
基于SSM和Lucene的水利文献检索系统设计
2019-03-07 03:23孙敏,鞠勇
水利信息化 2019年1期
孙 敏 ,鞠 勇
(1. 高邮市水利局,江苏 高邮 225600;2. 中科遥感科技集团有限公司,天津 300384)
1 研究背景
随着信息技术的飞速发展,人们对信息获取的准确性和速度方面的要求也越来越高。如何快速准确地获取想要的信息成为研究的重点和难点。水利系统[1]的文献资源非常丰富,具有广泛的来源,庞大的数据量和较强的时效性,采用传统的基于通用文献检索系统的方式难以获得最新的信息;与此同时,不少实用的水利文档也并不以正式出版物的形式出版,很难进入通用文献检索系统。而且通用检索系统都是以关键词检索为主,所以对检索的关键词与系统设置的目标词的匹配度要求较高,如果用户对水利领域没有先验知识储备,输入的关键词准确性不够高,则检索结果往往不尽人意。因此,传统的文献检索方式已经不适合当前水利信息化特定的发展和需求。
为了满足对水利文献检索的要求,针对水利领域科技文献的特点,构建水利领域科技文献的专有数据库,采用全文检索技术,通过对数据库中的文献信息建立索引提高检索速度[2];采用全文检索框架Lucene,设计面向水利领域的文献检索系统。
拟从以下 3 个方面进行研究:
1)文献检索的相关技术的研究。研究全文检索的相关知识及当前的技术热点等,同时对于如何将全文检索技术应用到水利文献检索系统中进行深入研究。
2)Lucene 框架的优化。深入学习 Lucene 框架及其采用的分词和检索算法。通过深入了解水利系统的专有概念和特点,结合 Lucene 建立索引和检索的基本过程,深入学习其原理并进行优化。
3)面向水利领域的文献检索系统的设计。对面向水利领域的文献检索系统进行分析、设计,完成本系统的需求分析及系统设计。
2 相关工作
文献检索是获取所需文献的过程,文献检索系统是用来让用户通过查询语句从系统索引文件中获取文献的。20 世纪 80 年代之前获取传统的水利文献的方式主要为手工检索,用户使用文献检索工具,通过关键词、作者等检索项查找文献信息,使用该方法不仅需要大量的时间也需要大量的人力。随着计算机的发展与普及,该方法已经慢慢被淘汰。在 20 世纪 80 年代之后,计算机已经逐渐的发展,各种检索机构也开始慢慢地将文献检索数据融入到计算机中,出现了光盘检索方式,通过将文献信息存储到光盘中进行查找。在 20 世纪 90 年代以后,伴随着全文检索技术的发展,现在主要采用联机检索方式来进行文献检索的工作,主要有如下方式:
1)在检索工具中,根据输入文献的标题、作者、关键词等信息检索到该文献,再根据系统提供的链接获取全文信息。
2)使用搜索引擎,对文献进行检索。
