
基于稀疏编码的异常检测
2019-03-04 08:30:52袁玲
现代计算机 2019年1期
袁玲
(四川大学计算机学院,成都610065)
0 引言
近年来,随着人口的持续增长及城市化进程的不断加快,人群活动变得日益频繁,在交通路口、机场、火车站、旅游景区等人群密集的公共场所发生重大异常事件的现象屡见不鲜。因此,在智能视频监控中对大规模人群的异常检测则显得尤为重要。异常检测早期研究方案集中在建立目标轨迹模型,这种方法大体思想是一个目标的轨迹如果偏离正常模型训练出来的轨迹,则该目标被标记为异常。然而,这些基于追踪的方法有其缺点:①对于遮挡场景下,是不稳定的;②在拥挤场景中,这些方法的计算复杂。
为了解决这些困难,有学者提出了一些基于时空低级视觉特征的方法,例如光流和梯度特征,然后使用这些特征训练出相应的模型,在这些模型下,出现的可能性小于一定阈值的则为异常[1]。使用人群正常的视频训练出隐马尔科夫模型(HMM),可以解决由于异常训练数据的稀缺性以及难于预先定义异常事件带来的问题。
考虑到人群本身的行为,社会力模型被Mehran 等人[2]引进,首先,该模型提出人的实际行为是受自身的期望以及周围人的排斥力影响的理论,然后使用排斥力训练出LDA 模型,最后,实验证明该模型在人群异常检测中是一个有效的运动模型。以上模型强调了时间上运动的变化,但是忽略了人群的外观变化,因此Mahadevan 等人使用了混合动态纹理模型(MDT)[3-4]来检测异常,该模型把异常分为时间上的异常和空间上的异常,时间上的异常被认为是出现可能性低的行为,而空间上的异常是视频中与周围场景相比,具有显著性特征的行为。
最近,基于稀疏编码的研究受到了很多关注,其中,基于稀疏编码的异常事件检测也取得不错的效果。文献[5-6]提出了动态稀疏表示的方法;Yang Cong等人[7]在此基础上制定了基于稀疏编码检异常检测的标准,该标准称为稀疏重构代价(SRC)。但是在实际应用中,训练样本的有限性会导致在新场景的视频中,异常检测结果出现偏差,因此,在线学习和更新稀疏编码字典的方法[8-9]被提出。尽管以上大多数基于稀疏编码的方法在检测效果上表现良好,但是实时性有待提高。
本文在原有稀疏编码的思想上,提出一种新的有效的稀疏表示方法,该方法在检测速度上,具有不错的效率,同时检测率也能得到保证。
1 稀疏编码
1.1 定义
对于训练模型,一个高维的特征显然能更好地描述事件,但是随着特征的维数增加,需要的训练数据呈现指数增长,在现实生活中,收集的训练数据是很难满足要求的。例如,在全局的异常检测中,要训练出一个较好的高斯模型,但是只有400 个训练样本的情况下,这是比较困难的。但是稀疏表示却适合代表具有高维特征的样本。稀疏编码,是通过正常样本训练出一个字典,该字典的线性组合可以训练样本。这个字典用D∈Rp×q来表示。对于一个测试样本X,我们可以通过以下公式来表示:
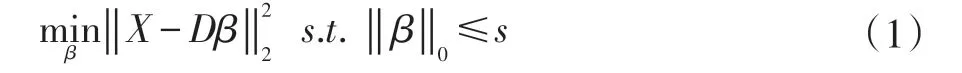
其中β∈Rp×1是稀疏系数,而是数据拟合项,‖ β‖0是稀疏重构项,而s 是(<<q)是稀疏数量控制参数。给定训练样本[x1,...,xn],我们可以通过公式(1)去训练字典D。
1.2 异常检测
