
一种基于超级基站的故障检测机制*
2019-02-26 00:59
广东通信技术 2019年1期
1 引言
近年来,随着移动通信技术的快速发展,出现了在线语音、视频、实时手游、手机购物等业务,使得基站业务数据流量指数增长。传统蜂窝移动通信系统在未来无法满足业务和能耗上的要求,中科院计算技术研究所提出了超级基站的概念。
超级基站[1-3]是一种物理集中、逻辑分布的多模异构新型接入网平台,支持资源水平共享、统计复用。超级基站通过统一和开放接口在集中式大规模资源池中按需创建大量虚拟基站,多个虚拟基站共享资源池中的资源,资源池中某部分资源出现问题,可能导致与之关联的多个基站故障,从而影响大范围接入用户业务,严重的话会造成整个网络崩溃。因此,超级基站平台要求一个更加安全、可靠网络环境以及一个更加高效的故障检测机制。
然而集中式接入网的设备复杂性越来越高,业务种类的增多,使得超级基站的数据规模呈爆发式的增长,其故障检测效率越来越低,故障管理变得越来越困难。目前,领域内出现了一些故障检测方法,文献[4]提出一种探针机制,周期性的向网络发送探测数据,判断网络的状态。此方式需要不断的向网络中发送探测包,这会给本来数据量就十分庞大的超级基站增加难以估计的开销,降低故障管理效率。文献[5]提出利用数据挖掘技术对故障数据进行训练,生成一套规则用于故障检测。此方法学习能力强,但是需要训练故障样本,并且故障样本越大,训练出来的规则可靠性越高,而对于大多数设备而言,一次获得大量故障样本比较困难。文献[6]提出了一种否定选择算法,此方法实现简单,只需要训练正常的数据就可检测出异常,但是异常并不一定是故障。而文献[7]提出的专家系统,存储了大量领域相关的知识给系统决策提供依据。于是,本文结合否定选择算法和专家系统,给超级基站设计了一个综合的故障检测机制—NEFDM(Negative selection algorithm and Expert system Fault Detection Mechanism)。