在目前的文献检索系统中,文献的领域范围很大,检索功能十分强大,用户在输入专业查询关键词时,无法准确的选择检索信息,因此检索出来的结果很多,一般很少会有人看完几千条的文献信息,并且由于文献领域的多样性,检索结果中会包含大量的非用户需要信息。如果用户输入关键词的英文时,由于与目标关键词相差很大的时候或者数据库中只包含了中文目标关键词没有英文关键词时,则检索出来的结果匹配度会降低,同时现有的文献检索系统中的数据信息有一些是属于半结构数据,在 Web 检索系统使用半结构数据也是信息检索的一个重要内容。
因此在传统信息检索技术的基础上,首先将现有的水利科技文献进行分类,然后实现关键词中英互搜功能,要求用户输入查询语句,系统在对查询语句进行分词后,检索出包含这些关键字的中文及英文文献。在这个过程中,通过对分词后的词进行翻译,得到中英文关键词,再进行多关键词检索。研究面向水利领域[3]的文献检索系统,可以更好满足水利系统用户的需求。
3 关键技术
针对现有文献检索系统不能有效针对水利领域文献检索[4]的情况,首先以项目、工程、学科、来源单位和文献类型等几个标准为依据,依照《中国水利百科全书》(2 版)对现有水利科技文献进行分类,从水利领域的广度和深度进行划分[5],逐层深入。水利领域的科技文献分类体系结构如表 1 所示。
水利领域科技文献的信息属性,主要包括学文献编号、文献标题、学科分类、作者、摘要、关键词、全文信息和文献来源。将水利领域的科技文献分为 10 个基本类别,水力学、工程水文学,治河、防洪工程,运河、航道工程,农田水利工程,海岸工程、近海工程,港湾工程,湖泊工程,水库、水电站工程,水工建筑物和水利工程机械,下面还有二级和三级分类,这样就构成了水利领域科技文献[6]的专有数据库[7]。
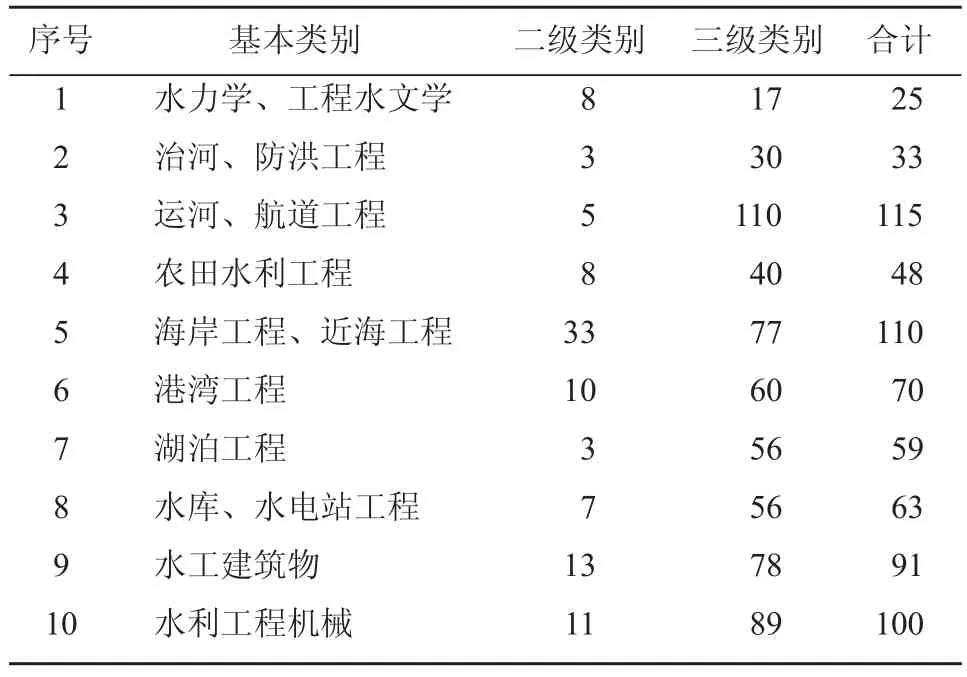
表1 水利领域科技文献学科分类 个
3.1 全文检索
采用全文检索的方式,对文档进行分析之后使用分词器将水利领域的科技文献数据库中的文档内容分词,然后建立双语索引,将词在文档中出现的位置和频率保存在索引文件中,在进行检索时,检索程序根据查询语句自发到索引文件中查找相关信息,并将检索结果反馈给用户[8]。
在水利文献检索系统中,应该依据水利文献内容的专有名词特点与全文检索的特点结合起来,在考虑系统效率的前提下设计索引文件的索引域及其存储方式和是否需要中英文分词,以便于系统能够更加准确、迅速地从文档中提取有价值的信息,然后对数据进行处理保存到索引文件中,用户即可对系统进行检索操作。全文检索的过程如图 1 所示。全文检索的 2 个过程:1)创建索引。从水利文献中提取有用的信息并对其重新组织,然后创建索引。2)搜索索引。指根据查询语句去索引文件中查找与之对应的索引,然后将结果反馈给用户。
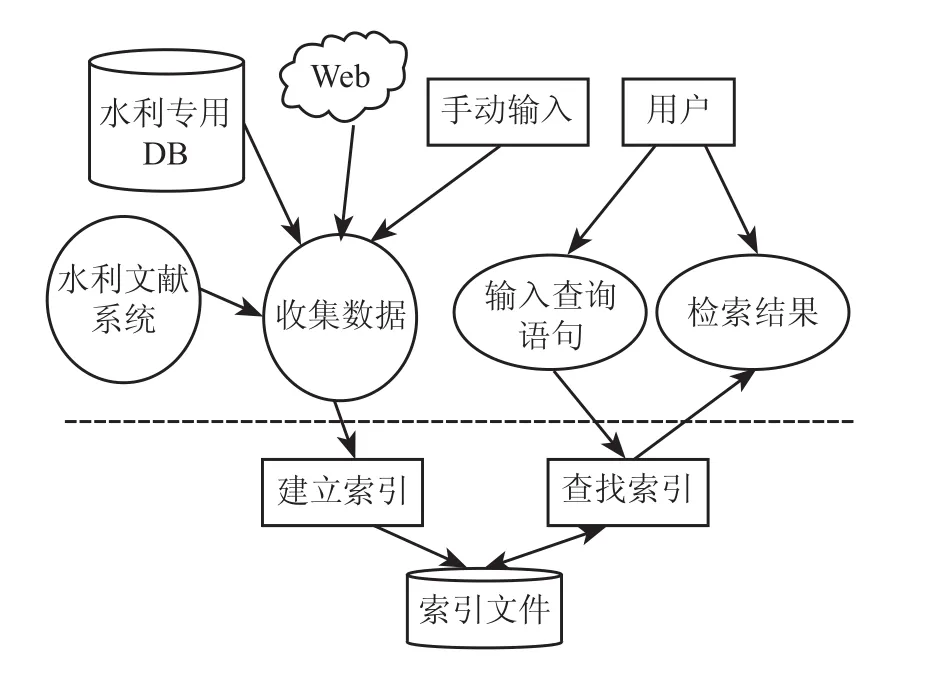
图1 全文检索的过程
