
针对跨姿态人脸识别的度量学习方法
2019-03-05 01:37王奥迪
现代计算机 2019年3期
王奥迪
(四川大学视觉合成图形图像技术国防重点学科实验室,成都610065)
0 引言
近年来,深度学习技术被广泛地应用在人脸识别中,大大加速了人脸识别的发展。深度学习技术以数据为驱动,因此一些大规模的公开人脸数据库也应运而生,极大地推进了人脸识别技术的研究。除了大规模的数据集,神经网络结构本身包括目标函数的设计也是解决人脸识别问题的主要途径。目前最新的方法中最具代表的网络结构有VGG[1]、GoogLeNet[2]和ResNet[3]等。
尽管目前的人脸识别技术已经取得了显著的发展,甚至在一些公开库上已经超越了人眼识别的准确率。但是在解决跨姿态人脸识别问题上效果仍然不理想。文献[4]中提到,现有的基于深度学习的人脸识别方法,在跨姿态(正脸与侧脸匹配)的识别任务上的准确率,相比于正脸间的识别任务的平均降低了10%左右,而人眼的识别准确率仅仅降低了2%左右。文献[5]提供了ResNet-18 模型在CFP[4]数据集上预测错误的样本对案例。图1 展示的是真实标签同属于一个人但被模型预测为不是一个人的样本对,图2 展示的是真实标签不是一个人但被模型预测为是一个人的样本对。可以看到,尽管ResNet-18 作为一个表征能力很强的模型,在跨姿态条件下的人脸识别任务中仍存在较大的误差。导致这一现象的主要原因之一是目前用来训练人脸模型的数据集中姿态变化较少或者不均衡。

图1 预测错误的负样本对

图2 预测错误的正样本对
本文提出一种基于度量学习的方法Cross-Pose Pair Loss(下文称之为CPP Loss)。该方法能够有效地利用训练集中有限的姿态变化,主要目标是扩大跨姿态条件下的类内距离和类间距离的差距,有效地提升了基准模型在跨姿态条件下的人脸识别准确率。
1 基准模型
1.1 训练数据集
本文用来训练人脸模型的数据集使用VGGFace2[6],VGGFace2 是一个公开的大规模的人脸数据集,包含9131 个类别,331 万张人脸图片,每个人平均有362.2张图片。数据集分为训练集和测试集,其中训练集包含8631 类,测试集包含500 类。该数据集是从谷歌上搜集的,覆盖了姿态、年龄、光照、种族和职业的变化。本文之所以使用该数据集作为训练集,也是因为该数据集包含了一定的姿态变化,尽管整个数据集上的姿态变化并不均衡。主要体现在每个人的姿态变化不同以及整个数据集上接近正脸的图片的数量远远大于姿态比较大的图片的数量。本文所有实验中用到的训练集是VGGFace2 的子集,包含8625 个人,300 多万张图片。
1.2 训练设置

