
C3S:基于相长干涉的智能传感系统并发传输策略研究
2019-02-25 01:27毛艳艳程大鹏冯烟利窦全胜李大社
通信学报 2019年1期
毛艳艳,程大鹏,冯烟利,窦全胜,李大社
(1.山东工商学院计算机科学与技术学院,山东 烟台 264005;2.中国石油大学(华东)地球科学与技术学院,山东 青岛 266580;3.山东省高等学校协同创新中心:未来智能计算,山东 烟台 264005;4.山东省高校智能信息处理重点实验室(山东工商学院),山东 烟台 264005)
1 引言
随着智能信息时代的到来,智能传感系统得到了前所未有的发展。智能传感系统是若干传感器节点通过实时感知、动态采集、分布传输和海量信息处理,为智慧城市、智能家居、环境监测、智能交通和工业4.0等领域而设计的分布式、智能网络信息系统。在智能传感系统中,受通信能力的限制,单个感知节点无法覆盖整个系统,往往需要通过构建大规模、分布式的通信网络传输实时感知数据,从而完成数据采集与分发[1-2]、智能诊断[3]、信息融合[4-5]等工作。
在智能传感系统中进行数据交换的主要性能指标包括节点功耗、传输延迟、分组接收率和信道吞吐量等。由于许多传感器节点是能量有限的,因此,如何利用智能算法充分延长整个网络的生存期是智能传感系统面临的一个挑战。目前,采用的主要方法有智能调节节点运算器和通信芯片的功耗[6]、设计节点能量消耗的智能均衡算法[7-8]、设计节点休眠调度算法[9-10]等。此外,为了防止感知数据失效,智能传感系统对实时性的要求较高。因此,智能传感系统要求在相同能量消耗的前提下尽可能地减少数据传输时延。目前的工作主要包括优化路由选择协议[11]、智能调整节点功率[12]等。而且,智能传感器节点大多工作在无线环境下,数据传输的可靠性受环境因素的影响较大。保障可靠性的解决方案包括减少多径效应和外部干扰对数据传输的影响、设计链路质量评估算法等[13]。最后,海量数据传输、智能网络重编程和快速数据分发都要求提高信道吞吐量。目前的方法有建立流水线机制[14]和优化数据传输模型[15]等方法。
最近,以相长干涉(CI, constructive interference)为代表的并发传输技术以其高可靠性、低时延和低功耗的优势成为智能传感系统中备受关注的数据传输方案。作为一种高效的智能传感系统并发传输技术,相长干涉可以实现毫秒级的数据传输时延,同时分组接收率达到99%以上。而且,以相长干涉为基础的网络洪泛、网络重编程、数据分发、故障诊断等服务通过码片级时钟同步有效延长网络生存期,并有效缓解节点能量消耗分布不均的问题。此外,并发传输技术可以减少节点数据传输过程中射频收发器的工作时间,从而降低占空比。然而,现有的相长干涉技术仍然缺乏一套完整的智能化并发传输策略。本文针对智能网络系统中的相长干涉并发传输技术进行研究,对分组接收率、能量消耗、吞吐量等技术指标进行优化,提出一种智能传感系统并发传输策略(C3S ,concurrent transmission strategy for intelligent sensing system)。