基于两种方式的结合,所提出的NEFDM应用在超级基站上可有效提升故障检测率,使得故障管理变得简单并能提升网络的自适应能力。NEFDM分为两步:1、异常检测:采用人工免疫系统的否定选择算法生成超级基站异常检测器,进行超级基站的异常检测,发现系统的异常情况。2、故障判定:对步骤1中检测出的异常进行故障判定。基于超级基站专家系统规则库对异常状况进行筛选,如果该异常是已知的并且造成了故障,采用专家规则库的方法解决;如果是未知异常状况,则通知系统故障管理模块进行故障定位,并将解决后的方案扩充到专家系统。
2 技术介绍
2.1 否定选择算法
否定选择算法属于人工免疫领域一种常用算法,又称阴性选择算法,由美国学者Forrest等在研究免疫系统时提出并成功应用于计算机安全领域。其原理借鉴了免疫细胞成熟时的“否定选择”过程,通过学习“自体”数据训练出的异常检测器并用于检测“非己”情况,其中“自体”数据指正常数据,“非己”指异常状况,该算法包括离线训练阶段和在线检测检测[8]两个阶段。
2.1.1 离线训练阶段
离线训练阶段的目的是生成异常检测器,用于异常检测,如下图1。
生成的成熟异常检测器集合用于下一阶的异常检测。
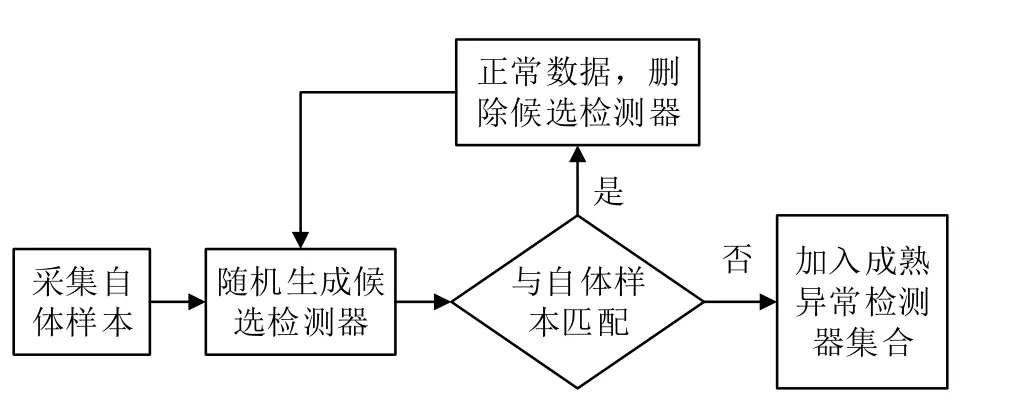
图1 离线训练阶段流程图
2.1.2 在线检测阶段
异常检测阶段是将成熟的异常检测器集合与待测数据中匹配,筛选出异常数据,如下图2。
2.2 专家系统
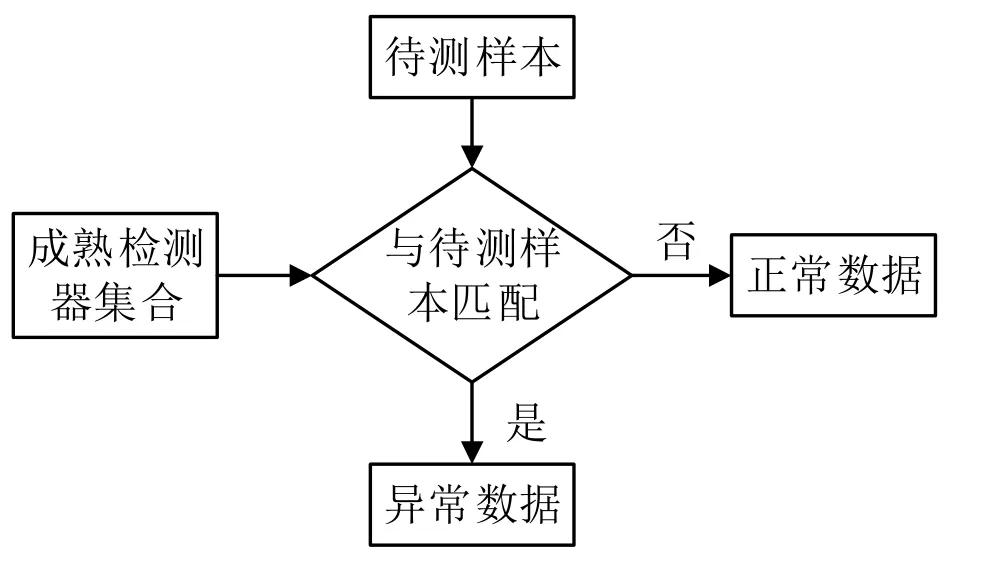
图2 异常检测阶段流程图
专家系统主要由知识库、推理机、人机交互接口等组件构成,如下图3。
知识库存储了大量的专业知识和经验。在构建知识库时,知识的表达是一个核心问题。知识表达的要求不仅适用于人类的自然表达,而且易于翻译成机器易于使用的格式。专家系统中规则知识的表达形式一般为:
IF<条件>或者<前提>,THEN<结论>或者<操作>,SOLUTION<方法>。
