPE对生物组织变性识别进行了研究, 得出以下结论.
1) VMD能够有效分解出包含生物组织变性信息的超声散射回波信号模态分量; 利用参数优化后的多尺度排列熵对重构后的超声散射回波信号进行特征提取, 结果表明, 选取延迟时间为2, 嵌入维数为7, 尺度因子为12时, 变性生物组织超声散射回波信号的多尺度排列熵值要高于未变性生物组织的熵值, 多尺度排列熵可以较好地区分未变性组织和变性组织.
2) 利用多尺度排列熵对VMD去噪后超声信号进行特征提取, 并结合GK模糊聚类和欧氏贴近度进行变性识别; 与EMD-MPE-GK聚类和VMDWE-GK聚类方法相比, 本文方法的聚类效果和变性识别率结果证明了所提方法的分类性能更好, 变性识别率更高, 可用于HIFU治疗中生物组织变性识别.
猜你喜欢
中国造纸(2022年9期)2022-11-25 02:24:54
数学物理学报(2022年4期)2022-08-22 04:06:44
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
数学物理学报(2020年3期)2020-07-27 01:19:56
环球时报(2019-04-03)2019-04-03 04:15:14
幸福·健康版(2016年10期)2016-11-17 11:21:46
数学物理学报(2016年5期)2016-08-24 07:38:40
太空探索(2016年5期)2016-07-12 15:17:55
数学物理学报(2016年6期)2016-04-16 04:40:58
西藏科技(2015年10期)2015-09-26 12:10:16