3.2 Lucene 和 SSM 框架
水利文献检索系统中检索功能的实现采用Lucene 全文检索框架。Lucene 是一个高性能、可扩展的全文检索框架,它提供了一系列的 API,可以利用爬虫获取的水利科技文献创建索引,根据文献、二级、三级类别及详细内容,比如文献编号、标题、作者、摘要、关键词等进行分词,根据用户输入的查询条件,从水利文献检索专有库中返回检索结果,生成页面形式供用户查看[9]。
Lucene 作为一个优秀的全文检索引擎,它的系统结构采用了面向对象的设计方法,使检索系统达到低耦合高效率,方便用户在此基础上进行二次开发。Lucene 中最核心的功能是索引和检索,良好的索引文件可以提高搜索响应速度。在 Lucene 中文件都可以转成方便检索的文本格式,文件类型可以是网页、各种本地文档等。
SSM 框架由 Spring,SpringMVC,MyBatis 3 个开源框架整合而成,常作为 Web 项目的框架。本系统除了使用 B/S 结构,同时还使用了 Maven 实现对软件项目的管理,这些技术的整合搭建出一个健壮的 J2EE 应用。水利文献检索系统的主要系统架构为,使用持久层框架 Mybatis 构建数据持久化层 Model,通过数据访问层 dao 与数据库进行交互,在服务层 service,进行结合水利领域专业词典建立分词接口进行全文检索服务,接着通过控制层controller,将前端控制器分发控制用户的请求给相应的服务层,最后在视图层用于展示检索出的水利文献结果。系统架构如图 2 所示。
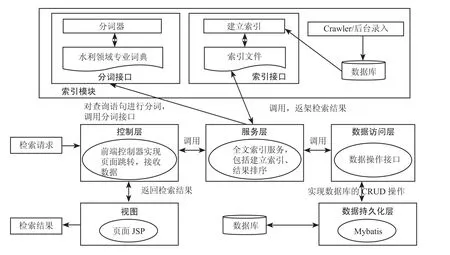
图2 系统架构图
4 索引建立
针对水利领域,检索系统需要水利领域的专业词汇的词典,在实际开发中,需要开发者根据实际需要扩展词库,根据前文的水利领域文献的三级分类,建立水利领域科技文献的专有数据库,组成水利领域词典 waterconservation info.dic,在 Lucene 框架中引入 ICTCLAS(汉语词法分析系统)的分词功能,使用 CHMM(层叠马尔科夫模型)进行分词,首先将文档分成单独的词汇,对其去除停用词得到Token(词元),然后对 Token 作进一步处理,例如将英文单词的大写转成小写、将英文单词缩减或转为词根形式等,最后得到的结果被称为 Term(词)。收集了水利领域的专业术语实现对 ICTCLAS 的词库扩展,实验证明扩展后的分词对水利领域的文献分词更准确、更快。
水利文献系统的索引数据有 2 个来源:1)利用爬虫获取的数据;2)管理员录入的文献数据信息[10]。
在建立索引时,把中英文关键词对应起来,把同义的词对应起来,只要输入一个词,所有结果都能出来。传统的系统只能机械地根据文字本身进行检索。系统采用的索引域主要包括:文献编号(ID)、文献标题(title)、作者(author)、摘要(summary)、关键词(keywords)、全文信息(context),其中由于全文信息内容太大,在建立索引域时只进行分词,不将其保存到索引文件中。建立索引过程如图 3 所示。