如果前提成立,则结论成立,解决方法如下。中间使用AND、OR等连接符。连接符之间是规则元,是告警信息、故障类型、解决方法等参数的详细描述。
推理机是专家系统的组织控制机构,它根据输入信息,运知识库中的知识,参考一定的策略进行推理,完成故障判定。
人机接口是专家系统和用户之间进行信息交互的媒介,通过定制的接口,可以方便地添加、删除和修改专家知识,浏览各种对象和属性,赋予初始值,调整对象的相对关系,从而高效地建立、扩展和维护专家系统的知识库。
3 NEFDM的设计
3.1 总体思路
NEFDM分为异常检测和故障判定两个步骤,如下图4。首先对基站的正常运行数据进行训练,生成异常检测器集合,接着使用异常检测器进行异常检测,如果检测到了异常,然后由专家系统进行筛选,若为已知的异常,及时通知故障管理系统参考知识库进行故障修复;如果检测到了无法分析的异常,通知故障管理系统进行故障定位,并将解决后的故障知识添加到专家系统。
接着介绍异常检测与故障判定在超级基站的具体设计。
3.2 异常检测
超级基站的异常检测将进行3个阶段工作:数据预处理、异常检测器生成、异常检测器检测。
3.2.1 数据预处理
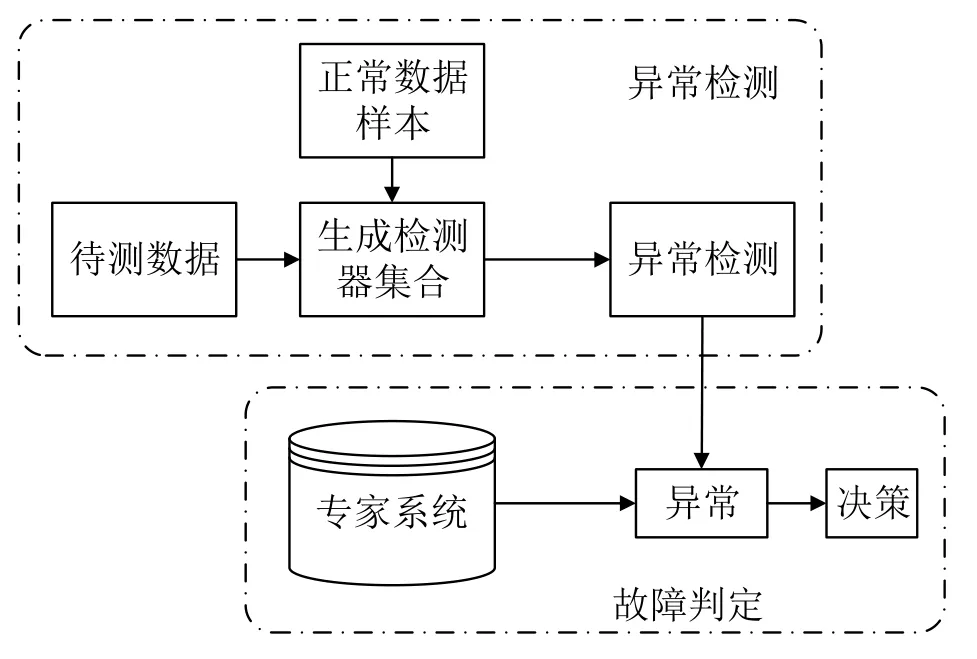
图4 超级基站故障检测
超级基站的有关性能运行参数有小区负载、丢包率、切换成功率、小区干扰门限等,有关设备的运行参数有内存利用率,温度、电压等等,这些参数均不是一个量纲级别,在异常检测前需要将参数归一化为同一量纲的数据,文献[9]提出将不同种类的数据归一化为实值向量序列,归一化的公式(3-1)给出,生成的异常检测器也是由实值向量序列表示。如下图表1,从超级基站取5个正常运行参数然后归一化成0-1区间内的实值,2个实值向量之间的距离表示二者之间的亲和度,亲和度越小就越匹配。例如向量x=[0.2, 0.3, 0.3, 0.1, 0.4]表示待测数据,同时向量y=[0.1, 0.4, 0.5, 0.2, 0.3]表示检测器,当两个向量之间的距离小于某个阈值时,就表示样本与检测器匹配。此例中向量x与向量y之间的亲和度用欧式(Euclidean)距离(3-2)计算。

