
一种场景内容分布的交互式渲染系统
2019-03-02 01:58柳有权张彩荣陈彦云
图学学报 2019年1期
孙 昭,柳有权,张彩荣,石 剑,陈彦云
一种场景内容分布的交互式渲染系统
孙 昭1,柳有权1,张彩荣1,石 剑2,陈彦云3
(1. 长安大学信息工程学院,陕西 西安 710064; 2. 中国科学院自动化研究所模式识别国家重点实验室,北京 100190; 3. 中国科学院软件研究所计算机科学国家重点实验室,北京 100190)
近年来,三维虚拟场景的规模和复杂程度不断提高,受到硬件的限制,一些应用中的超大规模场景(如建筑群,城市等)很难在单机上进行渲染或满足可交互的需求。针对该问题,提出了一种分布式渲染框架,将大规模场景在内容上进行划分,得到单一节点可渲染的子场景。这些子场景被分布到集群中不同的渲染节点进行处理,其渲染结果根据深度信息进行合成得到整个场景的最终渲染结果。为了降低交互响应时间,需对子场景的渲染结果进行压缩传输。实验充分验证了提出的分布式渲染系统能够高效处理超大规模场景的渲染和交互,并且具有良好的可扩展性,能够满足很多领域中对大规模场景交互式渲染的需求。
渲染;分布式系统;场景分布;交互式
近年来,计算机辅助设计在制造、建筑、机械设计和软件开发等行业得到了广泛地应用,其模型对象通常具有规模大、精度高等特征。如,一套完整的建筑信息模型(building information modeling,BIM),通常包含多个建筑模型、钢架结构模型、管线模型等,其中每个模型都包含复杂的几何信息。由于需要处理庞大的几何数据,所以对于此类场景的渲染是一个极具挑战的问题。
