
学术文本结构功能深度学习识别方法的多学科对比分析
2019-02-25 03:14李楠方丽张逸飞
现代情报 2019年12期
李楠 方丽 张逸飞


摘要:[目的/意义]学术文本的结构功能识别可视为多类别文本自动分类问题,借助深度学习技术能够获得良好的自动识别性能,然而目前缺少其在不同学科适用性的对比研究。[方法/过程]选择医学、图情、数据、出版、经济5个学科方向5种期刊的6 452篇结构式摘要为基础语料,设计并实现了基于Magpie深度学习组件的学术文本结构功能识别实验,通过对比分析同一分类模型在不同学科领域实验语料上的性能表现及其影响因素,揭示机器学习方法的学科适用性规律。[结果/结论]实验结果显示,学科差异性对于机器学习效果有显著的影响,其中医学领域学术文本的结构功能识别效率明显高于其他学科,常见的学术文本功能结构框架中“方法”和“结果”的机器学习识别效果更佳。
关键词:文本结构功能识别;深度学习;多学科;文本分类;Magpie
DOl: 10.3969/j .issn .1008 -0821 .2019 .12 .007
[中图分类号] G203 [文献标识码]A [文章编号]1008-0821( 2019) 12-0055-09
學术文本的结构功能是对学术文献的结构和章节功能的描述与概括[1],通常研究性论文的结构可以根据IMRaD模型的定义划分为“目的”、“方法”、“结果”和“结论”等部分[2],这种结构化的功能划分能够更加清晰地展示学术文献的语义构成,便于更细粒度的知识检索、挖掘与发现,因而在图书情报及信息科学领域,学术文本的结构功能识别成为学术文献知识挖掘的重要研究内容之一。而随着机器学习技术的兴起,基于传统的条件随机场(CRF)、支持向量机(SVM)等机器学习模型的自动识别方法获得了良好的实验性能,识别准确率可达到70% - 80%[ 1.3-4]。尤其是近年来,深度学习领域的技术突破使得自然语言处理能力得到极大提升,文本结构功能识别的效果获得了更深层次地优化,基于卷积神经网络(CNN)、长短期记忆网络( LSTM)等深度学习模型的最优识别效果可接近或超过90%[ 5-6]。
然而,在数据的复杂性和规模化效应的影响下,深度学习等机器学习方法的应用研究同样面临诸多值得深入探讨的现实问题,不同应用情境下机器学习方法的适用性问题就是其中之一。基于机器学习的文本结构功能识别问题本质上是基于文本的语法及语义特征实现的自动处理过程,因此,识别性能依赖机器学习模型对于文本特征的提取和训练学习效果。而学术文本不同于一般的开放域文本,学术研究的科学范式导致了学术文献在科学陈述逻辑、语言表达方式、语义结构功能等方面具有规律性的同时也存在一定差异,从而使得学术文本具有鲜明的学科特征。机器学习模型能否实现对特定应用情境下文本语法及语义特征的提取则直接影响着实际的应用效果。目前,大多数研究主要集中于各类机器学习模型的运行性能与应用效果[7-8],却少有学者从学科差异的视角探讨学术语境下机器学习方法的适用性。针对上述情况,本文选取不同学科、具有不同语义结构的学术文本建立深度学习实验环境,通过对实验结果的对比分析,评估机器学习模型在不同学科的运行表现。本研究不仅为验证深度学习模型在语义结构功能识别应用上的性能状况提供第一手的实证资料,而且为深度学习方法在不同学科背景下的应用提供有价值的参考建议。
1 文本结构功能识别相关研究
学术文本的内容结构具有一定的规律性,语句、段落或章节等不同的结构单元承担相应的语义功能,例如:特定语句陈述研究的目的或意义,特定段落描述研究方法,特定章节给出实验结果等。因而,学术文本的结构功能识别问题从机器学习的视角可视为一种文本自动分类任务,即在学术文献的结构框架下,对句子、段落或章节等不同层次的文本单元进行语义功能的分类预测,实现结构功能语义标签的自动标注。目前相关研究根据结构框架的不同主要分为两类:
一是对标题、摘要、章节、图表、公式等逻辑结构层次的自动识别,结构功能识别的主要对象是学术文本内容中包含的显性知识单元。例如LuongMT等采用条件随机场(CRF)方法实现文献中标题、作者、摘要、图表等逻辑结构的识别[9],Tu-arob S等则是采用支持向量机(SVM)和朴素贝叶斯(NBC)模型对学术文献的章节边界进行划分[10],Constantin A等提出了一种解析PDF文档结构的技术方案,实现了从PDF格式的学术文献中获取逻辑机构并实现XML规范化描述的工具,实现了对标题、作者、参考文献等结构的识别[11]。而国内相关研究也取得了进展,黄永等同样以支持向量机为分类器引入词汇聚类特征实现章节结构的识别[4]。
二是对文本内容的功能性结构层次的自动识别,例如IMRaD模型定义的“四项式”功能结构,并不一定与文本的语句、段落或章节等逻辑结构逐一对应,对学术文本中的语句、段落或章节等不同层次的单元根据不同的文本功能结构进行分类标识,是近年来研究的重点,也是本文关注的研究内容。目前,常用的学术文本功能结构框架除了广泛采用的IMRaD模型,还有根据特定领域的学科特点或论文体裁需求而定义的不同结构模型,比如早期临床类论文采用的“八项式”结构,包含目的、设计、研究单位、研究对象、处理方法、测定、主要结果和结论等要素,后经改进后称为Haynes -Huth结构[12];根据循证医学的临床指南,生物医学领域通常遵循PICO“四项式”结构,包含研究样本、临床干预、对照、干预的影响或结果,以便明确体现临床医学涉及的主要信息内容[13];在社会科学领域也有采用背景、目的、方法、结果、结论和评述等“六项式”结构;针对综述型论文提出的包括目的、资料来源、研究选择、资料提取、资料综合、结论等的“六项式”结构。上述功能结构框架已在不同领域文献的结构式摘要中得到采用,而在文本结构功能识别研究中,功能结构框架仍然以IMRaD为主。
在实现方法上,除了传统的CRF、SVM分类模型以及多种分类模型的融合改进以外,近年来深度学习模型的应用逐渐深入,以卷积神经网络( CNN)、递归神经网络(RNN)为代表的深度学习模型,以及在此基础上创新的长短期记忆网络( LSTM)、LSTM - CRF、CNN -CRF等模型层出不穷,学者们围绕不同分类模型在文本结构功能识别中的应用展开研究。笔者从调研文献中选取了近年来发表的5种代表性方法,对其研究对象、功能结构、分类模型等进行了对比,如表1所示,现有研究主要从机器学习方法有效性的视角更多地关注不同分类模型(分类器)在单一数据集上的实验性能,包括不同分类模型的整体和单类别识别性能、方法的执行效率、分类参数的最优设置等。其中,前3项研究采用传统的机器学习模型,后两项则采用深度学习模型,性能对比结果显示深度学习模型的实验性能整体高于传统模型,但由于现有研究针对不同学科领域的学术文本展开,样本的语种、规模、学科领域、功能结构都存在差异,因此无法直接对比分析其性能差异的影响因素。基于上述分析,本文重点关注特定分类模型在不同实验条件下的性能表现,以探索机器学习模型实际应用性能的深层规律。
2 基于深度学习的学术文本语义结构功能识别实验
2.1 数据准备
结构式摘要是近年来在部分学科领域推广使用的摘要撰写方式,倡导作者根据研究要素构成提供结构化的简要内容陈述,据统计ESI高被引期刊中提供结构式摘要的期刊总体占比14.4%,而生物医学领域采用结构式摘要的期刊占比达到29.2%[15]。尽管结构式摘要并未覆盖所有学科领域,但这种自带功能结构标签的摘要文本,对于开展有监督机器学习提供了极大的便利,因而成为众多学者选择的理想实验语料。