图1 C3S的逻辑关系
如图1所示,C3S分为以下3个层次:智能时钟同步层、智能能量分配层和智能并行流水线层。C3S在底层通过实现码片级时延度量和智能时钟校准算法,有效地提升了相长干涉并发传输机制的可靠性。同时为上层针对能耗和吞吐量的工作提供保障性支撑。在智能能量分配层,通过设计智能节点工作模式调度和自适应能量调度机制,对基于相长干涉的数据传输过程中传感器节点的能量消耗进行优化。在保障低功耗的前提下,C3S利用智能信道分配方法实现基于相长干涉的并行流水线,提高智能传感系统的吞吐量。与现有并发传输技术相比,C3S在智能化、可靠性、传输时延、功耗和数据传输效率等方面都有较大改进。
本文提出的C3S策略主要贡献如下。
1) 提出一种基于相长干涉的智能时钟校准算法(ICCA,CI-based intelligent clock calibration algorithm),通过分析相邻层次上的智能传感节点相长干涉时钟误差和多跳累积误差,对相长干涉并发传输进行智能补偿。
2) 提出稀疏网络拓扑下的相长干涉能量自适应调度方案(CIES, CI-based energy adaptive scheduling scheme),通过改进相长干涉并发传输时序,建立能量消耗模型,延长智能传感系统的生存期。
3) 提出基于相长干涉的并行流水线(CI2P,CI-based parallel pipeline),通过设计多信道分配方案,使传感器节点智能选取工作信道,最大化相长干涉并发传输的吞吐量。
4) 应用真实网络拓扑的实验结果表明,本文提出的 C3S策略可以有效提升智能传感系统的可靠性、网络生存期和吞吐量。
2 相关工作
作为一种并发传输技术,相长干涉指的是当来自2个(I1、I2)或多个节点的并发传输数据分组到达接收节点D的时间位移不超过0.5 μs时,接收节点D收到的数据分组信号强度大于任意节点单独向D发送数据分组时D接收的信号强度,如图2所示。
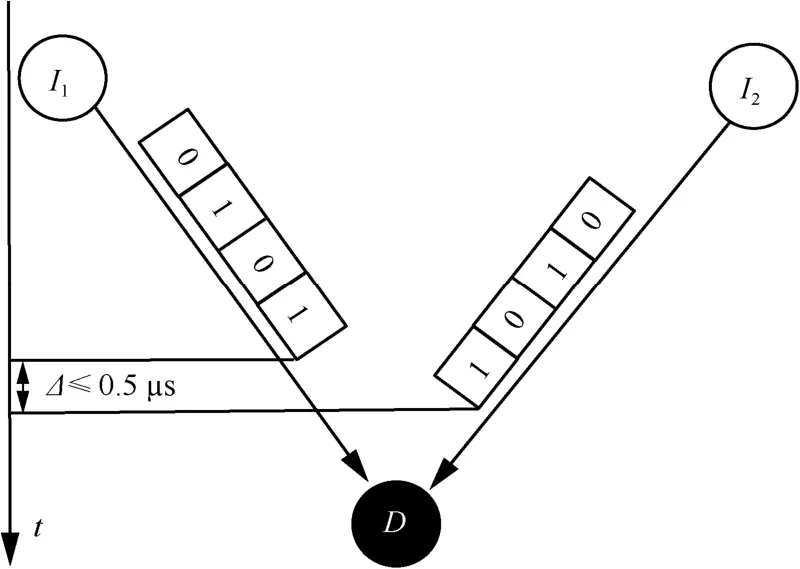
图2 相长干涉原理
相长干涉是文献[16]在解决 ACK广播风暴问题时发现的。此后,文献[17]利用相长干涉,首次在智能传感系统中实现了毫秒级时延的快速网络洪泛。Glossy的工作流程与拓扑无关,智能传感网中的所有节点都参与每个数据分组的转发。虽然可以实现99%的分组接收率和毫秒级的传输时延,但是传输过程中耗费了不必要的节点能量。而且,Glossy还存在可扩展性问题。文献[18]在Glossy的基础上搭建了相长干涉数据总线 LWB(low-power wireless bus),首次实现了任一节点间的相长干涉数据通信,并设计了节点相长干涉时隙的动态调整方案。但是,LWB并未对Glossy的底层传输流程进行优化,仍然存在能耗和扩展性的问题。此外,智能传感器系统中,节点转发流量的多样性会导致轮转周期不稳定,从而增大调度算法的收敛时间。文献[19]简化了LWB的工作流程,设计了一种时分复用的相长干涉数据采集协议Choco,首次通过控制数据分组来调整相长干涉数据传输的工作流程。然而,在多跳智能传感系统中产生的累积误差会增加分组丢失率。由于Choco在转发失败的情况下会重新分配时隙,直到数据分组被成功接收。所以,增加的重传次数会导致传输时延的上升,从而增大能量消耗。在吞吐量方面,文献[20]通过对相邻层次上节点信道的调度实现了基于相长干涉的流水线Splash。但是,Splash仍然采用拓扑无关的方法进行数据传送,在任意节点间的数据传输应用中,会产生不必要的能量消耗。同时,Splash每间隔一个传输轮次才向流水线输送一个数据分组,并未达到最优的数据传输效率。
最近的工作开始对相长干涉拓扑优化进行研究。文献[21]发现拓扑无关的相长干涉数据传输存在可扩展性问题。当智能传感系统传输路径中存在相互独立的子路径时,所产生的累积同步误差使相长干涉的分组接收率随着独立子路径的跳数增加而减少。对此,文献[21]通过设计基于网格的网络洪泛协议SCIF(spine constructive interference-based flooding),改善了相长干涉的可扩展性问题。但是,SCIF增加了转发跳数,从而增大了数据传输时延。文献[22]在多条传输链路中选取数据分组转发次数最少的链路转发相长干涉数据分组,提出了并发传输调度算法(CX, concurrent transmission)。相比于Glossy,CX 在一定程度上节省了转发过程中的能量消耗,但是,转发次数易受外部环境和链路质量的影响而动态变化,从而导致CX调度算法的重复调用,增大了网络传输时延和计算开销。此外,在理想条件下(PRR=100%),CX调度算法的计算对象为全网节点,并未对拓扑进行有效控制。文献[23]设计了单跳时延误差的时钟补偿方案 Triggercast,提高了相长干涉的可靠性。但是,Triggercast没有对智能传感系统中相邻两层节点的距离误差进行补偿。文献[24]在Triggercast的基础上提出了有损链路下相长干涉的充分条件。文献[24]认为参与发送的节点数量越多,相长干涉的分组接收率并非越高,从侧面证实了对基于相长干涉的智能传感系统进行拓扑优化的必要性。
此外,相长干涉在智能传感系统中的应用也很广泛。文献[25]提出了一种 MAC(medium access control)层协议Flip-MAC,通过修改IEEE 802.15.4的标志位,将相长干涉应用于 ACK帧的传递,大大节省了 ACK帧的转发时延。但是,随着并发节点数量的上升,Flip-MAC需要占用更多的标志位进行并发调度。另外,固定数量的标志位灵活性差,会带来传输开销和匹配率低等问题。文献[26]将相长干涉的应用扩展到了捕获效应的范围。与 LWB相比,文献[26]通过对转发时隙的控制实现了全网节点的数据交换。而文献[27]提出的FTSP(flooding time-synchronization protocol)则利用相长干涉减小时钟漂移估算误差,从而提高了时间同步协议的同步精度。此外,为了解决隐蔽站问题,文献[28]提出了一种冲突处理机制,而文献[29]利用相长干涉实现了快速、高效的冲突调度。此外,文献[30]设计了相长干涉的硬件测试平台Flocklab,文献[31]基于相长干涉设计了一个MAC协议参数的低功耗采集方案pTunes。与FTSP类似,文献[32]使用相长干涉改进时钟同步精度。文献[33]将相长干涉应用于可见光通信的数据传输。
综上所述,相长干涉技术以其可靠、快速的特点受到了广泛关注。然而,目前尚缺乏一种自下而上的基于相长干涉的智能传感并发传输策略。本文提出的C3S策略,将时钟校准、拓扑优化和流水线构建集于一体,不仅解决了相长干涉的能耗、吞吐量等问题,也很大程度上提升了相长干涉在智能传感系统中的应用范围。该策略可以使传感器节点进行智能时钟校准和智能能量调度,并自动构建基于相长干涉的并行流水线。
3 智能时钟同步层的设计
本节主要介绍C3S的底层策略,给出了相长干涉的相关定义,分析了相长干涉的码片级时延误差,描述了如何通过拓扑控制完成ICCA算法的设计。
3.1 定义
应用相长干涉进行数据传输时,通常采用同步机制控制数据传输流程。
在图3所示的传输场景中,第一个同步传输轮次内,初始节点I先将相长干涉数据分组发送给第一层同步节点R1、R2、R3和R4。R1、R2、R3和R4在收到数据分组后,在第二个同步传输轮次内同时将相长干涉数据分组发送给第二层同步节点R5、R6、R7、R8、R9以及初始节点I。在此轮次内,节点I同时收到来自R1、R2、R3和R4的相长干涉数据分组,R5同时收到来自R1、R2的相长干涉数据分组,R6同时收到来自R2、R4的相长干涉数据分组,R7同时收到来自R1、R3的相长干涉数据分组,R8同时收到来自R3、R4的相长干涉数据分组,R9同时收到来自R2、R3、R4的相长干涉数据分组。与第二个同步传输轮次类似,在第三个同步传输轮次中,R5、R6、R7、R8和R9将相长干涉数据分组同步传输给叶子节点:R10、R11、R12、R13、R14和R15。此外,每个节点转发数据分组的次数不能超过最大发送次数(参见定义2)。而且,每次相长干涉都必须满足以下条件。

