
自然场景下人脸表情数据集的构建
2019-02-27 02:28叶继华李汉曦
数据采集与处理 2019年1期
叶继华 刘 燕 李汉曦 甘 荧
(江西师范大学计算机信息工程学院,南昌,330022)
引 言
人脸表情识别技术是涉及生物特征识别、图像处理、运动跟踪、机器视觉、模式识别、生理学、心理学等研究领域的一个富有挑战性的交叉课题,是多年以来模式识别与人工智能领域研究的一个热点问题[1]。
人脸表情识别发展较晚,目前还不够成熟,运用较成熟的数据集有日本Advanced Telecommuni⁃cation Research Institute International(ATR)的专门用于表情识别研究的基本表情数据库JAFFE和Cohn-kanade表情数据库(CK),以及Lucey等人在2010改进的数据集CK+,但是这几个数据集信息比较单一并且图像数量比较少,如果用于深度学习的表情识别中远远不够,而且数据集都是在实验室条件下采集的表情图像。为配合表情研究,实验室自建了一个图像数量更多且表情类别更丰富(10种表情)的自然场景下人脸表情数据集(Facial expression datasets in the wild,FELW)。
1 人脸表情数据集的构建
1.1 自然场景下带标签的人脸表情数据集(FELW)
FELW数据集包含26 848张人脸图像,每张图像带有人脸部件的状态标签和表情标签两种标签。下面简单介绍FELW数据集的构建过程,数据集构建分为收集人脸表情图像和标注两个阶段。
1.1.1 收集人脸表情图像
在互联网上批量下载30万张自然场景下的人脸图像;然后采用自动人脸检测程序,获得了将26 848张人脸图像;最后裁剪其灰度化成120像素×120像素的灰度图,得到未带标签的FELW的原始图像。图1是数据集部分原始表情图像。
1.1.2 标注
这个阶段是对灰度图标注,标注内容包括了人脸部件的状态标签(Part_Label)和表情标签(Emo⁃tion_Label)两种标签。
Part_Label,包含了眉、眼、嘴、鼻、肌肉五大类。Emotion_Label,包含 10类表情,分别为平(中性)、喜(高兴)、怒(生气)、哀(悲伤)、惊(惊讶)、恐(恐惧)、恶(厌恶)、羞(害羞)、傲(傲慢)、鄙视。FELW 标注是用MATLAB中的GUI设计界面的,将原始表情图像分成多组,每组由一个人标注,FELW的标签标注界面实例如图2所示。
因为人在各种表情下面部各个部件的状态变化大多数比较细微,有时候会达到很难辨别的程度。因此需要对所选定的5个面部部件的状态进行标准的设定。对眉毛来讲,设定5个状态,分别为正常,弯眉、皱眉、眉毛上竖和平直。