为了保证语料的选取满足多学科对比研究的实验需求,笔者通过对中国知网( CNKI)收录期刊的摘要文本结构化程度、摘要语义结构、所属学科分类、文献量等方面进行调研,从5个不同的学科分支分别选择一种代表性期刊,以5种期刊上提供结构式摘要的刊载论文摘要文本作为实验数据。其中,医药、卫生類选取了国内最早引进结构式摘要并构建了生物医学领域“四项式”摘要结构化模型的《新乡医学院学报》[16],传统的图情类期刊《图书情报工作》和《数据分析与知识发现》则根据其发文所属的中图分类分布,将两个期刊分别作为图书馆学、图书馆事业类( G25)和信息处理、信息加工类( TP391)的代表期刊,而针对目前提供结构式摘要的经济类期刊较少的情况,选择了同时被CSSCI和北大核心期刊收录的《数量经济技术经济研究》作为经济类实验语料。实验数据集详情如表2所示。
考虑到实验数据规模平衡性,除《新乡医学院学报》只选取了10年数据外,其他期刊数据的起始年份均是从提供结构式摘要的卷期年份开始截止至检索日期(2019年6月)。然后,对获取的文本数据进行预处理,包括过滤非研究论文数据、对摘要文本进行语句切分等,经过预处理共获得符合要求的学术文本摘要6 452篇,带语义标签的学术文本语句32 160条记录,数据的训练测试比为9:1(摘要文本语料示例见图1)。
2.2 工具选取与实验步骤
实验采用开源深度学习组件Magpie[17]作为基础工具实现学术期刊摘要文本的功能结构识别实验,解决多学科不同期刊不同功能结构框架下的多类别分类问题( Multi-class Classification)。Magpie最初用于实现高等物理领域文献摘要的主题分类标引,后被改进并封装后成为一种实现大规模训练语料基础上的文本分类通用工具。目前,Magpie采用的基础模型参考了先后由Kim y[18]和Berger MJ[19]提出的基于CNN的文本分类模型。封装后的Magpie在Word2Vec实现的词向量化基础上,通过SciKit Leam进行数据集的标准化处理,然后利用Keras神经网络API实现深度学习完成分类任务,基本原理如图2所示。
为科学全面地评估机器学习方法的适用性,实验根据5种期刊所属的中图分类(见2.1节表2)将样本语料分为5组,下文简称“医学”、“图情”、“数据”、“出版”、“经济”,从学科差别、功能结构、样本规模等多种角度,观察5组数据的分类性能差异,分析机器学习的影响因素及变化规律。具体步骤如下:首先,将实验数据通过分词处理后利用Word2Vec算法构建各独立语句文本的词向量( Word_Vector);然后,在对数据进行标准化处理( Scaler)后调用Mapgie组件开展机器学习;最后,生成相应的机器学习模型( Model. h5),并应用于测试语料的自动分类。部分示例代码如下:
magpie= Magpie(
keras_model='../magpie_result/20_0.1 _li/mod-e1.h5 '.
word2vec_ model='../magpie _result/20 _0.1 _li/embeddings ',
scaler='../magpie_result/20_0. l_li/scaler ',
labels=[' purpose',' method',' result',' limita-tion ', 'application',valuation])
#调用Magpie机器学习模型及语义标注集
for index in df_test_data.index:
test—sentence= df—test—data. loc[ index,”sen-tence”]
test_sentence= jieba. cut( test _sentence, cut_all=False.HMM =True)
test—sentence=””.join( test_sentence)