由于渲染是一类计算密集型任务,针对大规模场景,目前主流的方法是对其进行简化。通过模型简化,可以得到“可渲染”的场景或提升场景的渲染效率,但是也会带来一定的质量损失。此外,对于大规模场景超过内存限制的情况,也可以使用out-of-core渲染来进行处理。在离线渲染中,人们通常使用集群(渲染农场),通过增加计算资源来减少所需要的渲染时间,而该种集群渲染通常是基于帧或图像区域进行任务划分,单一渲染节点上仍然需要完整的场景内容数据。
如何提高渲染效率以满足具体应用的交互需求是渲染大规模场景所面临的主要挑战。对此,本文提出了一种分布式渲染框架来处理大规模场景的渲染和交互。首先,需将大规模场景在内容上划分为单一节点可渲染的子场景,并将其调度到渲染集群中的渲染节点上进行处理。子场景的渲染结果将发送到客户端,并根据场景深度信息进行合成得到最终渲染结果。在整个过程中,客户端产生的交互动作通过网络消息通知渲染节点进行处理,更新渲染结果。在网络带宽的限制下,为了降低交互响应时间,可选择一个高效的实时压缩算法对渲染结果进行压缩传输,实验表明本文提出的分布式渲染系统能够达到可交互的性能,可以满足实际应用对大规模场景交互式渲染的需求。
1 相关工作
渲染可分为实时渲染和离线渲染。实时渲染是图形数据的实时计算和输出,主要应用于3D游戏和交互式的可视化等[1]。由于对响应时间有较高的要求,为了提升渲染性能,实时渲染在结果的真实感上会有所妥协。离线渲染针对动画、电影等应用,通过长时间的大量计算来模拟光线的物理传播以获得较高真实感的图像。近年来,实时渲染和离线渲染得到了不断发展,而随着硬件性能的不断提升,实时渲染的真实感也得到了很大的进步。例如游戏画面的分辨率和帧率越来越高(2048×1080,120 fps),效果也越来越真实。