对眼睛同样设置5个状态,分别为正常、眼眯、眼向下(可通过观察上眼皮是否下垂来辅助判断)、瞪眼和眼向上(可通过观察眼球是否朝上辅助判断);嘴巴则设置了6个状态,分别为正常、上翘(通过观察嘴巴是否上扬辅助判断)、嘴向下(通过观察嘴部形成的弧线是否朝下进行辅助判断)、张嘴(通过观察嘴巴是否张开或形成一个O形进行辅助判断)、咬牙(在能看到牙齿的情况下,观察待标注图像中的对象是否咬牙切齿)和撅嘴(嘟嘴或撅嘴);鼻子只设置了4个状态,分别为正常、鼻孔收缩(通过观察鼻头部分的肌肉是否紧绷进行辅助判断)、鼻孔张大(通过观察鼻头部分的肌肉是否舒张进行辅助判断)和鼻耸(通过观察鼻根部分是否紧缩进行判断);肌肉则只设定3个状态,分别为正常、紧绷(通过结合观察待标注对象是否痛苦和直接观察其肌肉是否紧绷进行辅助判断)和放松(通过观察待标注对象肌肉是否舒张或传达的表情是否欢喜而进行辅助判断)[2]。图2的左边是Part_Label部分,Part_Label是一组1×5的向量;右边是Emotion_Label部分,使用的是软标签形式,有10组表情,每组表情都可以进行打分,打分区间在1~5,分数越高表示该表情的概率越大。当判断不出任何表情或者脸上被遮挡时,直接对表情打6分,表示该图像不属于任何表情。最终得到的EmotionLabel是一组1×10的向量。FELW是一个包含了26 848张120×120的灰度人脸图像和其对应的Part_Label和Emotion_Label信息的数据集,这就是自然场景下带标签的人脸表情数据集。

图1 FELW数据集部分表情图像Fig.1 FELW partial expression image of data set
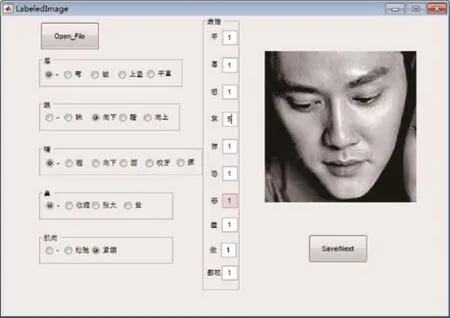
图2 GUI界面标注实例Fig.2 GUIinterface annotation instance
1.2 FELW数据集的不足
建立FELW数据集后,采用传统方法和深度学习方法进行实验,FELW数据集使用传统方法的最高识别率是65.01%,使用深度学习的人脸表情识别方法最高识别率是56.53%,最好的实验结果相对于先研究的数据集实验结果来说识别率仍然不高。通过对实验结果的分析,发现原数据集存在以下不足:
(1)图像并不全是正脸,直接用这样的图像进行表情识别的识别率不会高。
(2)Part_Label部分不合理。FELW的Part_Label部分有一些部件有主很难判断的标签,对于标注者来说,“鼻”和“肌肉”部分的细节很难在一张灰度图中区分。很难判断“鼻”的正常表情,收缩、张大,耸;同样也难以判断“肌肉”的松弛、紧绷。同时可以去掉一些重复的状态,“眉”部分的正常表情和弯(眉弯)可以合并成一个状态,因为大部分人的眉毛在正常情况下就是弯的。“眼”部分的特殊形状,向上(眼向上),向下(眼向下)部分也难以判断。“嘴”部分的“正常”可以去掉,因为大部分人的嘴巴在正常情况下就是上翘或者下垂的,与第二第三状态重合。
(3)每个Emotion_Label都需要打分太复杂。