#测试语句切分及预处理
temp= magpie.predict_from_text( test_sentence)
#应用Magpie进行分类预测
2.3 性能评价方法
目前对于文本分类实验的测评主要有如下指标:精确率( Precision)、召回率(Recall)以及调和均值( F-Score),可以单独评价不同分类的局部预测性能,并通过均值计算表达整体性能。为方便对比分析,本实验对混淆矩阵进行了P、R和F值列的扩展。具体混淆矩阵及其计算公式如下:
其中混淆矩阵中Ci表示分类,行代表真实值即摘要文本中自带的分类标签,列代表预测值即机器学习的分类预测结果,矩阵元素Xij表示真实值为Ci的文本被预测为Cj的类别数,各分类的准确率Pi根据预测值对应的列元素进行计算,召回率Ri根据真实值对应的行元素进行计算,整体准确率和召回率根据均值计算。计算公式如下:
3 实验结果分析
3.1 不同学科的文本结构功能识别效果初步分析
实验选择Python3.6开发环境并调用Mag-piel.0,设置训练语料中10%的数据作为机器学习效果的测试数据(即Test_ratio=0.1),文本的词向量维度设置为300(即vec_dim= 300),学习迭代次数设置为20(即Epochs= 20)。对5个学科的语句级文本数据进行标注实验结果如下:
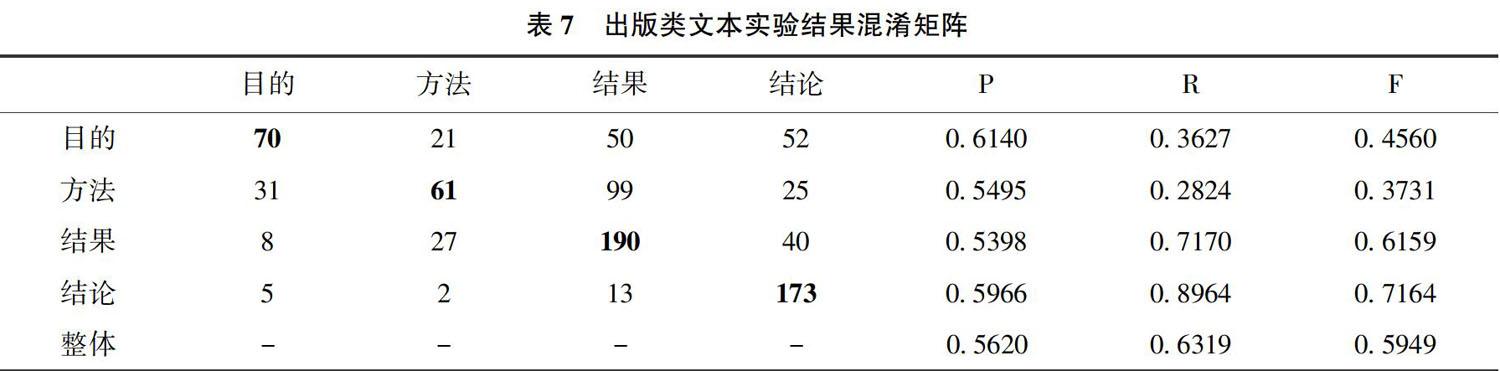
通过上述同参数对比实验可以发现:医学类文献摘要文本的语义结构功能自动识别效果最优,其次是图情和经济类摘要文本,识别效果较差的为数据类和出版类摘要文本。其中,医学类文本较其他4个学科的语义结构识别正确率有明显优势。结合表5-7的混淆矩阵显示,医学类表征分类器整体性能的F值分布在0. 8619 -0.9105之间,各分类的性能表现都接近或优于90%;而在其他学科,比如图情和出版类文本上整体F值分别仅有0. 683和0. 5949,表明相同的分类模型在不同学科文本中性能差异明显。
究其原因,医学类文本在语言形式表达上具有明显的规律性,使得各分类都有显著的排他性特征。例如,对医学类文本的句式进行归纳总结可以发现其句式具有特定规律,以“目的”类样本为例,491条分类正确的样本中,以“探讨/探寻/探索…” (286条)、 “了解/考察/观察…” (106条)、“研究…”(37条)、“分析/比较…”(32条)、“评价/总结…”(19条)为代表句型,共计480条,占该分类样本总数的98%。而在其他4个学科,这种句式表达的规律性相对不显著。
除了句式特征,只出现在某一类样本中的高频词往往在分类等机器处理的过程中作为基本特征具有很高的区分度,将这种具有高区分度的高频词(常为学科术语)其称为类别的专有高频词,据此对实验文本进行高频词分析,统计结果同样呈现出规律性。如表8所示医学和图情类语料专有高频词数量分布相对突出,医学词频高于60的43个高频词中专有高频词有29个,占比67%,词频高于50的高频词集合中专有高頻词占比甚至达到75%,相较而言图情类文本表现稍弱,词频高于50的高频词集合中专有高频词占比最高,达到67.6%;而出版、数据和经济类语料整体上高频词相对较少,词频超过20的高频词分别仅有32、29、10个,专有高频词数量极少。而从词频均值来看,医学类表现强势,高频词的词频均值远超其他类别,尽管出版类语料的词频均值也出现了40以上的较高数值,但高频词数量的限制使得出版类语料的文本特征区分度仍然较弱。从专有高频词与词频均值的分析结果来看,其特征规律也与实验结果保持一致。虽然除医学和图情类外其他3类语料识别效果偏低的情况,一定程度上可能受这3类语料的样本规模的影响,但笔者认为其数据统计结果呈现的规律一定程度上也反映出学科本身的术语专指度水平也是机器学习效果学科差异化产生的实质影响因素。
