
基于深度学习的HS Code 产品归类方法研究
2019-03-04 08:30许重建李险峰
现代计算机 2019年1期
许重建,李险峰
(北京大学深圳研究生院,深圳518000)
0 引言
随着经济的快速发展,我国已成为世界第一大出口国,外贸经济已成为我国经济的重要组成部分,出口贸易过程中关务业务非常专业而且复杂,其中HS Code(The Harmonization System Code,商品名称及编码协调制度)[1]是由国际海关理事会制定一种国际通用的进出口商品归类体系,是对各种不同产品出入境应征/应退关税税率进行量化管理的制度。HS Code 编码体系共有22 大类98 章,国际通用的HS 编码由2 位码、4 位码及6 位码组成,其中2 位码对应“章(Chapter)”,4 位码对应“目(Heading)”,6 位码对应“子目(Subheading)”,6 位码以上的编码及对应商品由各国自己定义。目前中国使用的是10 位HS Code 编码体系,大概有11302 个10 位的HS Code,每一个HS Code 有对应相关的商品描述,报考成分含量、用途、制备,等等,HS Code 编码体系中多处使用了兜底设计,例如将每一个“子目”的最后一行定义为“其他”(编码常用数字9 来表示),包含了所有在本“子目”中难以分类的商品,以保证HS Code 编码体系的完整性和涵盖面。正是这种“兜底式”的设计体系,导致了用算法来解决HS Code产品归类的复杂度和技术难度陡然增加。图1 是海关“第2 类-植物产品,第10 章-谷物”的部分商品HS Code 编码示例。
由于贸易过程中涉及的关务、税务、外汇、物流等业务专业性很强,所以出现了很多外贸综合服务平台专门为外贸公司提供这类专业复杂的出口贸易业务服务,让出口企业专注于自己的主营业务。HS Code 编码的复杂性导致其归类、查询和确认需要很多的人力工作量和专业的业务知识,并且很容易出错,成为当前影响国际贸易货物通关效率的重要因素之一。作为一个外贸综合服务平台,HS Code 产品归类是国际贸易的基础设施,如何进行无国别的商品归类显得非常重要,如何提高HS Code 产品归类的准确率和泛化能力成为了亟需解决的问题。
HS Code 产品归类本质上属于文本分类问题,文本分类问题是自然语言处理领域中一个非常经典的问题,比较著名的自动文本分类方法主要有Bayes[2]、KNN[3]、LLSF[4]、NNet[5]、Boosting[6]、SVM[7]、最大熵模型等,卡内基梅隆大学的Yang[2-8]使用英文标准分类语料,对常用的多种分类方法进行比较客观的比较后得出的结论是KNN 和SVM 较其他方法有更高的分类准确性和稳定性。但是,KNN 方法会随着文档数的增加效率迅速下降;SVM 方法本质上是一种两类分类器,对多类分类支持不好,而且分类器训练时间比较长。文献[9]的实验表明最大熵模型方法优于Bayes 方法,与KNN 方法和SVM 方法效率不相上下,但其稳定性较KNN弱。近几年深度学习无论在图片[10]还是NLP(Natural Language Processing)[11]领域都有质的突破,因此我们尝试使用深度学习的方法来进行HS Code 产品自动归类。首先我们对HS Code 领域数据特征进行分析,然后设计并建立相关的数据处理模型,接着在某外综服务平台上进行验证,实验结果证明这种方法效率很高并且稳定。为了对基于深度学习的HS Code 产品自动归类技术和其他文本分类方法进行比较,我们同时使用最大熵模型进行HS Code 产品自动归类预测,并比较了两种方法的测试数据,实验结果表明基于深度学习的分类方法要优于最大熵模型分类方法。