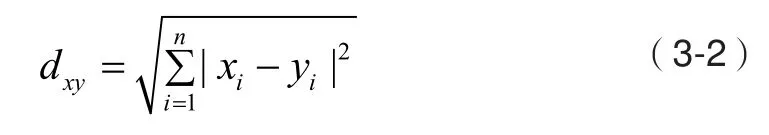
3.2.2 生成异常检测器
超级基站历史数据库中取出足够的正常运行参数,归一化处理为实值向量集合,我们称为自体样本。自体样本亲和半径为,若待测点与自体样本的最小距离大于,则待测点属于异常数据;反之,待测点属于正常数据。异常检测器的生成过程就是一种否定选择过程:随机生成检测器序列,比较检测器与自体样本的最小距离由公式(3-2)计算,若,该检测器被否定;若,该检测器可作为候选检测器,对应的检测半径为。已有的异常检测器的检测半径集合为为异常检测器的编号,为了减小检测器之间的重合率,需要判断L与所有的大小,若存在,则将丢弃候选检测器;若不存在,则将候选检测器加入到成熟检测器集合;下图5为异常检测器生成阶段的流程图。
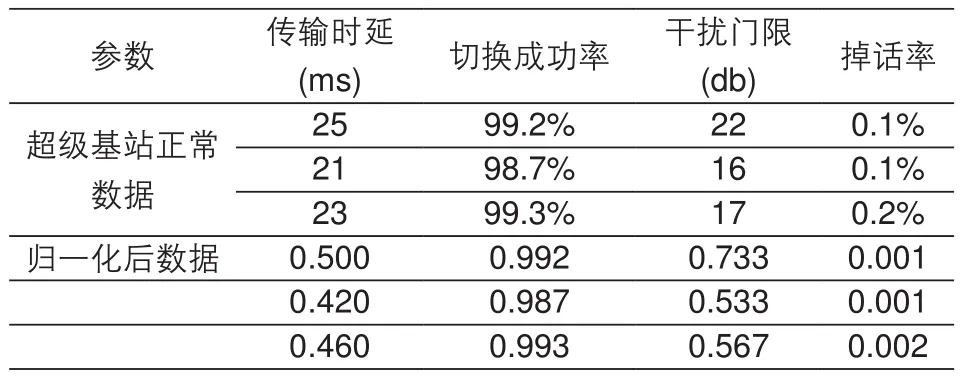
表1 超级基站自体样本案例
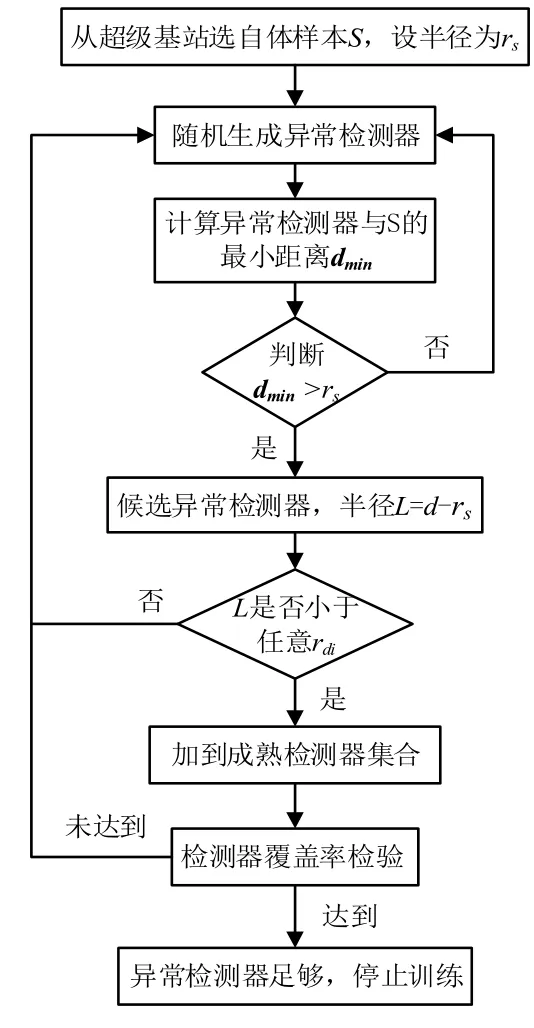
图5 异常检测器生成
生成检测器集的停止条件是检测器达到预定覆盖率的值。文献[10]提出使用样本估计是否达到了覆盖率,进行样本估计的时候暂时停止生成检测器。选取n个测试样本,设x为测试样本被检测器覆盖的数量,如公式(3-3),为估计的覆盖率。

p为预定覆盖率,σ为标准差,根据中心极限定理,当测试样本n足够大时,测试样本估计的覆盖率的误差z值可近似认为服从标准正态分布,由式(3-4)表示。
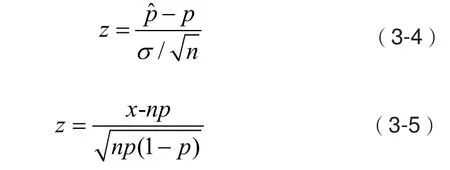
根据(3-3)和(3-4)可推出(3-5)。然而估计存在误差,文献[11]给出,当时,可认为已达到覆盖率,停止训练;当时,没有达到预定的覆盖率范围,继续产生检测器。其中α为显著水平,α越小,说明达到预定覆盖率的结果越准确,通常显著水平选为α=0.05,则置信水平为1-α=0.95,为此置信水平对应的值,可以通过查表得出。下图6为检测器覆盖率检验流程图。