(4)FELW的每张图像的标签只由一个标注者进行标注,太过主观。
1.3 FELW数据集的改进
1.3.1 数据集的改进
根针对上述不足,图像并不全是正脸,可以添加各个角度方位的状态标签;将Part_Label部分冗余的状态作调整;修改Emotion_Label部分的打分情况;扩大标注规模。对数据集进行如下改进:
(1)在人脸部件状态标签中对添加“人脸的角度”,“人脸的角度”的状态有“正脸”“左侧脸”“右侧脸”“仰视”“俯视”。
(2)对 Part_Label进行改进,去掉“鼻”和“肌肉”部分;调整“眉”“眼”“嘴”部分。
(3)Emotion_Label进行改进,直接勾选表情,去掉对各个表情的打分,最后取置信度。
(4)所有图像的标注都由3个不同的人进行标注,提高客观性。
对改进的FELW数据集的Part_Label进行标注时需要观察图像的眉毛、眼睛、嘴巴、人脸角度方向的状态,眉毛有4种状态,眼睛有3种状态,嘴巴有4种状态,人脸角度方向有5种状态。图3是对改进后的FELW人脸的4种部件的每个状态的展示。
图4是改进后的FELW数据集的GUI标注界面,图左边是Part_Label,包含了眉、眼、嘴、人脸角度方向4大类;右边是Emotion_Label,包含10类表情,是多选的;在界面最下面是“置信度”,置信度是标注者自己对整张图像的判断打分,置信度区间为0~5,置信度越高表示判断越高,置信度为0表示看不出任何表情,用Coefficient表示置信度。
标注完后,Part_Label和 Emotion_Label信息存入 .mat文件,.mat文件包括 EmotionLabel、Name、value、Coefficient。EmotionLabel表示 Emotion_Label标签,是一个 1×10向量,10个向量元素是 10类表情,分别为平(中性)、喜(高兴)、怒(生气)、哀(悲伤)、惊(惊讶)、恐(恐惧)、恶(厌恶)、羞(害羞)、傲(傲慢)、鄙视,每个向量元素是Emotion_Label部分勾选的情况,表情被勾选是1,否则为0;Name表示表情图像的命名,实验过程中可以通过Name索引到标签对应的表情图像;value表示Part_Label,是一个1×5的向量,每个向量元素对应的是Part_Label部分中每个部件勾选的位置;Coefficient是置信度。

图3 改进后的FELW标签的人脸四种部分状态展示Fig.3 Four partial states of the face labelled by the improved FELW
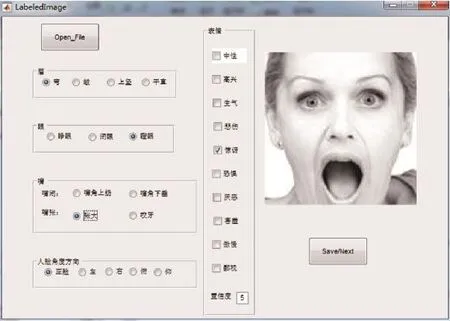
图4 改进后的FELW标注界面实例Fig.4 Improved FELW annotation interface instance