使用公式(1)训练出的字典D,引用文献[7]中定义的稀疏重构代价来检测异常。通常情况下,对于正常的事件应该是以很小的代价且以很少的基础向量(字典中的列向量)构建,也就是β为0 的个数比较少,而异常事件要么不能以很小的代价构建出,要么即使能以很小的代价构建出,也需要大量的基础向量。前人的研究验证了这个方法可以达到较高的检测率。
1.3 传统稀疏编码的效率问题
显然,在公式(1)中的字典具有高度冗余,因此在异常检测阶段中存在效率问题,因为在这个阶段中,需要在q 个基础向量中找到不大于s 个基础向量,而s 是远远小于q 的(q 足够大是为了能够表示更多的训练样本),那么这个过程是比较耗时的,因此研究怎样减小q是很必要的,本文就是针对这个问题进行优化。
2 本文算法
针对1.3 小节提出的问题,本文提出了一种新的字典学习方法。对于字典D,我们用n 个子字典构成,其中每一个字典由一些基础向量构成,并且使该子字典尽可能多的表示训练样本,在测试阶段,只需要在这些子字典中找到一个合适的子字典来表示样本。通过这样的优化,q 的数量大大减少,而针对找到的子字典,只需要通过最小平方误差找到合适的向量组合就能表示样本。本文框架如图1 所示。接下来,将详细介绍本文的方法。
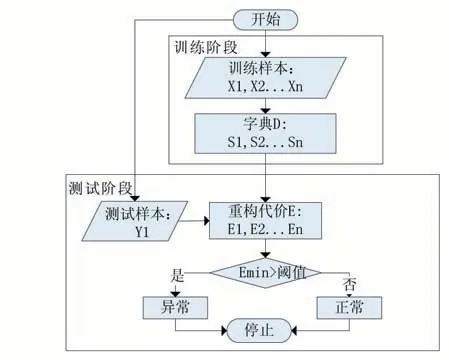
图1 本文框架流程图
2.1 字典的学习
对于字典的学习,我们首先得提取训练样本的特征数据,用以表示该样本。本文主要提取视频中的3D梯度特征,如文献[10]中定义的那样,该特征能较好地表示局部特征,因此使用该特征不但能检测出某一帧出现异常,且能更好的定位该异常。同时,我们将每一帧视频划分成10×10 图像块,然后在时间序列上每5帧组成一个10×10×5 的立方体,每一个立方体表示一个事件。
对于每一个立方体,我们提取其3D 梯度特征,然后组成训练样本数据X={x1,...,xn}∈Rp×n,我们的目标是找到一个基础字典组合S={S1,...,SK},其中每一个Si∈Rp×s。这个学习过程可以由公式(2)给出:
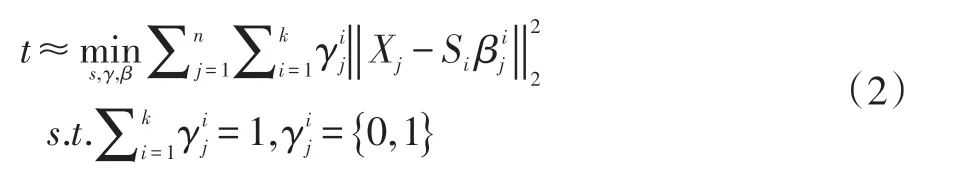
其中γ={γ1,...,γn},对于每一个γj∈K,用来指示Si集合是不是能被选择用来表示X 的第j 个数据。而用来表明是对于子字典Si构成Xj的系数。由上面的公式可以看出,Xj至少在S 中能有一个基础子字典能以很小的代价e 组成。很显然,选择合适的K 是很重要的,太小则不足够表示所有的训练样本,而太大则可能导致所有样本的重构代价几乎趋近于0,即使是异常样本。因此,对于K,不是固定,而是采取自适应学习的方法,也即是迭代,对于e 设置一个下限λ,当训练样本的所有的重构代价都达到了这个下限,此时的迭代次数K 就是最合适的。因此公式(2)可以变成为:
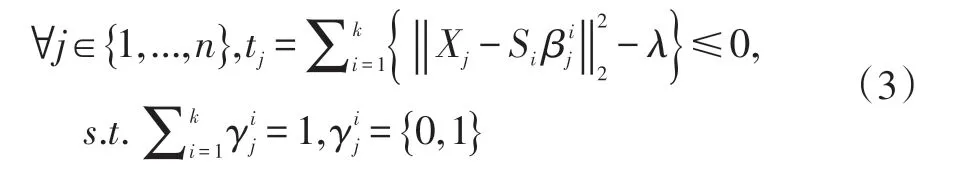
更新{Si,β,γ},对于公式(3),学习过程中要学习的参数有Si,β,γ。本文把这个学习过程分成两步,首先保持γ不变,更新{Si,β},然后利用已经学习好的{Si,β},更新γ。
第一步,给定该γ,此时可以把公式(3)变为:
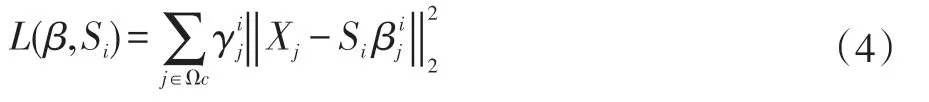
其中j∈Ωc,表示剩下的不能由S 表示的X 集合。上面这个公式可以看成求函数的最小值。对于公式(4)也将分成两步,一是保持Si不变,其中γj不等于0,求取