图3 相长干涉分层传输原理
1) 多个节点同时向一个共同节点发送内容相同的数据分组。
2) 多个节点发送的数据分组到达共同节点时的最大时间位移。

3)m个发送节点的信号强度差满足其中,Pmax为m个发送节点的最高信号强度,ΔiP为第i个节点的信号强度差。
根据相长干涉的特点,本文对相长干涉的主要概念进行如下定义和说明。
定义 1在相长干涉过程中,来自多个节点的同步数据分组到达接收端时的最大时间误差称为相长干涉的最大时间位移,用Δ表示。
定义 2在相长干涉过程中,任意节点发送同一个数据分组的最大次数称为相长干涉的最大发送次数,用N_tx表示。
定义 3在相长干涉过程中,节点成功接收同一个数据分组的次数与最大发送次数的比值称为相长干涉的数据分组传输成功率。
说明相长干涉的数据分组传输成功率与分组接收率不同,前者更强调每次相长干涉发生时的成功率,而后者是指在相长干涉的最大发送次数内,只要一次接收成功就计算为有效接收分组。
定义 4相长干涉的数据分组从初始节点发出开始,到全网节点都收到该数据分组为止的这段时间称为相长干涉的网络传输时延。
说明相长干涉的网络传输时延更强调全网节点首次全部收到数据分组的时间,代表了相长干涉数据传输到全网的最短时间。
定义 5相长干涉的数据分组从初始节点发出开始,到全网节点结束数据分组的发送和接收为止的这段时间内,全网节点的射频芯片运行时间的总和称为相长干涉的射频芯片工作时长。
3.2 相长干涉时延误差分析
设计智能时钟同步策略的目的是保证相长干涉的可靠性。为此,本文首先通过捕捉初始节点和转发节点中SFD中断的码片级时延,对相长干涉数据传输时序进行分析。
如图4所示,在发送和接收一个数据分组的过程中,初始节点和转发节点之间存在的时间延迟主要包括:发送数据时延Tip、传播时延Tcd和接收数据时延Trp。其中,Tip由信号处理时延Tsp和发送时延Tfd组成,Trp则包含由软件校准时延Tsd、逻辑处理时延Tld和收发转换时延Ttd。其中Tsp的取值与射频芯片的采样频率相关,误差范围为0.125 μs以内。而且对于相同型号的智能传感器节点来说,由于相长干涉的数据分组长度相同,节点传输速率也相同,所以Tfd是常量,可以忽略不计。此外,Tsd的值可以参照式(2)计算。

其中,fc为射频芯片的晶振频率,fr为DCO振荡频率,kr为在区间[0, 1]内的随机数。值得注意的是,最新的射频通信芯片 CC2538可消除软件校准时延。Tld则受晶振时钟漂移的影响,无法完全消除。和Tfd类似,相同型号的智能传感器节点产生的Ttd也可以被看作常量。值得注意的是,Tcd的取值是依赖于网络拓扑的。
为了测试节点距离对Tcd的影响,本文分别在室内环境和室外环境下搭建了如图5所示的通信场景。
在图5中,节点S1和S2到接收节点R的距离差为Δd,且将R处收到来自S1和S2的信号强度调整为一致。将S2的位置固定不变,S1从距离节点R为1 m逐渐移动到100 m。通过S1和S2同时向R发送相长干涉数据分组,测试R处的分组接收率。

图5 相长干涉的Tcd误差通信场景
如图6所示,当节点距离大于45 m时,室内、室外的相长干涉分组接收率均低于90%。当大于70 m时,室内、室外的相长干涉分组接收率均低于10%。而且,受多径效应的影响,室内环境下的平均分组接收率比室外环境少 21%。可见,Tcd误差对相长干涉分组接收率的影响是明显的。
3.3 基于CI的智能时钟校准算法
在之前的工作中,Disco利用式(3)对单跳相长干涉的Tsp和Tcd进行了有效的补偿,有效提高了相长干涉的同步精度。


图4 相长干涉的节点SFD引脚时序

图6 节点距离差与相长干涉分组接收率
如图7所示,节点I为相长干涉数据传输的初始节点,而节点R1、R2、R3、R4、R5、R6、R7、R8和R9为转发节点。为了简单起见,假设网络拓扑中有2种不同的距离d1和d2,且任意节点与I的累计距离为dik,任意节点之间的距离为dpk。当相长干涉数据传输开始时,I首先向R1、R2、R3发出数据分组。在随后的传输轮次,由R1、R2、R3发送数据分组。如果按照式(3)对I与R1、R2、R3的距离差进行Tcd补偿,可以弥补di2与di1和di3之间的Tcd误差。但是,在图 7的拓扑中,R1、R2、R3同时也向R4、R5、R6转发数据分组。以R6为例,因为d63小于d62,若只考虑对上一跳的补偿反而会增加d63和d62带来的Tcd误差,从而导致相长干涉失败。
当N_tx=2时,进一步对相长干涉的冲突次数进行分析。在首个传输轮次,R1、R2、R3收到来自I的数据分组。接下来的传输轮次,由于Tcd误差导致节点I和R5处接收分组失败。同时,由于Tcd累积误差被抵消,R4和R6可以收到数据分组。第三个传输轮次,R1、R3、R7、R9会成功收到来自单个节点发来的数据分组;由于d42= d62= d2,d48=d68=d2,R2和R8也会成功接收来自R4和R6发送的数据分组。第四个传输轮次,因为d41+di1=d42+di2=d63+di3,节点I可以成功接收数据分组。同时,由于d51+d14+d41+di1=d52+d42+d41+di1=d53+d36+d63+di3,所以R5成功接收数据分组。然而,R4和R6却由于Tcd误差而导致相长干涉失败。第五个传输轮次,R7、R8、R9成功收到来自R5的数据分组。第6个传输轮次,R4和R6由于累积误差被抵消,所以成功收到数据分组。因为d85≠d95= d75,所以R5接收失败。最后一个传输轮次,R4和R6完成最后一次数据分组转发,相长干涉数据传输结束。在所有的7个传输轮次中发生了5次由Tcd累积误差引起的相长干涉失败。因此,要保证相长干涉的可靠性,需要设计基于网络拓扑的Tcd补偿算法。