每张表情图像中3人分别标注,因此改进后的FELW包含了灰度表情图像和其对应的3组.mat文件,.mat文件包含了Part_Label和Emotion_Label信息。对3组数据进行分析,将3组数据结合成一组数据。
1.3.2 Kappa一致性检验
Kappa一致性检验是用Kappa系数来检验两种检验结果是否一致,可以根据Kappa系数的取值大小来衡量两种结果的一致性程度,Kappa系数的值越大说明两种结果的一致性越高[3-4]。Kappa系数是从比较两个观测者对同一事物的观测结果或同一观测者对同一事物的两次观测结果是否一致出发,用于由机遇造成的一致性和实际观测的一致性之间的差别大小作为评价基础所提出的统计指标[5]。Kappa公式如下

式中:pe是每一类正确分类的样本数量之和除以总样本数,也就是总体分类精度;假设每一类的真实样本个数分别是a1,a2,…,ac,预测出来的每一类样本个数分别是b1,b2,…,bc,样本个数为n,则有pe=。3组EmotionLabel两两进行Kappa一致性检验,kij≥0.4(kij表示EmotionLabel(i)和EmotionLabel(j)进行Kappa一致性检验得到的Kappa值)时,EmotionLabel(i)和Emo⁃tionLabel(j)与其Coefficent值进行下一步计算,公式如下
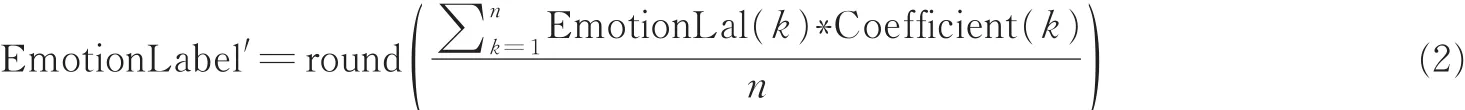
式中:n表示经过Kappa一致性检验筛选下的EmotionLabel组个数,k表示筛选出下的EmotionLabel组标号,对向量中每个元素四舍五入取整。最后得到的EmotionLabel′也是一个软标签,EmotionLabel′的向量元素的值也在0~5之间。
1.3.3 数据的合成
由于Part_Label的标注是单选的,将3组PartLabel值的相同位置的向量元素值进行比较,若3组相同位置的向量元素都不相同,则随机选择一个元素作为最终元素;若3组相同位置的向量元素有任意两个元素相同,则选取这个元素作为最终元素。
Emotion_Label是多选,则先将三组EmotionLabel用Kappa一致性检验分析的结果结合Coefficient得出最后的EmotionLabel′。
为了区别Kappa一致性检验对数据集的识别率的影响,本文将原始3组标注数据不经过Kappa一致性检验直接用式(2)进行结合生成EmotionLabel′向量,最后组成数据集FELW-1,用于FELW的对比实验。
2 人脸表情识别
2.1 传统的人脸表情识别方法
人脸表情识别系统一般包括人脸检测、图像预处理、表情特征提取和表情分类4部分[6]。本文采用Gabor+2DPCA+SVM和Curvelet+2DPCA+BP两种传统的人脸表情方法进行人脸表情识别。下面介绍两种本文使用的传统人脸表情识别方法。本文数据集的表情图像已经是120像素×120像素的灰度图,可以省去人脸检测和预处理的部分,下面方法只包含了特征提取和表情识别的步骤。