大规模场景的渲染任务繁重且耗时长。针对大规模场景,LUEBKE[2]提出了一种几何图元删减的方法,能够在一定程度上降低场景的复杂程度。但是,该方法容易造成模型结构的形变。除此之外,一些基于图像的处理算法[3-4],尝试使用自适应分辨率纹理或使用图像代替几何图元的方法来降低渲染的数据总量。但是与几何图元裁剪类似,此类渲染方法都是以牺牲视觉质量为代价来换取场景绘制效率的提升。本文所提出的系统不依赖于模型简化,但是可以使用模型简化对场景进行预处理来进一步提升效率。
分布式渲染是将图像渲染分布到多台计算机上进行处理的一种技术。MOLNAR等[5]提出了将分布式渲染架构按照排序发生的顺序和位置分为Sort-First、Sort-Middle及Sort-Last 3类,并分析了各自的计算、传输性能以及优缺点。郑利平等[6]针对地貌的渲染提出了基于Sort-Last的分布式渲染架构,其具有一定的灵活性和可扩展性,适合于更一般的渲染服务,如几何体渲染。高官涛等[7]提出了一套基于Spark MapReduce的分布式渲染系统,能够显著提高渲染速度,减轻开发所需的工作量。随着移动设备的快速发展,远程渲染系统带来了诸多便利,如CHEN等[8]提出了一种客户端GPU加速的场景扭曲技术,将渲染任务分布到客户端和服务端共同渲染,最终进行融合,可以大幅减少交互延迟并能提高用户体验。
针对大规模场景超过内存限制的情况,VARADHAN和MANOCHA[9]提出了out-of-core渲染技术,通过空间索引结构快速对所需的数据进行检索,并通过调度算法实现显存-内存、内存-外存之间的数据交换来进行渲染。SCHEIBLAUER和WIMMER[10]使用out-of-core来渲染大规模点云数据,并提出了点云选择和交互编辑的算法。本文方法也可以使用out-of-core来渲染超过内存限制的大规模子场景。