图7 基于Tcd的网络拓扑
根据图7的网络拓扑,可以将智能传感系统中的节点分为末端节点和中转节点两类。末端节点包括初始节点和叶子节点,只需要计算单跳Tcd补偿。当时,中转节点可以在不同的传输轮次中分别完成对上一跳和下一跳的Tcd补偿。假设一个包含n个节点的智能传感系统,第i个节点在第k个传输轮次的Tcd补偿与校准式如式(4)所示。
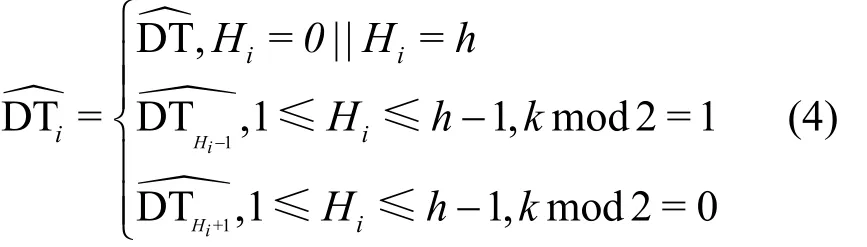
基于式(4),本文提出智能时钟校准算法ICCA。如算法1所示,ICCA假设初始节点为v1,网络跳数为H,节点vi的跳数为hi,Niu={u1,u2,…,up},Niu∈V为节点vi的hi-1跳邻居节点集合,Nid={d1,d2,… ,dq},Nid∈V为节点vi的hi+1跳邻居节点集合。首先,ICCA根据hi判定节点的类别。若当前节点是末端节点,按照式(3)进行Tcd补偿。若当前节点是中转节点,则在奇数传输轮次对其上一跳节点进行补偿,在偶数传输轮次对其下一跳进行补偿。最后,算法返回智能传感系统中所有节点在第i个传输轮次的Tcd补偿集合。
算法1智能时钟校准算法(ICCA)
输入一个节点集合V={v1,v2,… ,vn}
输出节点Tcd补偿集合T={t1,t2,… ,tn}

//初始节点或叶子节点
遍历其上一跳节点集合Niu

//中间节点

遍历其上一跳节点集合Niu

end
//传输轮次判定

ICCA的信号强度增益计算方法如下。假设射频芯片的频率为fc,Ai是节点接收的最强信号的振幅,Δt是时延补偿的残差,补偿后的时延是一个在区间上均匀分布的随机变量。对于一个h跳,每跳nj(j=1,…,h)个节点的网络,可以得到SNR的增益如式(5)所示。

ICCA的时间复杂度计算方法如下。对于包含n个节点的智能传感系统,ICCA算法的时间复杂度主要取决于中转节点的个数,以及每个中转节点的上、下层邻居节点个数。假设有k个中转节点(k<n),则 ICCA 的时间复杂度为O(k(p+q))。
4 智能能耗优化层的设计
本节主要介绍C3S的中间层策略,给出了相长干涉数据传输的能耗问题,介绍了节点状态迁移时序设计过程,描述了节点智能模式调度流程的设计,提出了相长干涉的能量消耗模型。
4.1 相长干涉数据传输的能耗问题
以 Glossy为代表的拓扑无关相长干涉数据传输协议要求所有智能传感系统中的节点参与数据分组转发,这会带来冗余的能量消耗。
如图8所示,按照Glossy的工作流程,图中所有的节点都需要转发数据分组。而事实上,只需要在中转节点中选择R2和R4进行相长干涉数据传输就可以将数据分组发送给L1、L2、L3、L4和L5。这可以比Glossy节省80%的能量。因此,传统的相长干涉数据传输存在冗余能量消耗的问题。同时,若选择R1、R3和R5进行相长干涉数据传输,也能将数据分组发送给L1、L2、L3、L4和L5。这意味着,当网络中出现冗余覆盖时,在底层ICCA算法的基础上通过智能调度转发节点的集合,可进一步延长网络生存期。

图8 相长干涉的能耗问题
针对相长干涉数据传输的能量消耗问题,本文采用拓扑相关的方法,从修改传统相长干涉数据传输的工作流程入手,提出稀疏网络拓扑下的相长干涉能量自适应调度方案CIES。
4.2 CIES的节点状态迁移时序
由于相长干涉数据传输要求的亚微秒级的同步精度,全网节点以相同的频率进行数据分组的转发。如图9所示,每个节点工作在4种不同的状态——睡眠状态、监听状态、接收状态和发送状态,节点通过触发不同的事件进行状态切换。在传统方法下,当相长干涉数据传输开始时,初始节点和中转节点分别触发Iw_Evt和Tw_Evt。初始节点进入发送状态,中转节点进入监听状态。正常情况下,当节点的发送次数c<N_tx时,节点在发送状态、监听状态和接收状态之间循环轮转,同时对发送次数进行计数。然而,当相长干涉数据传输失败时,触发F_Evt事件使节点从接收状态回到监听状态。当完成最后一次发送,即c=N_tx时,节点返回睡眠状态以节省能量。