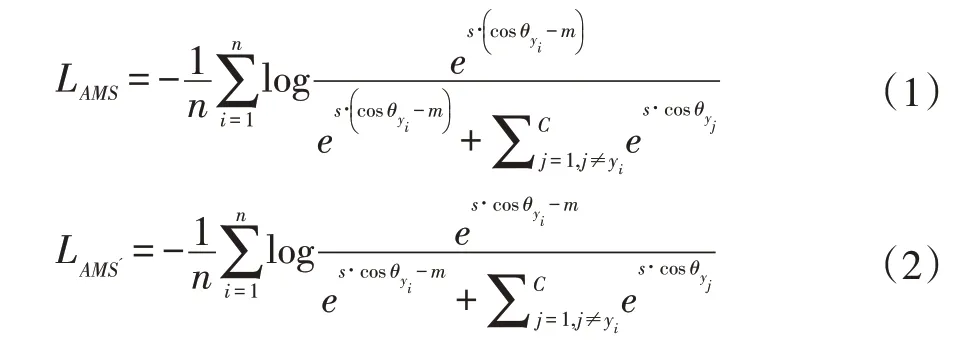
2 CPP Loss
假设{f,nf}是VGGFace2 训练集上的来自同一个人的一组跨姿态的样本对,其中f 为接近正脸的图片,nf 为非正脸图片。定义CPP Loss 如公式(3),其中i,j表示样本的类别,B 表示一次送入网络的一批样本的类别集合,表示两个样本间的相似度(实验中使用余弦距离),表示CPP Loss 正如所有的度量学习的方法,旨在减小样本的类间相似度和扩大样本的类内相似度。换句话说,即扩大样本的类间相似度与类内相似度的差距。而CPP Loss 主要针对的是跨姿态条件下的类内相似度和类间相似度。对于一个类别i 的样本对{fi,nfi},它们之间的相似度即为跨姿态条件下的类内距离,然后分别以fi和nfi作为锚,在样本集合B 中挖掘最大的跨姿态条件下的类间相似度。如公式(3)所示,CPP Loss 的优化目标就是最小化类间相似度和类内相似度间的差值。其中m 为一个间隔参数,旨在保证类间相似度比类内相似度至少差m。
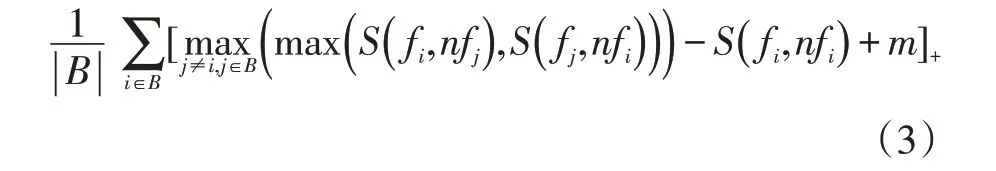
3 实验与分析
本文的实验代码均在PyTorch 下完成,训练集和测试集的所有图片都通过MTCNN[8]检测的5 个特征点位置做简单的平面内的二维对齐,并裁剪为统一的尺寸112×96。训练基准模型时参考文献[7]的设置,其中,间隔参数m 的值固定为5,尺度参数S 的初始值设为30。本文的CPP Loss 方法是基于基准模型继续训练学习。CPP Loss 方法中,网络以跨姿态的样本对作为输入。所以首先需要在训练集VGGFace2 上组织跨姿态样本对。具体做法是,将训练集中每个人的图片按偏航角(yaw)分为接近正脸(小于5°)和非正脸(大于45°)图片。训练时采取线上组织样本对的方式,首先随机采样一组不同的类别集合,然后针对每个类别,分别在其接近正脸和非正脸图片组中个随机采样一张图片组成跨姿态样本对。
表1 和表2 为实验结果对比表,测试集为Multi-PIE[9]的子集,包含249 个人和3029 张图片。测试协议为1:1 身份认证。测试时,将测试集中的正脸图片作为注册库(gallery),而查询库(probe)按偏航角分为三组,分别为小姿态(±15°和±30°)、较大姿态(±45°和±60°)和大姿态(±75°和±90°)。表1 中与基准模型对比的模型是在基准模型上只使用CPP Loss 继续训练学习得出的模型。可以看到,CPP Loss 方法在“正脸-较大姿态”和“正脸-大姿态”两组姿态跨度条件下均对基准模型的准确率有所提升。而间隔参数在一定的数值范围内,与模型的准确率成正比关系,具体分析可以参考文献[7]。表2 中与基准模型对比的模型是在基准模型上使用CPP Loss 结合AM-Softmax 继续训练学习得出的模型。可以看到,CPP Loss 结合AM-Softmax 的方法可以给基准模型在测试集上的准确率带来更大的提升,并且在三组姿态跨度条件下都有所提升。

表1 CPP Loss 不同间隔参数下的实验结果对比

表2 CPP Loss 结合AM-Softmax 不同间隔参数下的实验结果对比
综合上述的实验结果对比分析可以得出,本文提出的CPP Loss 方法,通过在跨姿态样本对上的度量学习,可以进一步提升基准模型在跨姿态条件下的人脸识别准确率。虽然训练数据集上的姿态变化不大并且存在不均衡现象,但是组织跨姿态样本对的方式可以更加有效地利用训练集中的姿态变化。值得一提的是,如果使用CPP Loss 结合AM-Softmax 的方法,可以给基准模型的准确率带来更大的提升,同时保证不损失其在小姿态跨度条件下的准确率。可以解释为CPP Loss 扩大跨姿态样本间的类内距离和类间距离的差距的同时,加上AM-Softmax 的约束可以保证模型在训练样本上的判别能力。并且相比于基准模型,在该阶段的训练过程中,AM-Softmax 会更加地专注于较大姿态的样本的学习。因为基准模型的训练集中较大姿态的样本占整体的样本数量的比例较小。
4 结语
针对跨姿态人脸识别问题,本文提出的CPP Loss,通过组织跨姿态样本对的方式,有效地利用数据集中的姿态变化,使用度量学习的方法提升了基准模型在跨姿态条件下的人脸识别准确率。为解决跨姿态人脸识别问题提供了一个可行性方法。
猜你喜欢
模式识别与人工智能(2022年9期)2022-10-17
作文中学版(2022年1期)2022-04-14
计算机研究与发展(2022年1期)2022-01-19
北京航空航天大学学报(2021年9期)2021-11-02
文萃报·周五版(2021年17期)2021-05-31
好日子(下旬)(2020年6期)2020-08-04
科技传播(2019年24期)2019-06-15
电子制作(2019年9期)2019-05-30
劳动保护(2018年8期)2018-09-12
文苑(2015年9期)2015-09-10