2 分布式渲染系统
2.1 系统概述
本文提出的分布式渲染系统架构如图1所示。客户端与渲染节点组成Master-Slave结构的分布式系统,渲染客户端(Master)负责渲染节点、渲染任务和场景资源的管理,并处理最终渲染结果的合成、展示和用户交互;渲染节点(Slave)持有渲染所需的场景数据并提供计算资源。客户端和渲染节点之间通过网络消息进行通信、传递任务、交互信息以及渲染中间结果。

图1 分布式渲染系统架构
2.2 分布式渲染流程
本文所提出的分布式渲染系统在处理渲染任务时,整个流程分为以下步骤:
步骤1.系统初始化,客户端与渲染节点建立1-to-N的网络连接。
步骤2.用户发起渲染请求,客户端基于渲染任务中场景在渲染节点上的分布,进行子任务分配,并发送消息通知渲染节点。
步骤3.渲染节点接受到渲染任务后,根据内容加载对应的场景,并将结果发送给客户端。
步骤4.客户端在全部场景加载成功后通知渲染节点进行渲染;若场景加载失败则通知用户,并通知渲染节点释放资源。
步骤5.渲染节点接到渲染指令后对场景进行渲染,将子场景的渲染结果(图像及深度)发送给客户端。
步骤6.客户端接收到渲染节点的中间结果后,根据深度信息进行合成,得到最终渲染结果。
步骤7.当用户产生交互行为,需要更新渲染结果时,客户端发送消息通知渲染节点,回到步骤5进行处理。
分布式渲染整体流程如图2所示。
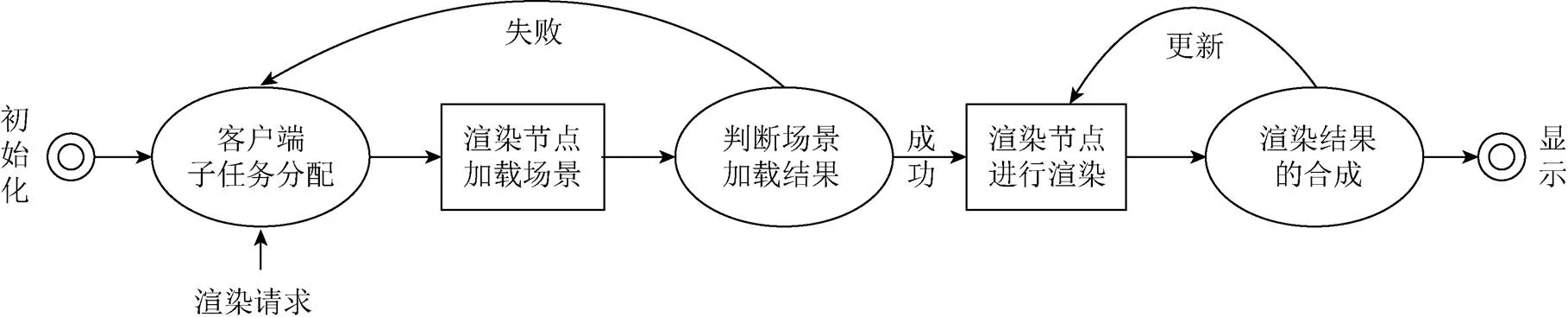
图2 分布式渲染系统流程图
2.3 渲染结果压缩