1 算分析与设计
本节我们首先将分析HS Code 编码使用的业务场景和领域数据特点,接着分析数据处理,然后针对这些业务场景和特点进行算法设计,算法设计包括总体框架设计和详细设计。
1.1 HS Code 业务场景和数据特点分析
在外综服关务板块中,商品HS Code 归类是外贸业务中最基础、技术性最强的工作。外综服平台基于海关标准对商品进行HS Code 归类及知识产权审核,HS Code 直接关系到报关、商检、退税、反倾销等多方面的要求,归类的准确性直接影响到通关顺利与否。正是HS Code 归类在通关过程中具有确定汇率、确定监管条件等关键作用,导致了HS Code 需要严格的准确率,这也是和其他业务场景产品归类最大不同的地方。同时,HS Code 的领域数据有自己非常独特的地方,HS Code 的文本标签数据是由品名和申报要素无序拼装在一起的,这和其他有特定上下文时序信息的文本数据在选择算法上将会有非常大的不同。HS Code的文本标签示例数据如图2 所示。

图2 HS Code文本标签数据示例
通过分析,我们归纳HS Code 领域数据主要有以下四个特点:
(1)HS Code 的领域数据是由品名和申报要素无序拼装起来的,文本没有上下文时序信息。
(2)HS Code 的领域数据即使产品名称相同,但如果材料、成分或用途不同,那么其归属的HS Code 也会不一样。
(3)HS Code 的领域数据大量涉及其他,除非等语义推理归类,如9405990000:税则上解释是品目9405所列物品其他材料制零件;9401790000:税则上解释是其他金属框架的坐具。这类badcase 的优化涉及到知识推理,本体逻辑推理,等等。
(4)HS Code 的领域数据同时有非常多的涉及到范围推理或者成分推理,如8536901100:税则上解释是工作电压不超过36 伏的接插件。
1.2 算法设计
(1)总体设计
通过对HS Code 领域数据特点分析,我们设计了基于文本深度学习的HS Code 产品归类模型,模型总体框架和详细的数据处理流程分别如上图3 和图4 所示,用户输入品名和一段产品描述,HS Code 产品归类模型将会计算预测出文本对应的top-5 HS Code。HS Code 产品归类模型主要包括层级分类器模型和词向量模型两部分,其中层级分类器模型又分第一层章节分类模型和第二层10 位HS Code 分类模型,用户输入首先通过第一层章节分类模型处理后再输出给第二层10位HS Code 分类模型处理,然后再输出粗排HS Code候选集合;词向量模型的输入则来自某外综服平台的标签数据和税则标签数据,以及一些外部数据,训练之后再进行K-means 聚类分析,然后再结合层级分类器模型输出的粗排HS Code 候选集进行细排语义匹配和语义推理,最后才输出HS Code 预测结果。
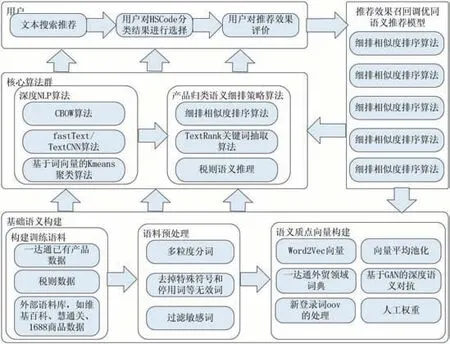
图3 HS Code产品归类文本深度NLP总体算法框架