超级基站异常检测器生成步骤如下:
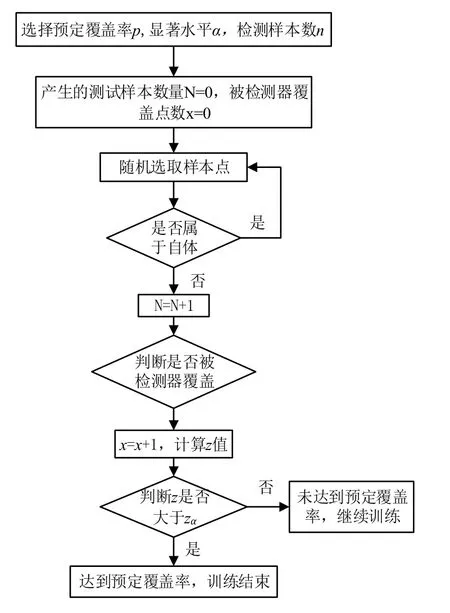
图6 检测器覆盖率检验
(1)选取3.2.1节归一化的实值自体样本,设置自体样本半径。
(5)接着判断成熟的检测器是否足够(如图6),此时停止生成检测器。
(6)选择显著性水平α,预定覆盖率p,需要检测的样本数为n。
(7)随机生成测试点,判断测试点是否属于自体,若属于则重新生成测试点;若不属于,统计生成的测试点数;
(8)接着判断测试点是否被覆盖,即判断测试点与检测器集合的距离L,若L大于,则该测试点未被覆盖;若L小于等于,则给测试点被覆盖,。
3.2.3 异常检测器检测
接下来,将上一小节生成的成熟检测器集合用于超级基站的异常检测,步骤如下:
(1)从超级基站操作维护中心选取待测数据,根据3.2.1节进行数据预处理。
(4)判断是否是最后一个检测器,若不是,返回(2)接着去下一个异常检测器,直到取完为止;若是,超级基站此时没有异常,接着监督下一个状态,返回(1)。
3.3 故障判定
异常检测器检测出了异常,接着进行故障判定。故障判定前需要先建立专家系统。
3.3.1 建立专家系统
首先获取知识库。知识获取来源:(1)通常是通信设备厂商或者移动通信协议制定者提出的通用标准、指标。(2)超级基站运维专家结合前几代产品的实际故障案例归纳总结出的知识。(3)超级基站故障检测机制挖掘出来的潜在知识,也就是此次检测之前收集的新知识。
接着是知识的表达。比如说掉话率偏高或小区切换失败,原因是切换参数设置不合理造成的,解决方法有调整切换门限、时延、天线倾斜角等等。超级基站专家知识库按如下形式表达。

然后设计推理机,设计成2个步骤:
(1)模型匹配:将当前检测出的异常情况与规则库进行条件匹配。如果完全匹配或大致匹配,则触发步骤(2)。
(2)竞争解决:从解决策略中依次选择最符合条件的方法,提供给管理端。
最后设计人机交互接口,做成可调用的API形式,进行推理机和知识库的数据均通过此API实现。