在网络上,直接传输渲染后的中间结果会对分布式渲染中响应时间产生很大影响。所以为了降低交互延迟,需对渲染节点上渲染任务的结果进行压缩后传输。综合考虑各种压缩算法的压缩比以及压缩/解压缩效率,可选择Snappy无损压缩算法对渲染结果进行压缩。Snappy是Google基于LZ77用C++语言编写的快速数据压缩与解压程序库,其目标是有非常高的速度和合理的压缩率。表1列出了Snappy和其他压缩算法在性能上的对比[11]。
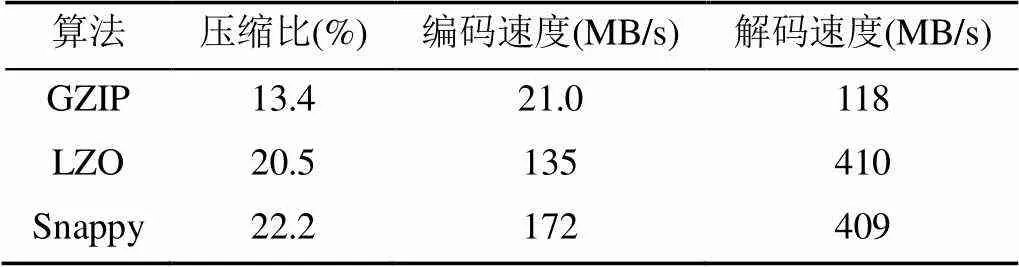
表1 多种压缩算法性能对比
3 性能和结果
3.1 实验环境与对象
本文使用2台计算机作为渲染节点,以及一台笔记本作为客户端。客户端与渲染节点之间通过千兆以太网络进行连接。渲染节点的配置为i7 3.40 GHz CPU,8 GB内存以及NVIDIA GeForce GTX 750 Ti GPU。
本实验对象将使用2个不同小区建筑的真实数据模型(场景A、B)作为测试数据。当进行场景划分时,将每一栋楼作为一个子场景。场景A,B的大小分别为874 MB,2 215 MB,分别包含6个及14个子场景。图3为场景B的模型俯视图,可以看到小区建筑中包含了楼体、公路、湖泊等子场景。图4分别展示了场景B中幕墙、整栋楼的钢架结构以及楼体本身等不同子场景的结构模型。
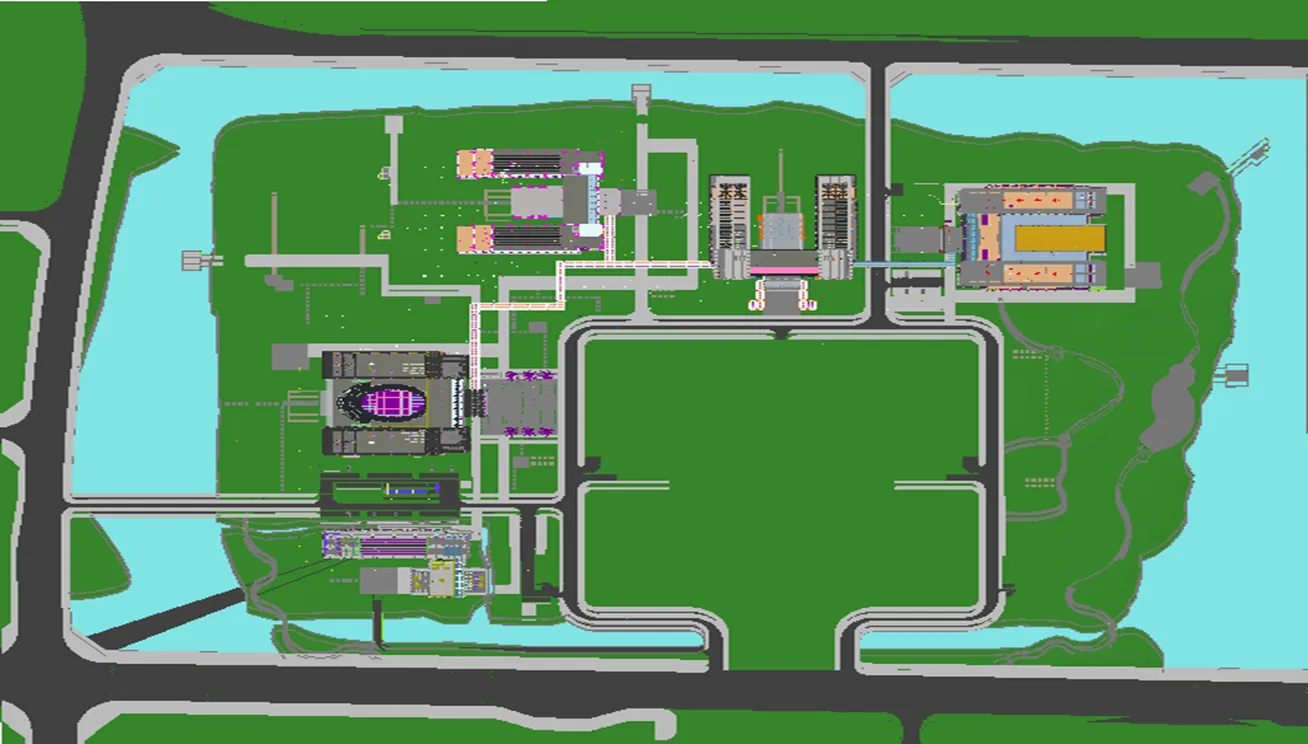
图3 场景B
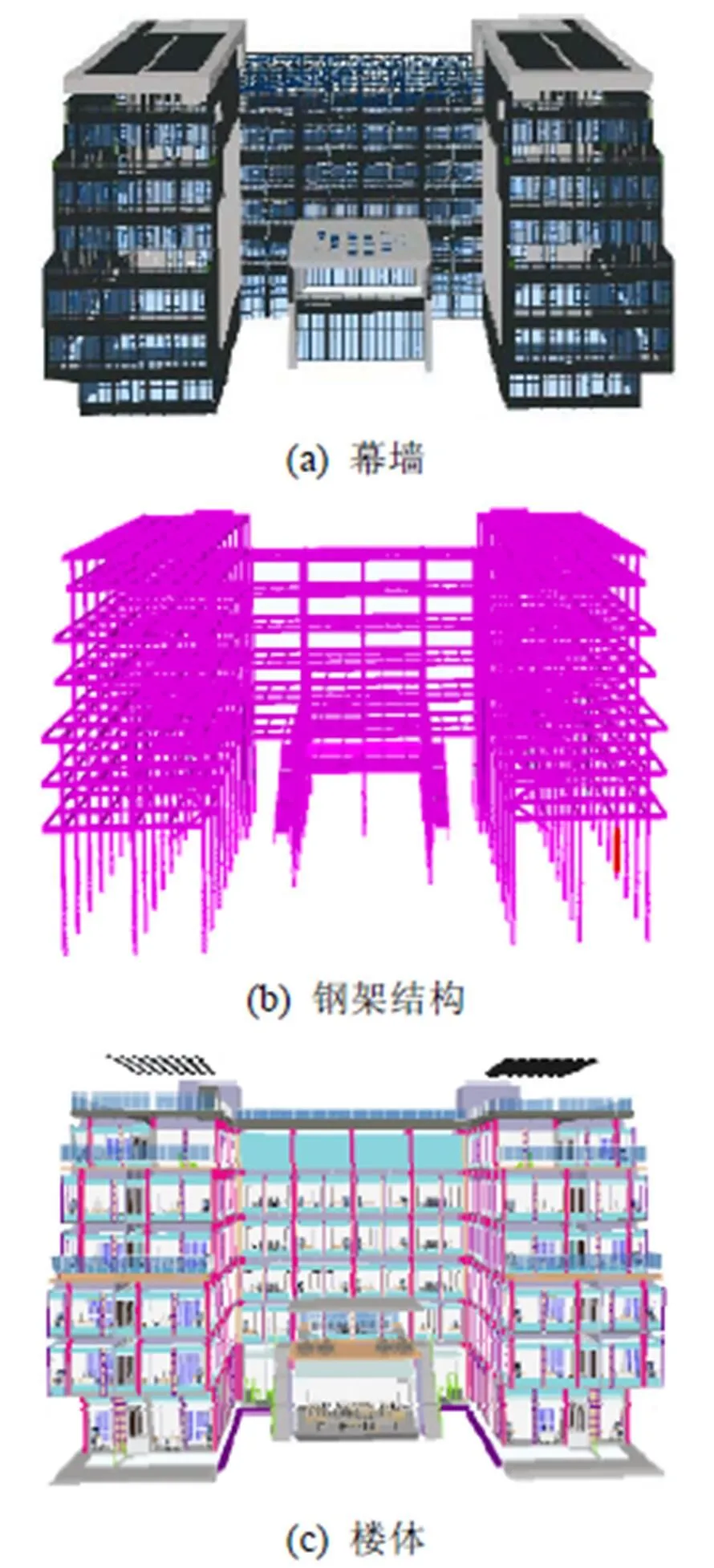
图4 场景B子场景
3.2 单机渲染性能
将场景A,B分别进行加载,完成单机渲染。表2和表3分别列出了2个场景及其子场景在单一渲染节点上的渲染性能。