图9 CIES的状态迁移
CIES对上述状态迁移时序进行了优化,给每个节点设定了2种工作模式:节能模式和转发模式。处于转发模式下的节点,其状态迁移时序与传统方法一致。处于节能模式下的节点在成功接收到一次数据分组后就触发Sl_Evt事件转入睡眠状态。
以常用的智能传感器节点的射频芯片 CC2538为例,其通用异步收发传输器的能耗为0.7 mA,而睡眠状态的能量消耗仅为0.9 μA。节能模式可以有效减少射频芯片处于发送状态和接收状态的时间,从而有效解决相长干涉数据传输的能量消耗问题。
4.3 CIES的节点智能模式调度
实现CIES的一个挑战就是根据网络拓扑和剩余能量找到网络中在转发模式下工作的节点集合。要降低相长干涉射频芯片工作时长就需要最小化转发节点集合,生成新的稀疏网络结构。而且,每个节点需要进行智能模式调度。这就需要设计轻量级、分布式的转发节点集合选择算法。
假设一个由n个节点组成的智能传感系统,各节点具有相同的传输范围。定义一个单位圆图G(V,E),图中边的集合为则存在以下定义。
定义6若图G(V,E)中存在节点集D,任意节点v属于D或者距离D一跳,则集合D是图G的一个支配集。若D的任意子集组成的子图是一个连通图,则D是一个连通支配集。若存在∀d∈D,使D-{d}不是连通支配集,则D是一个最小连通支配集。
定义7集合D中的节点称为支配节点(DN ,dominant node),能将一个支配集变为连通支配集的节点称为连通节点(LN,link node),连通支配集以外的节点称为雇佣节点(EN,employment node)。
CIES首先采用构造近似最小支配集的方法,并使用节点累积射频芯片工作时长作为关键技术指标,进行相长干涉的节点工作模式调度。
由定义6和定义7得知,DN节点和LN节点应设置为转发模式,而EN节点应设置为节能模式。因此,应该顺序设计DN节点选择流程和LN节点选择流程。
4.3.1 DN节点的选择
如图 10所示,在初始状态下,所有节点的类型值均为EN。若一个节点v的累积射频芯片工作时长小于门限值T0,就可以向其邻居节点发出DN节点广播请求,并将其累积射频芯片工作时长写入请求数据分组。随后,v的邻居节点会返回ACK,其中包含该邻居节点的射频芯片工作时长。收到来自所有ACK后,节点v将自己的累积射频芯片工作时长与所有邻居节点的累积射频芯片工作时长进行比较,若节点v的累积射频芯片工作时长最小,则节点v可发出DN节点声明的广播数据分组。如此反复,当网络中不再有节点发出DN广播请求,DN节点选择流程结束。在此之后,G中的节点或者是DN节点,或者是ED节点。

图10 DN节点选择流程
4.3.2 LN节点的选择
如图11所示,所有的ED节点将其与DN节点的连接信息进行广播。图G中一个ED节点最多与5个DN节点相邻[34]。而且,任何2个DN节点之间的距离可能是二跳或者三跳。当任意2个DN节点的距离为两跳时,形成路径若中间节点v与其他ED节点相比累积射频芯片工作时长最小,则节点v可以发送广播分组声明成为LN节点。当2个DN节点的距离为三跳时,形成路径所有和DN1、DN2连接的二跳中间节点分别将其累积射频芯片工作时长发送给DN1和DN2。若节点u和节点v的累积射频芯片工作时长分别在其所处的候选节点集合中为最小值,那么u和v在收到DN1和DN2的ACK后声明为LN节点。否则,节点DN1和DN2会继续重复上述步骤选择其他节点。
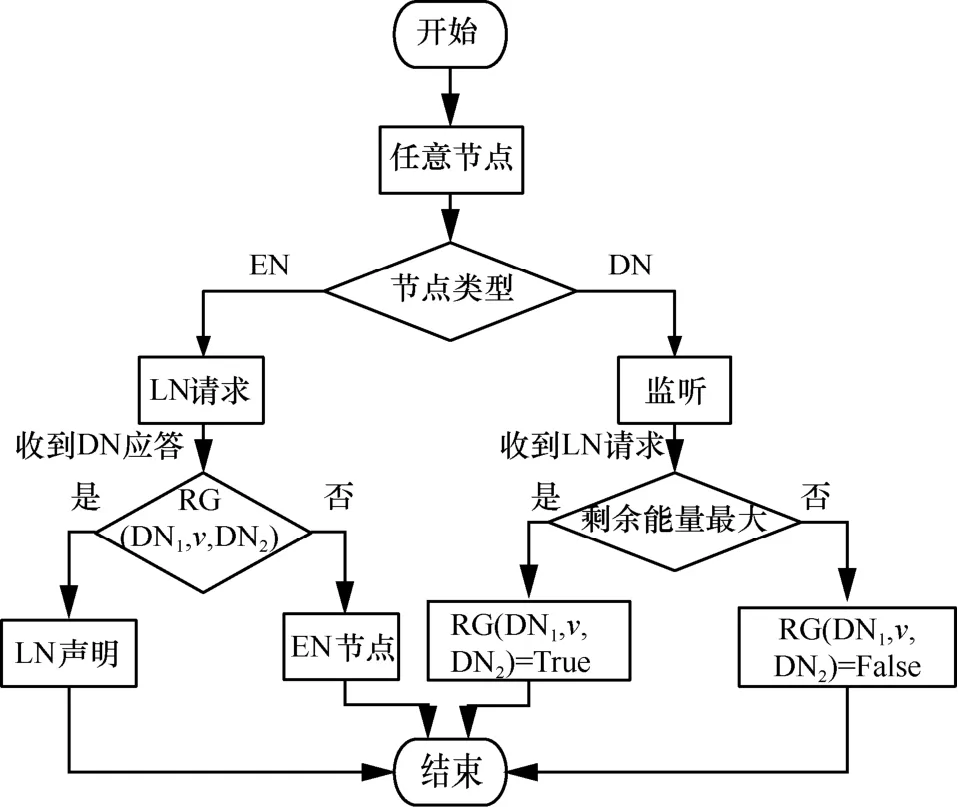
图11 LN节点选择流程
定理1CIES进行拓扑优化后,G中任意节点u和v之间的最大跳数是3h+2。其中,h是u和v之间最短路径的跳数。
证明假设G中任意两点u和v之间的最短路径为:P(u,v)={p1,p2,…,ph},其中p1=u,ph =v。对于∀pi,若pi不是DN节点,设其连接的DN节点为di;若pi是DN节点,则di=pi。
因为CDS (u,v)中至多有h个DN节点,即
CDS(u,v)={u,x1,x2,…,xh,v};
所以xi和下一个DN节点之间最多为三跳,即
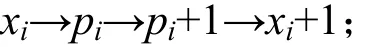
所以P(x1,xh)至多为3h跳;
因为 CDS(u,v)=P(u,x1)+P(x1,xL)+P(xh,u)=3h+2;
所以 CDS(u,v)至多有 3h+2 跳。
定理1从理论上证明了CIES的最大跳数上限。而且,当P(u,v)中的奇数下标节点为DN节点,偶数下标节点为LN节点,且任意2个DN节点之间均为两跳时,CDS(u,v)的值就是最短路径。
对于冗余覆盖的智能传感系统,每个节点上都设置相同的T0。若某个DN节点或者LN节点的累积射频芯片工作时长超过T0,CIES会通过该节点发出广播,从而完成最小支配集的重建。在重建过程中,CIES首先将原来的DN节点和LN节点的节点类别都设为EN,然后触发DN选择流程和LN选择流程,找到新的DN节点和LN节点集合,产生新的最小支配集,延长智能传感系统的生命期。然而,若CIES找不到新的DN节点和LN节点集合,则只能将全网节点都设置成中转节点。
4.4 CIES的能量消耗模型
假设智能传感系统有n个节点。任意节点在监听状态、发送状态和接收状态中单位时间内的能量消耗分别为Es、Et和Er。节点处于监听状态、发送状态和接收状态的时间分别为Ts、Tt和Tr。其他参数还包括数据分组长度l、数据传输速率kbit/s。
传统相长干涉数据传输方法让所有节点循环N_tx个周期的监听状态、发送状态和接收状态轮转后才结束整个传输过程。因此,其能量消耗可表示为
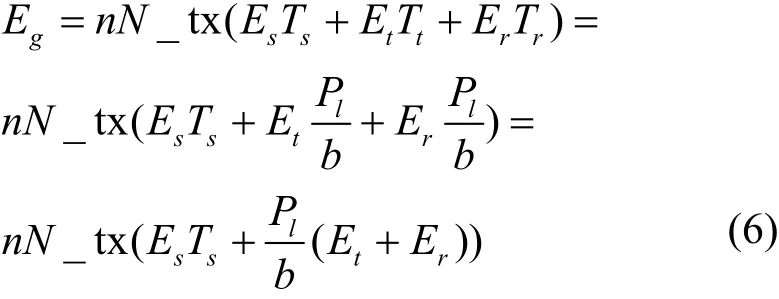
CIES中转节点的能量消耗与式(6)相同。但是,EN节点只需要运行一次完整的状态转换。因此,CIES的能量消耗可表示为