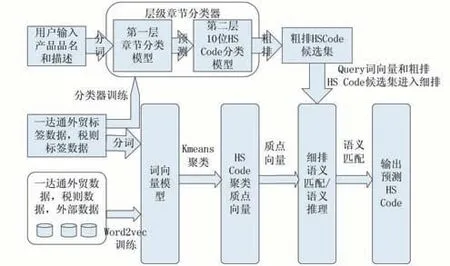
图4 算法数据处理流程图
(2)训练语料构建
语料对算法的重要性,就像汽油对汽车的重要性是一样的,是算法的引擎动力。HS Code 的语料既有来自监督(已打标签的)的某外综服平台历史通关数据、税则数据,又有来自无监督的维基百科中文数据、1688平台商品品名、类目属性数据。无监督数据主要用来训练词向量,提高词向量模型的泛化能力。
(3)分词
在文本NLP 中,词是最小的能够独立活动的有意义的语言成分,因此分词是开展文本NLP 的最基础一环,在HS Code 文本NLP 中使用的是jieba 分词[12]。jieba 分词算法使用了基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图(Directed Acyclic Graph,DAG),再采用动态规划查找最大概率路径,找出基于词频的最大切分组合,对于未登录词,采用了基于汉字成词能力的HMM模型[13-14],使用了Viterbi 算法[15]。在使用jieba 分词时,定制了该外综服平台的专用品名词典和基于jieba 上定制该外综服平台外贸特有的分词库,这样在分词时,可以有效地突出该外综服平台专用品名的切词效果。同时,jieba 分词算法会加载定制的品名字典、停用词字典、申报要素字典、正则表达式字典,等等。定制后的jieba 分词运行效果如表1 所示,其中无线燃气探测器由于是外贸专业领域品名,会保留专业品名不被分词,从而保证专业品名的语义完整性。

表1 jieba 分词效果
(4)词向量
词向量是一种把词处理成向量的技术[16],并且保证向量间的相对相似度和语义相似度是相关的。这个技术是在无监督学习[17]方面最成功的应用之一。传统上,自然语言处理(NLP)系统把词编码成字符串,这种方式是随意确定的,且对于获取词之间可能存在的关系并没有提供有用的信息。Word2Vec[18]词向量本质是一种神经概率语言模型,词的表示是向量形式、面向语义的。两个语义相似的词对应的向量也是相似的,具体反映在夹角cosine 或距离上。甚至一些语义相似的二元词组中的词语对应的向量做线性减法之后得到的向量依然是相似的。词的向量表示可以显著提高传统自然语言处理任务的性能。Word2Vec 主要提供了CBOW[19]和Skip-Gram[20]两种模型。在HS Code 文本NLP 场景中,词向量训练采用的是CBOW 模型如图5所示。
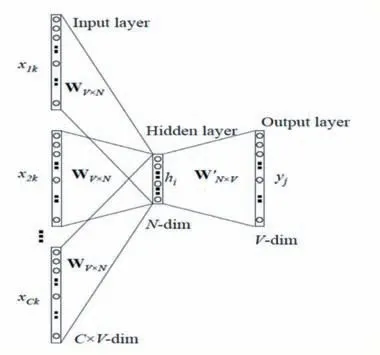
图5 CBOW模型
CBOW 模型采取的策略是根据上下文的词语预测当前词语的出现概率的模型。在CBOW 模型的训练中,采用了负采样(Negative Sampling)[21]的训练方式,负采样的思想是每次训练只随机取一小部分的负例使它们的概率最小,以及对应的正例概率最大。对负例进行抽样需要先定义一个噪音分布(Noise Distribution),然后再依据概率分布进行带权随机抽样。在Word2Vec 的CBOW 模型中,我们使用的噪音分布是基于词的频次的权重分布,计算公式如下:
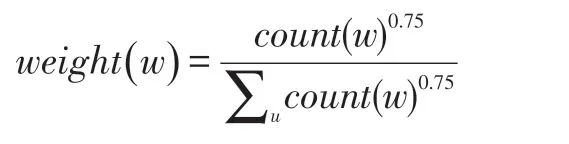