(1)Gabor+2DPCA+SVM:先将网格化的表情子图像进行Gabor小波变换[7],然后用2DPCA[8-10]对子图进行降维,提取特征主成分。最后用SVM分类器进行表情分类。图5(a)给出了Gabor+2DPCA+SVM方法流程图。
(2)Curvelet+2DPCA+BP:对输入样本图像进行Curvelet变换[11]后再用2DPCA进行降维提取特征主成分。最后用BP神经网络[12]进行表情分类。图5(b)给出了Curve⁃let+2DPCA+BP方法流程图。
2.2 基于深度学习的人脸表情识别
本文表情数据集是大小为120像素×120像素的图像,表情分类是10类。所以模型输入是120×120的图像矩阵,输出是大小1×10的向量。本文使用了用于人脸表情识别的3个卷积神经网络模型FERNet(Facial Expression Recognition Net),图6是本文采用的3个CNN模型。
如图6(a)所示,模型1输入120像素×120像素的灰度表情图像,经过连续两个卷积层,一个池化层,再经过一个卷积层,一个池化层,然后经过三个连续的卷积层,再进行一个池化层,最后经过3个全连接层,输出一个1×10的向量。有12层网络,前3个卷积层进行ReLU[13]调整,再进行LRN[14]归一化后输出;后3个卷积层只经过ReLU调整。
如图6(b)所示,模型2是参照Zeiler&Fergus二人提出的ZF模型[15]设计的一个CNN模型。输入120像素×120像素的灰度表情图像,经过一个卷积层,一个池化层,再经过一个卷积层,一个池化层,然后经过3个连续的卷积层,再进行一个池化层,最后经过3个全连接层,输出一个1×10的向量。有11层网络,虽然网络层数没有模型1多,但是其卷积层的卷积核个数远多于模型1。前3个卷积层进行Re⁃LU调整,再进行LRN归一化后输出;后3个卷积层只经过ReLU调整。
如图6(c)所示,模型3与模型2的网络类似,但是没有添加LRN,目的是区别未使用LRN对卷积和ReLU的影响,体现出LRN是否会对实验结果产生影响。。输入120像素×120像素的灰度表情图像,经过连续两个卷积层,一个池化层,再经过一个卷积层,一个池化层,然后经过3个连续的卷积层,再进行一个池化层,最后经过3个全连接层,输出一个1×10的向量。整个网络的卷积层只经过ReLU调整。

图5 两种传统人脸表情识别方法流程Fig.5 Flowchart of two traditional facial expression recogni⁃tion methods
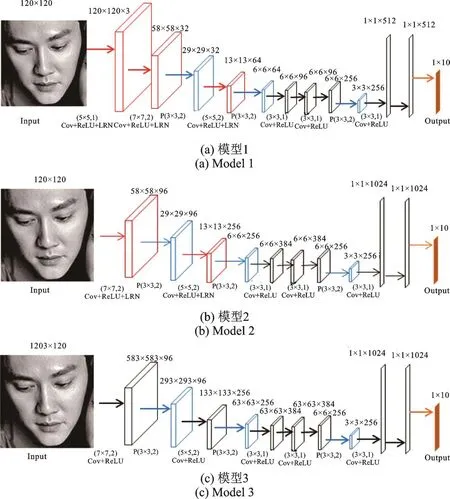
图6 本文采用FERNet模型Fig.6 FERNet model
3 实验结果与分析