其中,
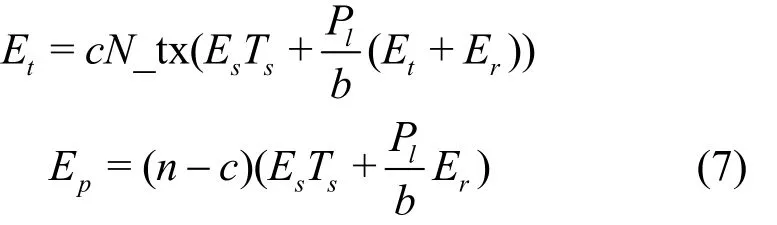
其中,c为中转节点的数量,Et和Ep分别为中转节点和EN节点的能量消耗。CIES节省的能量ΔE可计算为
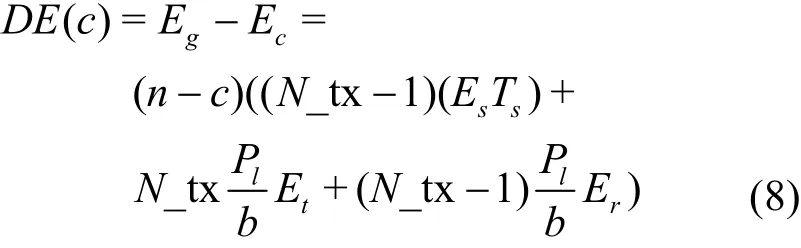
式(8)表明,每个 EN节点可减少N_tx-1次待机状态,N_tx-1次接收状态和N_tx次发送状态。然而,DN和LN节点则不能节省能量。因此,CIES在冗余覆盖图中节省的能量KEc可计算为