更新Si,这里采用块梯度下降方法,每一次用公式(6)更新Si,直到收敛。

更新γ,使用公式(5)、(6)得到的{Si,β},对于每一Xj,公式(3)可以转化为公式(7):
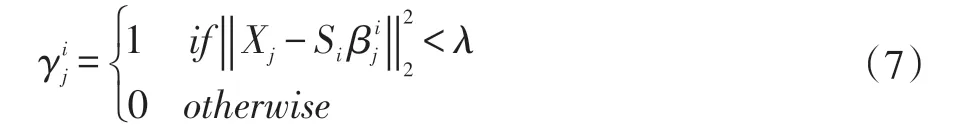
使用上文描述的字典学习过程,就可以得到一个合适的字典D,该字典能很好地描述训练样本,算法过程如下所示:
算法1:训练字典
输入:X,Xc=X
重复
重复
利用公式(5),(6)更新{Si,β}
利用(7)更新γ
直到(4)收敛
把Si加入到集合S
去除已经满足条件(γj=0)的Xj
i=i+1;
2.2 测试
对于已经学习好的字典组合S={S1,...,SK},就可以在测试阶段寻找是否存在一个Si,满足重构代价小于阈值,可以使用(8)式得到合适的Si。
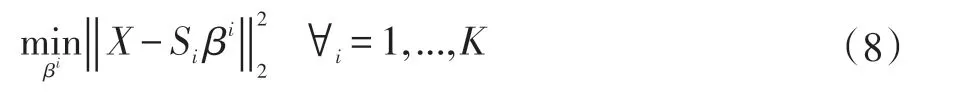
显然这是一个二次函数,可以优化成公式(9):

然后,重构代价就可表示为:

测试算法流程如下:
算法2:测试
输入:X,{R1,...,RK},阈值T
for j=1 →K
输出正常
else
输出异常
end
3 实验
本文实验环境为MATLAB 2015,Windows 10,在UCSD 数据集上进行实验。对于给定的视频将大小重新定义成为120×160,并把视频分成10×10×5 的立方体。
3.1 UCSD数据集
USCD 数据集主要有分为两个子集(UCSDped1,UCSDped2),每一个子集里面都有训练数据和测试数据,而且测试数据里面含有像素级别的异常标记掩模。其中UCSDped1 训练数据含有34 个视频,每一个视频有200 帧,测试数据有36 个视频,10 个带有异常标记的视频,而UCSDped2 训练数据有10 个视频,测试数据16 个,每一个测试数据都含带有标记的掩模,且视频帧数为120 帧。本文把两个子集的训练数据都当成训练样本,只使用带有人工标记异常帧的视频进行测试。因此,本文获得的训练数据集(3D 梯度特征)总共有307200 个10×10×5 维的特征。
3.2 实验结果以及分析
下图展示了在UCSDped1 中测试数据中的第三个视频中的第142 帧的数据。

