
基于深度学习支持向量机的上证指数预测
2019-03-05 06:01:46张晶华甘宇健
统计与决策 2019年2期
张晶华,甘宇健
(广西财经学院 信息与统计学院,南宁 530003)
0 引言
股票价格的变化规律一直是国内外学者研究的热门课题。由于股票市场每天的交易量数据大,使得在对其数据进行预处理时,往往会漏掉一些重要的信息。因此如何建立一个股票价格变化预测模型是非常有意义的。
目前国内外学者对股票价格变化规律的研究主要采用BP算法、ANN算法、人工神经网络等算法[1-5],但也存在诸多问题,主要集中在模型参数选取少、实用性不高等问题,满足不了股票大量数据交易的研究。针对上述问题,本文试着利用深度学习具有处理大数据的优点,结合支持向量机预测效果良好的特性,对下一个股票交易价格预测进行深入研究。
1 模型构建
Hinton等提出了深度学习并将其应用于机器学习领域[6-13],其思路是借用多层机器学习模型并通过训练大量数据的方式来寻找数据有用特征,从而提高预测精确度和分类准确度。本文将简单介绍深度学习支持向量机模型构建方法。
对任意N个上证指数数据让其随机生成样本集(xi,ti),其中xi=[xi1,...,xin]T∈Rn;ti=[ti1,...,tim]T∈Rm。假设隐含层节点的总数为,支持向量激活函数为g(x),则深度学习支持向量机模型描述为:

其中,αi为误差调节变量,一般取值为[-1,1];wi=[w,w,...,w]T为第i个隐含层与输入层节点的权重向i1i2in量值;β=[β,β,...,β]T为第i个隐层与输出层节点的ii1i2im权重向量值;bi为第i个隐层节点的激活阈值。本文利用零误差对式(1)进行拟合求解。即对于任意N个数据样本集,深度学习支持向量机模型零误差拟合求解公式为:

其中,γj为调节平衡变量,一般取值为[-1,1]。
其中:
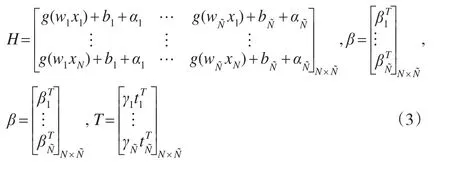
2 参数求解
在利用深度学习支持向量机模型对数据进行特征支持向量训练学习时,首先要对深度学习支持向量机模型的可视层v和隐层节点h进行0或1随机赋值以及偏置值的随机赋予,利用式(3)可求出矩阵H的值;然后假设v和h满足全概率分布p(v,h)的条件且服从Boltz-mann分布。由于深度学习支持向量机模型是双向的,在v值给定的情况下,所有隐层满足独立的条件概率,由此得到v和h的关系式:

同理,在h值已知的情况下,深度学习支持向量机模型中所有可视层也满足独立的条件概率。又已假设所有的v与h之间满足Boltzmann分布,因此当输入v值时,可以利用p(h|v)求解h的值,在得到h的值后,再利用p(h|v)求解新的v1。进而利用权重值的调节方法使所求v1值与原v值一致,若经过反复调节后新旧的值相同或近似,则可把隐层的数据特征当作是可视层输入数据的特征;反之,则重复上述过程,直至找到新旧的值相同或近似时才停止特征深度学习支持向量训练学习。
关于深度学习支持向量机模型中v和h值求解,本文构造如下关系式,即:

其中,ϕ={W,a,b}为深度学习支持向量机模型中的偏置变量。
对式(4)进行指数化与正则化,利用已知假设p(v,h)满足的条件,得到v与h的关系式,即:
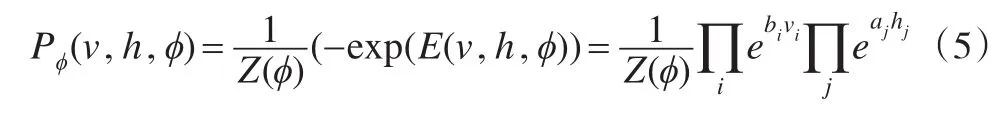
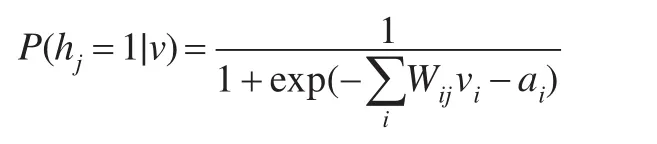
同理,在已知h值的条件下,求解深度学习支持向量模型的第i个可视层节点的式子为:

最后利用所得深度学习支持向量机模型对下一个股票交易日进行数值预测,并把所得预测值与实际值做分析比较。
对于任意给定N个数据样本集 {(xi,ti)|xi∈Rn,ti∈Rm,i=1,2,...,N},支持向量机激活函数为g(x),隐层节点总数为,则深度学习支持向量机训练学习步骤为:
①对深度学习支持向量机模型的输入wi、ai和bi(i=1,2,...,N)进行随机赋值;
②在①的基础上,利用式(3)计算矩阵H;
③根据式(3)所得的矩阵H,并利用式(3)至式(5)求解向量β;
④利用所得深度学习支持向量机模型,对下一个上证指数交易日进行数值预测。
3 实证检验
3.1 数据选取与清洗
本文选取上海证券交易所2010年4月22日至2014年6月10日共1000个历史数据,其包括开盘价、最低价、最高价、收盘价和成交量,在对数据进行训练学习前必须对所得的上证指数数据进行清洗。目前常规的方法有多项式拟合法等,由于本文所采取的数据彼此之间间隔短,差异不大,因此本文实验采用原数据进行预测分析,避免在清洗过程中漏掉一些重要上证指数数据信息。
由于评价标准指标不一样,往往出现不同的量纲和量纲单位,从而影响模型的预测结果。为了消除上述评价指标量纲不同的影响,本文对所得的上证指数数据进行标准化处理,即设所得的原始数据为{yi},并利用(其中ymax=max{yi},ymin=min{yi}),对其进行标准化处理,把所得上证指数数据化为[0,1]之间的数。
3.2 深度学习支持向量机模型构建与参数设置
本次实验平台是使用Matlab软件中的Deep Learning Toolbox工具包,对上述深度学习支持向量机程序与参数进行优化设置,为了比较本文算法的优劣性,从误差精度等方面与支持向量机方法进行比较。本文初始值选300,经过模型训练优化配置后只有5个隐藏的深度学习支持向量机结构,其对应的维数位 80、100、120、150和170;α、γ取值分别0.5和0.3时,误差最小,仿真结果与实际值对比如图1所示。

图1 本文方法与实际值比较
3.3 模型误差分析选取
关于模型误差分析,本文选取相对误差(MAPE)和均方误差(RMS)做误差对比分析,具体如下:

利用这些误差进行对比分析,主要是对比深度学习支持向量机预测上证指数的效果,同时也可以寻找最佳的预测方案。
3.4 模型预测结果与比较分析
根据上述步骤,对所得上证指数数据进行处理后,按照模型设置进行深度学习支持向量机训练学习,并对下一个交易日的上证指数进行预测,最后将本文方法与支持向量机算法进行比较,结果如图1和图2所示。

图2 本文方法与支持向量机算法比较
本文模型误差和支持向量机误差如表1所示。

表1 模型误差和支持向量机误差
实验结果表明,利用深度学习支持向量机模型对下一个上证指数交易日进行数值预测所得的值比利用支持向量机方法预测值误差小。因此,深度学习支持向量机算法与已有的支持向量机算法相比,在预测精确度方面得到明显的改善。
4 结束语
针对上证指数数值预测准确性难的问题,本文提出了深度学习支持向量机算法,该算法利用深度学习支持向量机具有在大数据中提取某种规律且不受噪音影响等特点,构建深度学习支持向量机模型,借用模型对上证指数数据进行特征深度学习支持向量训练学习,然后优化和配置模型参数,最后利用模型进行仿真实验。仿真结果表明:利用深度学习支持向量机模型预测的下一个上证指数交易日数值比支持向量机模型预测值误差小,因而本文模型具有一定的实用性和理论指导价值。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
人民珠江(2019年4期)2019-04-20 02:32:00
智富时代(2017年4期)2017-04-27 18:16:50
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
华东经济管理(2015年9期)2015-12-16 13:31:26
计算机工程(2014年9期)2014-06-06 10:46:47
机械工程与自动化(2014年3期)2014-05-07 12:49:22
上海电机学院学报(2013年3期)2013-03-11 18:07:58