式(9)说明,能量的节省正比于UDG中冗余中转节点集的数量。
5 智能并行流水线层的设计
本节主要介绍C3S的性能提升策略,分析了相长干涉的多信道通信特点,介绍了CI2P的建立过程。
5.1 CIES的节点状态迁移时序
在第4节的自适应能量分配策略和现有低占空比唤醒方法的基础上,如何提高网络的吞吐量就显得尤为重要。PIP和Splash采用信道轮转的方法实现相长干涉。然而,PIP对网络冗余路径的利用率低。Splash虽然让全网节点参与转发,但是只实现了单流水线。本文旨在实现一种相长干涉的多信道并行流水线CI2P。
在建立 CI2P之前,需要首先评估相长干涉在射频芯片的16个工作信道上的通信可靠性。为此,本文设置了一个接收节点和16个发送节点。16个发送节点分别工作在 16个不同的信道,接收节点则通过信道轮转接收数据分组。每个发送节点发送500个数据分组,平均分组接收率的结果如图12所示。除了第 26号信道之外,其他信道的平均分组接收率都在10%到40%之间,属于有损链路。而且,除了第 26号信道之外,其他信道的分组接收率的平均方差达到 0.593。评估结果表明,在单链路下通过信道轮转建立流水线,其可靠性不能满足智能传感系统的需求。
幸运的是,相长干涉的数据传输采用的是并发链路。因此,本文对基于相长干涉的并发链路进行了可靠性测试。在上述实验的基础上,每个发送节点附近增加3个工作在相同信道的并发节点,采用相长干涉的方式同时向接收节点发送数据分组。如图 13所示,第 26号信道的分组接收率提升至99.8%,方差减小为0.02。其他信道中,有4条信道的分组接收率超过了70%。分组接收率最小的信道也提升至38%。除了第26号信道之外,其他信道的分组接收率的平均方差减少到0.13。
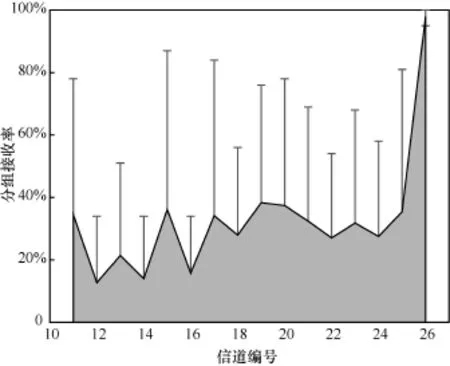
图12 16条信道的分组接收率
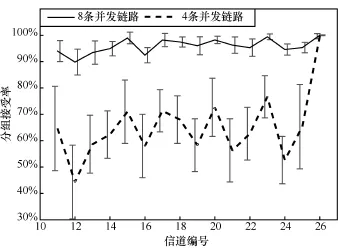
图13 16条信道相中干涉下的分组接收率
进一步将并发节点的数量增大至8个。如图13所示,第26号信道的分组接收率达到了99.99%,方差减小为 0.001。其余信道的平均分组接收率也超过了90%。
5.2 CI2P的建立
在单信道通信中,相长干涉数据传输只允许智能传感节点每 2个传输轮次发送一个数据分组。CI2P将多信道轮转应用于任意节点之间的数据传输,实现了并行流水线,其基本原理如图14所示。
在图14中,传感系统中的任意节点I通过节点v1,v2,...,v8的转发将相长干涉数据分组发往节点D。相长干涉数据传输开始时,节点I、v1、v2工作在信道a,v3和v4工作在信道b,v5和v6工作在信道c,v7和v8工作在信道d。每一个传输轮次结束后,节点I在信道a和信道b之间反复切换,v1和v2在信道a和信道c之间反复切换,v3和v4工作在信道b和信道d之间反复切换,v5、v6、v7和v8不需要进行信道轮转。由于要分别接受来自2条流水线的数据分组,目的节点D则需要在信道c和信道d之间反复切换。在第一个传输轮次,所有节点都工作在默认信道。第二个传输轮次,节点I转换到信道b,v1和v2 转换到信道c。第三个传输轮次,节点I、v1和v2转换到信道a,v3和v4转换到信道d。第四个传输轮次,节点I、v3和v4转换到信道b,节点D转换到信道d。在CI2P建立的过程中,共发生了10次信道转换。
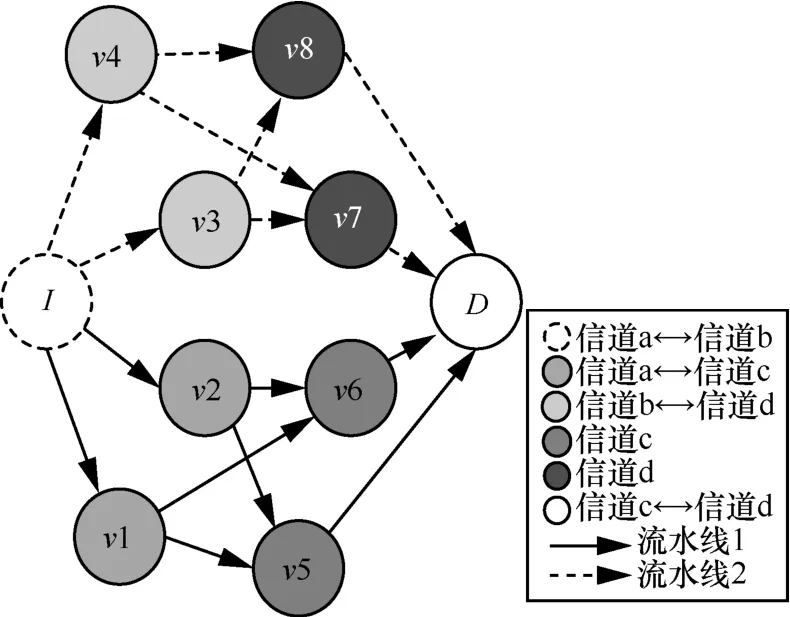
图14 CI2P的基本原理
图15描述了CI2P建立的过程中各节点收发数据分组的详细情况。其中,P1i和P2i分别表示CI2P中流水线1和流水线2上的第i个数据分组。相长干涉数据传输开始时,所有节点都在监听状态。第一个传输轮次,节点I发送数据分组P11。由于v3和v4工作在信道b,所以只有v1和v2收到数据分组P11。第二个传输轮次,节点I发送数据分组P21,v1和v2转发数据分组P11,在v5处形成相长干涉。第三个传输轮次,节点I发送P12,v3和v4发送P21,v5和v6将P11发送给目的节点D。第四个传输轮次,节点I发送数据分组P22,v5和v6收到数据分组P12,v7和v8将P21转发至目的节点D,并发流水线建立完成。自第五个传输轮次开始,节点D在每个传输轮次都会收到一个不同的数据分组。CI2P建立后数据分组的轮次产出比达到了100%。
根据上述分析,CI2P的建立方法如下。首先通过第3节的最小支配集构建方法选出从I到D的转发节点集合S1和S2。然后,分别对S1和S2中的节点信道进行如下调度。初始节点I的默认信道与S1的第一层节点相同,其轮换信道与S2的第一层节点相同。目的节点D的默认信道与S1的第h-1层节点的信道一致(h为S1和S2的深度)。对于任意中转节点vi,若所处层次为第h-1层,则一直工作在默认信道。否则,若vi位于S1,则vi的默认信道等于vi所在的层次,vi的轮转信道与下一层的高度相等。若vi位于S2,则vi的默认信道等于vi所在的层次数与h-1的和,vi的轮转信道等于默认信道号+1。

图15 CI2P建立流程
将CI2P的传输效率与Glossy和Splash进行比较。假设数据分组的大小为xbit,每个传输轮次时隙为Ts,I与D之间的跳数为h,N_tx的值为1。Glossy完成一个数据分组的传输时间为hTs,Splash完成一个数据分组的传输时间为2Ts,而CI2P完成一个数据分组的传输时间为Ts。因此,CI2P的传输效率是Glossy的h倍,是Splash的2倍。
6 C3S策略的性能评估
本节主要介绍C3S的性能评估,分析了智能时钟同步层的性能,对能耗优化层的CIES策略进行了评估,评估了智能并行流水线层的性能。
6.1 智能时钟同步层的性能评估
为了评估智能时钟同步层 ICCA算法在智能传感系统中的有效性,本文在Matlab2015上搭建了一个包含4 000个节点的均匀分布网络,对该ICCA的收敛时间、数据分组传输成功率和网络传输时延进行评估。图16描述了当节点个数从500个增加到4 000个时,ICCA的收敛时间。当节点个数为500时, ICCA的收敛时间为2.32 μs。当节点个数为4 000时,ICCA的收敛时间为6.78 μs。每增加 500个节点,ICCA的收敛时间平均增加0.65 μs。