相比于直接使用频次作为权重,取0.75 幂的好处可以减弱不同频次差异过大带来的影响,使得小频次的单词被采样的概率变大。有了噪音分布以后,基于CBOW 模型的负采样训练的损失函数如下:
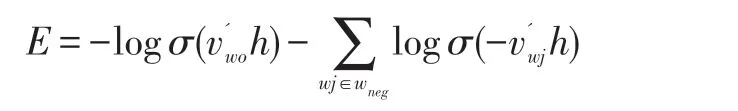
负采样(Negative Sampling)是一种概率采样的方法,属于NCE(Noise Contrastive Estimation)[22]的一种简单形式,训练得到的词向量质量也很高,词向量语义表达能力更强一些,因此相对常用一些。
(5)层级分类器
由于整个HS Code 编码体系自身是按照2 位码-章节,4 位码-目,6 位码-子目,最后10 位HS Code 层次结构进行管理的,而且10 位的HS Code 总共大概有11302 个类别,且每个HS Code 类别的数据分布是极其不均衡的。因此直接用文本分类算法对11302 个10位HS Code 进行一步到位的预测是非常不准确的,故而采取层级分类器方案先进行粗排。第一层分类器将一段文本正确的分类到HS Code 的前2 位(HS Code 每个章节),预测top 5 个章节,第二层分类器是按照每个章节来预测top 200 个10 位HS Code。整个层级分类器的分案采用的是fastText[23]分类算法进行预测,同时也探索使用了TextCNN[24-25]分类器算法,最后发现TextCNN 的分类器算法比fastText 在HS Code 归类上效果要差很多。笔者详细分析了为什么TextCNN 比fast-Text 在外贸HS Code 领域效果会这么差,最后得出的结论是领域数据导致的。TextCNN 的主要优势在于捕捉一段真实文本中的上下文时序语义信息,就像图片CNN用来捕捉局部感受视野是一样的,而HS Code 领域数据只是有品名和申报要素无序拼装的,完全没有上下文时序语义信息,所以TextCNN 方法得出的效果差。
fastText 的核心思想是将整篇文档的词及NGram[26]向量叠加平均得到文档向量,然后使用文档向量做Softmax 多分类。fastText 的模型架构图6 所示,由fastText 模型架构可以看出,从hidden layer 输出到output layer,fastText 就是一个层级的Softmax 线性多类别分类器,分类器的输入是一个用来表征当前文档的向量;模型的前半部分,即从输入层输入到隐含层输出部分,主要是叠加构成这篇文档的所有词及N-Gram的词向量,然后取平均来生成用来表征文档的向量。在fastText 训练时,使用的损失函数如下:
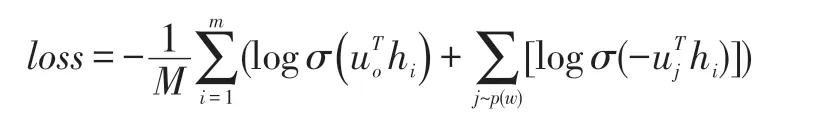
在我们使用的56238 条测试数据集上,fastText 第一层章节分类器预测top 5 个章节的准确率达到了0.962908。
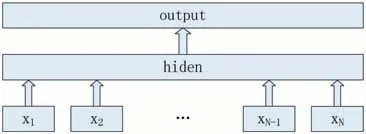
图6 fastText模型架构
fastText 第二层分类器预测每个章节的10 位HS Code,如在85,84,94,61,39 进行第二层分类器预测到top 200 的10 位HS Code 预测上,因为这几个重点章节,例如85 章节下面就有1300 多个不同的10 位HS Code,只有先通过第二层分类器预测给出top 200 的10位HS Code,后续精排算法策略才能实现,top 200 准确率如表2 所示。