图2 异常行为

图3 图3的真实异常标记的位置

图4 本文计算出来的异常位置
图2 用红色矩形框标记的为异常行为(在人行道上骑车),图3 是人工标记的异常位置,图4 是本文算法检测出的异常行为位置,从图2-图4 可以看出,本文异常定位的结果比较准确。
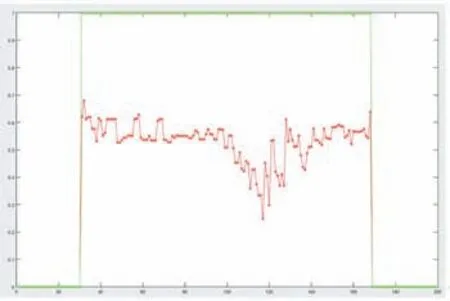
图5
图5 绿色代表测试数据中真实的正常和异常情况,正常为0,异常为1,红色代表该异常的代价(对于小于一定阈值的值,本文直接计算为0)。
图5 是图2 所在帧的整个视频的重构代价函数变化,横轴表示视频帧数,纵轴表示每一帧的重构代价,当阈值取0.25 的时候,能把含有异常行为的帧检测出来。从图2-图5 可以分析出,本文算法对于异常检测与异常定位的方法是有效的。并且经过实验,本文异常检测的准确率可以达到94.4%,准确率的计算是是根据本文计算出来的掩模(图4)的面积与真实数据的掩模的面积(图3)的比值是否大于0.4 得到的。如果比值大于0.4,则判定该帧异常定位结果正确,最后将所有测试视频计算出来的平均值作为准确率。除此之外,本文也采取了ROC 曲线对实验结果进行分析,同时也与其他研究中的实验结果进行了对比。如图6所示:

图6 ROC曲线,横轴为误检,纵轴为检测正确
从图6 可以看出,本文算法在被检测为异常行为,而实际为正常行为的概率(FPR)较低的情况下,检测率(TPR)也较高。并且也与其他算法相比,AUC(Area Under Curve)也能达到不错的效果。最后本文在时间上也与其他算法进行了对比,本文测试阶段主要有两个过程耗时较长:一是特征提取,二是使用算法2 进行异常检测。从表1 可以看出,本文的方法在时间上能提升不少,因此本文算法在提升时间效率方面有显著效果。
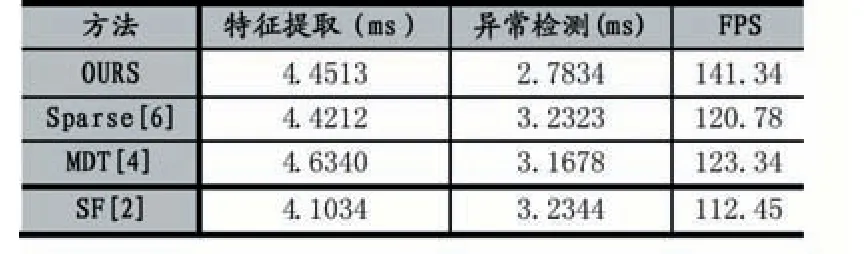
表1 几种方法的时间比较
4 结语
本文提出了一个基于稀疏子字典组合学习的异常检测方法,对于字典D,我们用n 个子字典构成,其中每一个字典由一些基础向量构成,并且使该子字典能尽可能多的表示训练样本。最后在UCSD 数据集上对检测结果和时间性能进行了验证,该方法能通过减少传统稀疏编码的搜索维数,在不影响检测结果的情况下,有效地提升检测的速度,并且当使用MATLAB 在普通台式PC 上进行计算时,本文的方法也能达到高检测率以及高速率。
猜你喜欢
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
汉字汉语研究(2020年2期)2020-08-13 07:52:48
科技创新与应用(2020年6期)2020-02-29 10:39:27
电子制作(2019年22期)2020-01-14 03:16:24
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