图16 ICCA的收敛时间
如图17所示,当智能传感系统的节点个数从500个增加到4 000个时,Glossy的数据分组传输成功率下降了 32%,然而,ICCA的数据分组传输成功率在此过程中一直保持在96%以上。节点个数增加会加大总的数据转发次数,当出现数据分组传输失败时,会加大累积时延误差,从而影响后续的数据分组传输成功率。从图17还可以看出 ICCA数据分组传输成功率的平均误差比Glossy要小。

图17 ICCA的数据分组传输成功率
最后,本文评估了定义4描述的网络传输时延。如图18所示,当智能传感系统包含500个节点时,ICCA的网络传输时延为1.24 ms,而Glossy的网络传输时延为2.41 ms,比ICCA多了1.17 ms。当节点个数增加到4 000个时,ICCA的网络传输时延为5.02 ms,而Glossy的网络传输时延为7.14 ms,比ICCA多了2.12 ms。而且,ICCA网络传输时延的平均误差为0.16 ms,而Glossy网络传输时延的平均误差为0.64 ms。
当节点个数超过2 000个时,Glossy网络传输时延的平均误差达到了0.87 ms。很明显,ICCA的网络传输时延更小,数据传输更稳定。

图18 ICCA的收敛时间
6.2 智能能耗优化层的性能评估
本节分别对CIES的分组接收率、网络传输时延和射频芯片工作时长进行评估,所有评估结果均取500次测试的平均值。
如图19所示,当N_tx=1时,CIES和Glossy的PRR均超过97.2%。当N_tx=2时,CIES和Glossy的PRR均达到99.9%。图19中也存在个别分组接收率低于 80%的情况。例如,当传输距离为 65 m时(N_tx=1),有一次的分组接收率仅为 76.4%。原因在于,CIES在减少转发次数的同时也减少了节点接收数据分组的次数。在CIES中,EN节点只能从上层的 IN或者 LN节点获取数据分组。而在Glossy中,中间节点可从上层节点和下层节点至少获得2次接收数据分组的机会(N_tx=1)。
图20描述了1 052个点组成的智能传感系统在N_tx=2时的网络传输延迟。在CIES中,有264个点的网络传输延迟在1 ms以内,全网节点收到数据分组的时间是11 ms。然而,Glossy将数据传遍全网的时间要多花费的时间。虽然Glossy可以实现毫秒级的相长干涉数据传输。但是,图 20的仿真证明,CIES的数据传输速度相比Glossy更快。这是因为,CIES通过基于底层的ICCA算法,同步精度高,从而减少了重传次数。

图19 CIES的可靠性评估

图20 CIES的网络传输延迟
图21展示了累积射频芯片工作时长。当节点传输距离在40~100 m内,Glossy的累积射频芯片工作时长从22.5 ms降至19.6 ms。而CIES的累积射频芯片工作时长从15 ms降至7.2 ms。当传输距离为100 m时,CIES可以节省63.93%的能量消耗。图21说明,CIES对能量消耗的节省与网络密度成正比。
6.3 智能并行流水线层的性能评估
本节分别对 CI2P的分组接收率、吞吐量和网络利用率进行评估。如图22 所示,CI2P的平均分组接收率为 98.84%,Glossy的平均分组接收率为99.11%,Splash的平均分组接收率为97.22%。在所有的测试中,CI2P有 4次获得最高分组接收率,Splash只有一次获得最高分组接收率,而Glossy获得了7次最高分组接收率。此外,Glossy的分组接收率方差为0.022,CI2P的PRR方差为0.026,Splash的PRR方差为0.031。图22的实验结果表明,3种协议的分组接收率差距不明显。相比而言,Glossy最稳定。原因是在于,Glossy可以充分利用网络中的所有节点进行相长干涉数据传输。Splash在流水线切换时产生了时延误差,影响了分组接收率。由于底层的ICCA算法,CI2P的分组接收率与Glossy更为接近。

图21 CIES的射频芯片工作时长

图22 CI2P的可靠性评估
为了对吞吐量进行评估,本文在智能传感系统中任选10条初始节点与目的节点组成的通信链路,在每条链路上分别使用D-PIP、Splash和Glossy 发送长度为32 bit 的数据分组,测量上述3种方法的平均分组接收率。如图23所示,Glossy的平均吞吐量为25.74 kbit/s,Splash的平均吞吐量为78.67 kbit/s,CI2P的平均吞吐量却达到了177.43 kbit/s。实验结果说明,CI2P的平均吞吐量是Splash的2.23倍,是Glossy的6.85倍。在图23中,CI2P的吞吐量平均误差为 6.42 kbit/s,Splash的吞吐量平均误差为14.54kbit/s,Glossy的吞吐量平均误差为3.04 kbit/s。可见,与Splash和Glossy相比,CI2P显著地提高了网络吞吐量。
在图24中,本文测量了CI2P在10条信道中的利用率。首先,本文使用TelosB节点进行了满载数据传输测试,测试结果表明,TelosB节点的实际最高速率为220 kbit/s。然后,本文使用CI2P进行相长干涉数据传输,用测得的吞吐量占实际最高速率的百分比来衡量CI2P的信道利用率。如图24所示,链路1中测得的有效利用率最低,为75.2%。吞吐量为167.2 kbit/s。链路9的信道利用率最高,其吞吐量达到了204.6 kbit/s。所有10条链路的平均信道利用率达到了84.21%。实验结果说明,CI2P的信道转换时延只占用了15.79%的利用率。

图23 CI2P的吞吐量评估

图24 CI2P的信道利用率评估
7 结束语
本文提出了一种基于相长干涉的并发传输策略C3S。该策略采用分层的思想,针对智能传输系统的可靠性、功耗和吞吐量进行了优化设计。C3S提出了ICCA智能时钟校准算法,CIES智能能量分配方案和 CI2P智能并行流水线。与传统的相长干涉数据传输协议相比,C3S的同步精度更高,传输时延更小,传输功耗更低,信道利用率更高。
猜你喜欢
体育科技文献通报(2022年4期)2022-10-21
传感技术学报(2022年7期)2022-10-19
今日农业(2022年15期)2022-09-20
体育科技文献通报(2022年3期)2022-05-23
作文中学版(2020年1期)2020-11-25
通信电源技术(2020年8期)2020-07-21
电子制作(2019年23期)2019-02-23
电子制作(2018年23期)2018-12-26
汽车文摘(2017年5期)2017-12-05
现代防御技术(2016年1期)2016-06-01