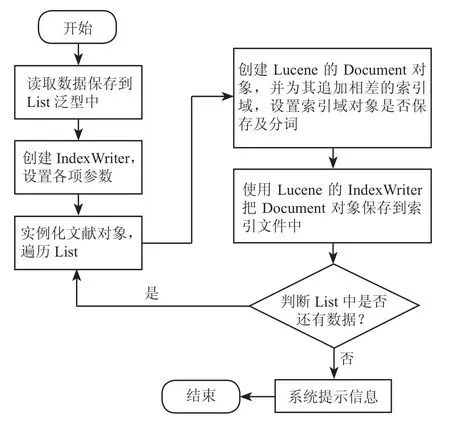
图3 建立索引流程
系统通过数据库中新增加的文献信息进行创建索引操作,从而实现对索引文件的更新,该功能为系统自动进行,采用监听器对数据库进行定时查看。当系统运行后,监听器会定时查询数据库是否有新增加的数据,若有则对其建立索引。系统判断新增加文献的方法主要是在数据库中建立一张新表,用来保存新增文献的 docID,当新增文献的索引全部建立完成后,系统会自动清空该表数据,为下次新增加的数据做准备。
索引模块主要为索引管理,包括建立、更新索引及索引重构,这些操作都是在索引管理页面进行。建立索引时进行分词。建立索引操作一般发生在系统建立之初,系统后期的调试及操作不会再进行该操作。
5 检索过程
检索模块负责搜索用户输入的查询条件,系统根据输入条件进行查找,返回检索结果,生成页面形式供用户查看。检索模块分为关键词和高级检索[11]。
用户在输入关键词检索的查询语句之后,会首先用正则表达式判断查询语句时候包含特殊符号,如果包含则分离出这些特殊符号,之后系统自动对给查询语句进行分词处理,对得到关键词后进行翻译得到中英文关键词,根据关键词检索的参数构造QueryParser 对象进行文献检索,检索完成后,系统对检索的结果进行排序及对关键词进行高亮处理,最后将结果返回给客户端浏览器,如图 4 所示。
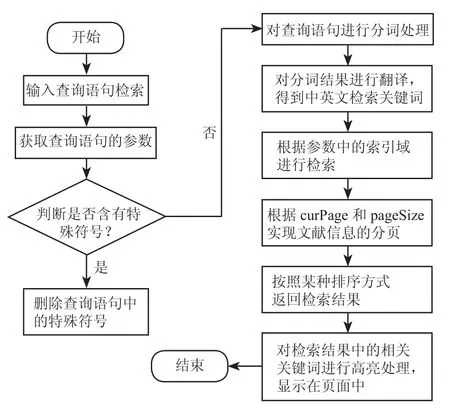
图4 检索过程
用户在输入查询语句进行检索时,系统先对查询语句分词,然后对分词结果进行翻译得到中英文关键词,最后进入索引文件中找到与这些关键词相关的信息,根据排序方式返回给用户。假如用户在输入框中输入“水利工程”,那么系统会对这个词语进行翻译成“Hydraulic Engineering”,然后系统会在索引文件中寻找与这 2 个词语相关文献类别,然后显示的中英文文献信息的检索结果。
根据检索过程和实验原理,得到水利文献检索系统的文献检索结果,如表 2 所示。

表2 水利文献检索结果
从表 2 中的检索实验成果数据来看,水利文献检索系统能够根据输入的中英文专业关键词,在水利领域文献数据库中从基本的分类类别中找到与之相匹配的中英文文献,通过对水利文献的分类和全文检索框架 Lucene[12],一定程度上提高了检索的搜索效率。
6 结语