超级基站的专家系统只需建立一次,以后每次都是对专家知识库的扩充,给下一次的故障判定提供参考依据。
3.3.2 故障判定
专家系统建立完成后接着进行故障判定,如下图7,步骤如下:
(1)异常检测器检测出异常,启动专家系统;
(2)找到异常情况的原始数据,通过人机交互接口进入推理机实行模型匹配,若匹配成功,说明超级基站的异常是已知的,触发竞争解决机制,选择最合适的解决方法;若匹配失败,说明检测出了未知异常,上报故障定位模块进行故障定位。
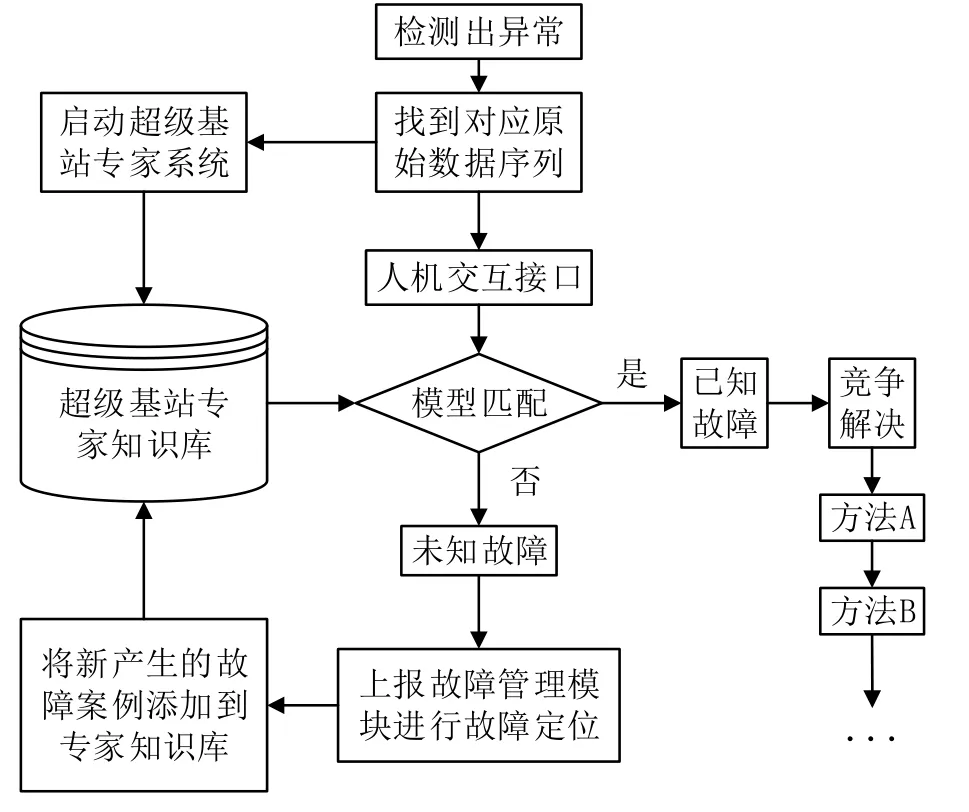
图7 超级基站故障判定
(3)将已解决的故障案例以指定的格式添加到超级基站专家知识库,供下一次的故障检测使用。
4 结束语
本文给超级基站设计的采用否定选择算法和专家系统相结合的故障检测机制(NEDFM)能给超级基站带来如下好处:
(1)NEDFM能及时发现超级基站潜在的异常状况,并上报给故障管理系统,能从整体减小故障发生的概率、提升故障管理的效率,进而增强网络的可靠性和稳定性。
(2)否定选择算法在进行异常检测模型训练时只需提供正常运行参数样本,而不需提供大量的故障样本,实现较为容易。
(3)NEFDM结合了专家系统,每次新发现的异常案例能被专家系统收录,当下次再发生相同的异常能及时处理,提高了系统的自动化程度。
猜你喜欢
水泥工程(2022年2期)2022-08-22
军民两用技术与产品(2022年1期)2022-06-01
上海大学学报(自然科学版)(2020年4期)2020-05-24
制造技术与机床(2019年6期)2019-06-25
火力与指挥控制(2018年10期)2018-11-13
中国交通信息化(2017年9期)2017-06-06
电子制作(2017年10期)2017-04-18
中国交通信息化(2016年9期)2016-06-06
工业设计(2016年11期)2016-04-16
图书馆研究(2015年5期)2015-12-07