3.2 不同结构框架下学术文本结构功能识别效果深度分析
为了进一步探究学科文本特征差异产生的原因,实验对不同功能结构框架下各分类的识别性能分别进行了对比分析。在5组样本数据中,医学和出版两类文本的功能结构完全相同,但其他3类文本也都包含了目的(研究目标)、方法(过程/方法、研究方法)、结果(研究发现)等常用功能结构,根据期刊实际要求而略有不同。而对照不同功能结构的实验结果可以发现在各个学科不同分类之间的识别性能各异,纵向比较并没有明显的共同规律。医学类整体准确率都在90%左右,尤其是“目的”和“结果”类的识别准确率高于90%,而出版和图情类文本的识别准确率最高值出现在“方法”类,经济和数据类的识别准确率最高值分别出现在“研究价值”和“局限”类。
而从横向比较来看,在“方法”和“结果”类的识别召回率上各个学科的表现趋势是基本一致的,医学类文本的“方法”类识别召回率达到全局最优的94.43%,经济类文本的“研究发现”类召回率达到91.89%,其他学科的“方法”或“结果”类召回率均为学科内最优,这一现象说明了这两类文本的机器学习特征分类辨识度较高,而体现在F值上也具有同样的规律。不同功能结构的分类可辨识度具有一定差异,对于机器学习的效果有一定程度的影响。
结合词频分析对各分类专有高频词进行单独统计也可以发现,在医学类文本中专有高频词的分布相对均衡,每个分类基本都有一定数量的专有高频词且词频相对较高,而在图情类文本中专有高频词分布逐步向“方法/过程”类倾斜,在出版类文本中排名前15位的专有高频词就只在“方法”类中出现了,这一分布特点进一步印证了不同功能结构分类的可辨识度差异的存在。综合实验结果证明在功能结构中“方法”和“结果”类事实描述的学术性内容具有更高的可辨识度,除了医学领域,其他学科的“目的”、“结论”等思辨性较强的阐述性内容则在机器学习过程中呈现较低的识别效果。
4 总结
本文创新性地从多学科对比分析的视角考量深度学习方法在学术文本结构功能识别中的应用效果,在相同分类模型的基础上对不同学科文本的整体识别效果、各分类的局部识别性能以及不同学科文本的统计特征等进行对比研究。从实验结果来看,深度学习模型在文本结构功能识别中的应用效果毫无疑问高于传统的机器学习模型,本文的实验数据并未进行过多的数据筛选及模型优化,获得的实验结果已经超过部分调研的相关研究成果,再次证明了深度学习策略优于传统机器学习方法中的机器学习特征建模策略,依靠神经网络的迭代计算与自学习来实现对特征的提取与模型构建,在以自然语言处理为基础的研究中具有很好的适用性。更重要的是,实验研究的结果证明了学科差异性对学术文本结构功能识别效果的影响是不可忽视的,而学术文本的句式、高频词等规律性特征是出现这种学科差异性的重要原因。因此,在当前大数据研究不断深入,大量研究依靠数据规模化处理以提升机器学习效率的同时,我们应当充分考虑学科差异化带来的影响,不应该盲目构建跨学科大规模应用数据集合,而需要充分融人数据的学科特征,包括文本的语言表达特点、语义结构差异、学科术语专指度等,在形成合理的跨学科数据集成框架后再考虑多学科数据的融合与集成应用。由于本次实验选取的各学科样本规模并不均衡,部分学科样本量偏小,一定程度上会对实验结果的有效性产生一定影响,因此拟在后续研究中进一步扩大数据规模及学科覆盖面,一方面更深层次、更全面地衡量机器学习的性能和泛化能力,实现更准确地学科差异化的影响评估;另外一方面也可以从深度学习的技术视角,进一步探索在不同学科语境下深度学习方法在条件设置、参数选取等方面是否也具有学科差异化表现等一系列问题。
猜你喜欢
计算机应用(2016年12期)2017-01-13
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