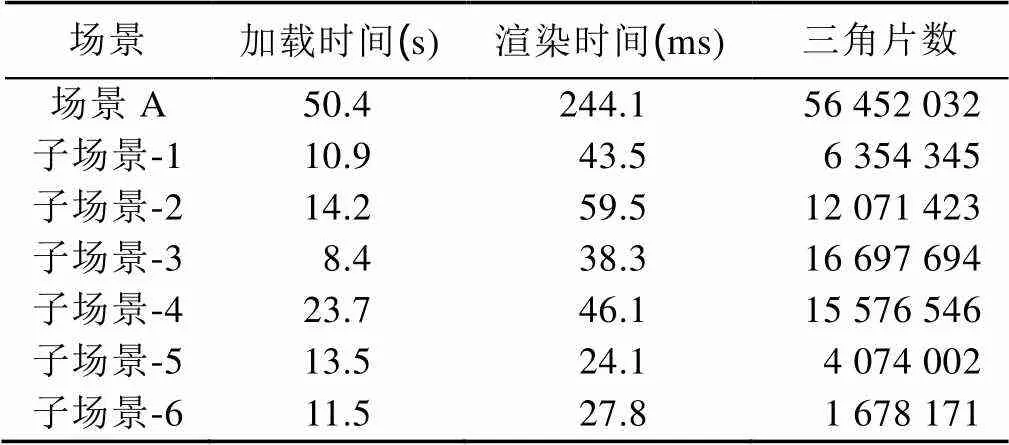
表2 场景A单机渲染性能
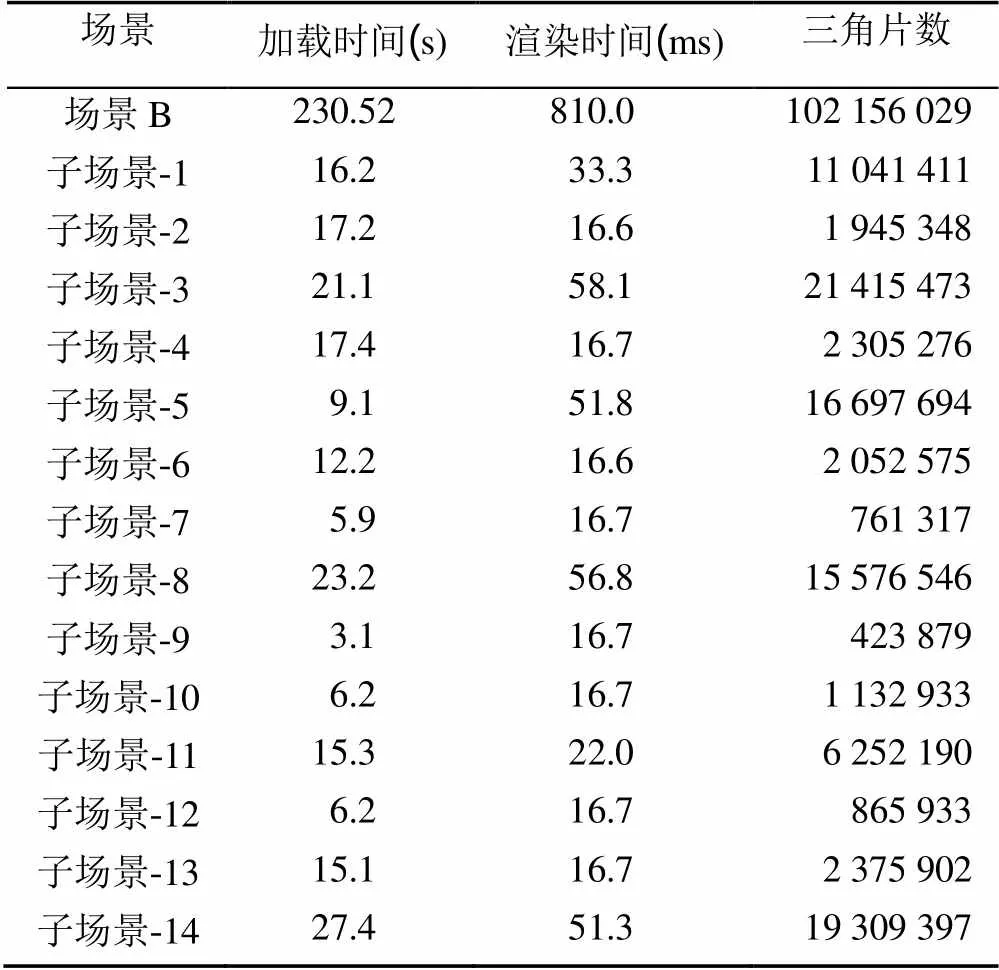
表3 场景B单机渲染性能
3.3 分布式渲染性能及分析
当进行分布式渲染大规模场景时,将场景中的内容按内存大小平均分配到两台渲染节点上进行渲染。表4显示了场景分布式渲染性能结果。
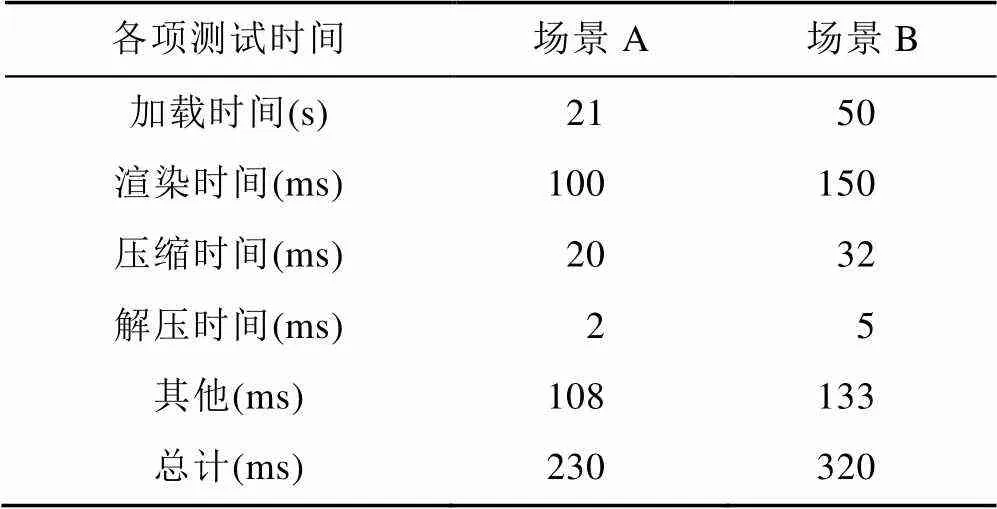
表4 场景分布式渲染性能
表4中各项测试时间结果是在完成相应任务时耗时最长的渲染节点中取得;其他项为网络通讯和消息处理等时间;总计为交互响应延时,包括渲染时间、压缩解压时间、传输时间、客户端发送/接收指令等时间。
实验结果表明,采用本文提出的分布式渲染系统进行大规模场景绘制,减少了场景加载时间,将渲染结果进行压缩传输,能够降低系统交互延时,解压时间可以忽略不计。整个分布式渲染系统交互响应所需时间远远小于单机渲染时间,利用分布式渲染框架,极大地提高了渲染效率。
4 小 结
本文提出了一种渲染大规模场景的分布式渲染框架。将大规模场景在内容上划分为单一节点可渲染的子场景,使用多个渲染节点进行分布式处理,各个渲染节点上的子场景渲染结果根据深度信息进行融合得到最终结果,为了降低交互延时,使用一种实时压缩算法对渲染结果进行压缩,减少了网络传输的开销。本文提出的分布式渲染系统能够在处理超大规模时达到可交互的性能。
[1] AKENINE-MÖLLER T, HAINES E, HOFFMAN N. Real-time rendering [M]. Wellesley: A.K.Peters Ltd, 2008: 1-2.