本研究实现了基于 SSM 和 Lucene 的水利文献检索系统的设计。首先调研了现有的几种检索技术,对其背景进行了详细的介绍,然后从水利领域的广度和深度进行划分,将水利领域划分出 10 个基本类别,根据水利科技文献的需求,组成水利领域词典 waterconservation info.dic,构成水利领域科技文献的专有数据库。系统在 Lucene 框架中引入ICTCLAS 的分词功能,使用 CHMM(层叠马尔科夫模型)进行分词,收集了水利领域的专业术语实现对 ICTCLAS 的词库扩展,将中英文关键词对应起来。将 SSM 项目框架技术,全文检索技术 Lucene和水利领域文献检索结合在一起,详细描述了建立索引及检索的过程,主要贡献如下:
1)在构建水利文献检索系统专有数据库的过程中,从水利领域的广度和深度进行划分,参考文献[7] 对水利文献进行分类,进一步迭代和细化了文献的分类。为构建专有数据库打下基础。
2)实现中英文专业关键词互搜功能,引入 ICTCLAS 的分词功能,并用水利领域词典waterconservation info.dic 对其进行扩展。
3)采用全文检索技术 Lucene 和项目框架 SSM从工程上构建水利文献检索系统,将水利领域文献的时效性和专业性与高性能、可拓展的检索框架Lucene 结合在一起,同时采用 SSM 框架,使得系统更加健壮。
由于时间和技术水平有限,笔者设计与实现的文献检索系统还有一些需要完善和修改的地方,主要有以下 3 个方面:
1)主题爬虫技术。系统中的网络爬取信息是通过录入关键词爬取信息,因此获取的文献信息比较单一。系统对通过解析页面获取文献的标题、作者、摘要等信息,无法获取全文信息,由管理员通过上传文献获取,在扩充文献资源时需要浪费很长时间。因此需要深入研究主题爬虫技术,在获取文献标题等信息的同时获取文献的全文信息,达到文献信息的多元化。
2)进一步研究中文分词。本系统中的水利领域专业术语笔者由于时间关系只收集了几百条术语,后期若想继续研究水利领域的文献检索系统还需要继续扩展词典。同时本系统支持同义词检索,检索范围还很有限,因此这也是日后需要研究和解决的问题。
3)文献查重方面。笔者在文献查重方面只进行文本相似度检测,无其他操作。在检测方面可以考虑先将文献信息进行分词后再进行查重,还可根据文献的特殊性改进查重算法,这也是日后需要考虑的问题之一。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
科学与财富(2019年27期)2019-10-25
电子制作(2019年14期)2019-08-20
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
现代计算机(2016年27期)2016-10-29
专利代理(2016年1期)2016-05-17
软件导刊(2015年6期)2015-06-24
数字技术与应用(2014年12期)2015-05-04
中学生英语·外语教学与研究(2008年4期)2008-03-18