将FELW分别用传统的人脸表情识别方法和深度学习的人脸表情识别方法进行实验,并用JAFFE数据集和FELW系列数据集进行实验对比。本文实验中用到的术语:
软标签:由于FELW系列数据集图像的Emotion_Label不止一种表情,将采用所有表情实验的表情标签称为软标签。
硬标签:在Emotion_Label向量元素中选择最大值作为该图像的表情标签。
FELW-原:未改进的数据集。
FELW:改进后的数据集。
FELW-1:未经过Kappa一致性检验数据集。
3.1 传统的人脸表情识别实验
(1)实验1
在FELW-原、FELW和FELW-1数据集和JAFFE数据集上分别用上述两种传统方法进行实验。由于JAFFE数据集只有7种表情且样本太少。首先,将FELW系列数据集转化为硬标签形式进行实验;然后,选取跟JAFFE数据集一样的表情类别,每种表情30张图像作为实验样本,Train∶Test=1∶1或2∶1进行实验,取200次实验平均值。实验结果如表1所示。
(2)实验2
由于JAFFE数据集没有软标签,并且两种传统方法中只有Gabor+2DPCA+SVM方法可以进行软标签实验,所以接下来的实验仅在FELW系列数据集上采用软标签形式进行Curvelet+2DPCA+BP实验。本文做了10组实验,用了5种不同的实验样本数量,分别是180,210,240,300,360,每种数量的Train∶Test=1∶1或2∶1进行实验,实验结果如表2所示。
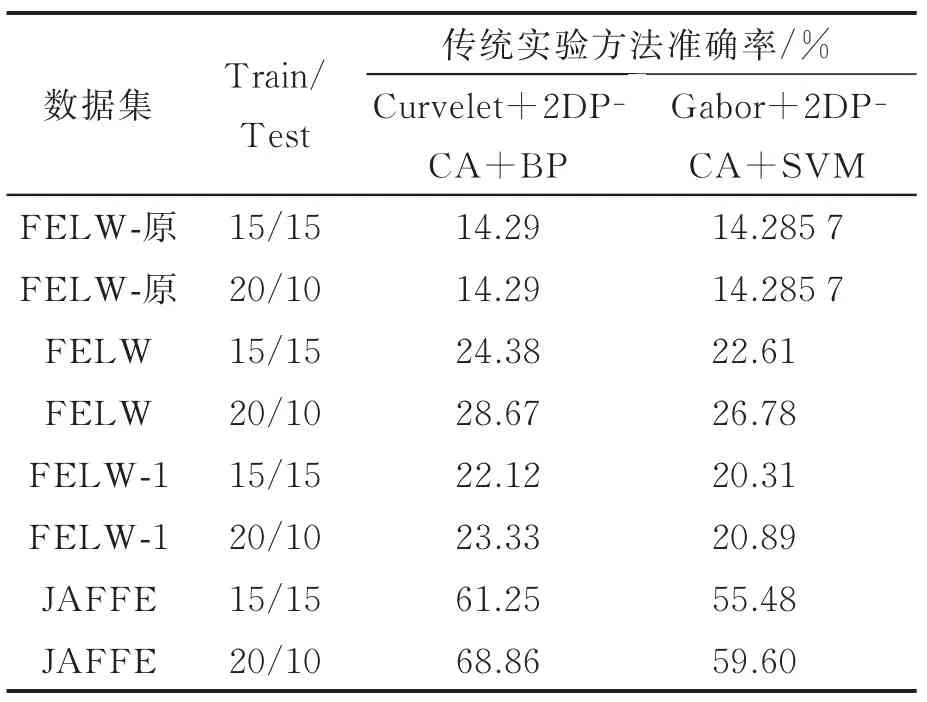
表1 JAFFE数据集和使用硬标签的三组数据集传统实验结果Tab.1 Traditional experimental results for JAFFE da⁃tasets and three sets of datasets using hard tags
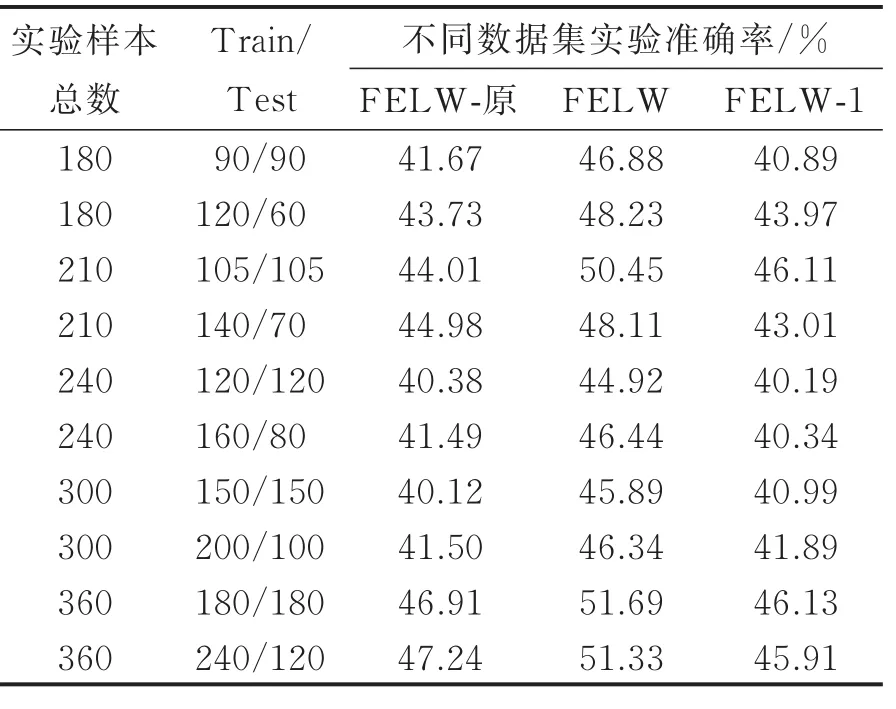
表2 软标签形式对3组数据集进行Curvelet+2DP⁃CA+BP实验准确率Tab.2 Curvelet+2DPCA+BP experimental accuracy for the three data sets in the form of soft tag
(3)实验3
在FELW系列数据集中采用Part_Label+软标签形式进行Curvelet+2DPCA+BP方法实验。实验样本参数与实验2一样,实验结果如表3所示。
(4)实验4
由于FELW2.0的图像没有经过图像配准,并不全是正脸,可能会影响人脸表情识别。将FELW数据集和FELW-1数据集挑出正脸图像重复实验3,实验结果如表4所示。
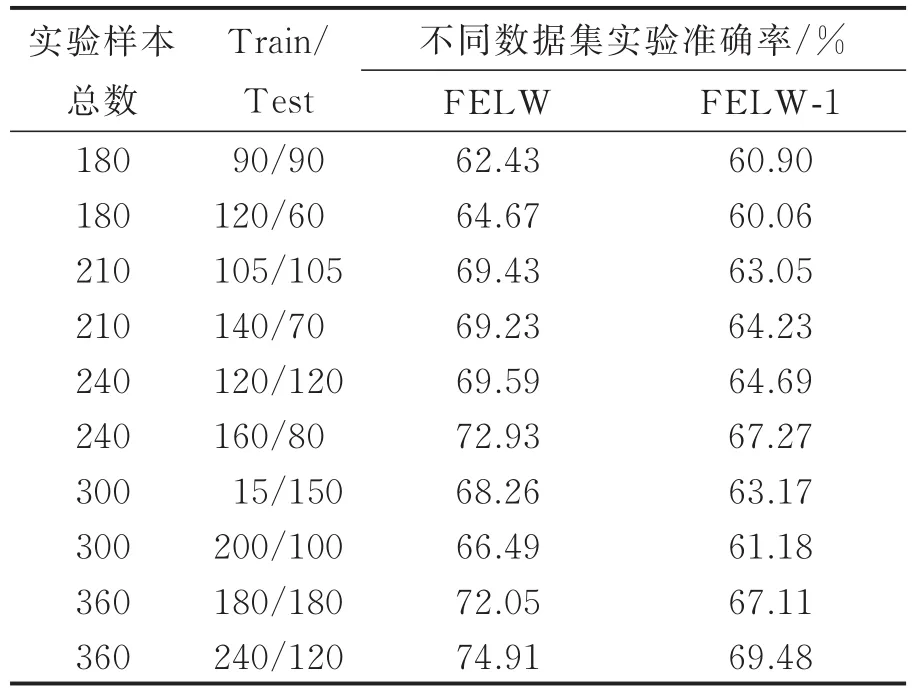