[2] LUEBKE D, WATSON B, COHEN JD, et al. Level of detail for 3D graphics [M]. New York: Elsevier Science Inc., 2002: 219-223.
[3] 杜莹, 武玉国, 游雄. 全球虚拟地形环境中Mipmap纹理技术研究[J]. 测绘科学技术学报, 2006, 23(5): 355-358.
[4] ANDUJAR C, BRUNET P, CHICA A, et al. Visualization of large-scale urban models through multi-level relief impostors [J]. Computer Graphics Forum, 2010, 29(8): 2456-2468.
[5] MOLNAR S, COX M, ELLSWORTH D, et al. A sorting classification of parallel rendering [J]. IEEE Computer Graphics and Applications, 1994, 14(4): 23-32.
[6] 郑利平, 陈斌, 王文平, 等. 基于分布式渲染架构的远程可视化研究[J]. 计算机研究与发展, 2012, 49(7): 1438-1449.
[7] 高官涛, 郑小盈, 宋应文, 等. 基于Spark MapReduce框架的分布式渲染系统研究[J]. 软件导刊, 2013(12): 26-29.
[8] CHEN Y J, HUNG C Y, CHIEN S Y. Distributed rendering: Interaction delay reduction in remote rendering with client-end GPU-accelerated scene warping technique [C]//IEEE International Conference on Multimedia and xpo Workshops. New York: IEEE Press, 2017: 67-72.
[9] VARADHAN G, MANOCHA D. Out-of-core rendering of massive geometric environments [EB/OL]. (2002-11-01)[2018-03-18].http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=90A14D277042676F059C400F3BF7066E?doi=10.1.1.298.4890&rep=rep1&type=pdf.
[10] SCHEIBLAUER C, WIMMER M. Out-of-core selection and editing of huge point clouds [J]. Computer and Graphics, 2011, 35(2): 342-351.
[11] GEORGE L. HBase: The definitive guide: random access to your planet-size data [M]. California: O’Reilly Media, Inc., 2011: 424-425.
A Scene-Distributed Interactive Rendering System
SUN Zhao1, LIU You-quan1, ZHANG Cai-rong1, SHI Jian2, CHEN Yan-yun3
(1. School of Information Engineering, Chang’an University, Xi’an Shaanxi 710064, China; 2. State Key Laboratory of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences, Beijing 100190, China; 3. State Key Laboratory of Computer Science, Institute of Software, Chinese Academy of Sciences, Beijing 100190, China)
With the constant increase in the scale and complexity of three-dimensional virtual scenes in recent years, very large-scale scenes (such as buildings, cities, etc.) can hardly be processed on single rendering node and their interactive performance can also be hard to achieve. Aiming at this shortcoming, the authors present an interactive distributed rendering framework. The authors divide the large scene into a set of renderable sub-scenes, which are distributed to different rendering nodes for processing. Intermediate sub-scene rendering results are merged to the final result based on depth information. To reduce the latency, the rendering results are compressed to accelerate the network transmission. The proposed distributed rendering system can efficiently process rendering and interaction for large-scale scenes. Moreover, the experiment has also confirmed that it is able to provide good scalability. A wide range of applications can benefit from interactive distributed rendering by this system.
rendering;distributed system; scene distribution; interactive
TP 391
10.11996/JG.j.2095-302X.2019010087
A
2095-302X(2019)01-0087-05
2018-07-02;
2018-07-12
中央高校基本科研业务费专项资金项目(310824173401)
孙 昭(1992-),女,陕西咸阳人,硕士研究生。主要研究方向为计算机图形学。E-mail:2016124012@chd.edu.cn
柳有权(1976-),男,湖北秭归人,教授,博士,硕士生导师。主要研究方向为计算机图形学。E-mail:youquan@chd.edu.cn
猜你喜欢
新作文·高中版(2022年5期)2022-11-22
新作文·高中版(2022年5期)2022-11-22
机械工业标准化与质量(2022年6期)2022-08-12
湖南电力(2022年3期)2022-07-07
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
传媒评论(2019年5期)2019-08-30
制导与引信(2017年3期)2017-11-02
雷达与对抗(2015年3期)2015-12-09
