
基于FFmpeg与CUDA的YUV与RGB色彩空间转换性能对比分析
2019-02-26 00:59
广东通信技术 2019年1期
1 引言
随着互联网技术和多媒体技术的快速发展,多媒体数据的传输和获取变得越来越便利,人们对高清晰度视频图像画面的需求日益增长。近年来,视频图像的分辨率经历了从720P到1080P再到4K的发展,4K技术逐渐进入到人们的生活。4K让人们体验到极致的视觉感受的同时给硬件及软件也带来了更高的挑战,这其中就包括图像显示过程中涉及的色彩空间转换的问题。YUV与RGB是最常见的两种色彩空间模型[1],两者之间的相互转换在数字多媒体领域尤为重要。众所周知,4K分辨率为,长宽比为16:9,标准4K分辨率的像素总数可达800万,为全高清1080P(1920×1080)的4倍,是720P(1280×720)的8倍。如何高效地对高分辨率视频图像进行色彩空间转换,受到了该领域研究者们的广泛关注。
目前,业界主要使用FFmpeg工具进行音视频的开发。FFmpeg是一款开源、免费、跨平台且功能强大的音视频处理工具,其主要利用CPU进行音视频数据处理,然而当数据量非常庞大时,CPU在大规模矩阵类型的数值计算上就显得力不从心[2]。因此,近些年GPU的迅猛发展弥补了CPU在这方面的不足。GPU可以用大量的并行线程对大规模矩阵类型数值进行并行计算,其和CPU并行工作可以极大的提高音视频处理的效率。为了测试色彩空间转换在GPU上的工作性能,本文分别基于FFmpeg和CUDA对YUV与RGB色彩空间的转换性能进行了对比,实验结果表明基于CUDA的色彩空间转换由于利用了大量的GPU并行加速有着更好的性能表现。
2 色彩空间模型
2.1 RGB色彩空间模型
常用的色彩空间模型有RGB、YUV/YCrCb、CMYK、HSV等[3]。RGB是计算机视觉系统中最常见的色彩空间模型,图1中的立方体形象的表示了RGB色彩空间。3个坐标轴分别对应了红(Red)、绿(Green)、蓝(Blue)3个颜色分量。原点对应黑色,距离原点最远的顶点即为白色。黑色原点与白色顶点之间的连线为灰度线。在计算机中,RGB色彩空间的存储方式有多种,最常见的是R、G、B每个分量采用8比特即一个字节进行表示,因此每个像素占用3个字节的内存空间,每个分量的颜色强度为0~255。RGB色彩空间总共能表示约1678万种色彩,通常也称为1600万色或24位色。
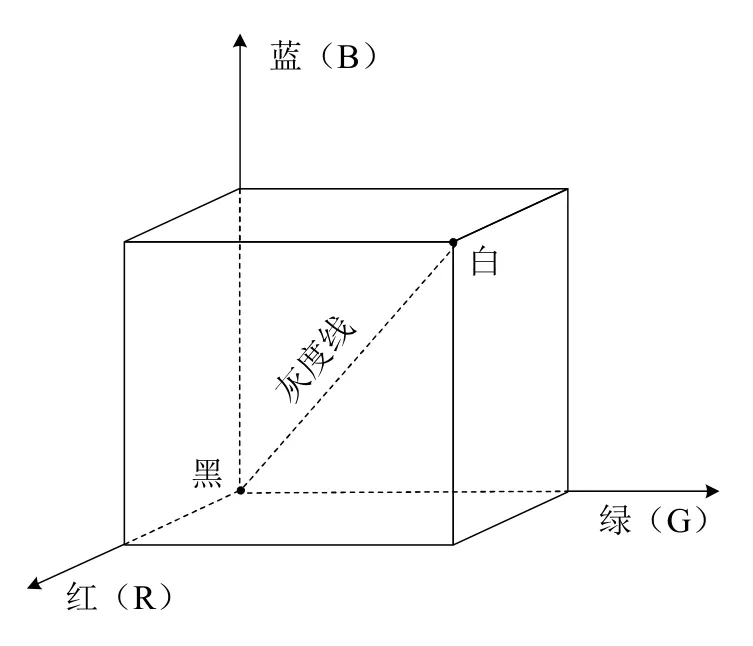
图1 RGB色彩空间模型
2.2 YUV色彩空间模型
人眼对亮度和色彩的感知程度不同,其对色彩细节的分辨能力比对亮度细节的分辨能力低,根据这一视觉特性产生了YUV、YCbCr、YIQ等色彩空间。YUV是一种基本的色彩空间,其他的色彩空间均是从YUV衍生而来。YUV色彩空间中的Y分量指图像的亮度成分,显示的是灰度图像,U和V分量为色度成分,描述的是色彩和饱和度。
YUV色彩空间有多种采样格式,如4:4:4,4:,2:2,4:2:0,4:1:1。4:2:0格式是比较常用的,它的含义是对Y分量进行全采样,对U和V分量在水平和垂直方向上采样率均为在Y分量上的一半。4:2:0格式的YUV通常是平面存储格式,其一般是先全部存储Y分量,然后U和V的分量依次存储。YUV被广泛的应用于视频会议、数字电视和DVD存储中,本文主要采用YUV420格式进行试验对比。
3 YUV转RGB色彩空间性能对比
3.1 FFmpeg简介
FFmpeg是一个集录制,转换,音、视频频编解码功能为一体的完整的开源免费解决方案,它包含了非常先进的音频/视频编解码库libavcodec和用于视频场景比例缩放、色彩空间转换的libswscale库[4]。FFmpeg项目的部分组成如表1所示。