表4 正脸+Part_Label+软标签形式对3组数据集进行Curvelet+2DPCA+BP实验准确率Tab.4 Cur velet+2DPCA+BP exper iment al accura⁃cyfor three sets of data sets in the form of pos⁃itive face+Part_Label+soft label
(5)实验分析
实验1可知,JAFFE数据集的识别率在两种传统人脸表情识别方法中识别率比LFEW-原,LFEW和LFEW-1高出很多。原因是:JAFFE数据集图像都是正脸,而LFEW系列数据集是自然状态下的人脸表情图像,图像复杂;训练样本太少使得训练模型获取的特征表达不够全面;强制转换成硬标签也可能导致效果不好。
将实验2,3,4结果统计得到图7的折线图,从图中可以看出:①由折线图趋势可以看出,样本越多,识别率越高;Train∶Test=2∶1的识别率普遍比 Train∶Test为 1∶1的识别率高。②使用相同数据集,采用Part_Label加软标签的形式实验效果比仅采用软标签形式的效果更好。③使用相同数据集,筛选正脸的实验效果比未筛选正脸的效果更好。④使用相同形式实验时,FELW数据集实验效果最好。
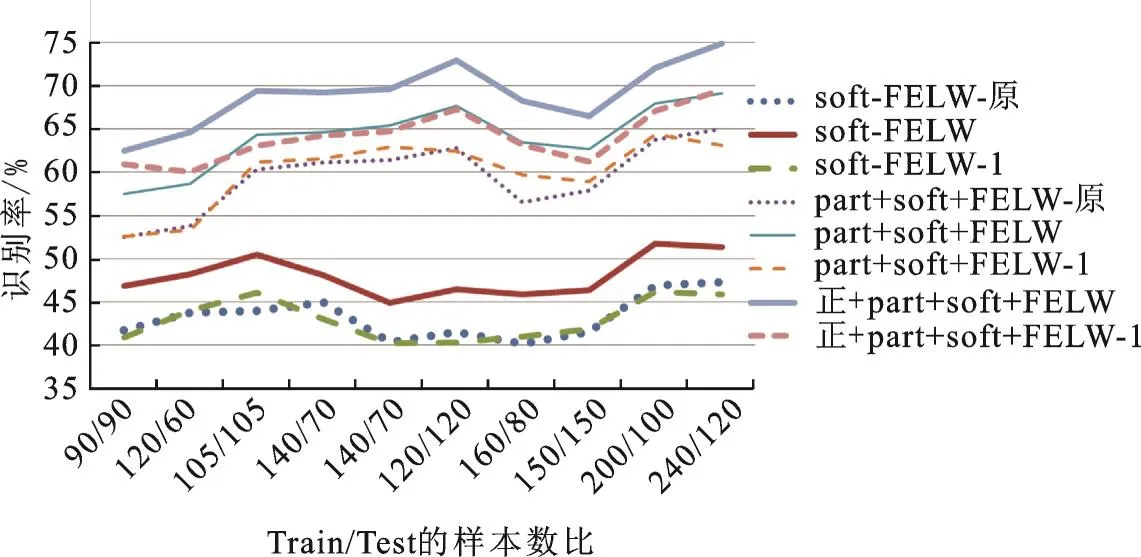
图7 实验2—4的结果统计Fig.7 Statistically results of Experiments 2—4
3.2 基于深度学习的人脸表情识别实验
数据集包含26 848张图像,从中随机选择20 000个样本进行训练,其余的作为测试样本,训练时将20 000个样本平均分成10份,分次取9份作为训练样本,剩下1份则作为验证样本。每个数据集进行10次实验,最终的识别率是10次实验的识别率的平均值。
(1)实验1
依照本章所建立的模型,采用硬分类规则进行表情识别,所得结果如表5所示。
(2)实验2
为了验证软标签的作用,使用软标签形式进行识别,将软标签用在网络最后一层,其他实验参数与实验1一致,实验结果如表6所示。
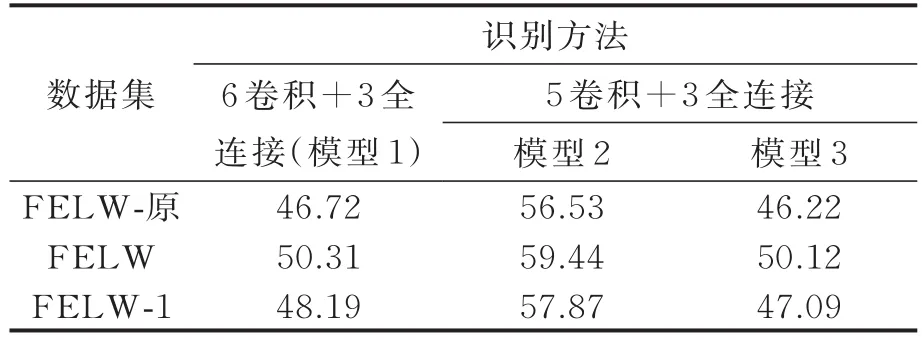
表5 硬标签形式在3种深度模型上实验准确率Tab.5 Har d label for m exper iment in three depth models%
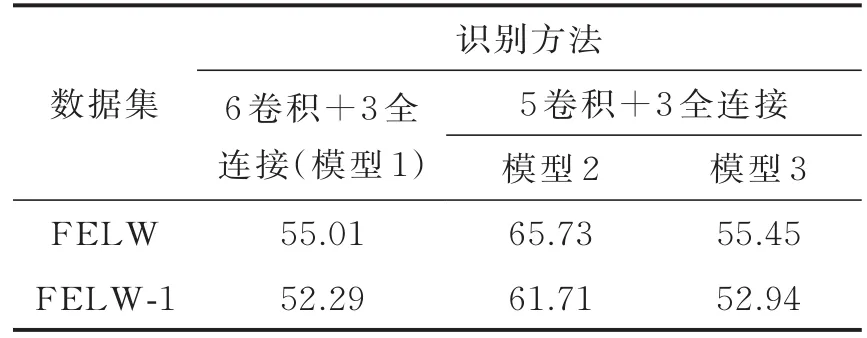
表6 软标签形式在3种深度模型上实验准确率Tab.6 Soft label for m exper iment in thr ee depth models%
(3)实验3
将Part_Label标签作为特征的表达,与原图像一起作为网络的输入。即Part_Label+软标签形式识别,其他实验参数与实验1一致,实验结果如表7。
(4)实验4