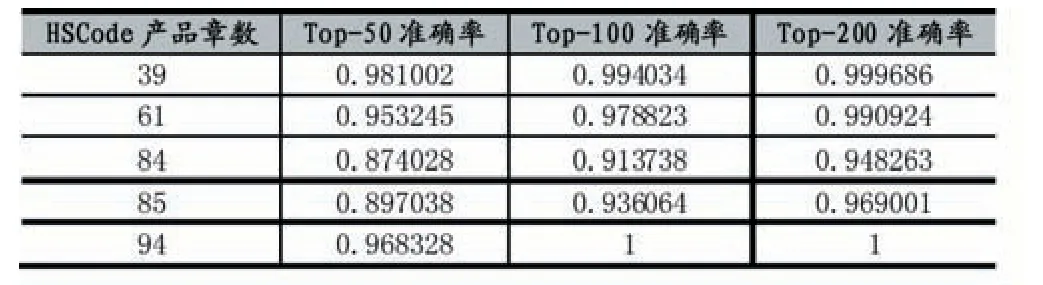
表2 第二层分类器预测实验结果
(6)K-means 聚类质点向量
通过两层层次分类器初步选出200 个10 位HS Code,进入到精排算法阶段时,由于我们数据严重倾斜,(如3926909090 对应的历史数据有54879 条,8534009000 对应的历史数据有39458,8507600090 对应的历史数据有39177,4202920000 对应的历史数据有36745,9403609990 对应的数据有29441,等等),这时候精排算法阶段用人工权重的方式会有些难以实现,因为有一些数据倾斜的问题,对一些历史数据样本大 的 10 位 HS Code(如 上 述 的 3926909090,8534009000 等),先用K-means[27]聚类算法求出50 个聚类质点,让这50 个聚类质点的向量来表达一个10位HS Code。通过这种方式加强HS Code 的向量表达能力和抗干扰能力。K-means 聚类质点向量的核心问题是在于聚类算法在何时收敛,我们使用了如下的代价函数作为聚类算法收敛的判断依据:
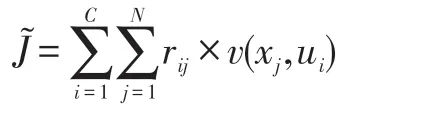
其中:
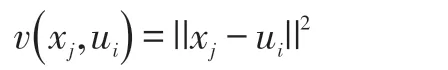
rij:表示如果第j 个数据点属于第i 类,那就记作1,否则记作0 的一个N×C 大小的矩阵。代价函数的差分值小于一定数值的时候(N 次越不过最小值点)即可认为收敛了。
(7)文本词向量平均池化
有了词向量模型,文本NLP 中最小语义单位——词,就可以用分布式向量来表达了。由于HS Code 的领域文本由品名和申报要素无序拼装起来的,文本没有上下文时序信息,因此这种文本组织方式适合用词向量平均池化来表达整个文本的语义向量,就是将一段文本中的每个词向量进行相加并求均值,这种方式综合考虑了一段文本中每个词的贡献能力。除了用词向量平均池化,在文本向量表示中我们也尝试了词向量最大池化,词向量最大池化就是去一段文本中每个词向量每个维度最大的值,这种方法相当于考虑一段文本中最显著特征信息,忽略掉其他无关或者不重要的信息。经过测试对比,在HS Code 领域文本,词向量平均池化的整体效果比最大池化的效果要好很多。
(8)语义匹配相似度计算
一段文本查询经过两层层级分类器粗排选出候选HS Code 集合,然后就会进入HS Code 文本归类的细排算法阶段,细排阶段的主要核心环节就是文本语义匹配相似度的计算。文本语义匹配的主要难点:
①自然语言处理中基本处理单位是词,而词只是个符号表示,存在语义鸿沟的现象,需要将符号表示由模型转成向量表示,这里就会有很多的误差。
②词语匹配的多元性,不同的词语可能表示的是同一个语义,例如同义词,如“荷花”、“莲花”、“水芙蓉”、“芙蕖”,它们表示的都是同一种植物;同理一个相同的词在不同的语境下会有不同的语义,例如“苹果”既可以是一种水果,也可以是一家公司,亦可以是一个品牌。
③短语匹配的结构性,多个词语可以按照一定的结构组合成短语,匹配两个短语需要考虑短语的结构信息。例如“机器学习”和“学习机器”两者的词语是一样的,而词的顺序不同,导致文本语义完全不同。