表1 FFmpeg项目部分组成成员
FFmpeg采用的是主程序+核心库的编程模式,核心库隐藏了内部各种具体格式的实现,对外提供统一的调用方法,这样主程序就不用去关注如何调用与具体格式相关的函数。本文采用libswscale库的sws_scale函数实现对视频图像的格式转换以作对比。
3.2 CUDA简介
基于FFmpeg的色彩空间转换完全依赖于CPU的计算,而CPU是一个负责执行复杂逻辑处理和事务管理的单元,它并不擅长大规模矩阵类型的数值计算,而GPU恰恰相反,它可以用大量的并行线程进行处理,可以很好地弥补CPU的不足。2003年NVIDIA公司推出了CUDA架构,为GPU通用计算提供了良好的软硬件开发环境。CUDA可以看做是专为NVIDIA GPU设计的C语言开发环境,有着丰富的套件,让开发人员可以更加专注于自己所开发的应用[5]。
在CUDA程序中,能被GPU执行的部分称作内核(Kernel),整个内核由成千上万条简单的线程组成,并交由GPU处理,无法并行化的部分交由CPU完成。为了提高线程之间的相互协作能力同时节省显存带宽,CUDA将线程分成了线程(thread)、线程块(block)和线程网格(grid)三个层次结构,图2展示了三者之间的结构关系。在同一block里面的线程可以共享内存数据[6]。

图2 线程、线程块、线程网格之间的关系
3.3 基于FFmpeg和CUDA的YUV转RGB性能对比
YUV色彩空间与RGB色彩空间之间的转化公式如下:

本文利用CUDA进行色彩空间转换的核心转换算法代码如下:


其中,maxlongth为图像的所有像素长度;color_space_conversion_mat数组表示色彩空间转换矩阵;blockIdx.x表示线程块的x索引值;blockDim.x表示线程块中线程的x维度值;threadIdx.x表示线程的x索引值。
为了更直观地看到两种方法在色彩空间转换上的效果,本文分别在不同分辨率下对转换时间以及转换后的主观视觉效果进行了对比。实验平台为64位CentOS7操作系统,Intel酷睿i5四核处理器,3.3 GHz主频,32G内存。显卡为Quadro P2000,5G显存。表2给出了实验对比结果,实验数据均为对十幅图像进行色彩空间转
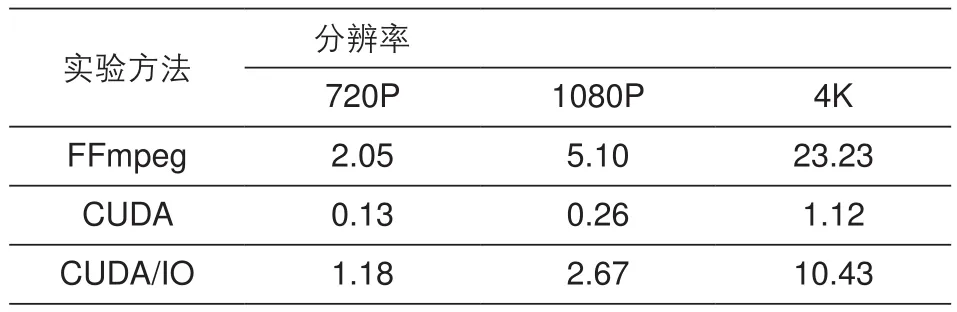
表2 两种方法在不同分辨率下的转换时间对比(ms)
换取均值。CUDA/IO表示加入了CPU与GPU内存数据交换的时间(内存数据交换的时间主要由总线接口(Bus interface)影响)。从表2可以看出,如果不算内存交换时间,CUDA平台下,720P、1080P、4K的转换时间只有0.13 ms、0.26 ms和1.12 ms,比FFmpeg高出十几倍,然而实际工程中内存交换地损耗是不可避免的,算入IO时间,转换时间则分别上升到了1.18 ms、2.67 ms、10.43 ms,比FFmpeg高出不到两倍,可想而知,内存交换极大的影响了色彩空间转换的效率。从数据中还可以分析出随着分辨率的增加CUDA平台下的转换效率有上升的趋势,从侧面说明了利用CUDA进行并行计算在越大的数据量下越有优势。
图3给出了两种方法在720P分辨率下的peppers图像和baboon图像上进行色彩空间转换后的主观视觉效果对比,从图中可以看出,基于FFmpeg和基于CUDA的两种方法对图像转换的主观视觉与原始图像基本一致。

图3 基于ffmpeg和CUDA的色彩空间转换主观视觉对比(a)peppers图像(b)baboon图像
4 总结
本文分别基于FFmepg和CUDA平台实现了对YUV到RGB色彩空间转换的仿真实验,通过实验数据的对比分析,可知利用GPU加速可以大幅提高数据处理的工作效率,然而CPU与GPU的内存交换损耗则成为了系统瓶颈的关键因素,因此,要想提高工作效率,一是要尽力避免频繁的内存交换;二是选择更有效的存储方式;三是使用CUDA内存优化技巧。无论如何,利用CUDA对大规模矩阵数据并行处理相较于CPU都有着一定的优势。如果总线接口传输带宽问题解决,那么世界将真正迎来计算时代新纪元。
猜你喜欢
山西电子技术(2021年3期)2021-06-28
汽车零部件(2021年4期)2021-04-29
网络安全技术与应用(2020年1期)2020-01-07
电脑报(2019年31期)2019-09-10
家庭影院技术(2019年7期)2019-08-27
当代陕西(2019年13期)2019-08-20
电子制作(2018年12期)2018-08-01
中国交通信息化(2017年2期)2017-06-06
环球市场(2017年36期)2017-03-09
电脑爱好者(2015年21期)2015-09-10