同时为了提高识别率采用筛选正脸的方式进行实验。使用软标签+正脸进行识别(软标签使用在模型最后一层),实验结果如表8所示。
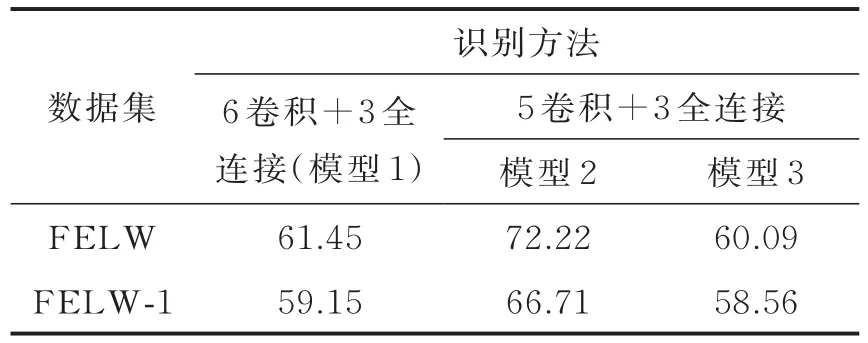
表7 Par t_Label+软标签形式在3种深度模型上实验准确率Tab.7 Part_Label+soft label for m exper iment in thr ee depth models%
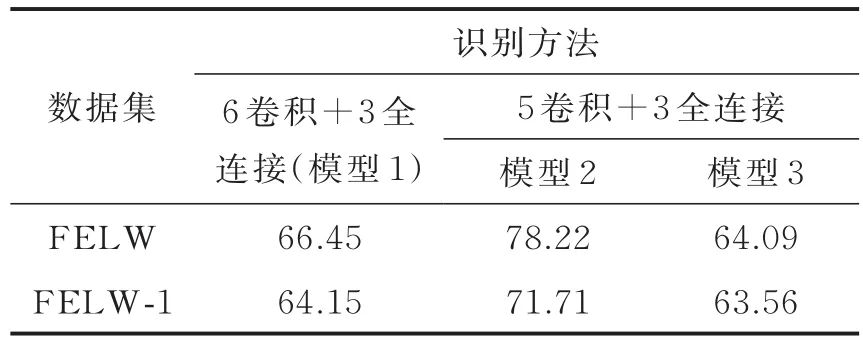
表8 正脸+Par t_Label+软标签形式在3种深度模型上实验准确率Tab.8 Positive face+Par t_Label+soft label form experiment in thr ee depth models%
(5)实验分析
将实验1—4结果统计得到柱形图8,由图8可以看出:①在相同数据集实验时,模型1识别率比模型3略高,因为模型1的网络更深;模型2实验识别率比模型1高,因为模型2使用的卷积核个数远比模型1多;模型2比模型3高,因为模型2使用了LRN。②采用相同形式使用相同模型实验时,FELW数据集识别率最高。③相同数据集在相同模型实验时,正脸+Part_Label+软标签的形式识别率最高。
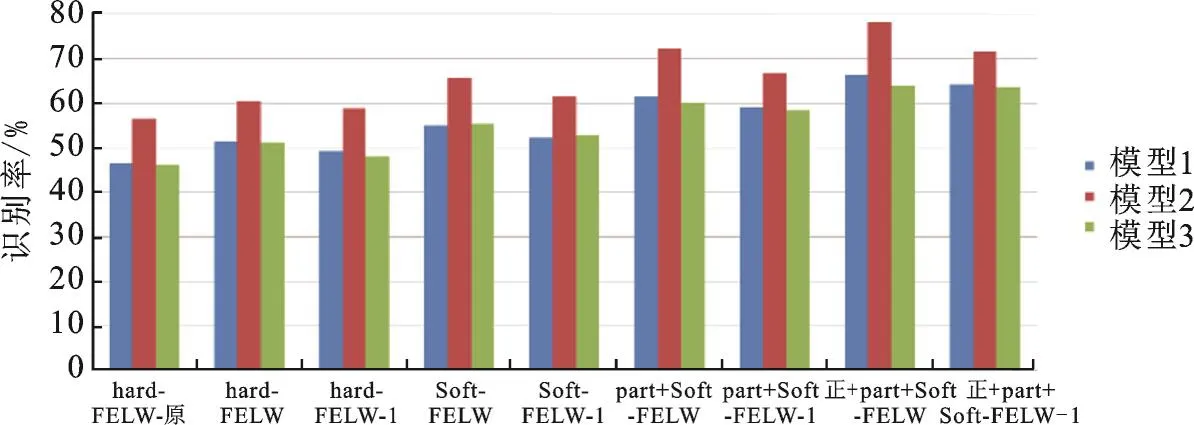
图8 实验1—4准确率统计柱形图Fig.8 Accuracy histogram of Experiments 1—4
4 结束语
本文介绍了人脸表情数据集FELW的建立与改进,并另建了一个FELW-1数据集与其对比。对这3组数据集分别用传统人脸表情识别方法和深度学习的人脸表情识别方法实验。两种方法实验结果表明:FELW数据集的识别率比FELW-原、FELW-1数据集识别率高,同时体现了Kappa一致性检验对数据集的作用;采用正脸+Part_Label+软标签的形式的实验识别率效果最好;采用深度学习的人脸表情识别方法时,使用LRN的模型2比没有使用LRN的模型3识别率高,同样体现了LRN的作用。由于FELW数据集图像是未经过图像配准的归一化操作,而且图像不是在实验室采集而是在网络上采集的自然场景下的各种类型图片,图像的质量远远比不上现在成熟的人脸表情数据集图像质量,但是在传统方法和深度学习方法的识别率达到了70%以上的效果,后续还可以继续改进数据集以达到更好的识别率。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
动漫星空(2018年9期)2018-10-26
车迷(2018年11期)2018-08-30
中国交通信息化(2018年3期)2018-06-13
海峡姐妹(2018年3期)2018-05-09
中国交通信息化(2016年2期)2016-06-06
Coco薇(2015年11期)2015-11-09