目前HS Code 文本归类中的语义匹配相似度是基于K-means 聚类质点向量的cosine 进行计算的。未来可以考虑采用带监督的DSSM 语义匹配模型或者WMD(词移距离)来进行语义相似度的匹配计算。基于聚类质点向量的cosine 相似度算法伪代码:
输入:两个词向量v1 和v2
输出:cosine 相似度cosine_sime
def cosine_similarity_self(v1,v2):
dot_product=np.dot(v1,v2)
cosine_sim=dot_product/(norm(v1)*norm(v2))
return cosine_sim
(9)深度语义对抗
由于该外综服自身出口数据有限,并且出口的产品数据极度不平衡,有部分HS Code 对应的产品在该外综服出口数据非常少甚至还有一些从来没有出口过,这样数据的瓶颈将会越来越凸显,如何解决数据样本瓶颈的问题是一个重要的困难。由于产品是互通性的,那么如何将淘宝天猫、1688 海量商品数据隐射到外贸出口产品数据是一项非常有价值的工作。表3 是天猫商品数据和该外综服平台外贸出口数据的一些属性对比和差异性。
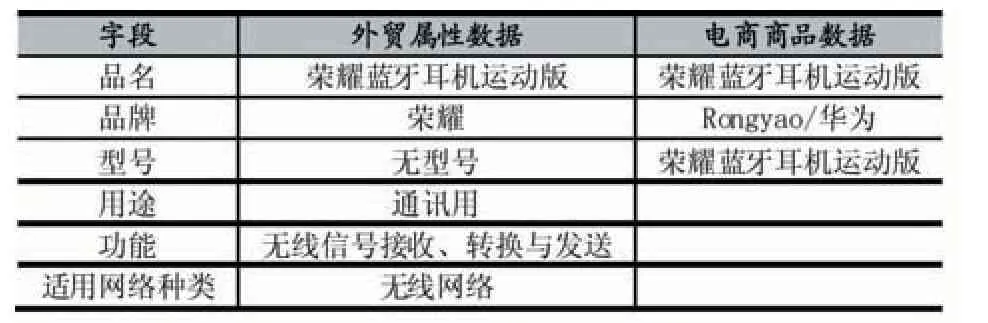
表3 外贸属性数据和电商商品数据对比示例
从语义上来看,天猫的商品语义和该外综服平台带有归类要素的外贸语义差异确实比较大。而用GAN(Generative Adversarial Networks)[28]来把天猫商品品名作为噪音来对抗生成语义向量隐射到该外综服平台的语义,难度确实不小,这主要是GAN 的内在原理确定的,GAN 只适用于连续型数据的生成,图片是典型的连续性数据,对于离散型数据效果不佳,文本数据就是最典型的一种离散型数据。这里的离散和连续主要是指数据是否持续可微分。图像矩阵中的元素是可微分的,其数值直接反映出图像本身的明暗、色彩等因素,很多这样的像素点组合在一起,就形成了图像,也就是说,从图像像素矩阵到图像,不需要采样生成。而文本本身都是一个个词向量构成,而词向量是经过采样训练出来的独立向量,天然都是离散、独立的。而GAN本身是一种对抗神经网络,而神经网络的优化方法大多数都是基于梯度的,而对于独立训练出来的文本离散向量对应的生成器G(Generator)的损失函数loss 会是一个近似于常数log2 的JS 散度,而固定常数log2 的导数是0,这样这个生成器不能进行基于梯度进行反向传播(Back Propagation,BP)[29]进行优化。这里需要想其他的办法来避免这个问题,目前的我们采用的方法是基于最新的Wasserstein GAN[30]进行处理,把天猫平台的商品文本数据做为噪音并采用GAN 进行处理来和该外综服的打标数据做语义对抗,将天猫平台的商品数据文本隐射到该外综服的语义向量。同时GAN这种处理方式要注意天猫出海业务数据经过生成器后出来的向量语义是不是有很大的变化,有些情况可能会迷惑判别器,但它的分类类别和它应该归属的类别比已经偏了,这个是两者数据分布差异引起的,所以需要用迁移成分分析(Transfer Component Analysis,TCA)来调整数据的边缘分布条件分布和联合分布。
(10)税则语义推理
我们基于HS Code 文本归类模型,统计了模型预测失败的案例(这些案例都是不在top 3 预测之内,但是都是在top 20 预测之内),分析了这些案例失败的原因主要如下:
①涉及其他,除非等类别,如9405990000:税则上解释是品目9405 所列物品其他材料制零件。9401790000:税则上解释是其他金属框架的坐具。这类失败案例的优化涉及到知识推理,本体逻辑推理等等,难度非常大,知识推理需要较长时间研究,我们会在后续研究中进一步完善。
②涉及到范围推理或者成分推理,如8536901100:税则上解释是工作电压不超过36 伏的接插件。
③品名跨多个类,但是根据成分、制备、用途来确定具体的HS Code。
其中,涉及其他,除非等类别的失败案例比例高达72%以上,这里就涉及到了税则语义推理的研究了。目前税则语义推理的整体算法方案正在全力调研中,是下一步的研究工作。
2 实验
2.1 测试数据和结果
我们对前面的设计进行了实现,并在某外综服平台上进行测试验证,测试数据分布如图7 所示,所有产品的HS Code 数据都能在www.hsbianma.com 网站上查询到,我们选择7、8、11、16、20 等5 个产品大类的数据进行测试,这些测试数据基本涵盖了本文分析的HS Code 数据的所有特性,测试结果如表4 所示,我们同时使用最大熵模型对HS Code 产品进行分类来测试预测Top5 的准确率,实验数据表明基于深度学习预测的HS Code 平均Top5 准确率达到0.904422,而基于最大熵模型方法的平均预测准确率只有0.825588,基于深度学习的分类预测方法准确率明显高于基于最大熵模型的分类方法,我们同时给出了基于深度学习方法对HS Code 产品分类预测的Top1 准确率、Top3 准确率和Top10 准确率供参考,其中Top1 预测平均准确率达到了0.766517,已经超越了商用的预期值0.75。
图7 测试数据分布图
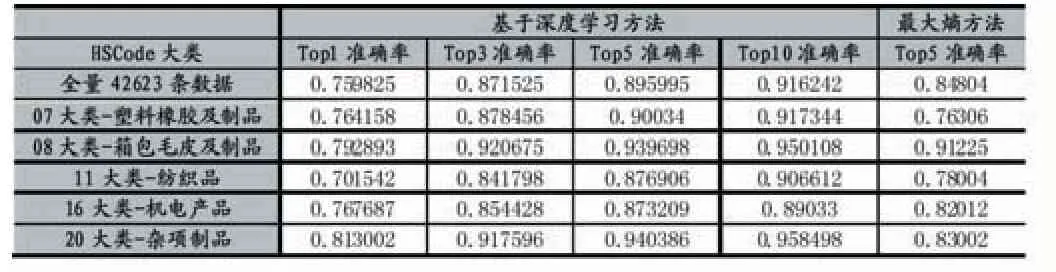
表4 实验结果数据
2.2 实验效果展示
(1)用户输入产品品名
图8 产品品名输入截图
(2)用户点选类目
图9 点选类目截图
(3)用户输入详细产品描述

图10 输入产品描述
(4)HS Code 自动归类结果
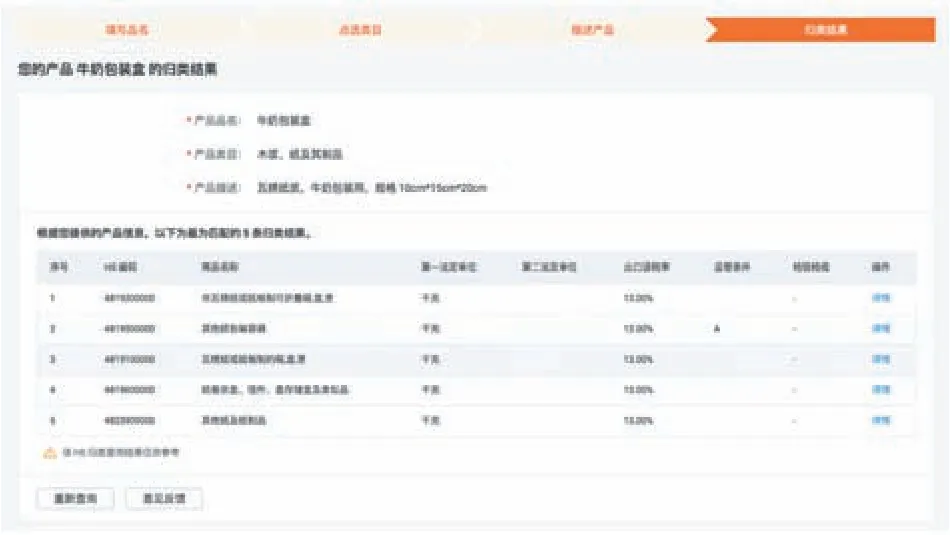
图11 HS Code自动归类结果展示
3 结语
本文中,我们研究了基于深度学习的HS Code 产品分类方法,首先对HS Code 的数据特征进行分析,接着对整体算法进行总体设计,然后对算法框架中的每个环节进行详细的设计和分析,最后依赖某外综服平台实现了该分类方法并进行了实验验证和分析,实验结果表明基于深度学习的HS Code 产品分类方法准确率很高,优于基于最大熵模型的分类方法。同时在方法研究实践过程中,我们也发现该方法目前的一些不足,例如数据不平衡需要引入语义对抗网络,这些问题有待我们下一步进行研究,并且进行更多的验证。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
中学生数理化(高中版.高考数学)(2021年10期)2021-12-02
计算机系统应用(2021年2期)2021-02-23
疯狂英语·新读写(2018年2期)2018-11-29
软件导刊(2017年4期)2017-06-20
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
